Digital Transformation: Lottery in the Cloud
While everyone is waiting for news, a resident of Voronezh will appear and take away his winnings, having broken the record jackpot of 506 million rubles, we will tell you about the technical part of the solution, which allowed one of the largest companies selling lottery tickets in Russia to increase sales by 3 times.

Just imagine, the company has more than 40 thousand units in almost all locations in Russia. At some point, the guys came up against the scalability of the scalability and realized that it was time to change something and use new technological solutions.
After that, together with us, a solution was developed based on Azure services and Microsoft SQL Server DBMS. Together with him, there was no need to install specialized software for data processing, and errors began to be detected at an early stage. As a result, the number of offices working with lottery tickets increased from 8 to 22 thousand, and the volume of ticket sales grew three times.
')
We hand over to Paul, the author of the article.
Today, cloud services are becoming more common. I think many people ask the question “Why are they so good?” I answer for myself: “First of all, with its scalability, high-quality infrastructure and abundance of services.” But sometimes things are not without nuances, knowledge of which will help save time and money. This article will discuss just some of them that should be considered when developing in the Entity Framework + Azure SQL bundle.
From a developer’s point of view, this is almost the same as a modern Microsoft SQL Server. The most important difference is the presence of artificial limitations in performance, on which the price of a “cloud” DBMS depends.
Of course, the CPU also takes part in calculating this parameter, and the number of I / O operations with the disk and with the log, though the exact composition of the formula is unknown. And most importantly - for reasonable money DTU is not so much. And a lot of DTUs cost a lot of indecent money. Obviously, they need to be saved and not wasted. And, besides purely financial considerations, there is one more, very important: the DBMS does not scale well enough.
"How so?" - you ask. “We are in the clouds and we are going to pay only for the resources we used and to be able to quickly scale our solution. I can click the mouse at any time and increase the number of available DTUs by a factor of five. "
You can, but consider how the transition to another category of performance occurs inside the platform.
And it happens like this :
The recovery and synchronization process takes a non-zero time, practice shows that for every 50 GB of the Standard database it takes about 1 hour, and this is for the database without any load. This means that if your database weighs 150 GB and in the morning after the advertising campaign you have a 100% database load and everything slows down - you will be able to increase the number of DTUs at best for dinner. Of course, your business department during this time will colorfully explain to you where he saw your magical clouds, and also ask where their praised scalability and resilience are.
The final conclusion is simple : we always need a performance margin, and switching performance levels must be done in advance.
Having understood the question of why we need to save DB resources, we will try to answer the question “How?”.
First of all, we note that the modern approach to design almost completely eliminates the use of stored procedures. No, nobody forbids, but this approach should not be the main one. In the era of classic two-tier applications, the active use of stored procedures on the database server was a good tone. But then, it was a means to implement the same application server, which today is implemented by your ASP.NET application. Well, of course, transferring logic to the DBMS, we again quickly run into problems of scaling, which is called “see point one”.
So, we have a web application based on ASP.NET + Entity Framework and LINQ to SQL for writing queries. Convenient - as much horror. You can forget about the database ... Yeah, that’s where the main danger lies. Unfortunately, you can forget about the database only in simple cases. And in the complex and highly loaded .... Here is a specific example. Suppose we need to pull out a few records by condition:
Everything is great, simple and clear. It will execute the simplest query equivalent to:
Now let's imagine that in the following code we need to use only three of the 20 fields in this table - let it be Amount, ClientID, AccountID. And we always pull out all 20. With decent loads, it quickly turns out that sampling all the fields creates a large number of disk accesses, even if you have an Amount index, and if not, then all the more complete the entire table is produced. All such cases are solved from two sides - from the application side you select only those fields that you absolutely need:
And if, as in our example, there are significantly fewer such fields than fields in the table, an index is created with the fields enabled:
If you look at the query plan - all data is taken from the index, disk access almost does not occur. DTU is extremely economical.
