Export data in any format: what IDE can do on IntelliJ platform
In DataGrip, as in our other IDE with database support, there is a mechanism for exporting data. The user selects the export format from the proposed or creates it himself.

A table, view, or result can be exported to a file or clipboard.
Export to file:
- Context menu on a table or view in the tree → Dump data to file.
- Context menu on request in the editor → Execute to file.
- In the toolbar of the data or result editor, click the Dump data → To File button ...
')

Export to clipboard:
- Select the data to export in the data editor or the result and press Copy or Ctrl / Cmd + C.
- In the result toolbar or data editor, click Dump data → To File ...
Some formats are configured by default. We call the export mechanism itself “extractor”: several extractors for different formats are already built into the IDE. For example, consider exporting data to the clipboard, but it works for exporting to a file.
In the menu to the left of the Dump Data button, select the extractor.
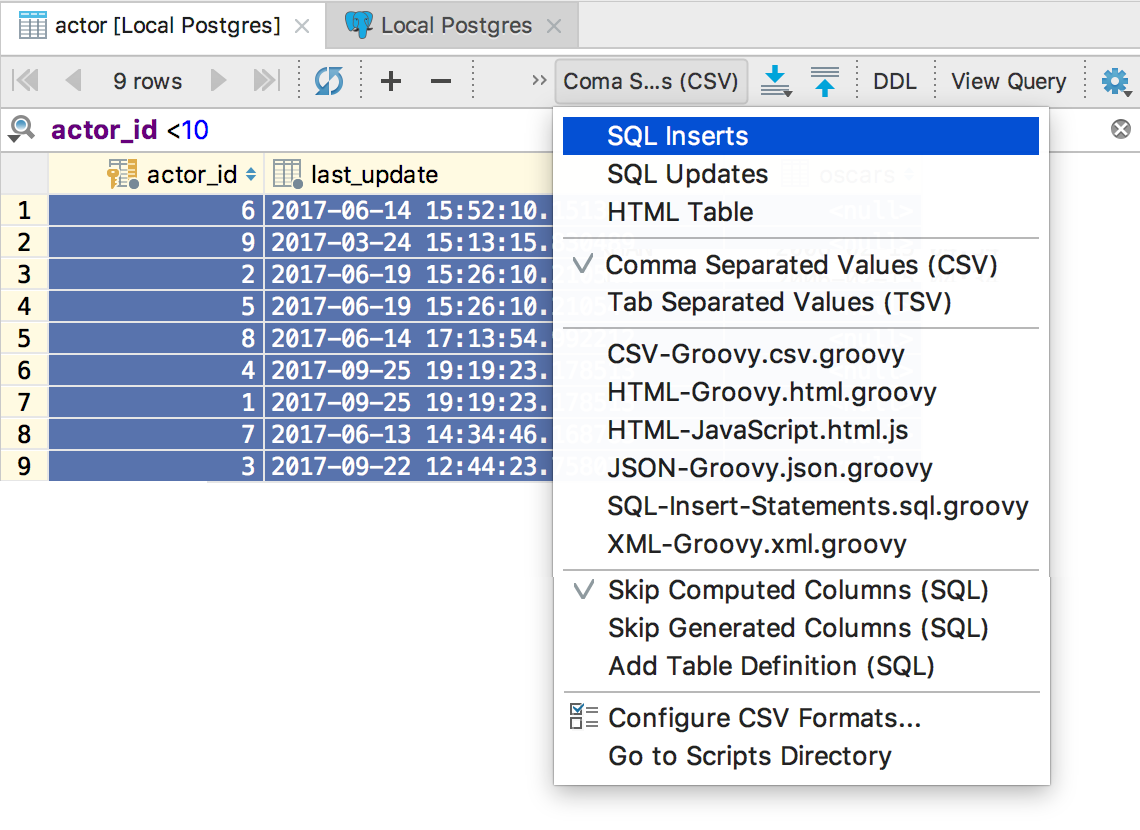
A set of INSERT / UPDATE requests or JSON, CSV, HTML - you decide. Here is described how the built-in extractors work, we will not focus on this.
It is logical that users want to expand the built-in features.

