Swift and TensorFlow
I do not like to read articles, I immediately go to GitHub
I apologize in advance for this inconvenience.
Everything that will be described in this article in one way or another will affect several areas of computer science, but it is not possible to plunge into each separate sphere. I apologize in advance for this inconvenience.
It is probably not necessary to talk about machine learning and artificial intelligence in 2017. A large number of both journalistic articles and serious scientific works have already been written on this topic. Therefore, it is assumed that the reader already knows what it is. Speaking of machine learning, the data scientist community and software engineers usually imply deep neural networks that have become very popular because of their performance. Today in the world there are a large number of different software solutions and complexes for solving the problem of artificial neural networks: Caffe, TensorFlow, Torch, Theano (rip), cuDNN etc.
')
Swift
Swift is an innovative, protocol-oriented, open source programming language grown within Apple by Chris Latner (who recently left Apple after SpaceX and settled in Google).
Apple's OSs already had various libraries for working with matrices and vector algebra: BLAS, BNNS, DSP, subsequently merged under the roof of one Accelerate library.
In 2015, there were small solutions for the implementation of mathematics based on the metal graphic technology.
In 2016, CoreML appeared:
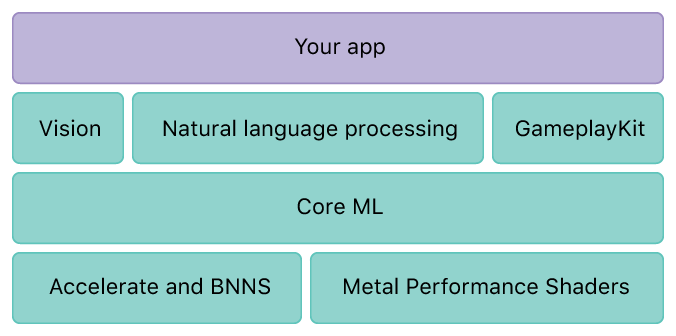
CoreML is able to import a ready-made, trained model (CaffeV1, Keras, scikit-learn) and further provide the developer with the opportunity to export it to the application.
That is, you need to: Build a model on another platform, in Python or C ++, using third-party frameworks. Next, train it on a third-party hardware solution.
And only after that you can import and work in the Swift language. In my opinion it is very piled up and difficult.
Tensorflow
TensorFlow, like other software packages that implement artificial neural networks, has many ready-made abstractions and a mechanic for working with neurons, the connections between them, the calculation of errors and the inverse distribution of errors. But unlike other packages, Jeff Dean (an employee of Google, the creator of the distributed file system, TensorFlow, and many other great solutions) decided to build on TensorFlow the idea of separating the data execution model and the data execution process. This means that you first describe the so-called calculation graph, and after that you start its calculation. This approach allows you to separate and work very flexibly with the data execution model and directly with the data execution process , distributing the execution across different nodes (processors, video cards, computers and clusters).
TensorFlowKit
To solve the whole cycle of tasks from developing a model to working with it in the final application, I wrote an access and work interface with TensorFlow in one language.
The solution architecture looks like two levels: medium and high.
- At the low C level, the module allows access to libtensorflow from the swift language.
- The middle level allows you to get away from C pointers and operate with “beautiful bugs”.
- The high level implements various abstractions for accessing the elements of the model and various utilities for exporting, importing and visualizing the graph.
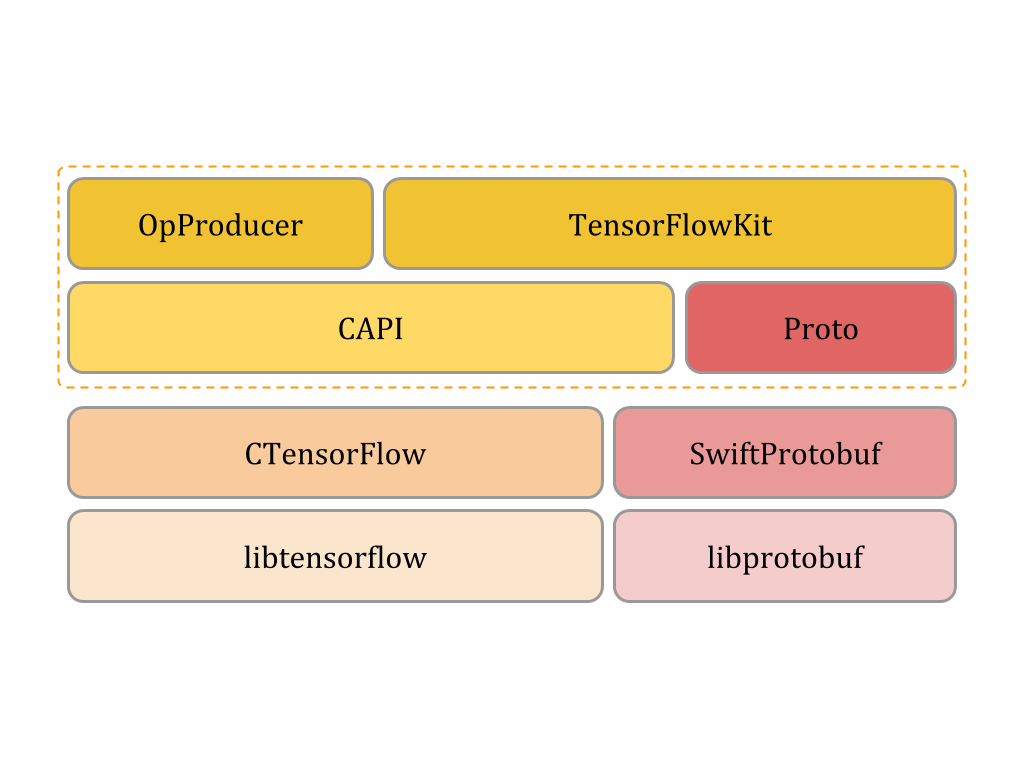
Thus, you can create a model (Graph computing) in swift language, train it on a server running Ubuntu OS, using several video cards and then easily open it in your program on macOS or tv OS. Development can be conducted in the usual Xcode with all its advantages and disadvantages.
