Question: Does the software really use the new instruction sets?
Over time, vendors added new and new instructions to the processors that control our laptops, servers, phones, and many other devices. Adding machine instructions that solve specific computational subtasks is a good way to improve the performance of the system as a whole without complicating the pipeline and not trying to ramp up the frequency to beyond the limits. One new instruction, performing the same operation as several old ones, allows repeatedly increasing the performance of solving a given task.
New instructions, such as Intel Software Guard Extensions (Intel SGX) and Intel Control-flow Enforcement Technology (Intel CET) , are also able to provide completely new functionality.

The good question is how soon the new instructions added to the architecture reach the end user. Can operating systems and other applications take advantage of new instructions , taking into account that they usually provide backward compatibility and the ability to run independently of the installed processor model? Many years ago, the use of new instructions was achieved by rebuilding the program for the new architecture and adding checks that prevent starting on old hardware and printing something like “sorry, this program is not supported on this hardware”.
')
I used Wind River Simics full-platform simulator to find out to what extent modern software can use new instructions, while remaining compatible with old hardware.
To find out how software can dynamically adapt to different hardware, I used the Simics model of the “generic PC” platform and two different processor models: the first generation Intel Core i7 (codename Nehalem, released late 2008) and the Intel Core i7 sixth generation (codename Skylake, released in mid-2015).
The following Linux boot scripts were run that run on the configurations described above:
The same disk image was used for testing, thereby ensuring that the software stack remains unchanged. Only the configuration of the processor in the virtual platform differed. It was expected that Linux, running on newer hardware, would use new instructions. Each configuration was launched with the connected instrumentation mechanism, which counted how many times each instruction was executed. The mechanism for instrumentation existing in Simics does not change the behavior of guest applications and allows studying the loading of the BIOS and operating system kernels due to the fact that it operates at the level of processor commands. At the same time, the executing application cannot determine whether it is running with or without a tool. Each configuration was executed in 60 seconds of virtual time. This is enough to load the BIOS and operating system. After each launch, 100 most frequently used instructions were selected, which were used for further analysis.
The basis of this work is the assumption that the software can dynamically adapt the executable code depending on the equipment used. That is, the same binary structure can use different instructions on different hardware.
