Intel processor frequency control rakes
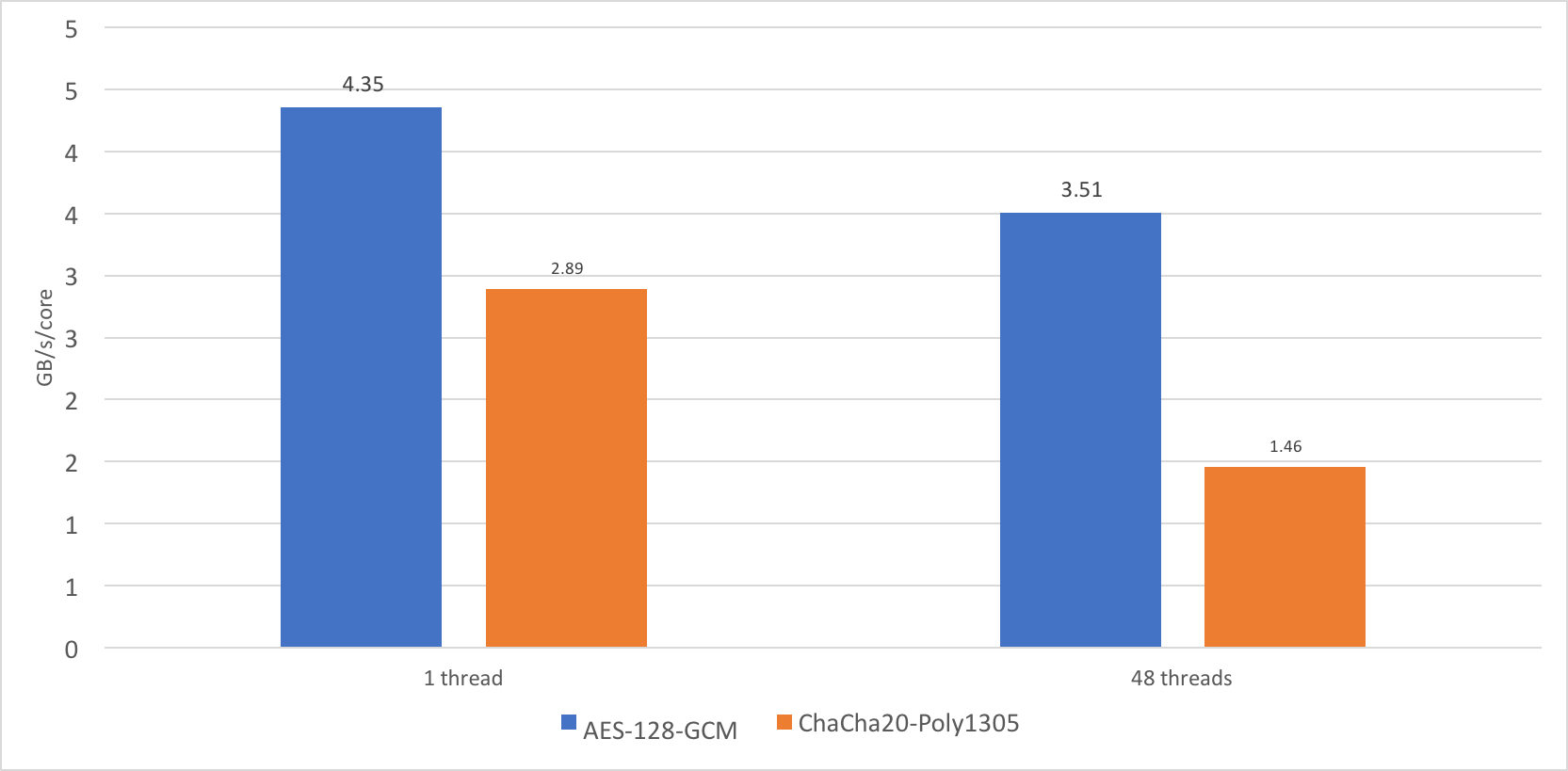
When comparing the Qualcomm Centriq server chip with the existing Intel Xeon Skylake generation, I noticed a strange thing: the performance of the ChaCha20-Poly1305 cipher doesn’t scale well when adding cores. One stream worked at a speed of approximately 2.89 GB / s, and on 24 cores and at 48 threads, the total performance was only 35 GB / s.
Not bad, of course, but I expected to see something like 69 GB / s. 35 GB / s is only 1.46 GB / s per core, or about 50% of the performance of a single core. AES-GCM is much better scaled under the same conditions, up to about 80% of the performance of a single core, which is explained by the ability of the processor to increase the frequency under load on one core.

Why does the ChaCha20-Poly1305 scale so badly? Check out the AVX-512 instruction set, which extends most existing SIMD instructions to 512 bits and adds a few new ones. The problem is that they consume a significant amount of energy, because in one go you need to perform from 8 to 64 normal operations.
To keep power consumption at an acceptable level, Intel in the Haswell processor family 3 years ago introduced a dynamic frequency change. This mechanism reduces the base frequency of the processor in the case of execution of AVX2 or AVX-512 instructions. If only the AVX-512 code is executed, everything is in order. The frequency is lower, but the total number of operations performed per unit of time is greater.