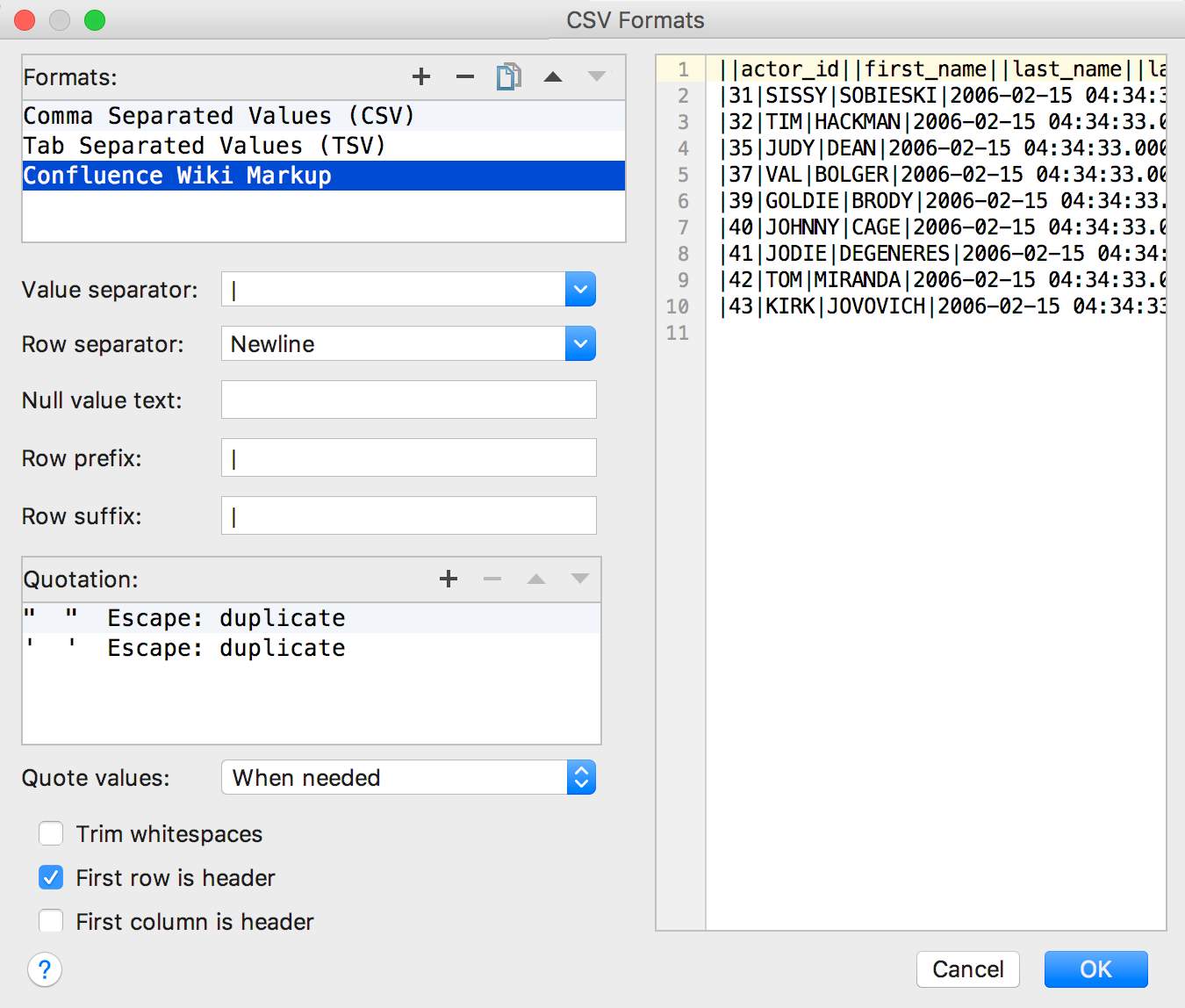
To create your own extractor for a CSV-based format (or, strictly speaking, DSV), in the same menu, click on Configure CSV formats ...

Here you can make changes to existing extractors or create your own. For example, Confluence Wiki Markup.
The saved new extractor will appear in the menu:

For more complex cases, use scripts. Several built-in extractors are Groovy or JavaScript scripts: CSV-Groovy.csv.groovy , HTML-JavaScript.html.js, and others. We will use Groovy in our examples.
Let 's analyze the name of the CSV-Groovy.csv.groovy file :
CSV-Groovy - the name of the script.
csv - file extension with the result.
groovy - script file extension. If you edit it in IntelliJ IDEA, it will help to have code highlighting and autocompletion.
Scripts are usually located in `Scratches and Consoles / Extensions / Database Tools and SQL / data / extractors` . To get to this folder, click Go to scripts directory in the extractors selection menu.