The most interesting thing is that the platform itself will prompt you with requests that require improvement in the described scenario. On a working database, you need to carefully follow the recommendations for the indexes that the platform provides. These recommendations are collected in the Perfomance Recommendations menu item:
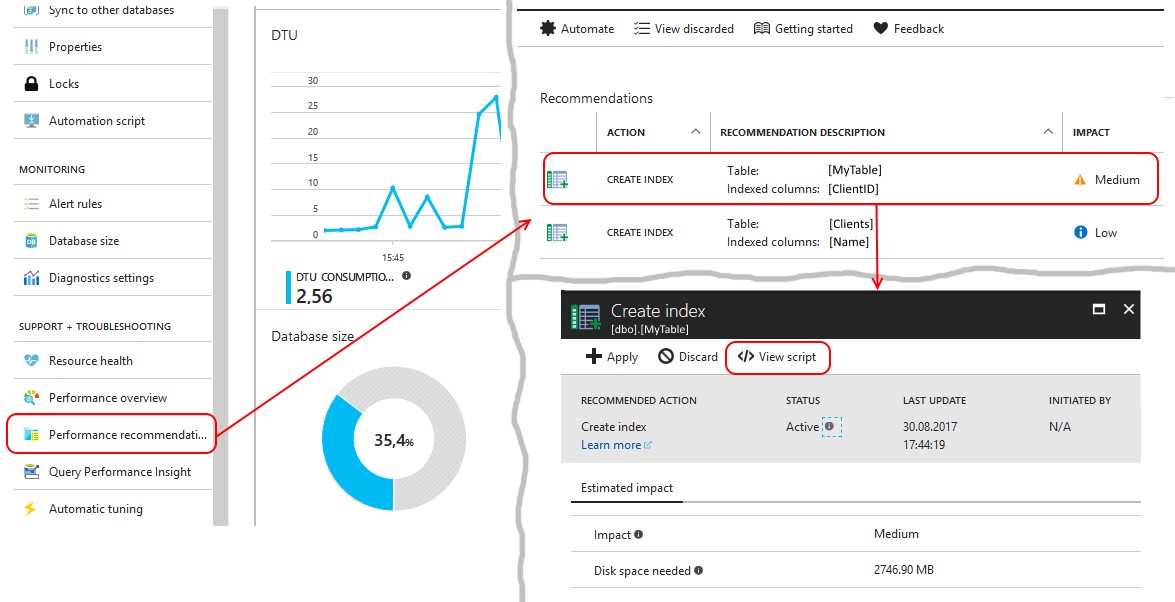
It is necessary to look at the request to create an index that the system offers. And if it is proposed to create an index, where in the INCLUDE all fields of the table are listed with the exception of the key ones, then this is exactly the case described above!
The cheapness of disk storage has given rise to a general trend towards data denormalization in a DBMS. From here, NoSQL bases also began to appear, the work with which requires a specific approach, but gives a big gain in speed. To some extent, a similar principle has to be applied today for ordinary relational DBMS.
No matter how beautiful your 6-story join is, its implementation is quite a difficult task for the server. Making the server “shovel” half of the database to produce two digits is a worthy task, but it sharply limits you in scaling. Practice shows that it is often easier to make two simple queries to the DBMS and then glue the result into memory, rather than force the server with one complex query. Moreover, it is simpler and faster to simply get 5-7 thousand lines in a simple request and make improvements using the application server than to fill in a request that produces three lines, but at the same time consumes all the available resources. Due to this, we transfer part of the logical load on the application server, the scaling of which takes 2 minutes and often happens automatically. And about the complexity of scaling the DBMS, everything has already been said above.