In order to understand how this dynamic adaptation works, you need to understand how iron works. Far in the past, when there were few processors and new models appeared quite rarely, the software could easily check whether the performance was on Intel 80386 or 80486, Motorola 68020 or 68030 and adapt its behavior accordingly. Now there is a huge variety of systems. To solve the problem of identification on IA-32 processors, you should use the CPUID instruction , which itself is a complex system that describes various aspects of equipment.
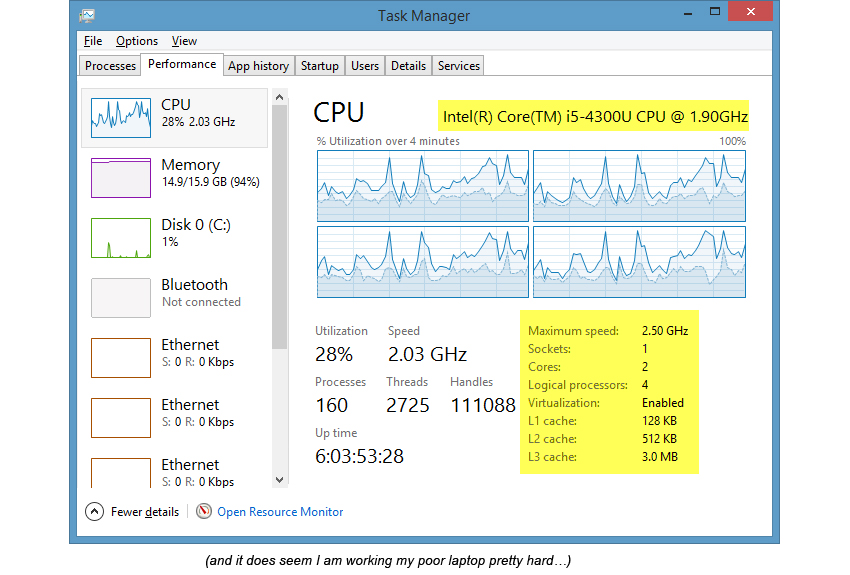
You, for certain, already met the information received by means of the CPUID instruction, without even thinking of its source. For example, the Task Manager in Microsoft Windows 8.1 shows information about the type of processor and some of its other characteristics, which are obtained using the CPUID instruction:
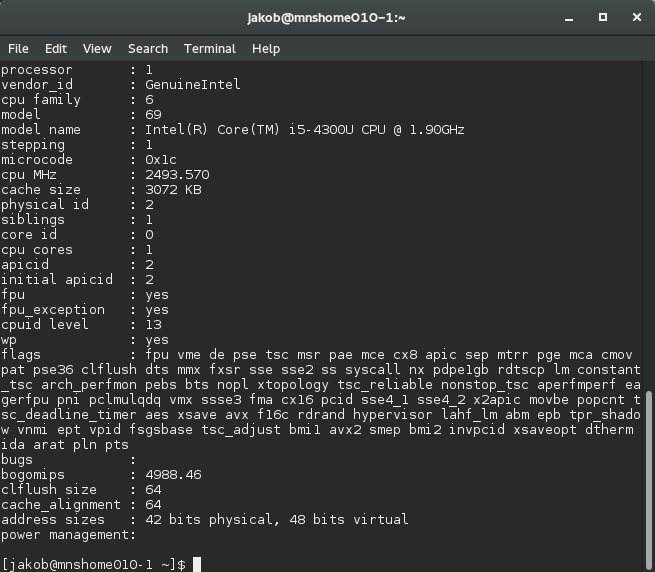
On Linux, the "cat / proc / cpuinfo" command can display comprehensive information about the processor, including the flags of the command set extensions that are available on the current system. Each extension has its own flag, the presence of which the software should check before the start of execution. Here is an example of information collected on the fourth generation Intel Core i5 processor:
CPUID provides information on the various instruction set extensions available in the processor, but how does the software actually use these flags to select the appropriate binary code depending on the hardware? It would not be wise to use an “if-then-else” construct in every place that is going to use “non-standard” instructions. It is enough to do the check only once, since these characteristics will not change during the session.
Linux usually uses function pointers that use different instructions to implement the same functionality. A good example can be found in the file arch / x86 / crypto / sha1_ssse3_glue.c (source elixir.free-electrons.com/linux/v4.13.5/source ):

These functions check for certain functionality and register the corresponding hash function. The order of the call ensures that the most efficient implementation will be used. Specifically, in this case, the best solution is based on SHA-NI extension instructions , but if they are not available, AVX or SSE implementations are used.
The graph below shows the results of running six different configurations (two processors and three operating systems). It shows all the instructions, the number of which exceeds 1% of the total number in any launch. "V1" means the launch of the first generation on the Core i7, the "v6" - the sixth.
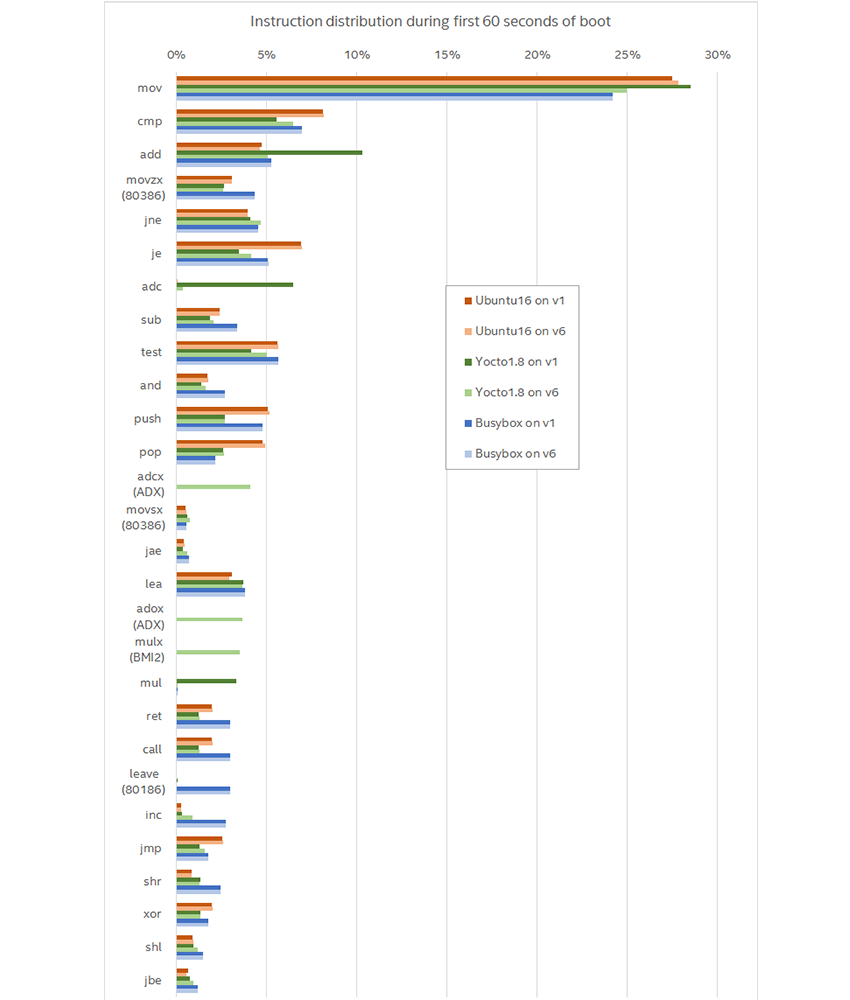
The first conclusion that suggests itself: most of the instructions are not very new. Rather, they refer to the basic instructions added back in Intel 8086: move, compare, jump, and add. For newer instructions, the name of the extension in which they were added is written in parentheses. A total of six more or less new instructions in the list of the 28 most frequently used ones.