Documentation and API is located at this link.
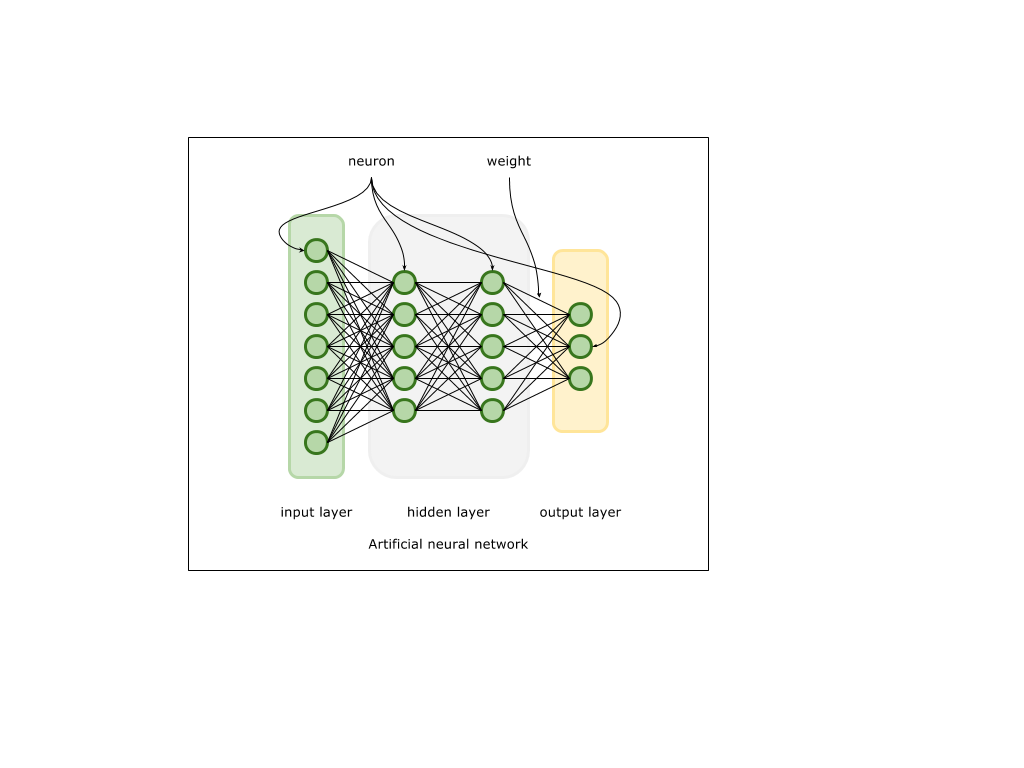
Very briefly about the theory of neural networks.
Artificial neural networks implement some (very simplified) model of neuron connections in the tissues of the nervous system. The input signal in the form of a vector of large dimension enters the input layer consisting of neurons. Further, each input neuron transmits this signal to the next layer, transforming it, based on the properties of connections (weights) between neurons and the properties of neurons of the next layers. In the process of learning, an output signal is formed on the output layer, which is compared with the expected one. Based on the difference between the output signal and the sample signal, an error value is generated. Further, this error is used to calculate the so-called gradient - a vector, in the direction of which it is necessary to make corrections of connections between neurons, so that in the future the neural network generates a signal more similar to the expected one. The process itself is called inverse error distribution or backpropagation. Thus, neurons and connections between them accumulate information necessary for generalizing the properties of the data model that this neural network is learning. The technical implementation rests on various mathematical operations on matrices and vectors, which, in turn, have already been implemented to one degree or another by solutions such as BLAS, LAPACK, DSP, etc.
MNIST

For example, I took “Hello world!” In the world of neural networks: the task of classifying MNIST images. MNIST datasets are thousands of 28 x 28 pixel handwritten digit images. Thus, we have ten classes that are neatly distributed in 60,000 images for training and 10,000 images for the test. Our task is to create a neural network capable of classifying an image and determining belonging to one of ten classes.
Before working with TensorFlowKit itself, you must install TensorFlow. On macOS, you can use the brew package manager:
brew install libtensorflow The linux build is available here.
Create a swift project, connect the dependency to it.
dependencies: [ .package(url: "https://github.com/Octadero/TensorFlow.git", from: "0.0.7") ] Prepare MNIST dataset.
The package for working with MNIST data is written and available at the link. The package will download the dataset itself into a temporary directory, unpack it and present it in the form of ready-made classes.
dataset = MNISTDataset(callback: { (error: Error?) in print("Ready") }) We collect the necessary graph of operations.
The entire space and subspace of the calculation graph is called Scope and may have its own name.
At the entrance of our network, we will submit two vectors. The first is directly the images presented in the form of a vector of higher dimension 784 (28x28 px).
