Sir Markdown. Yandex lecture
When developing documentation, we are guided not only by standards, but also by the convenience of its use. Standards determine the composition and form of documentation, and the format is based on convenience. Developer Sergey Bocharov talks about the way the Markdown document and the problems that have to be solved in exchange for the ease of use of this format.
- We know that now lies on the scales
And what happens now.
An hour of courage struck on our watch,
And courage will not leave us.
Not scared to lie down under the bullets of the dead,
Not sad to be homeless.
And we will keep you, Russian speech,
Great Russian word.
')
We will carry you free and clean
And give the grandchildren, and save from captivity -
Forever.
Good evening, friends, my name is Sergey Bocharov. I began with Anna Akhmatova's poem “Courage”. It was written in 1942, during the Great Patriotic War, and even then the poetess understood that it would be much easier to return and build the factories and factories broken by the bombing than to return the spiritual wealth that was wasted and actually trampled during the war years.
Poetry is one of the few tools that helps us learn to feel the beautiful. Today we are talking about technical documentation - it would seem such a far from poetry, but preserving the beautiful, maintaining a single style is very important, especially when working with this format. Markdown has de facto become the standard for writing technical documentation in the open source world. And united people of different specialties.
I have a hard and at the same time pleasant mission. I want you to have the full sense of assembling Markdown documentation in Yandex, and also to share the tools that we developed. I hope you will use them in your projects too.
The tools that are developed are written in JS, because we in Yandex love JavaScript. And all development is conducted around this language. You shouldn't be upset here if you have another development environment or a HYIP React - I think you can find analogues on GitHub.
Perhaps many wonder why Markdown became sir? This is a metaphor, and it is connected with the fact that we in Yandex are trying to robotize any process.
A large number of tools are also being developed around Markdown. To date, we have already developed a lot of tools, we continue to develop. I sometimes get the impression that it does not serve for us, but we serve for this format. Therefore - Sir Markdown.
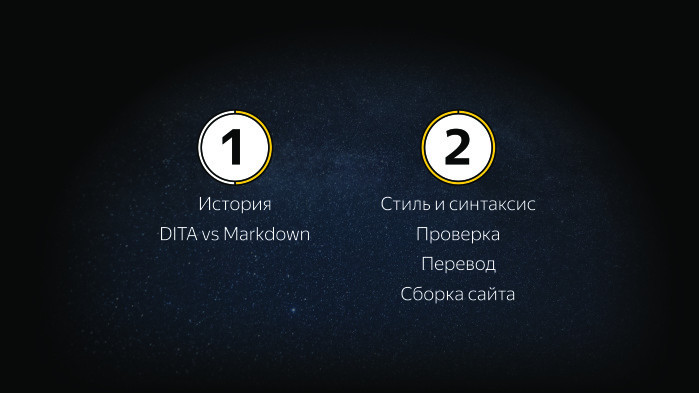
In the first global part we will talk about why we are writing in this format, why we are developing some tools for it. In the second part, we will discuss in more detail the example of our library on how to maintain the quality of the content, how to translate it, and how to assemble one site from many repositories.
Markdown was created in 2004 by John Gruber and Aaron Schwartz. The idea was to have a simple textual syntax and then convert it to richer and more valid HTML.

We have a heading of the first level, the second level and some paragraph of text.
Why a new format when there is a DITA with richer tools? Why create new tools for Markdown? Let's try to answer together.

DITA has a more complex syntax, and to work with it, it is desirable to have a specific development environment. It is clear that this is an XML format, it also opens in a text editor. But SVG also opens in it, while no one draws there - everyone uses Photoshop or Sketch.
Markdown, to the exact opposite, has a lighter syntax, which is why it was so much loved by many developers. As a result, the documentation in Markdown is written and maintained by a technical writer with the active participation of contributors and developers, and documentation in DITA is often developed only by a technical writer, developers and contributors do not actively participate.
A striking example of the Markdown documentation site is the npm site, today it contains 475,000 modules, and every day there are more and more of them.

Here are the most popular ones. If you go to any site, for example Gulp, and go to the documentation section, we immediately get to GitHub, where we see that the gulp.js API is described in Markdown.
Therefore, if for some reason you are not yet using Markdown or bypassing it, please use and make your developers happy.
Style and syntax. I propose to consider the example of our internal library of Lego, super-secret. Now I will demonstrate.

Suddenly, right? All these blocks are different. Here is the block logo, teaser, etc. And they are stored on GitHub, the standard de facto.

