Storage. Multi-tier software-defined storage. Why, why, and how is implemented using the example of the MIRhosting cloud
The topic of clouds has recently become more and more in demand. Now, even in the Russian Federation, companies increasingly understand why they can use this cloud and even begin to actively use it. The more companies are interested in the clouds, the more questions arise for us, software developers for the cloud, on the implementation of new trends and technologies, and on service providers that provide the fault-tolerant work of the platform as a whole.
In this article, I would like to share the experience of only one of the sides of the cloud, but at the same time, perhaps the most complex and important is the implementation of disk space. The article was prepared by Andrey Nesterenko, an expert on cloud technologies at MIRhosting , which is one of the hosting providers using Jelastic PaaS, who last month announced the opening of a third region of the cloud platform - in Russia.

First, some background information on how the cloud platform works as a whole. Yes, we are talking specifically about the cloud platform, and not about selling VPS and naming this action Cloud. In our understanding, the key differences are fault tolerance (which, in particular, automatically excludes the use of local data storage), access to the “unlimited” resource pool at any time, and payment upon the use of these resources, and not for limits or tariffs. The technical implementation of such a cloud requires the collaboration of all elements: equipment, network, orchestration, technical support.
Below we describe how we implemented only one component - fault-tolerant disk space.
')
Technologically, data storage runs on Virtuozzo Storage . For those who are not familiar with the idea is similar to other implementations of SDS, the most well-known open source solution is Ceph. The choice of Virtuozzo Storage, rather than Ceph, is primarily related to commercial support and development, better performance characteristics , and “sharpened” live container migration and, as a result, the resiliency of these containers. Also an important reason was that Jelastic offers this integration with VZ SDS out of the box. I will write about Virtuozzo Storage, but with a few changes. All this can be applied to Ceph, and to other similar solutions.
So, architecturally in Virtuozzo Storage there are 2 components: Metadata Servers and Chunk Servers. Data is cut into so-called chunks, i.e. essentially binary "chunks". These "pieces" are smeared over Chunk Servers, which can and should be as much as possible. In practice, Chunk Servers is a separate drive (no matter if the HDD or SSD or NVME), that is, if we have one server with 12 drives, then we will have 12 Chunk Servers that provide RAID 0 performance. Of course, there should be several such separate servers to ensure fault tolerance, 5 - the minimum recommended number. The more servers and chunks on them, the better the performance and faster replication in case of failure of individual chank servers.
The server metadata, respectively, manages all this mess from chunks of data spread across multiple chunk servers. Only one metadata server is required for correct operation, but if it fails, the entire cluster will become inaccessible. On the other hand, the more metadata servers, the more sags performance, since any i / o cluster action should be recorded on more and more servers. There is also a classic problem with split brain: in case of failure of one or several metadata servers, the rest should remain in the “majority” in order to be guaranteed active and unique. Usually, 3 metadata servers are made for small clusters, and 5 for larger ones.
This is what a typical cluster looks like:

(picture from the blog Virtuozzo, I think the guys will not mind)
The cluster administrator can set in the global settings how many replicas should be guaranteed to be available. In other words, how many server chunk can fail without data loss? Suppose we have physically 3 servers, each of which has 3 disks (chan-server) and we set the recommended value: 3 replicas. The first thing that comes to mind is: what happens if one entire server fails and, accordingly, 3 chank servers on it?
If 3 replicas of some data were recorded just on these 3 chank servers within one physical server, then these data will be lost, despite the fact that we still have 2 physical servers online with 6 chank servers on them. To manage this situation, you can configure different levels of replication: at the chunk server level (not recommended), at the host level (by default) or at the rack level and at the building / location level.
Returning to our example above, when using the default values - at the host level, the metadata servers automatically determine which chank servers are located on the same physical servers, and provide replication to different physical machines. In order for replication to work at the rack or location level, you need to specify which machine is in which rack and / or location. In this case, fault tolerance will work at the level of different racks or even data centers. This is exactly what we have done at MIRhosting: the data is divided into 2 independent data centers.
So, using such SDS technologies, we get theoretically perfect fault tolerance, however, theory and white paper on the site is one thing, and practice and demanding customers are another
The first thing you have to face is a network. In a normal situation, the traffic between chunk servers is about 200 mbps and rarely exceeds 500 mbps. The more servers, the more traffic is “smeared” across different servers. But in case of failure of chank-server / servers, urgent replication begins to restore the correct balance of data. And the more servers we have, the more data is gone, the more data begins to fly over the network, easily creating 5 Gbps and higher. So, 10 Gbps network is the minimum requirement, as well as 9000 MTU (Jumbo frames). Of course, if we want to provide really good fault tolerance and overall stability, it is better to have two separate 10 Gbps switches and connect each data store through 2 ports.