OpenSSL 1.1.1dev contains several implementation options for the ChaCha20-Poly1305, including the use of AVX2 and AVX-512. BoringSSL implements the algorithm in a slightly different way and only using AVX2, so its performance on a single core is only 1.6 GB / s instead of 2.89 GB / s in OpenSSL.
What effect does this have in a situation where the load is a mixture of conventional calculations and a small fraction of calculations using the AVX-512? We use Xeon Silver 4116 with a base frequency of 2.1 GHz in a two-socket configuration. The table found on wikichip shows that the execution of AVX-512 instructions even on one core will reduce the base frequency to 1.8 GHz, and the execution of instructions on all cores will reduce the base frequency to 1.4 GHz.
Imagine that we have a web server (Apache or NGINX), which also runs applications. The question arises: what will happen if we start to encrypt traffic using the ChaCha-Poly1305 algorithm implemented using the AVX-512 instructions?
I compiled two versions of NGINX: one with OpenSSL 1.1.1dev, the other with BoringSSL - and installed them on a server with two Xeon Silver 4116, receiving a total of 24 cores. The web server is configured to process and return a medium-sized HTML page. LuaJIT was used to remove line breaks and extra whitespace, as well as compressing the page with the brotli algorithm. Then I measured the number of requests that the server was able to handle at full load.

When using ChaCha20-Poly1305 instead of AES-GCM, the webserver compiled with OpenSSL served 10% fewer requests, which is equivalent to idle two processor cores. It can be assumed that such a difference is observed due to the low speed of the ChaCha20-Poly1305 algorithm itself, but this is not the case.
First, BoringSSL performed equally well with both encryption algorithms. Secondly, even when only 10% of requests use the ChaCha20-Poly1305, performance drops by 5.5%, and by 7% if the share of such requests reaches 20%. For reference: in Cloudflare real HTTPS traffic, the share of requests using the ChaCha20-Poly1305 algorithm is 15%.
According to perf, the processor spends only 2.5% of the time on processing AVX-512 instructions with a 100% share of requests from the ChaCha20-Poly1305, and less than 0.3% with a share of such requests of 10%. Regardless of the share of requests, the CPU frequency decreases, because the AVX-512 instructions are executed on all cores at once.
It is difficult to say how much the processor frequency drops at a particular point in time. However, after observing the readings of lscpu , I found out that during the execution of the openssl speed -evp chacha20-poly1305 -multi 48 get CPU MHz: 1199.963 ; for a web server with OpenSSL and AES-GCM algorithm, CPU MHz: 2399.926 obtained CPU MHz: 2399.926 , and for a web server with OpenSSL and ChaCha20-Poly1305 algorithm, CPU MHz: 2184.338 , that is, 9% less.
Another interesting difference is that the ChaCha20-Poly1305 algorithm using AVX2 is a bit slower in OpenSSL, but does not lose in performance in BoringSSL. The reason is that BoringSSL does not use AVX2 multiplication instructions for Poly1305, and for ChaCha20 it uses only relatively simple instructions xor, shift, add, which allows the core to remain at the base frequency.
OpenSSL 1.1.1dev is still in development, so I suspect that this problem has not yet met anyone. We switched to using BoringSSL a few months ago, and the performance of our servers will not suffer from the described effect.
What does the coming day prepare for us? For future generations, Intel has announced a new set of instructions that should further improve the performance of cryptographic operations. These extensions include AVX512 + VAES, AVX512 + VPCLMULQDQ and AVX512IFMA. However, if the problems with lowering the frequency by that time are not resolved, the use of new instruction sets may be more detrimental than good in terms of performance.
The problem is not only and not so much in cryptographic libraries. Authors of OpenSSL cannot be blamed for finding ways to increase performance; on the contrary, I myself wrote a decent amount of OpenSSL code using AVX-512. Observed behavior is just a sad side effect. There are many libraries that use the AVX-512, and users most likely are not aware of the details of their implementation. If you do not need to use the AVX-512 for specific computationally intensive tasks, I suggest you turn off their support on your servers and personal computers in order to avoid an undesirable decrease in the processor frequency.
Of course, these facts are described in the guidance documentation: the frequency reduction itself is described in Optimizing Performance with Intel Advanced Vector Extensions , and the limits of its change depending on the number of cores occupied for the specific Skylake processor in the Intel® Xeon® Processor Scalable Family Specification Update . However, these documents are not for the general public in the sense that few read about and even know about their existence, and not all that I would like to know is described there. I was not able to find, for example, the official description of the work of the PCU and the frequency reduction algorithm itself when executing the instructions of the AVX-512 and its increase after.
Habré already had articles that discussed the use of AVX-512 in development (for example, How I made the fastest image resize. Part 2, SIMD ). I find it very useful to know about the nuances of the behavior of modern processors and system administrators too (no matter how they are called now), therefore, I publish the translation to the hub System Administration.
Explanation: The translator is not affiliated with Cloudflare, Inc. The translation is made out of love for art, all rights are with their owners. Written by KDPV blumblaum , CC BY-SA 2.0. The title came up with CodeRush .
')
Source: https://habr.com/ru/post/342272/
All Articles