There is a general description of the library, there are also directories of blocks, and in each directory there is a description of this block. We view the documentation as part of the code, so we call it the appropriate name. It is also convenient in case of replacement, search & replace. Once upon a time a technical writer worked on every document. The translator also worked on the English versions, and ideally the documentation, the Russian and English versions, should be consistent, that is, they should have the same structure and content.
The developers themselves are also actively working on the documentation, there are a lot of them. The process that we are trying to build in the company is as follows: the developer, having developed a new functionality or a new unit, sets the task for the technical writer in the form of a pull request or issue.
The technical writer describes this functionality, and then returns it for translation if a language version of the document is needed. And everyone is happy, but this is a perfect world. And in the real world, the situation is often the following: the developer himself comes in and makes changes to the documentation.

Here we are faced with the first problem - loss of consistency. The next problem is also changing the style of writing documentation.

It seems - think, the main thing is that the functionality is described. It turns out no. After the document was written by a technical writer, the developers were happy.
Then, when a few dozen more developers came there with their commits, they were already pondered and eventually wept. They say - you need to rewrite the document, it has become incomprehensible, it is impossible to read it, there are a lot of different incomprehensible constructs, ghouls, problem text markers.
They need to somehow be able to fight. Technical writers know and are able to deal with them, and developers often allow them in the documentation, and such documentation is uncomfortable to read.

For example, is everyone comfortable here? Everyone understands what it is about? Obviously, this is git, and this is found in our documentation. Here is a clearer option.

Developers who have little experience with GitHub sometimes encounter difficulties when they read the documentation that the guru developers wrote. Therefore, we add the following problem - the preservation of style and terminology. Developers commit a lot, and the technical writer is almost invisible, the unity of style is broken.
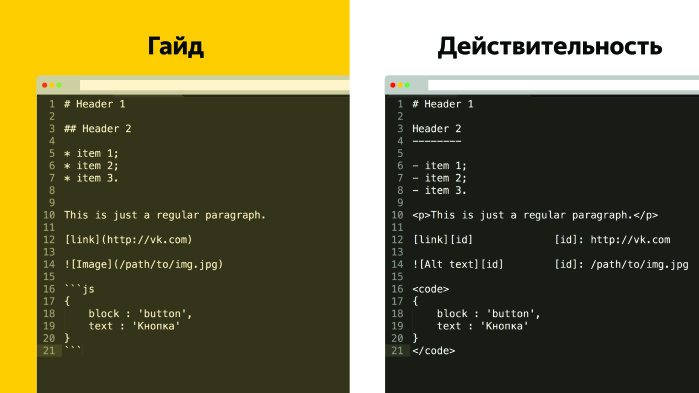
The next problem with this approach is that the syntax is broken. Markdown allows you to write in completely different ways and get the same result. The developers of technical documentation for each case have an agreement on how we write headlines, lists, insert screenshots, etc.
Indeed, the reality is often different from the desired, and this problem also needs to be able to fight. It would seem that the result is expected, but if this problem is not solved now, it will have to be solved at the assembly stage. Often there is a task - for example, to find all third level headers with Backtick and increase by two pixels. If we do not solve it at the linting stage , then we will have to solve it at the assembly stage, to write large scripts.
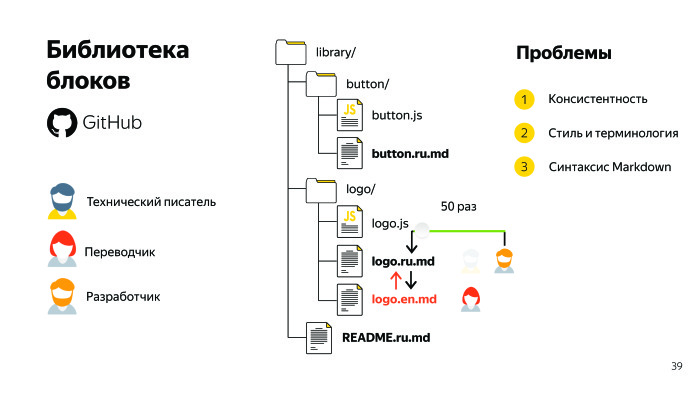
Therefore, we add the following problem - Markdown syntax. We have three main challenges with which we fight. We also have open-source projects, in particular, BEM. Open-source projects have contributors in addition to developers, technical writers and translators. Contributors help make our products better, for which we are grateful. There are a lot of them. They send us their pull requests, and we share quality content with them. Therefore, it is definitely necessary to somehow find solutions.