Obviously, there are variations between different versions of Linux in addition to variations caused by using different processors. For example, BusyBox, configured with the old kernel, uses the LEAVE instruction, which is not popular with other kernel versions, and it also uses the POP instruction much less. However, this does not answer the question of how software uses new instructions when they are available. For our goal, the most interesting variations are caused by a change in the processor generation when the same software stack is started.
All of the scenarios studied in this work are loading the Linux operating system with different kernel parameters. In addition, different distributions can be compiled by different versions of the compiler using different flags. Thus, a binary code, even compiled using the same source code, may differ.
On the example of Yocto, we see this effect. Yocto uses ADCX, ADOX and MULX instructions (included in the ADX and BMI2 extensions). This example also demonstrates well the speed at which new instructions can appear in software. These three instructions were added to the fifth generation Intel Core processor, which was released at about the same time as the Linux kernel used in Yocto. That is, support for new instructions was added by the time the processor entered the market. And this is not surprising, since the specification for new instructions is often published before their hardware implementation. That is, the software can pre-adapt its behavior (an interesting article on this topic) to new hardware, often using virtual platforms for debugging and testing.
However, Ubuntu 16.04 with a newer kernel does not use ADX and BMI2, which means that it was configured differently. This may be due to the compiler version or flags, kernel parameters, or a set of installed packages.
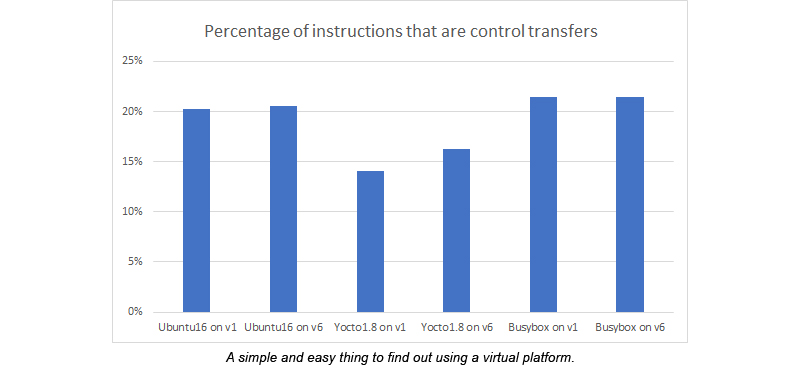
Another thing that was interesting to understand - what instructions are used to change the flow of control. The classic rule described in the no less classic book by Hennessy and Patterson says that every sixth instruction is Jump. However, the measurements showed that approximately one of the five instructions is an instruction that modifies the control flow. Closer to one of six for Yocto.
Perhaps the most well-known command-line extensions to the public are Single Instruction Multiple Data (SIMD) or, in other words, vector instructions. Vector instructions are present in IA-32 processors, starting with the MMX extension added to the Intel Pentium in 1997. Now the presence of MMX instructions is actually guaranteed. You may notice that some of them are present on the graph of the most popular instructions. Further, many different streaming SIMD Extensions (SSE) instructions and the most recent AVX, AVX2 and AVX512 were added.