By the way, this at the same time solves such a complex issue as updating the firmware in the switches.
The second thing we decided was to ensure the operation of the cluster on the basis of dual data centers. Initially, the network for the data warehouse worked on pure L2. However, with the growth of the cloud platform as a whole and the amount of data storage as its component, in particular, we came to a logical decision that we need to switch to pure L3. This step is very much tied to another topic - the work of containers in the conditions of dual data centers and live migration. The network for the data storage was made similarly to the internal and external network of containers, for unification. The topic is worth a separate article, I hope it will be interesting to the community. No performance degradation with the transition to L3 was observed.
The third and probably most important thing is performance. Clients are different, they have different requirements, different projects, and in the conditions of a public cloud this becomes a complex problem. In itself, this is divided into 2 parts: the overall performance of the i / o cluster and the various required performance for different clients. Let's start with the first.
In many ways, the solution of the performance issue was carried out using the “spear method”, since neither in the documentation nor in the information from the Virtuozzo technical support, there are no such best practices as such. One support staff member of Virtuozzo, who spent 30 minutes of his time on the phone and told a lot of things, helped a lot. Having collected all the available information, adding a little brain and passing through the colander of experience, we came to the following scheme:

Compute Node (node where containers are started) - the system runs on SSD, it also hosts pfcache. The second SSD, and recently NVMe - under the client’s cache. And one or two SSD / NVMe for local chunks. Using RAID1 is possible, but it seems to us at this stage in the development of SSD drives that are of no particular importance, given the automatic recovery of containers at failover in any case. Client cache has less effect than chunk on compute node. The system determines the nearest available chunk and tries to use it for “hot” data.
Storage Node (node, which is used only for chunks, without containers), obviously, is filled with SSD and NVMe. HDD is historically still used, in fact, to provide "cold" replicas.
HDD caching is not used, and we are already trying to completely replace HDDs with SSDs. Those storage systems that still have HDDs are sure to work through a good raid card, RAID0, with a caching write operation, which improves the performance of these HDDs.
The overall available cluster performance depends directly on the number of chunks, i.e. drives.
The second task is the need to regulate i / o in the conditions of a public cloud and various customer requests. Each container in the cloud is assigned certain i / o limits on the number of operations (iops) and bandwidth (io limit through traffic). At the moment, the cloud MIRhosting gives the default 500 iops and bandwidth of 200 Mb / s, which is almost equal to the double performance of the SATA HDD drive. For the vast majority of customers, these numbers are more than enough, given that these limits are given for each container, which the customer can create in any quantities.
However, some customers require increased i / o performance. Obviously, this is solved by different limits for different clients. But it is not economically profitable to have a cluster capable of giving, say, 10,000 iops per container (and having the appropriate stock), and selling its resources with lower limits.
There is a good solution - it is the ability to use different levels in the data warehouse. Let's say the first level will be built on SSD + HDD, and the second level will be built on SSD + NVMe.
We will provide the stated characteristics and make it economically viable (which is directly related to the cost). The transfer of containers from one level to another occurs “live” and is implemented in Jelastic PaaS as well as hourly pay, like other cloud resources.