The next section is about auto-checking, linting. What can be done to somehow learn to consistently check the Markdown syntax, find grammatical errors and markers of the problematic text. This is my favorite section. I think the linting progression works on the progression of a technical writer.
Let's start with a tool called remark-lint. It allows you to check the syntax and style of writing. The remark itself is in the public domain, it was not developed by us, we use it, it has its own set of rules, there are more than 50 of them. We wrote our rules on top of these rules, added our guide to remark.

How it works? Suppose there is a test file with content, there is a heading of the first level, the second and some kind of list.
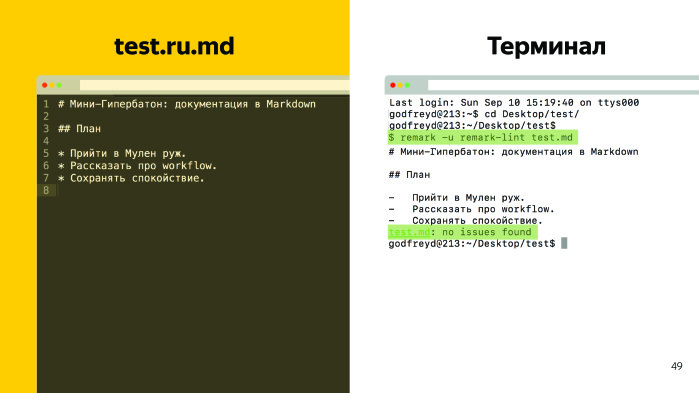
We enter a command in the terminal. This is the command we have on the precommute is being processed, I show. When a technical writer commits on GitHub and the document is in order, a message is displayed that there are no errors. And the commit goes to GitHub. Suppose we have mistakes - for example, we make the second level in the first heading, and in the second heading we add “Hello” and an exclamation mark. We execute the same command, and we have three errors.
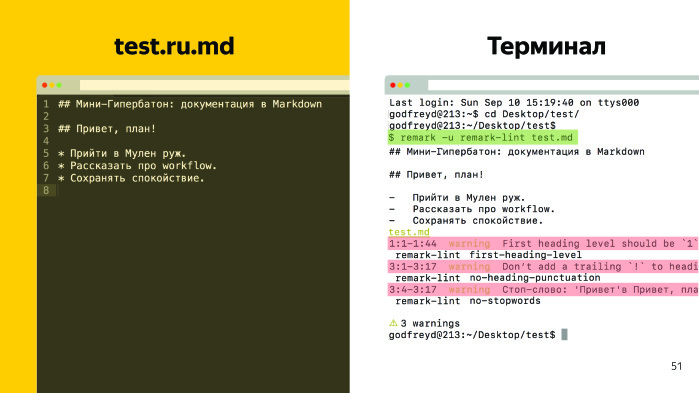
Linting progression works on the progression of a technical writer. A technical writer recalls that we agreed not to put exclamation marks in the headlines, rules, everything is fine. How are these rules connected? At the root of the project lies the remarkrc file, in it we define a set of our own rules (I have shortened them) and a set of borrowed rules of the remark itself.
The next tool is yaspeller. It checks grammar and spelling errors in documentation. Documentation is on Yandex. Technologies - it, by the way, is written in git. You can read it, everything works on the same principle: there is a spelling error - a message is displayed. Contributors, developers who are trying to make you a pull request, send some corrections, they will not be able to send them with spelling errors or inaccuracies in the Markdown syntax. So these tools are very convenient to connect, and they work on prekommite.
The next section is devoted to translation. We developed the md2xliff tool. We translate a lot of open source documentation and a bit of internal. In the case of open-source documentation, we have contributors who send their pull-requests, and to make it easier for them to send them, we make dies for them on our website in which we offer them to follow the link either through the GitHub interface or using the prose service. io. For example, they come in, make changes, click OK, and a pull request arrives.
How does all this support? Suppose a technical writer wrote a document, the translator translated it, the user came - initially into the Russian version - and corrected something there. How to deal with the English version? Is there something to rule there or not? Unclear. How to look for a typo that was corrected is also unclear. Or you can go to GitHub and see the difference there in diff. But this is still a task, you need to put it to the translator. Need to find a solution.