I did not expect a large number of vector instructions, considering that the boot of the operating system and the BIOS were studied. However, approximately 5-6% of the executed instructions turned out to be vector. The number of executed vector instructions, measured as a percentage of the total number of instructions executed and grouped by extensions:
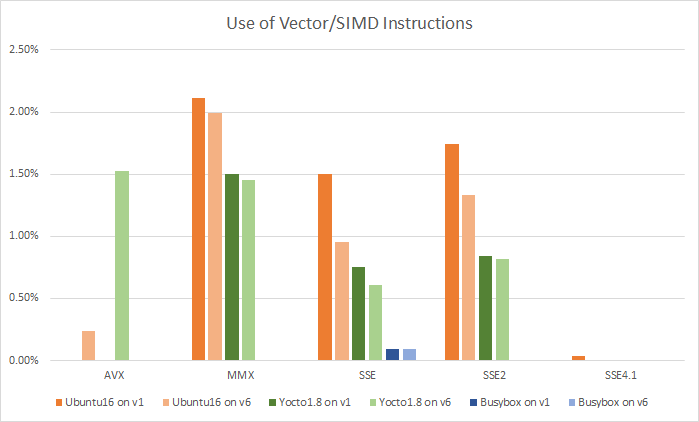
The first thing that catches your eye is that Busybox doesn't actually use vector instructions. The next interesting observation is that, when changing the first generation processor to the sixth processor, the number of older instructions decreases, and the number of new ones increases. In particular, the replacement of old SSE instructions with newer AVX and AVX2 is traced.
As stated at the outset, it was not difficult to conduct this study using Simics. Obviously, Simics has access to all instructions running on all processors in the simulated system (these experiments were conducted on a dual-core system, however, the second core did not execute any instructions at boot time). The scenarios were fully automated, including the selection of the device on which the OS is installed, the user name and password at the end of the download. Each script was run once, as repeated launches will show exactly the same results (we examine repetitive scenarios, starting from the same place).
It was instructive to learn how software stacks adapt and use new instructions on newer processors. Modern programs are adaptive and will execute different code depending on the hardware used without recompilation. In all studied scenarios, the same software stack was used on different simulated systems, while using different instructions depending on their availability. The study is an excellent example of data that can easily be obtained using simulation, but can hardly be collected on real equipment.
New instructions, such as Intel Software Guard Extensions (Intel SGX) and Intel Control-flow Enforcement Technology (Intel CET) , are also able to provide completely new functionality.
The good question is how soon the new instructions added to the architecture reach the end user. Can operating systems and other applications take advantage of new instructions , taking into account that they usually provide backward compatibility and the ability to run independently of the installed processor model? Many years ago, the use of new instructions was achieved by rebuilding the program for the new architecture and adding checks that prevent starting on old hardware and printing something like “sorry, this program is not supported on this hardware”.
')
I used Wind River Simics full-platform simulator to find out to what extent modern software can use new instructions, while remaining compatible with old hardware.
Experimental setup
To find out how software can dynamically adapt to different hardware, I used the Simics model of the “generic PC” platform and two different processor models: the first generation Intel Core i7 (codename Nehalem, released late 2008) and the Intel Core i7 sixth generation (codename Skylake, released in mid-2015).
The following Linux boot scripts were run that run on the configurations described above:
- Ubuntu 16.04, kernel version 4.4, year of release 2016,
- Yocto 1.8, kernel version 3.14, year of release 2014,
- Busybox with kernel 2.6.39, year of release 2011.
The same disk image was used for testing, thereby ensuring that the software stack remains unchanged. Only the configuration of the processor in the virtual platform differed. It was expected that Linux, running on newer hardware, would use new instructions. Each configuration was launched with the connected instrumentation mechanism, which counted how many times each instruction was executed. The mechanism for instrumentation existing in Simics does not change the behavior of guest applications and allows studying the loading of the BIOS and operating system kernels due to the fact that it operates at the level of processor commands. At the same time, the executing application cannot determine whether it is running with or without a tool. Each configuration was executed in 60 seconds of virtual time. This is enough to load the BIOS and operating system. After each launch, 100 most frequently used instructions were selected, which were used for further analysis.
Learning the basics of processor identification
The basis of this work is the assumption that the software can dynamically adapt the executable code depending on the equipment used. That is, the same binary structure can use different instructions on different hardware.
In order to understand how this dynamic adaptation works, you need to understand how iron works. Far in the past, when there were few processors and new models appeared quite rarely, the software could easily check whether the performance was on Intel 80386 or 80486, Motorola 68020 or 68030 and adapt its behavior accordingly. Now there is a huge variety of systems. To solve the problem of identification on IA-32 processors, you should use the CPUID instruction , which itself is a complex system that describes various aspects of equipment.
You, for certain, already met the information received by means of the CPUID instruction, without even thinking of its source. For example, the Task Manager in Microsoft Windows 8.1 shows information about the type of processor and some of its other characteristics, which are obtained using the CPUID instruction:
On Linux, the "cat / proc / cpuinfo" command can display comprehensive information about the processor, including the flags of the command set extensions that are available on the current system. Each extension has its own flag, the presence of which the software should check before the start of execution. Here is an example of information collected on the fourth generation Intel Core i5 processor:
CPUID provides information on the various instruction set extensions available in the processor, but how does the software actually use these flags to select the appropriate binary code depending on the hardware? It would not be wise to use an “if-then-else” construct in every place that is going to use “non-standard” instructions. It is enough to do the check only once, since these characteristics will not change during the session.