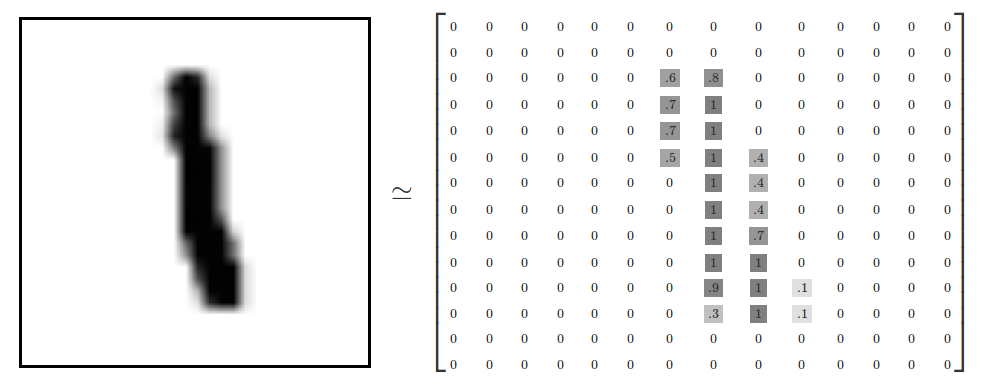
That is, in each component of the vector x there will be a Float value from 0-1, corresponding to the color of the pixel of the picture.
The second vector will be its corresponding class, encrypted in the form (see below) where the corresponding 1 component corresponds to the class number. In this example, the class is 2.
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0 ] Since the input parameters will change in the learning process, we create a Placeholder to reference them.
//Input sub scope let inputScope = scope.subScope(namespace: "input") let x = try inputScope.placeholder(operationName: "x-input", dtype: Float.self, shape: Shape.dimensions(value: [-1, 784])) let yLabels = try inputScope.placeholder(operationName: "y-input", dtype: Float.self, shape: Shape.dimensions(value: [-1, 10])) To visualize the graph, I used TensorBoard . I will discuss how to create graphs and visualize the learning process with TensorFlowKit in another article.
On the input column is as follows:
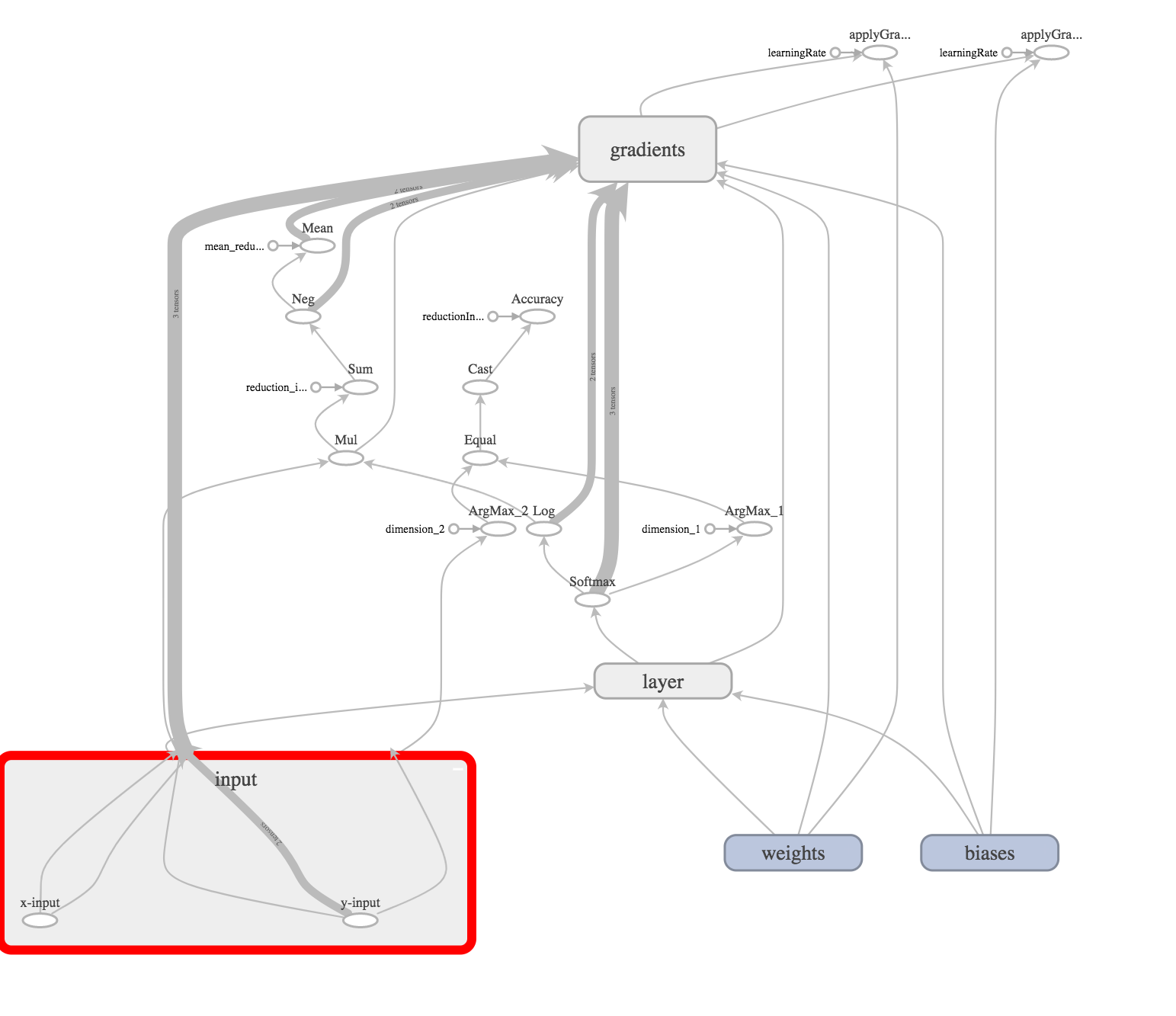
This is our input layer.