There is a second situation. For example, the developer wrote the second version of the library, and took not the whole document, did not rewrite 30 pages, and then deleted the piece, added there. And if deleted - it is not clear what to do. We have to go and somehow check this into a diff on GitHub.
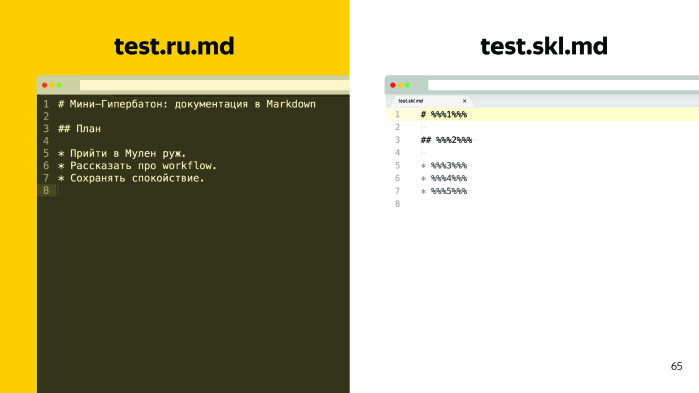
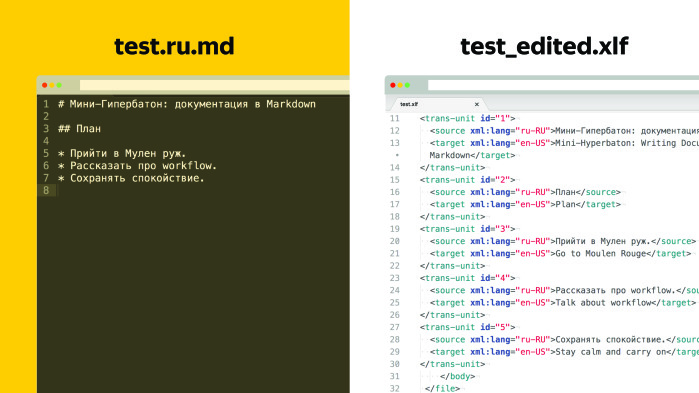
How to be? It seems to be a difficult situation in which there is no way out. However, if any of you have worked with translations, they probably know that there are a lot of standards, and upon closer inspection, the solution looks like this: there is a test file and some text of the documentation that lies on GitHub. What should be done? It is necessary to generate two files from it, a skeleton and a XLIFF translation.


The skeleton is block formatting, that is, we substitute pieces of text for such placeholders with numbers.
XLIFF is a special format, it is described, it has a specification, everything is simple there. The most important thing is that in XLIFF there are units, and the id of the unit corresponds to the segment that we changed in the skeleton.
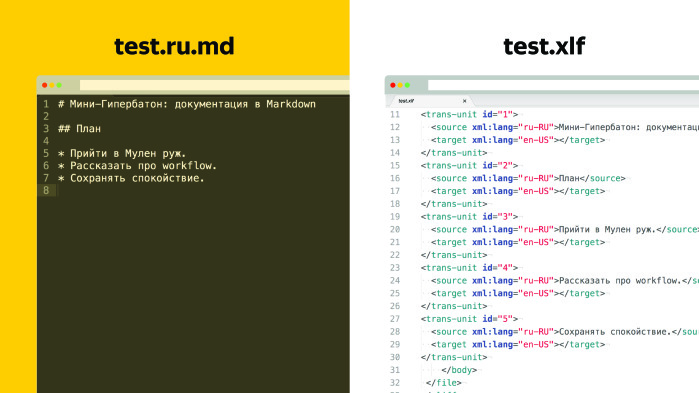
Also there are two tags in each unit: source and target. The source tag contains exactly that piece of text that we replaced in the skeleton, and the target field is initially empty. We give this XLIFF to the translator. The target field is now filled out. After the transfer, we do the reverse generation and get the English version of the document.
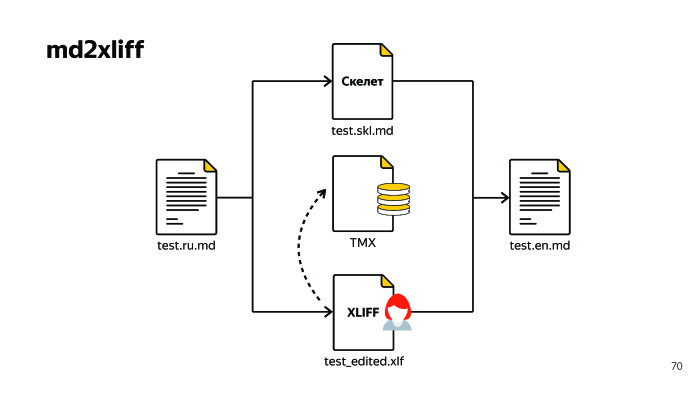
At the same time, the translation here does not disappear anywhere, but is stored in a special standardized XML file TMX. There are two values: source and target. How does this help us? We return to the past situation. Contributors, developers or another technical writer came and corrected something in the source document. In the Russian version, for example.