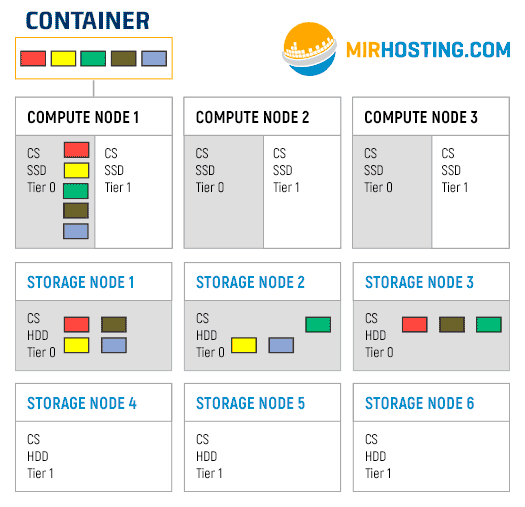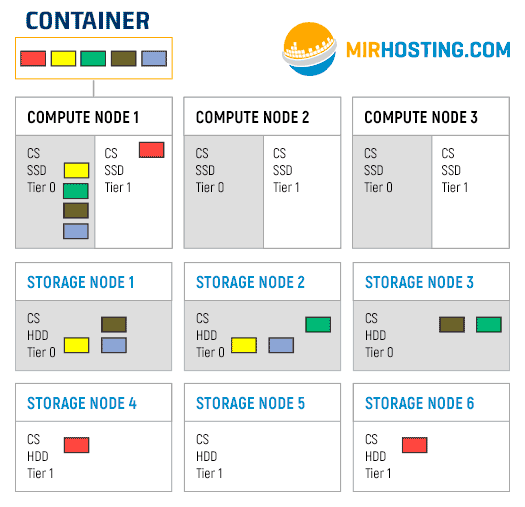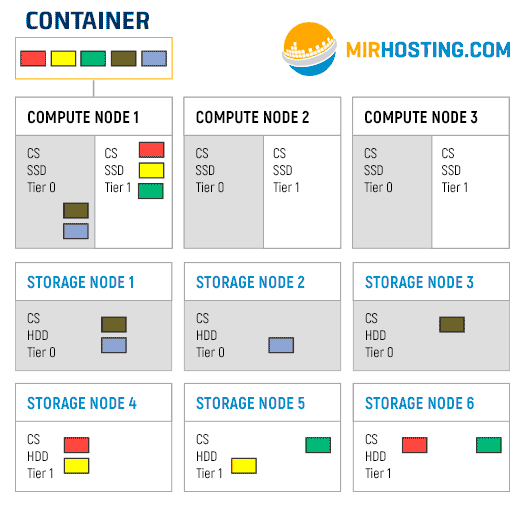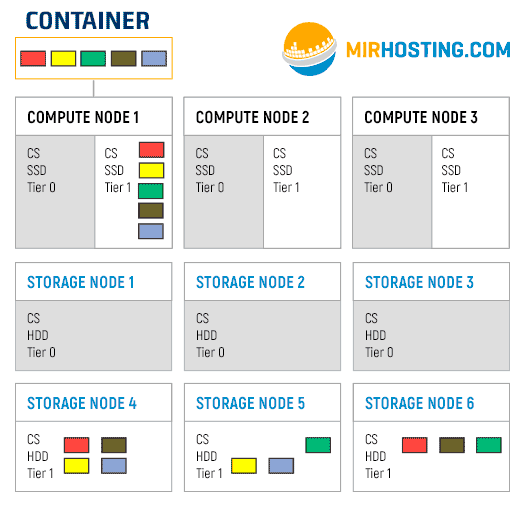
Suppose we have one container, which is located on the first Compute node. Its file system is divided into 5 chunks. We also have a cluster configured to use 3 replicas, that is, each chunk will be hosted on 3 different servers. The first slide of the gif is how the chunks will be placed when placed on tier 0. The following shows the process of crawling chunks onto Tier 1 carriers.
At the moment, cloud storage resources are quite stable and difficult to imagine how you can live differently. The failure of disks, and even the entire node, does not create any visible problems for customers and requires planned actions to replace and add disks.
PS Already in the process of preparing this material, an article was published habrahabr.ru/post/341168 , in which similar issues and topics are discussed. Our article reflects a slightly different view on the same tasks and problems, and I would like to hope that it will be useful to the community.
The mentioned drawbacks in the article would also be interesting to consider separately, but most of these drawbacks are not related to the data storage itself, but to the more global work of the cloud, in particular with migration issues.
If the topic is interesting, we can share our own developments on the work of containers within the cloud on the basis of dual data centers. In particular, from the network and live migration under such a scheme.
In general, I have to agree with SyCraft that there are bugs, and the technical support of Virtuozzo cannot always clearly say what is happening and why. Nevertheless, this solution, in fact, is the only one in its class, which provides the necessary set of services, is actively developing and is commercial, that is, supported by developers.
You can try this solution of fault-tolerant disk space in combination with automatic distribution and orchestration of containers, taking into account the specifics of a specific application from Jelastic PaaS, as well as the performance of the MIRhosting infrastructure by registering with the link . We welcome your feedback.
In this article, I would like to share the experience of only one of the sides of the cloud, but at the same time, perhaps the most complex and important is the implementation of disk space. The article was prepared by Andrey Nesterenko, an expert on cloud technologies at MIRhosting , which is one of the hosting providers using Jelastic PaaS, who last month announced the opening of a third region of the cloud platform - in Russia.