Next, create weights (links) between the input layer and the hidden layer.
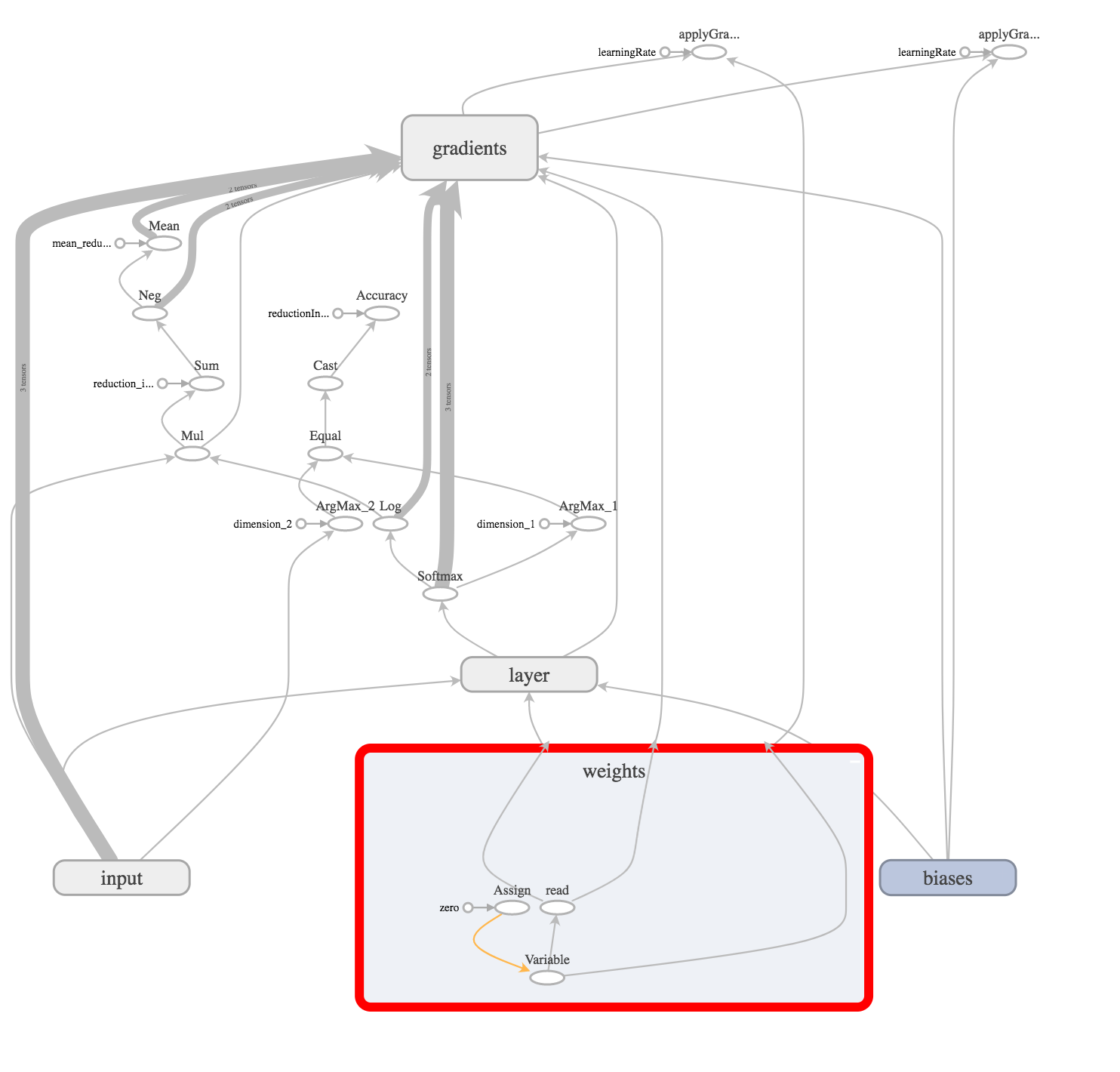
let weights = try weightVariable(at: scope, name: "weights", shape: Shape.dimensions(value: [784, 10])) let bias = try biasVariable(at: scope, name: "biases", shape: Shape.dimensions(value: [10])) Since weights and bases will be changed (adjusted) in the process of network training, we create an operation of variables (variable) in the graph.
And we initialize them with a tensor filled with zeros.
Now create a hidden layer that will perform the simplest operation (x * W) + b
This is the operation of multiplying the vector x (dimension 1x784) by the matrix W (dimension 784x10) and adding the basis.