Suppose we are trying to choose some statistics of the total amount of orders of our customers, where each order was from 10 thousand. You need to issue a total amount, the number of such orders and the name of the client. Transactions are stored in a certain table
Let's see what the Entity Framework turns it into:
The query is not complicated, but a large number of such “simple” queries will generate quite a considerable load. And if there are a lot of them, then it’s logical to keep a list of customers in the cache. And then the sample code could be:
Which turns the Entity Framework into a much simpler query:
And after that, we finish building the sample with customer data:
Even with the “right” index:
The request plan for the second case is half the Estimated Subtree Cost. Pictures of query plans, respectively:
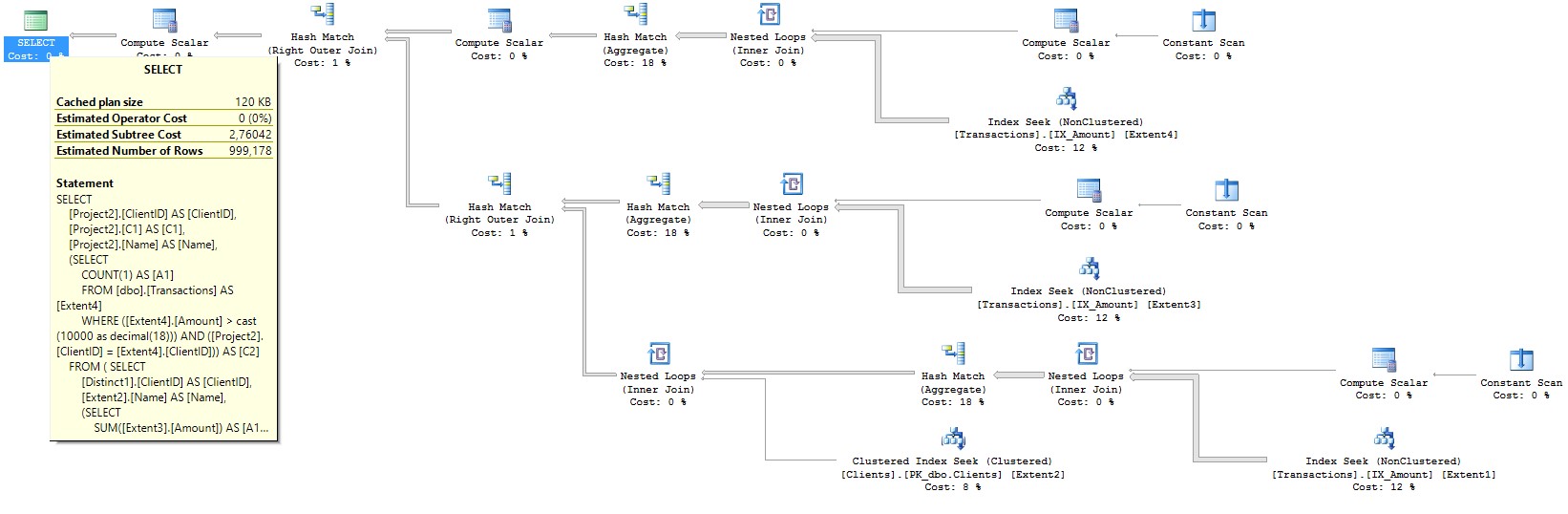
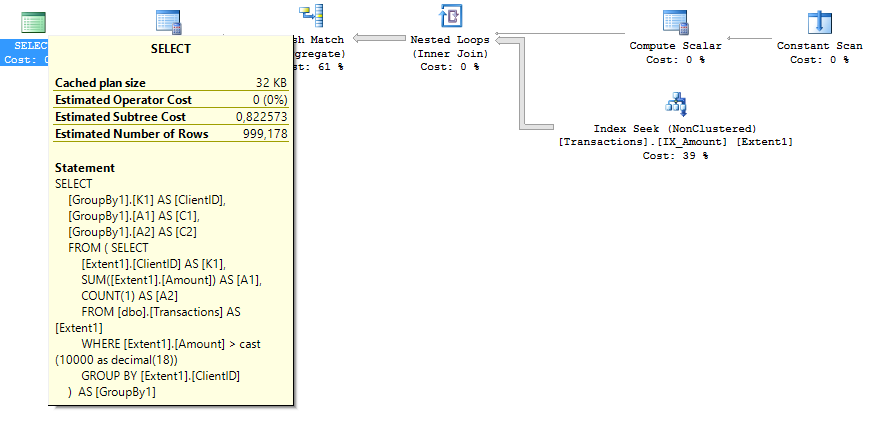
The described approaches allow you to increase the speed of the system by 10-40 times, proportionally reducing the required level of performance of Azure SQL.