We still generate XLIFF, give it to the translator, it applies the base that it has saved in the program and translates exactly those segments that have changed. It does not translate strings that have a one-hundred-percent match - they are replaced by an auto-replacement. Thus, there is no longer a problem to look for what has changed. We guarantee that all the lines that have somehow been changed will be visible in the translation. Next, we generate the English version of the document, everything is simple. It seems that there is a ready-made solution - simply because surely they should be.

There is a smartcat.ai from ABBYY, there is a solution from Google and there is Matecat . But the total flaws of these solutions are that they do not support Markdown, which does not have a single standard for how to write. And they bypass it, support any standardized formats. Last week I checked Markdown in matecat, everything is red. Although Markdown was simple.
Take, for example, our tool with a complex nesting. If you have a code, there are three bacteriums inside it, and there is JSDoc there, it handles everything at 99%, the nesting level can be anything.
The second fatal flaw in these services is that they do not integrate with GitHub. We want the user to come to us through the link and correct something, but they are not integrated.
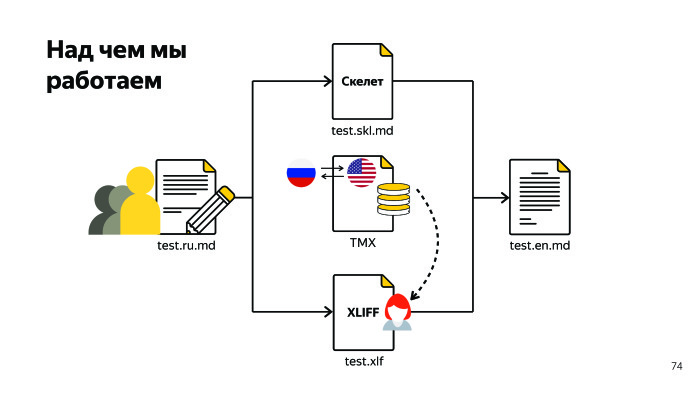
We all discussed this. When there is a source document in Russian, and we translate into another language, we have a certain pair, a tough attachment to the Russian language. We are working to get rid of this attachment so that we can rule TMX on the fly, no matter where the user goes. It can come to the Russian version, and maybe to the English version, and we must deploy the TMX right at the time of generation. Until it is decided.
I propose to consider assembling the site as part of a general review of the path of the Markdown document from the time of writing to the time of laying out on the site.
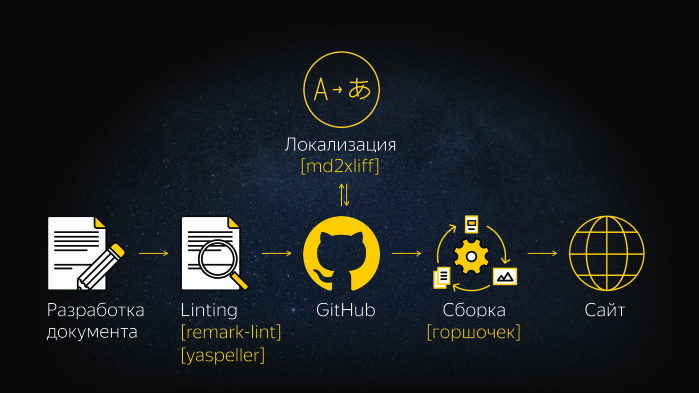
What does the workflow look like? Suppose a work plan has been drawn up, all information has been collected. If we talk about Markdown, it is important to observe the agreement on syntax. After that there is an autocheck, it works out on the precommite of our linings. Further the document gets on GitHub. If you need an English version, we localize the document. After the assembly takes place, and there are two stories. One is when the document is one-to-one per page, and the second is when you need to build various in-line examples. In the page you need to embed an iframe, etc. We have a tool that can do it all, a potty. He is able to substitute links, combine different Markdown documents into one, and is able to build inline examples. Then there is a calculation on the site.
Why do you need a website? Why, as on gulp.js, not to store all documentation in Markdown?