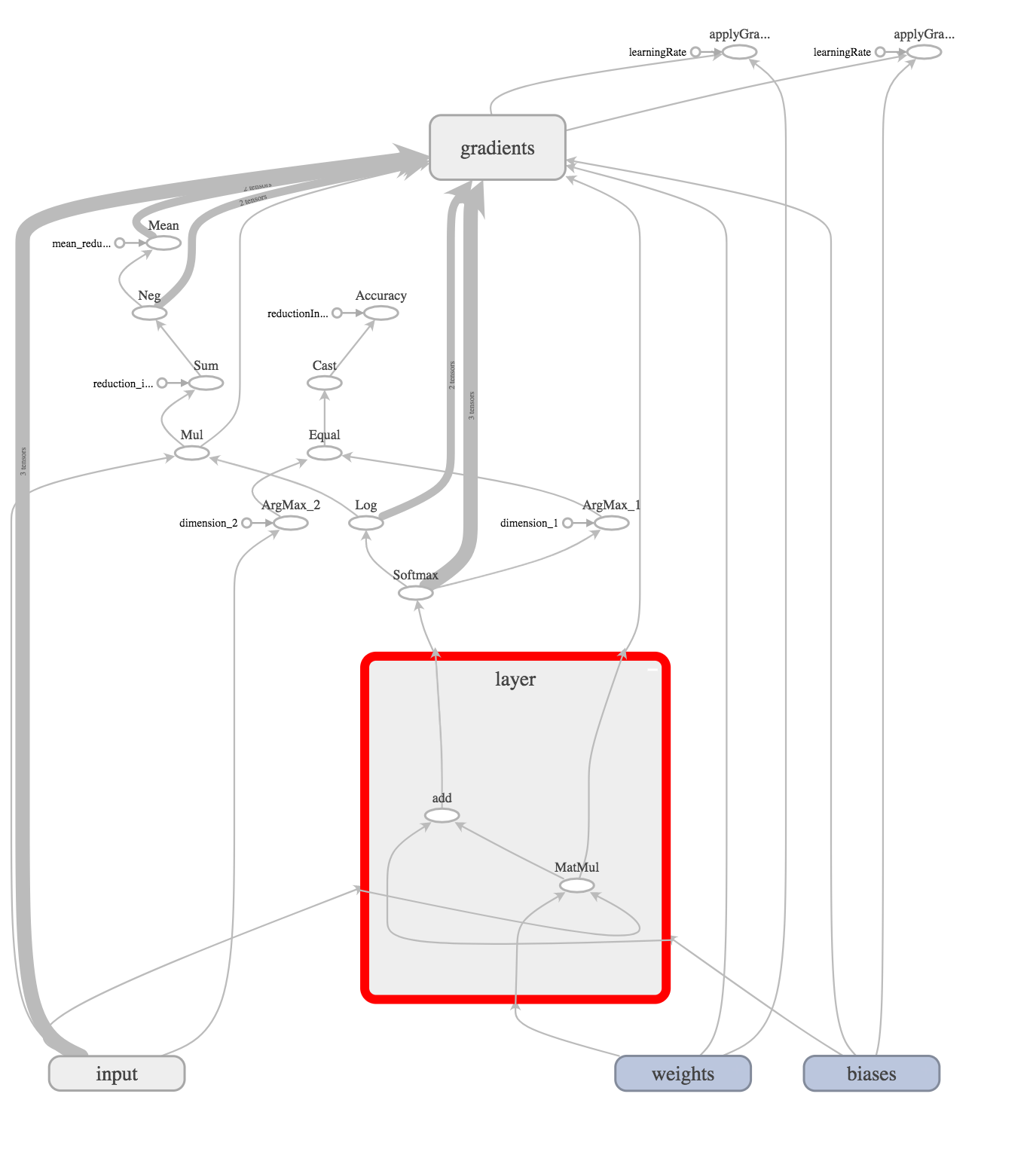
In our case, the hidden layer is already a weekend (task level “Hello World!”), So we need to analyze the output signal and choose the winner. To do this, use softmax operation.
For a better understanding of what I will describe below, I suggest that we consider our neural network as a complex function. The input to our function is the vector x (representing the image). At the output, we get a vector that says how much the function is sure that the input vector belongs to each of the classes.
Next, take the natural logarithm of the magnitude of the predictions in each of the classes and multiply it by the value of the vector of the correct class, neatly transmitted at the very beginning (yLabel).