 Pavel Kutakov - over 15 years of experience as a developer and architect of software systems in various business areas. The list of projects includes a banking information system operating worldwide from the USA to Papua New Guinea, as well as an integrated development environment for the Firebird DBMS. Currently, he is leading the development of specialized transactional services for the national lottery operator.
Pavel Kutakov - over 15 years of experience as a developer and architect of software systems in various business areas. The list of projects includes a banking information system operating worldwide from the USA to Papua New Guinea, as well as an integrated development environment for the Firebird DBMS. Currently, he is leading the development of specialized transactional services for the national lottery operator.
We remind you that you can try Azure for free .
Minute advertising . If you want to try new technologies in your projects, but do not reach the hands, leave the application in the program Tech Acceleration from Microsoft. Its main feature is that together with you we will select the required stack, we will help to realize the pilot and, if successful, we will spend maximum efforts so that the whole market will know about you.
Introduction
Just imagine, the company has more than 40 thousand units in almost all locations in Russia. At some point, the guys came up against the scalability of the scalability and realized that it was time to change something and use new technological solutions.
After that, together with us, a solution was developed based on Azure services and Microsoft SQL Server DBMS. Together with him, there was no need to install specialized software for data processing, and errors began to be detected at an early stage. As a result, the number of offices working with lottery tickets increased from 8 to 22 thousand, and the volume of ticket sales grew three times.
')
We hand over to Paul, the author of the article.
Today, cloud services are becoming more common. I think many people ask the question “Why are they so good?” I answer for myself: “First of all, with its scalability, high-quality infrastructure and abundance of services.” But sometimes things are not without nuances, knowledge of which will help save time and money. This article will discuss just some of them that should be considered when developing in the Entity Framework + Azure SQL bundle.
Let's start with Azure SQL
From a developer’s point of view, this is almost the same as a modern Microsoft SQL Server. The most important difference is the presence of artificial limitations in performance, on which the price of a “cloud” DBMS depends.
- In the on-premise server, you are limited by CPU power, HDD speed and RAM, and, as a rule, all this is bought with a good margin.
- In the cloud version, you do not know how much hardware resources you have, instead you have some calculated value of performance, called DTU (Data Transfer Unit).
Of course, the CPU also takes part in calculating this parameter, and the number of I / O operations with the disk and with the log, though the exact composition of the formula is unknown. And most importantly - for reasonable money DTU is not so much. And a lot of DTUs cost a lot of indecent money. Obviously, they need to be saved and not wasted. And, besides purely financial considerations, there is one more, very important: the DBMS does not scale well enough.
"How so?" - you ask. “We are in the clouds and we are going to pay only for the resources we used and to be able to quickly scale our solution. I can click the mouse at any time and increase the number of available DTUs by a factor of five. "
You can, but consider how the transition to another category of performance occurs inside the platform.
And it happens like this :
- database recovery from backup is done;
- replication between databases is configured;
- when the bases are synchronized, switching occurs (naturally, with a small gap in availability, it is stated that this time does not exceed 30 seconds).
The recovery and synchronization process takes a non-zero time, practice shows that for every 50 GB of the Standard database it takes about 1 hour, and this is for the database without any load. This means that if your database weighs 150 GB and in the morning after the advertising campaign you have a 100% database load and everything slows down - you will be able to increase the number of DTUs at best for dinner. Of course, your business department during this time will colorfully explain to you where he saw your magical clouds, and also ask where their praised scalability and resilience are.