The answer is obvious - we need a single entry point. We have more than a hundred repositories, and we want these documents to be collected in one place. We also need search, navigation and live examples. Live examples look like this.
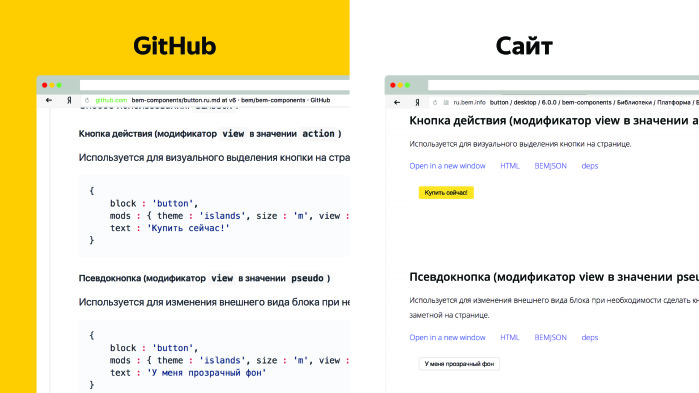
The same document on GitHub and on the site is rendered differently. We can open it in a new window, click on the button, view its HTML. It is very convenient.

What are our recipes? What do you do? In the first place - to determine the needs. If they are similar to ours, then introduce restrictions on the Markdown syntax, follow the terminology, do automatic checks and use Translation Memory. Tools: remark-lint , yaspeller , md2xliff . Thank you.
I sometimes get the impression that it does not serve for us, but we serve for this format. Therefore - Sir Markdown.
- We know that now lies on the scales
And what happens now.
An hour of courage struck on our watch,
And courage will not leave us.
Not scared to lie down under the bullets of the dead,
Not sad to be homeless.
And we will keep you, Russian speech,
Great Russian word.
')
We will carry you free and clean
And give the grandchildren, and save from captivity -
Forever.
Good evening, friends, my name is Sergey Bocharov. I began with Anna Akhmatova's poem “Courage”. It was written in 1942, during the Great Patriotic War, and even then the poetess understood that it would be much easier to return and build the factories and factories broken by the bombing than to return the spiritual wealth that was wasted and actually trampled during the war years.
Poetry is one of the few tools that helps us learn to feel the beautiful. Today we are talking about technical documentation - it would seem such a far from poetry, but preserving the beautiful, maintaining a single style is very important, especially when working with this format. Markdown has de facto become the standard for writing technical documentation in the open source world. And united people of different specialties.
I have a hard and at the same time pleasant mission. I want you to have the full sense of assembling Markdown documentation in Yandex, and also to share the tools that we developed. I hope you will use them in your projects too.
The tools that are developed are written in JS, because we in Yandex love JavaScript. And all development is conducted around this language. You shouldn't be upset here if you have another development environment or a HYIP React - I think you can find analogues on GitHub.
Perhaps many wonder why Markdown became sir? This is a metaphor, and it is connected with the fact that we in Yandex are trying to robotize any process.
A large number of tools are also being developed around Markdown. To date, we have already developed a lot of tools, we continue to develop. I sometimes get the impression that it does not serve for us, but we serve for this format. Therefore - Sir Markdown.
In the first global part we will talk about why we are writing in this format, why we are developing some tools for it. In the second part, we will discuss in more detail the example of our library on how to maintain the quality of the content, how to translate it, and how to assemble one site from many repositories.
Markdown was created in 2004 by John Gruber and Aaron Schwartz. The idea was to have a simple textual syntax and then convert it to richer and more valid HTML.
We have a heading of the first level, the second level and some paragraph of text.
Why a new format when there is a DITA with richer tools? Why create new tools for Markdown? Let's try to answer together.
DITA has a more complex syntax, and to work with it, it is desirable to have a specific development environment. It is clear that this is an XML format, it also opens in a text editor. But SVG also opens in it, while no one draws there - everyone uses Photoshop or Sketch.
Markdown, to the exact opposite, has a lighter syntax, which is why it was so much loved by many developers. As a result, the documentation in Markdown is written and maintained by a technical writer with the active participation of contributors and developers, and documentation in DITA is often developed only by a technical writer, developers and contributors do not actively participate.
A striking example of the Markdown documentation site is the npm site, today it contains 475,000 modules, and every day there are more and more of them.
Here are the most popular ones. If you go to any site, for example Gulp, and go to the documentation section, we immediately get to GitHub, where we see that the gulp.js API is described in Markdown.
Therefore, if for some reason you are not yet using Markdown or bypassing it, please use and make your developers happy.
Style and syntax. I propose to consider the example of our internal library of Lego, super-secret. Now I will demonstrate.
Suddenly, right? All these blocks are different. Here is the block logo, teaser, etc. And they are stored on GitHub, the standard de facto.
There is a general description of the library, there are also directories of blocks, and in each directory there is a description of this block. We view the documentation as part of the code, so we call it the appropriate name. It is also convenient in case of replacement, search & replace. Once upon a time a technical writer worked on every document. The translator also worked on the English versions, and ideally the documentation, the Russian and English versions, should be consistent, that is, they should have the same structure and content.
The developers themselves are also actively working on the documentation, there are a lot of them. The process that we are trying to build in the company is as follows: the developer, having developed a new functionality or a new unit, sets the task for the technical writer in the form of a pull request or issue.