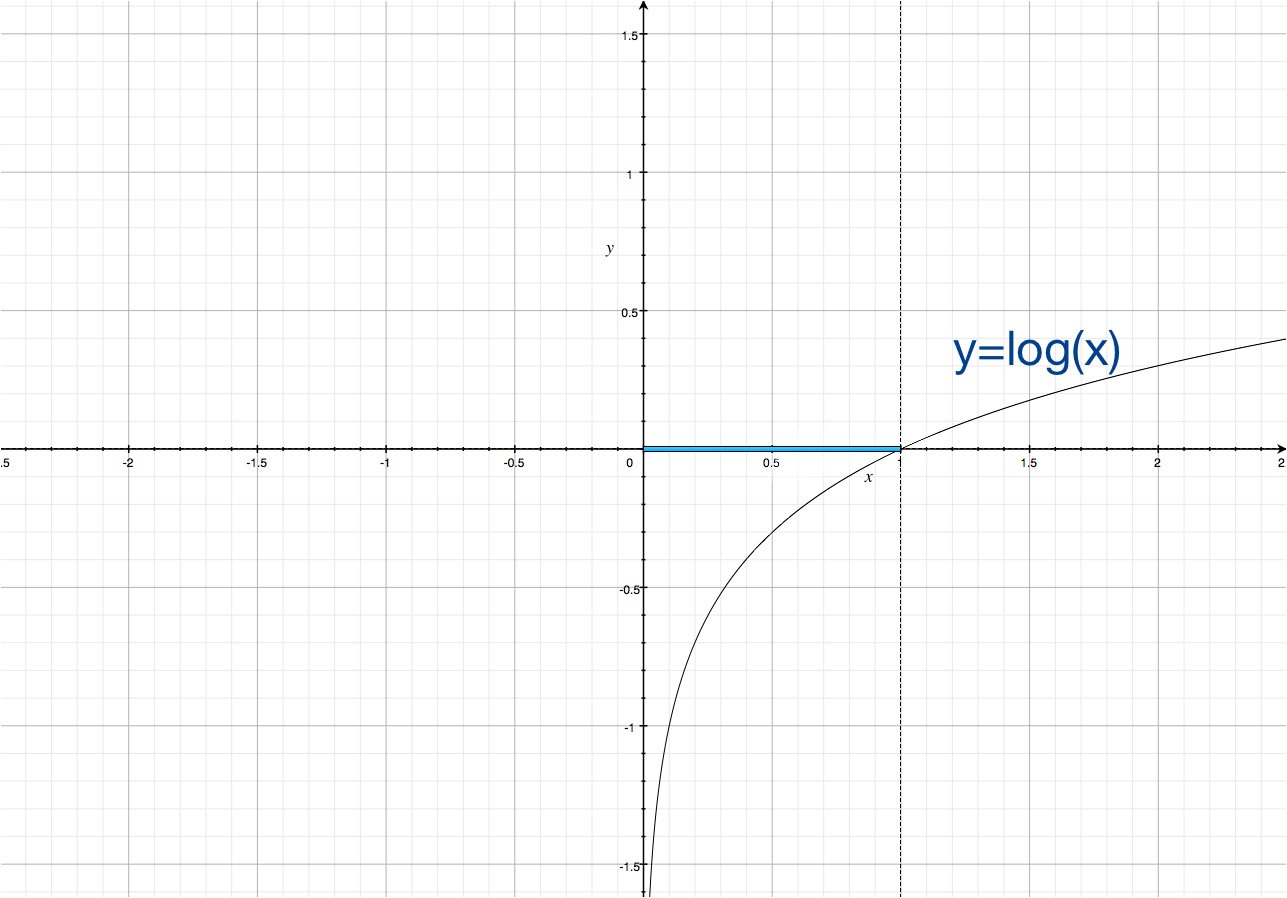
In this way, we get the meaning of the error and can use it to “convict” the neural network. Below is a picture of two examples. On the first class 2: the error was 2.3, on the second class 1: the error is zero.
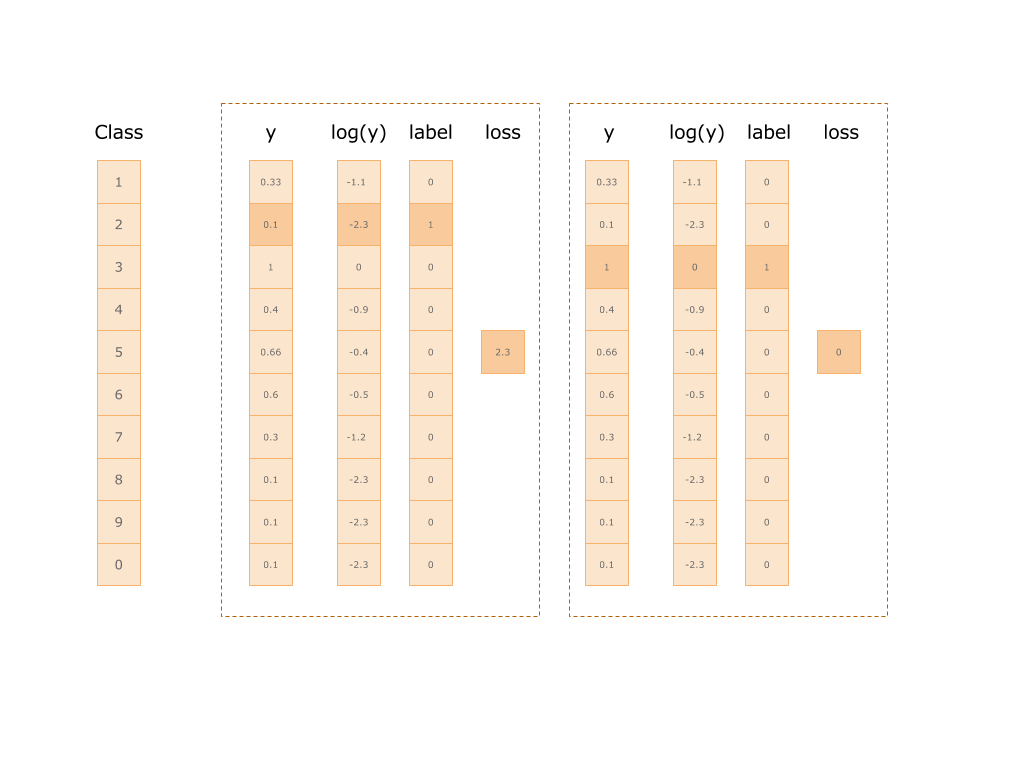
let log = try scope.log(operationName: "Log", x: softmax) let mul = try scope.mul(operationName: "Mul", x: yLabels, y: log) let reductionIndices = try scope.addConst(tensor: Tensor(dimensions: [1], values: [Int(1)]), as: "reduction_indices").defaultOutput let sum = try scope.sum(operationName: "Sum", input: mul, reductionIndices: reductionIndices, keepDims: false, tidx: Int32.self) let neg = try scope.neg(operationName: "Neg", x: sum) let meanReductionIndices = try scope.addConst(tensor: Tensor(dimensions: [1], values: [Int(0)]), as: "mean_reduction_indices").defaultOutput let cross_entropy = try scope.mean(operationName: "Mean", input: neg, reductionIndices: meanReductionIndices, keepDims: false, tidx: Int32.self) What to do next?