The final conclusion is simple : we always need a performance margin, and switching performance levels must be done in advance.
Having understood the question of why we need to save DB resources, we will try to answer the question “How?”.
Approach the first - we take only the necessary
First of all, we note that the modern approach to design almost completely eliminates the use of stored procedures. No, nobody forbids, but this approach should not be the main one. In the era of classic two-tier applications, the active use of stored procedures on the database server was a good tone. But then, it was a means to implement the same application server, which today is implemented by your ASP.NET application. Well, of course, transferring logic to the DBMS, we again quickly run into problems of scaling, which is called “see point one”.
So, we have a web application based on ASP.NET + Entity Framework and LINQ to SQL for writing queries. Convenient - as much horror. You can forget about the database ... Yeah, that’s where the main danger lies. Unfortunately, you can forget about the database only in simple cases. And in the complex and highly loaded .... Here is a specific example. Suppose we need to pull out a few records by condition:
myContext.MyTable.Where(x=>x.Amount>100).ToList(); Everything is great, simple and clear. It will execute the simplest query equivalent to:
Select * from MyTable where amount>100 Now let's imagine that in the following code we need to use only three of the 20 fields in this table - let it be Amount, ClientID, AccountID. And we always pull out all 20. With decent loads, it quickly turns out that sampling all the fields creates a large number of disk accesses, even if you have an Amount index, and if not, then all the more complete the entire table is produced. All such cases are solved from two sides - from the application side you select only those fields that you absolutely need:
myContext.MyTable.Where(x=>x.Amount>100) .Select(x=>new MyTableViewModel{ ClientID = x.ClientID, AccountId = x.AccountID, Amount = x.Amount }) .ToList(); And if, as in our example, there are significantly fewer such fields than fields in the table, an index is created with the fields enabled:
create index IX_AmountEx on MyTable(Amount) include(AccountID, ClientID) If you look at the query plan - all data is taken from the index, disk access almost does not occur. DTU is extremely economical.
The most interesting thing is that the platform itself will prompt you with requests that require improvement in the described scenario. On a working database, you need to carefully follow the recommendations for the indexes that the platform provides. These recommendations are collected in the Perfomance Recommendations menu item:
It is necessary to look at the request to create an index that the system offers. And if it is proposed to create an index, where in the INCLUDE all fields of the table are listed with the exception of the key ones, then this is exactly the case described above!
Second approach - keep it simple
The cheapness of disk storage has given rise to a general trend towards data denormalization in a DBMS. From here, NoSQL bases also began to appear, the work with which requires a specific approach, but gives a big gain in speed. To some extent, a similar principle has to be applied today for ordinary relational DBMS.
No matter how beautiful your 6-story join is, its implementation is quite a difficult task for the server. Making the server “shovel” half of the database to produce two digits is a worthy task, but it sharply limits you in scaling. Practice shows that it is often easier to make two simple queries to the DBMS and then glue the result into memory, rather than force the server with one complex query. Moreover, it is simpler and faster to simply get 5-7 thousand lines in a simple request and make improvements using the application server than to fill in a request that produces three lines, but at the same time consumes all the available resources. Due to this, we transfer part of the logical load on the application server, the scaling of which takes 2 minutes and often happens automatically. And about the complexity of scaling the DBMS, everything has already been said above.