First, some background information on how the cloud platform works as a whole. Yes, we are talking specifically about the cloud platform, and not about selling VPS and naming this action Cloud. In our understanding, the key differences are fault tolerance (which, in particular, automatically excludes the use of local data storage), access to the “unlimited” resource pool at any time, and payment upon the use of these resources, and not for limits or tariffs. The technical implementation of such a cloud requires the collaboration of all elements: equipment, network, orchestration, technical support.
Below we describe how we implemented only one component - fault-tolerant disk space.
')
Software-defined storage (SDS)
Technologically, data storage runs on Virtuozzo Storage . For those who are not familiar with the idea is similar to other implementations of SDS, the most well-known open source solution is Ceph. The choice of Virtuozzo Storage, rather than Ceph, is primarily related to commercial support and development, better performance characteristics , and “sharpened” live container migration and, as a result, the resiliency of these containers. Also an important reason was that Jelastic offers this integration with VZ SDS out of the box. I will write about Virtuozzo Storage, but with a few changes. All this can be applied to Ceph, and to other similar solutions.
So, architecturally in Virtuozzo Storage there are 2 components: Metadata Servers and Chunk Servers. Data is cut into so-called chunks, i.e. essentially binary "chunks". These "pieces" are smeared over Chunk Servers, which can and should be as much as possible. In practice, Chunk Servers is a separate drive (no matter if the HDD or SSD or NVME), that is, if we have one server with 12 drives, then we will have 12 Chunk Servers that provide RAID 0 performance. Of course, there should be several such separate servers to ensure fault tolerance, 5 - the minimum recommended number. The more servers and chunks on them, the better the performance and faster replication in case of failure of individual chank servers.
The server metadata, respectively, manages all this mess from chunks of data spread across multiple chunk servers. Only one metadata server is required for correct operation, but if it fails, the entire cluster will become inaccessible. On the other hand, the more metadata servers, the more sags performance, since any i / o cluster action should be recorded on more and more servers. There is also a classic problem with split brain: in case of failure of one or several metadata servers, the rest should remain in the “majority” in order to be guaranteed active and unique. Usually, 3 metadata servers are made for small clusters, and 5 for larger ones.
This is what a typical cluster looks like:
(picture from the blog Virtuozzo, I think the guys will not mind)
The cluster administrator can set in the global settings how many replicas should be guaranteed to be available. In other words, how many server chunk can fail without data loss? Suppose we have physically 3 servers, each of which has 3 disks (chan-server) and we set the recommended value: 3 replicas. The first thing that comes to mind is: what happens if one entire server fails and, accordingly, 3 chank servers on it?
If 3 replicas of some data were recorded just on these 3 chank servers within one physical server, then these data will be lost, despite the fact that we still have 2 physical servers online with 6 chank servers on them. To manage this situation, you can configure different levels of replication: at the chunk server level (not recommended), at the host level (by default) or at the rack level and at the building / location level.
Returning to our example above, when using the default values - at the host level, the metadata servers automatically determine which chank servers are located on the same physical servers, and provide replication to different physical machines. In order for replication to work at the rack or location level, you need to specify which machine is in which rack and / or location. In this case, fault tolerance will work at the level of different racks or even data centers. This is exactly what we have done at MIRhosting: the data is divided into 2 independent data centers.
Enough theory, tell something really interesting.
So, using such SDS technologies, we get theoretically perfect fault tolerance, however, theory and white paper on the site is one thing, and practice and demanding customers are another
The first thing you have to face is a network. In a normal situation, the traffic between chunk servers is about 200 mbps and rarely exceeds 500 mbps. The more servers, the more traffic is “smeared” across different servers. But in case of failure of chank-server / servers, urgent replication begins to restore the correct balance of data. And the more servers we have, the more data is gone, the more data begins to fly over the network, easily creating 5 Gbps and higher. So, 10 Gbps network is the minimum requirement, as well as 9000 MTU (Jumbo frames). Of course, if we want to provide really good fault tolerance and overall stability, it is better to have two separate 10 Gbps switches and connect each data store through 2 ports.
By the way, this at the same time solves such a complex issue as updating the firmware in the switches.