Mathematically speaking, we must minimize the objective function. One of the approaches is the gradient descent method. I will try to tell about it in the next article, if this is necessary.
Thus, we have to calculate how much each of the weights (components of the W matrix) and the basis vector b need to be corrected so that the neural network makes a smaller error in such input data.
Mathematically, we must find the partial derivatives of the output node by the values of all our intermediate nodes. The resulting symbolic gradients will allow us to “shift” the values of our components of the variables W and b according to how each of them influenced the result of previous calculations.
Magic TensorFlow.
The fact is that all ( in fact, not yet all ) these complex calculations TensorFlow is able to do on its own, after analyzing the graph that we built.
let gradientsOutputs = try scope.addGradients(yOutputs: [cross_entropy], xOutputs: [weights.variable, bias.variable]) After calling this operation, TensorFlow will independently build another half hundred operations.
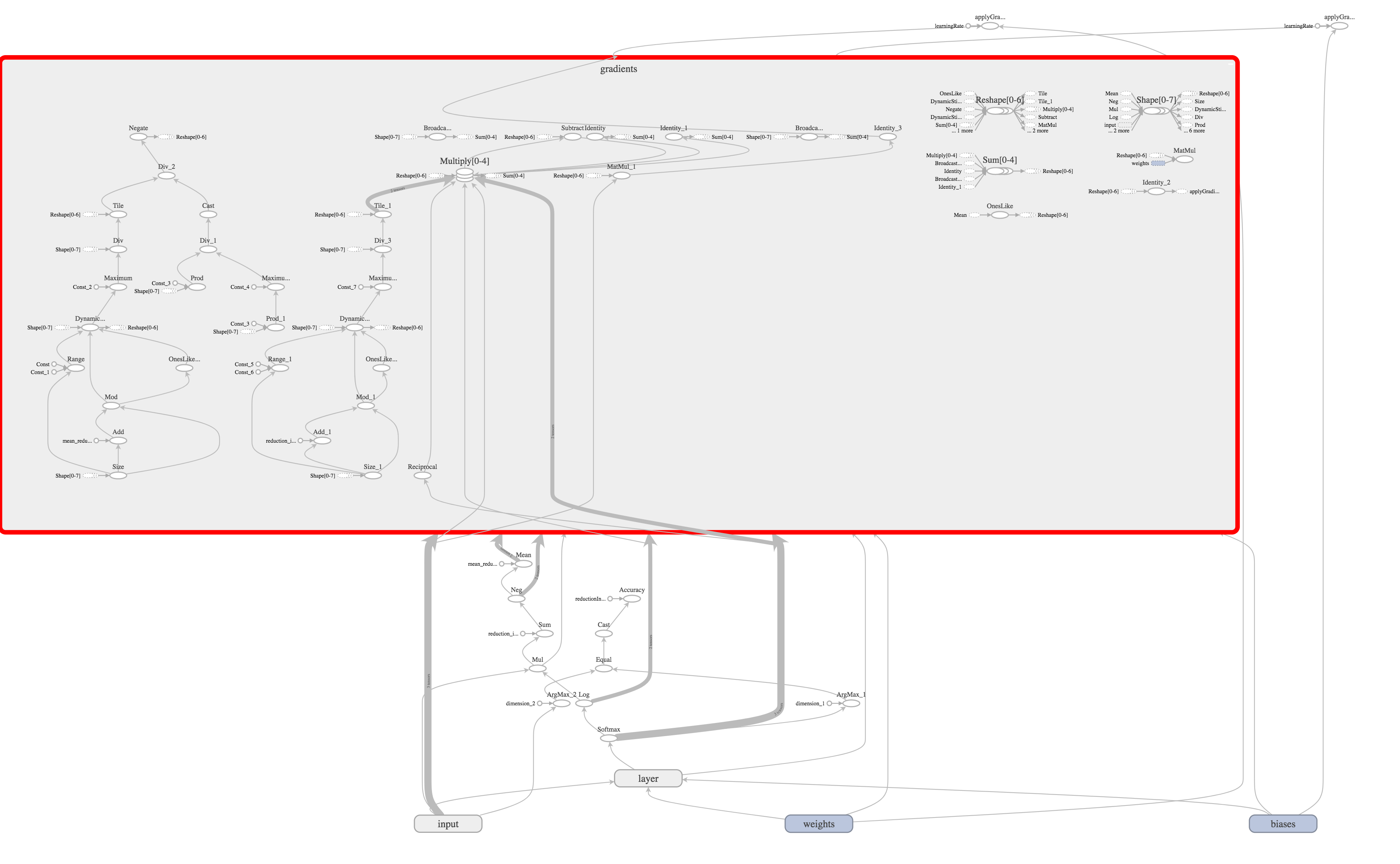
Now it is enough to add the operation of updating our weights to the value previously calculated by the gradient descent method.
let _ = try scope.applyGradientDescent(operationName: "applyGradientDescent_W", `var`: weights.variable, alpha: learningRate, delta: gradientsOutputs[0], useLocking: false) Everything, the graph is ready!