Example
Suppose we are trying to choose some statistics of the total amount of orders of our customers, where each order was from 10 thousand. You need to issue a total amount, the number of such orders and the name of the client. Transactions are stored in a certain table
Transactions , and clients, respectively, in Clients . A typical query looks like this: from t in dc.Transactions where t.Amount>10000m group t by t.ClientID into tg join cli in dc.Clients on tg.Key equals cli.ID into resTable from xx in resTable select new { Amount = tg.Sum(x => x.Amount), ClientID = tg.Key, ClientName = xx.Name, ItemCount = tg.Count() }; Let's see what the Entity Framework turns it into:
SELECT [Project2].[ClientID] AS [ClientID], [Project2].[C1] AS [C1], [Project2].[Name] AS [Name], (SELECT COUNT(1) AS [A1] FROM [dbo].[Transactions] AS [Extent4] WHERE ([Extent4].[Amount] > cast(10000 as decimal(18))) AND ([Project2].[ClientID] = [Extent4].[ClientID])) AS [C2] FROM ( SELECT [Distinct1].[ClientID] AS [ClientID], [Extent2].[Name] AS [Name], (SELECT SUM([Extent3].[Amount]) AS [A1] FROM [dbo].[Transactions] AS [Extent3] WHERE ([Extent3].[Amount] > cast(10000 as decimal(18))) AND ([Distinct1].[ClientID] = [Extent3].[ClientID])) AS [C1] FROM (SELECT DISTINCT [Extent1].[ClientID] AS [ClientID] FROM [dbo].[Transactions] AS [Extent1] WHERE [Extent1].[Amount] > cast(10000 as decimal(18)) ) AS [Distinct1] INNER JOIN [dbo].[Clients] AS [Extent2] ON [Distinct1].[ClientID] = [Extent2].[ID] ) AS [Project2] The query is not complicated, but a large number of such “simple” queries will generate quite a considerable load. And if there are a lot of them, then it’s logical to keep a list of customers in the cache. And then the sample code could be:
var groupedTransactions= (from t in dc.Transactions where t.Amount > 10000m group t by t.ClientID into tg select new { Amount = tg.Sum(x => x.Amount), ClientID = tg.Key, ItemCount = tg.Count() }).ToList(); Which turns the Entity Framework into a much simpler query:
SELECT [GroupBy1].[K1] AS [ClientID], [GroupBy1].[A1] AS [C1], [GroupBy1].[A2] AS [C2] FROM ( SELECT [Extent1].[ClientID] AS [K1], SUM([Extent1].[Amount]) AS [A1], COUNT(1) AS [A2] FROM [dbo].[Transactions] AS [Extent1] WHERE [Extent1].[Amount] > cast(10000 as decimal(18)) GROUP BY [Extent1].[ClientID] ) AS [GroupBy1] And after that, we finish building the sample with customer data:
from tdata in groupedTransactions join client in clientCache on tdata.ClientID equals client.ID select new { Amount = tdata.Amount, ItemCount = tdata.ItemCount, ClientID = tdata.ClientID, ClientName = client.Name }; Even with the “right” index:
reate index IX_Amount on Transactions (Amount) include(ClientID) The request plan for the second case is half the Estimated Subtree Cost. Pictures of query plans, respectively:
Summary
- When working with Azure SQL, it is necessary to spend DTU very efficiently in order not to run into exorbitant prices. In this case, the performance margin should be, since the change in the limiting performance of your database can take several hours.
- To do this, carefully write requests to require only the necessary data. We actively use indexes with INCLUDE fields.
- We simplify requests, we carry out the final data connection on the server side of the application - it is cheaper and scales faster.
The described approaches allow you to increase the speed of the system by 10-40 times, proportionally reducing the required level of performance of Azure SQL.
about the author
Pavel Kutakov - over 15 years of experience as a developer and architect of software systems in various business areas. The list of projects includes a banking information system operating worldwide from the USA to Papua New Guinea, as well as an integrated development environment for the Firebird DBMS. Currently, he is leading the development of specialized transactional services for the national lottery operator.We remind you that you can try Azure for free .
Minute advertising . If you want to try new technologies in your projects, but do not reach the hands, leave the application in the program Tech Acceleration from Microsoft. Its main feature is that together with you we will select the required stack, we will help to realize the pilot and, if successful, we will spend maximum efforts so that the whole market will know about you.
Source: https://habr.com/ru/post/342148/
All Articles