The second thing we decided was to ensure the operation of the cluster on the basis of dual data centers. Initially, the network for the data warehouse worked on pure L2. However, with the growth of the cloud platform as a whole and the amount of data storage as its component, in particular, we came to a logical decision that we need to switch to pure L3. This step is very much tied to another topic - the work of containers in the conditions of dual data centers and live migration. The network for the data storage was made similarly to the internal and external network of containers, for unification. The topic is worth a separate article, I hope it will be interesting to the community. No performance degradation with the transition to L3 was observed.
The third and probably most important thing is performance. Clients are different, they have different requirements, different projects, and in the conditions of a public cloud this becomes a complex problem. In itself, this is divided into 2 parts: the overall performance of the i / o cluster and the various required performance for different clients. Let's start with the first.
In many ways, the solution of the performance issue was carried out using the “spear method”, since neither in the documentation nor in the information from the Virtuozzo technical support, there are no such best practices as such. One support staff member of Virtuozzo, who spent 30 minutes of his time on the phone and told a lot of things, helped a lot. Having collected all the available information, adding a little brain and passing through the colander of experience, we came to the following scheme:
Compute Node (node where containers are started) - the system runs on SSD, it also hosts pfcache. The second SSD, and recently NVMe - under the client’s cache. And one or two SSD / NVMe for local chunks. Using RAID1 is possible, but it seems to us at this stage in the development of SSD drives that are of no particular importance, given the automatic recovery of containers at failover in any case. Client cache has less effect than chunk on compute node. The system determines the nearest available chunk and tries to use it for “hot” data.
Storage Node (node, which is used only for chunks, without containers), obviously, is filled with SSD and NVMe. HDD is historically still used, in fact, to provide "cold" replicas.
HDD caching is not used, and we are already trying to completely replace HDDs with SSDs. Those storage systems that still have HDDs are sure to work through a good raid card, RAID0, with a caching write operation, which improves the performance of these HDDs.
The overall available cluster performance depends directly on the number of chunks, i.e. drives.
The second task is the need to regulate i / o in the conditions of a public cloud and various customer requests. Each container in the cloud is assigned certain i / o limits on the number of operations (iops) and bandwidth (io limit through traffic). At the moment, the cloud MIRhosting gives the default 500 iops and bandwidth of 200 Mb / s, which is almost equal to the double performance of the SATA HDD drive. For the vast majority of customers, these numbers are more than enough, given that these limits are given for each container, which the customer can create in any quantities.
However, some customers require increased i / o performance. Obviously, this is solved by different limits for different clients. But it is not economically profitable to have a cluster capable of giving, say, 10,000 iops per container (and having the appropriate stock), and selling its resources with lower limits.
There is a good solution - it is the ability to use different levels in the data warehouse. Let's say the first level will be built on SSD + HDD, and the second level will be built on SSD + NVMe.
We will provide the stated characteristics and make it economically viable (which is directly related to the cost). The transfer of containers from one level to another occurs “live” and is implemented in Jelastic PaaS as well as hourly pay, like other cloud resources.
Suppose we have one container, which is located on the first Compute node. Its file system is divided into 5 chunks. We also have a cluster configured to use 3 replicas, that is, each chunk will be hosted on 3 different servers. The first slide of the gif is how the chunks will be placed when placed on tier 0. The following shows the process of crawling chunks onto Tier 1 carriers.
At the moment, cloud storage resources are quite stable and difficult to imagine how you can live differently. The failure of disks, and even the entire node, does not create any visible problems for customers and requires planned actions to replace and add disks.
PS Already in the process of preparing this material, an article was published habrahabr.ru/post/341168 , in which similar issues and topics are discussed. Our article reflects a slightly different view on the same tasks and problems, and I would like to hope that it will be useful to the community.
The mentioned drawbacks in the article would also be interesting to consider separately, but most of these drawbacks are not related to the data storage itself, but to the more global work of the cloud, in particular with migration issues.
If the topic is interesting, we can share our own developments on the work of containers within the cloud on the basis of dual data centers. In particular, from the network and live migration under such a scheme.
In general, I have to agree with SyCraft that there are bugs, and the technical support of Virtuozzo cannot always clearly say what is happening and why. Nevertheless, this solution, in fact, is the only one in its class, which provides the necessary set of services, is actively developing and is commercial, that is, supported by developers.
You can try this solution of fault-tolerant disk space in combination with automatic distribution and orchestration of containers, taking into account the specifics of a specific application from Jelastic PaaS, as well as the performance of the MIRhosting infrastructure by registering with the link . We welcome your feedback.
Source: https://habr.com/ru/post/342278/
All Articles