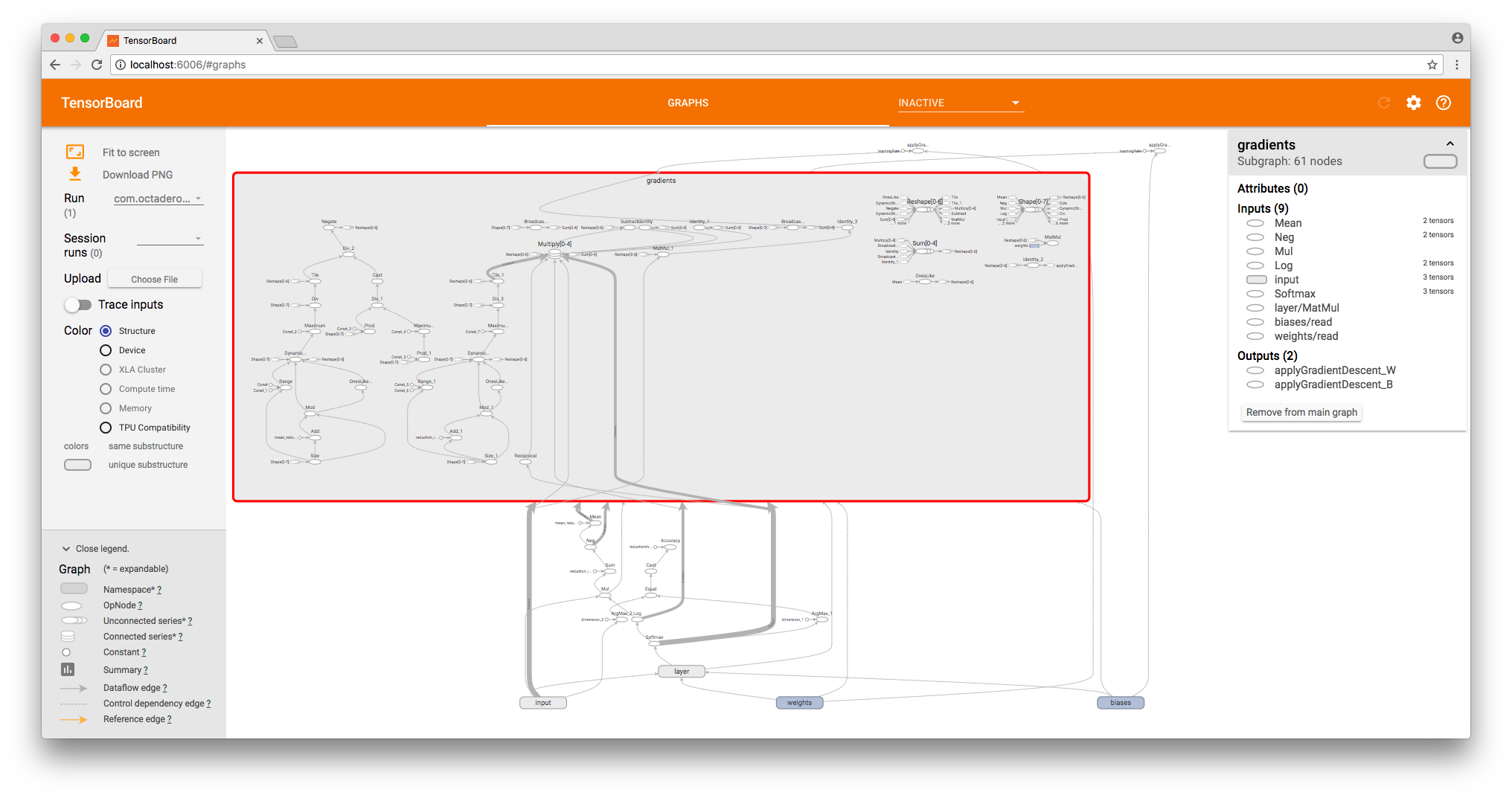
As I said, TensorFlow separates the model and calculations. For this reason, the graph we have constructed is only a model for performing calculations.
We can start the calculations using Session.
Having prepared the data from the dataset and placed it in the tensors, we start the session.
guard let dataset = dataset else { throw MNISTTestsError.datasetNotReady } guard let images = dataset.files(for: .image(stride: .train)).first as? MNISTImagesFile else { throw MNISTTestsError.datasetNotReady } guard let labels = dataset.files(for: .label(stride: .train)).first as? MNISTLabelsFile else { throw MNISTTestsError.datasetNotReady } let xTensorInput = try Tensor(dimensions: [bach, 784], values: xs) let yTensorInput = try Tensor(dimensions: [bach, 10], values: ys) for index in 0..<1000 { let resultOutput = try session.run(inputs: [x, y], values: [xTensorInput, yTensorInput], outputs: [loss, applyGradW, applyGradB], targetOperations: []) if index % 100 == 0 { let lossTensor = resultOutput[0] let gradWTensor = resultOutput[1] let gradBTensor = resultOutput[2] let wValues: [Float] = try gradWTensor.pullCollection() let bValues: [Float] = try gradBTensor.pullCollection() let lossValues: [Float] = try lossTensor.pullCollection() guard let lossValue = lossValues.first else { continue } print("\(index) loss: ", lossValue) lossValueResult = lossValue print("w max: \(wValues.max()!) min: \(wValues.min()!) b max: \(bValues.max()!) min: \(bValues.min()!)") } } This code can be found on GitHub .
Every 100 operations, we derive the size of the error.
New article: Visualization of the neural network learning process using TensorFlowKit published.
Source: https://habr.com/ru/post/342132/
All Articles