The technical writer describes this functionality, and then returns it for translation if a language version of the document is needed. And everyone is happy, but this is a perfect world. And in the real world, the situation is often the following: the developer himself comes in and makes changes to the documentation.
Here we are faced with the first problem - loss of consistency. The next problem is also changing the style of writing documentation.
It seems - think, the main thing is that the functionality is described. It turns out no. After the document was written by a technical writer, the developers were happy.
Then, when a few dozen more developers came there with their commits, they were already pondered and eventually wept. They say - you need to rewrite the document, it has become incomprehensible, it is impossible to read it, there are a lot of different incomprehensible constructs, ghouls, problem text markers.
They need to somehow be able to fight. Technical writers know and are able to deal with them, and developers often allow them in the documentation, and such documentation is uncomfortable to read.
For example, is everyone comfortable here? Everyone understands what it is about? Obviously, this is git, and this is found in our documentation. Here is a clearer option.
Developers who have little experience with GitHub sometimes encounter difficulties when they read the documentation that the guru developers wrote. Therefore, we add the following problem - the preservation of style and terminology. Developers commit a lot, and the technical writer is almost invisible, the unity of style is broken.
The next problem with this approach is that the syntax is broken. Markdown allows you to write in completely different ways and get the same result. The developers of technical documentation for each case have an agreement on how we write headlines, lists, insert screenshots, etc.
Indeed, the reality is often different from the desired, and this problem also needs to be able to fight. It would seem that the result is expected, but if this problem is not solved now, it will have to be solved at the assembly stage. Often there is a task - for example, to find all third level headers with Backtick and increase by two pixels. If we do not solve it at the linting stage , then we will have to solve it at the assembly stage, to write large scripts.
Therefore, we add the following problem - Markdown syntax. We have three main challenges with which we fight. We also have open-source projects, in particular, BEM. Open-source projects have contributors in addition to developers, technical writers and translators. Contributors help make our products better, for which we are grateful. There are a lot of them. They send us their pull requests, and we share quality content with them. Therefore, it is definitely necessary to somehow find solutions.
The next section is about auto-checking, linting. What can be done to somehow learn to consistently check the Markdown syntax, find grammatical errors and markers of the problematic text. This is my favorite section. I think the linting progression works on the progression of a technical writer.
Let's start with a tool called remark-lint. It allows you to check the syntax and style of writing. The remark itself is in the public domain, it was not developed by us, we use it, it has its own set of rules, there are more than 50 of them. We wrote our rules on top of these rules, added our guide to remark.
How it works? Suppose there is a test file with content, there is a heading of the first level, the second and some kind of list.
We enter a command in the terminal. This is the command we have on the precommute is being processed, I show. When a technical writer commits on GitHub and the document is in order, a message is displayed that there are no errors. And the commit goes to GitHub. Suppose we have mistakes - for example, we make the second level in the first heading, and in the second heading we add “Hello” and an exclamation mark. We execute the same command, and we have three errors.
Linting progression works on the progression of a technical writer. A technical writer recalls that we agreed not to put exclamation marks in the headlines, rules, everything is fine. How are these rules connected? At the root of the project lies the remarkrc file, in it we define a set of our own rules (I have shortened them) and a set of borrowed rules of the remark itself.
The next tool is yaspeller. It checks grammar and spelling errors in documentation. Documentation is on Yandex. Technologies - it, by the way, is written in git. You can read it, everything works on the same principle: there is a spelling error - a message is displayed. Contributors, developers who are trying to make you a pull request, send some corrections, they will not be able to send them with spelling errors or inaccuracies in the Markdown syntax. So these tools are very convenient to connect, and they work on prekommite.
The next section is devoted to translation. We developed the md2xliff tool. We translate a lot of open source documentation and a bit of internal. In the case of open-source documentation, we have contributors who send their pull-requests, and to make it easier for them to send them, we make dies for them on our website in which we offer them to follow the link either through the GitHub interface or using the prose service. io. For example, they come in, make changes, click OK, and a pull request arrives.