Linux usually uses function pointers that use different instructions to implement the same functionality. A good example can be found in the file arch / x86 / crypto / sha1_ssse3_glue.c (source elixir.free-electrons.com/linux/v4.13.5/source ):
These functions check for certain functionality and register the corresponding hash function. The order of the call ensures that the most efficient implementation will be used. Specifically, in this case, the best solution is based on SHA-NI extension instructions , but if they are not available, AVX or SSE implementations are used.
results
The graph below shows the results of running six different configurations (two processors and three operating systems). It shows all the instructions, the number of which exceeds 1% of the total number in any launch. "V1" means the launch of the first generation on the Core i7, the "v6" - the sixth.
The first conclusion that suggests itself: most of the instructions are not very new. Rather, they refer to the basic instructions added back in Intel 8086: move, compare, jump, and add. For newer instructions, the name of the extension in which they were added is written in parentheses. A total of six more or less new instructions in the list of the 28 most frequently used ones.
Obviously, there are variations between different versions of Linux in addition to variations caused by using different processors. For example, BusyBox, configured with the old kernel, uses the LEAVE instruction, which is not popular with other kernel versions, and it also uses the POP instruction much less. However, this does not answer the question of how software uses new instructions when they are available. For our goal, the most interesting variations are caused by a change in the processor generation when the same software stack is started.
All of the scenarios studied in this work are loading the Linux operating system with different kernel parameters. In addition, different distributions can be compiled by different versions of the compiler using different flags. Thus, a binary code, even compiled using the same source code, may differ.
On the example of Yocto, we see this effect. Yocto uses ADCX, ADOX and MULX instructions (included in the ADX and BMI2 extensions). This example also demonstrates well the speed at which new instructions can appear in software. These three instructions were added to the fifth generation Intel Core processor, which was released at about the same time as the Linux kernel used in Yocto. That is, support for new instructions was added by the time the processor entered the market. And this is not surprising, since the specification for new instructions is often published before their hardware implementation. That is, the software can pre-adapt its behavior (an interesting article on this topic) to new hardware, often using virtual platforms for debugging and testing.
However, Ubuntu 16.04 with a newer kernel does not use ADX and BMI2, which means that it was configured differently. This may be due to the compiler version or flags, kernel parameters, or a set of installed packages.
Change control flow
Another thing that was interesting to understand - what instructions are used to change the flow of control. The classic rule described in the no less classic book by Hennessy and Patterson says that every sixth instruction is Jump. However, the measurements showed that approximately one of the five instructions is an instruction that modifies the control flow. Closer to one of six for Yocto.
Vector instructions
Perhaps the most well-known command-line extensions to the public are Single Instruction Multiple Data (SIMD) or, in other words, vector instructions. Vector instructions are present in IA-32 processors, starting with the MMX extension added to the Intel Pentium in 1997. Now the presence of MMX instructions is actually guaranteed. You may notice that some of them are present on the graph of the most popular instructions. Further, many different streaming SIMD Extensions (SSE) instructions and the most recent AVX, AVX2 and AVX512 were added.
I did not expect a large number of vector instructions, considering that the boot of the operating system and the BIOS were studied. However, approximately 5-6% of the executed instructions turned out to be vector. The number of executed vector instructions, measured as a percentage of the total number of instructions executed and grouped by extensions:
The first thing that catches your eye is that Busybox doesn't actually use vector instructions. The next interesting observation is that, when changing the first generation processor to the sixth processor, the number of older instructions decreases, and the number of new ones increases. In particular, the replacement of old SSE instructions with newer AVX and AVX2 is traced.
Simics
As stated at the outset, it was not difficult to conduct this study using Simics. Obviously, Simics has access to all instructions running on all processors in the simulated system (these experiments were conducted on a dual-core system, however, the second core did not execute any instructions at boot time). The scenarios were fully automated, including the selection of the device on which the OS is installed, the user name and password at the end of the download. Each script was run once, as repeated launches will show exactly the same results (we examine repetitive scenarios, starting from the same place).
Conclusion
It was instructive to learn how software stacks adapt and use new instructions on newer processors. Modern programs are adaptive and will execute different code depending on the hardware used without recompilation. In all studied scenarios, the same software stack was used on different simulated systems, while using different instructions depending on their availability. The study is an excellent example of data that can easily be obtained using simulation, but can hardly be collected on real equipment.
Source: https://habr.com/ru/post/342282/
All Articles