How does all this support? Suppose a technical writer wrote a document, the translator translated it, the user came - initially into the Russian version - and corrected something there. How to deal with the English version? Is there something to rule there or not? Unclear. How to look for a typo that was corrected is also unclear. Or you can go to GitHub and see the difference there in diff. But this is still a task, you need to put it to the translator. Need to find a solution.
There is a second situation. For example, the developer wrote the second version of the library, and took not the whole document, did not rewrite 30 pages, and then deleted the piece, added there. And if deleted - it is not clear what to do. We have to go and somehow check this into a diff on GitHub.
How to be? It seems to be a difficult situation in which there is no way out. However, if any of you have worked with translations, they probably know that there are a lot of standards, and upon closer inspection, the solution looks like this: there is a test file and some text of the documentation that lies on GitHub. What should be done? It is necessary to generate two files from it, a skeleton and a XLIFF translation.
The skeleton is block formatting, that is, we substitute pieces of text for such placeholders with numbers.
XLIFF is a special format, it is described, it has a specification, everything is simple there. The most important thing is that in XLIFF there are units, and the id of the unit corresponds to the segment that we changed in the skeleton.
Also there are two tags in each unit: source and target. The source tag contains exactly that piece of text that we replaced in the skeleton, and the target field is initially empty. We give this XLIFF to the translator. The target field is now filled out. After the transfer, we do the reverse generation and get the English version of the document.
At the same time, the translation here does not disappear anywhere, but is stored in a special standardized XML file TMX. There are two values: source and target. How does this help us? We return to the past situation. Contributors, developers or another technical writer came and corrected something in the source document. In the Russian version, for example.
We still generate XLIFF, give it to the translator, it applies the base that it has saved in the program and translates exactly those segments that have changed. It does not translate strings that have a one-hundred-percent match - they are replaced by an auto-replacement. Thus, there is no longer a problem to look for what has changed. We guarantee that all the lines that have somehow been changed will be visible in the translation. Next, we generate the English version of the document, everything is simple. It seems that there is a ready-made solution - simply because surely they should be.
There is a smartcat.ai from ABBYY, there is a solution from Google and there is Matecat . But the total flaws of these solutions are that they do not support Markdown, which does not have a single standard for how to write. And they bypass it, support any standardized formats. Last week I checked Markdown in matecat, everything is red. Although Markdown was simple.
Take, for example, our tool with a complex nesting. If you have a code, there are three bacteriums inside it, and there is JSDoc there, it handles everything at 99%, the nesting level can be anything.
The second fatal flaw in these services is that they do not integrate with GitHub. We want the user to come to us through the link and correct something, but they are not integrated.
We all discussed this. When there is a source document in Russian, and we translate into another language, we have a certain pair, a tough attachment to the Russian language. We are working to get rid of this attachment so that we can rule TMX on the fly, no matter where the user goes. It can come to the Russian version, and maybe to the English version, and we must deploy the TMX right at the time of generation. Until it is decided.
I propose to consider assembling the site as part of a general review of the path of the Markdown document from the time of writing to the time of laying out on the site.
What does the workflow look like? Suppose a work plan has been drawn up, all information has been collected. If we talk about Markdown, it is important to observe the agreement on syntax. After that there is an autocheck, it works out on the precommite of our linings. Further the document gets on GitHub. If you need an English version, we localize the document. After the assembly takes place, and there are two stories. One is when the document is one-to-one per page, and the second is when you need to build various in-line examples. In the page you need to embed an iframe, etc. We have a tool that can do it all, a potty. He is able to substitute links, combine different Markdown documents into one, and is able to build inline examples. Then there is a calculation on the site.
Why do you need a website? Why, as on gulp.js, not to store all documentation in Markdown?
The answer is obvious - we need a single entry point. We have more than a hundred repositories, and we want these documents to be collected in one place. We also need search, navigation and live examples. Live examples look like this.
The same document on GitHub and on the site is rendered differently. We can open it in a new window, click on the button, view its HTML. It is very convenient.
What are our recipes? What do you do? In the first place - to determine the needs. If they are similar to ours, then introduce restrictions on the Markdown syntax, follow the terminology, do automatic checks and use Translation Memory. Tools: remark-lint , yaspeller , md2xliff . Thank you.
Source: https://habr.com/ru/post/342192/
All Articles