Change existing extractors or add new ones to this folder. For example, create an extractor to export data in one line separated by commas. This is useful if values from a single column are inserted into an IN clause of a WHERE clause.
Based on the existing extractor, we created a new one: CSV-ToOneRow-Groovy.csv.groovy .
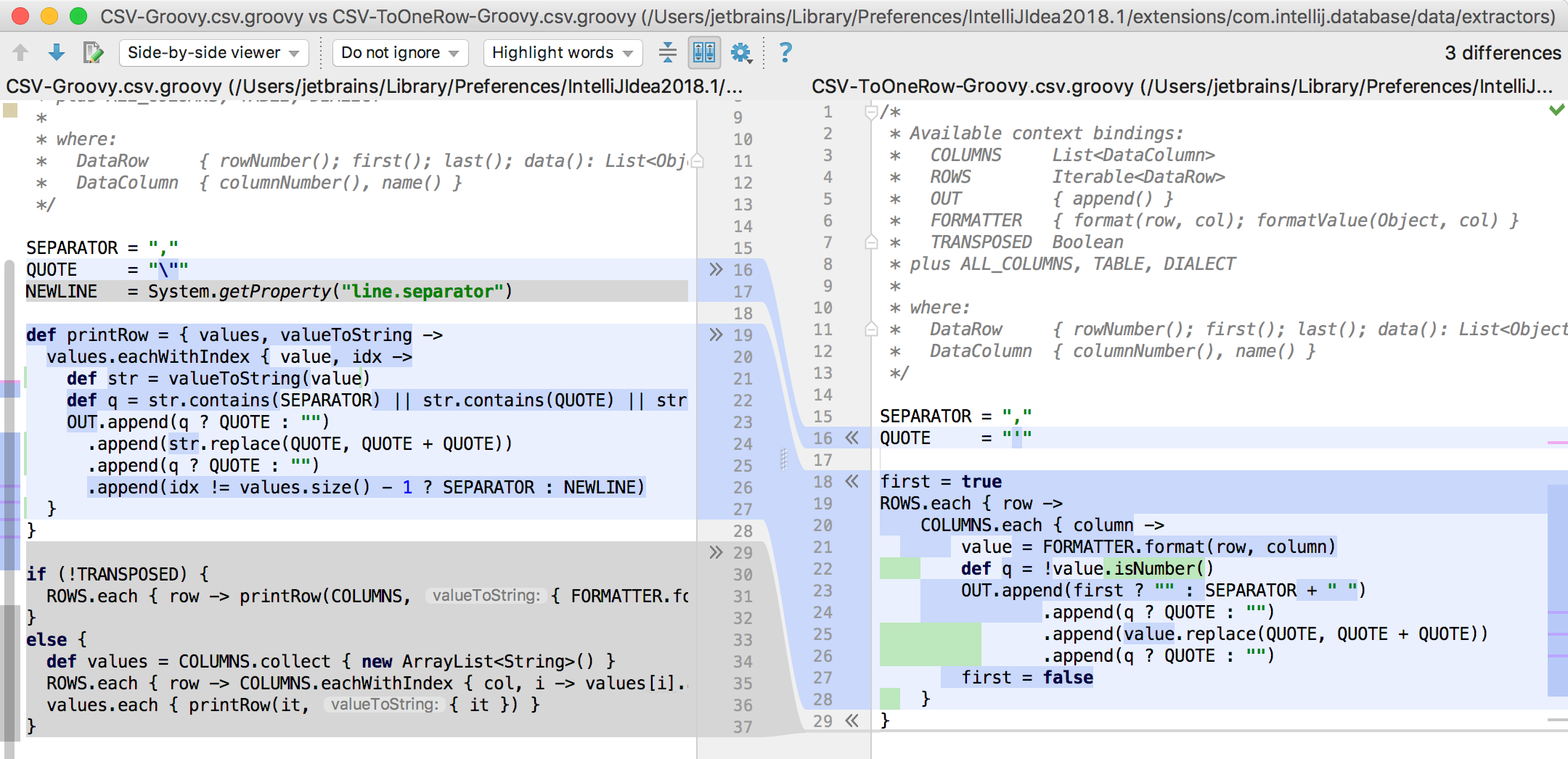
Available in context:
The DasTable has two important methods:
Up to version 2017.3:
Starting from 2017.3:
Read more about the API here .
If you do this in IntelliJ IDEA with Groovy installed, the backlight and autocompletion will work:

Put the new script in the folder and go: it is ready for use and is visible in the menu.
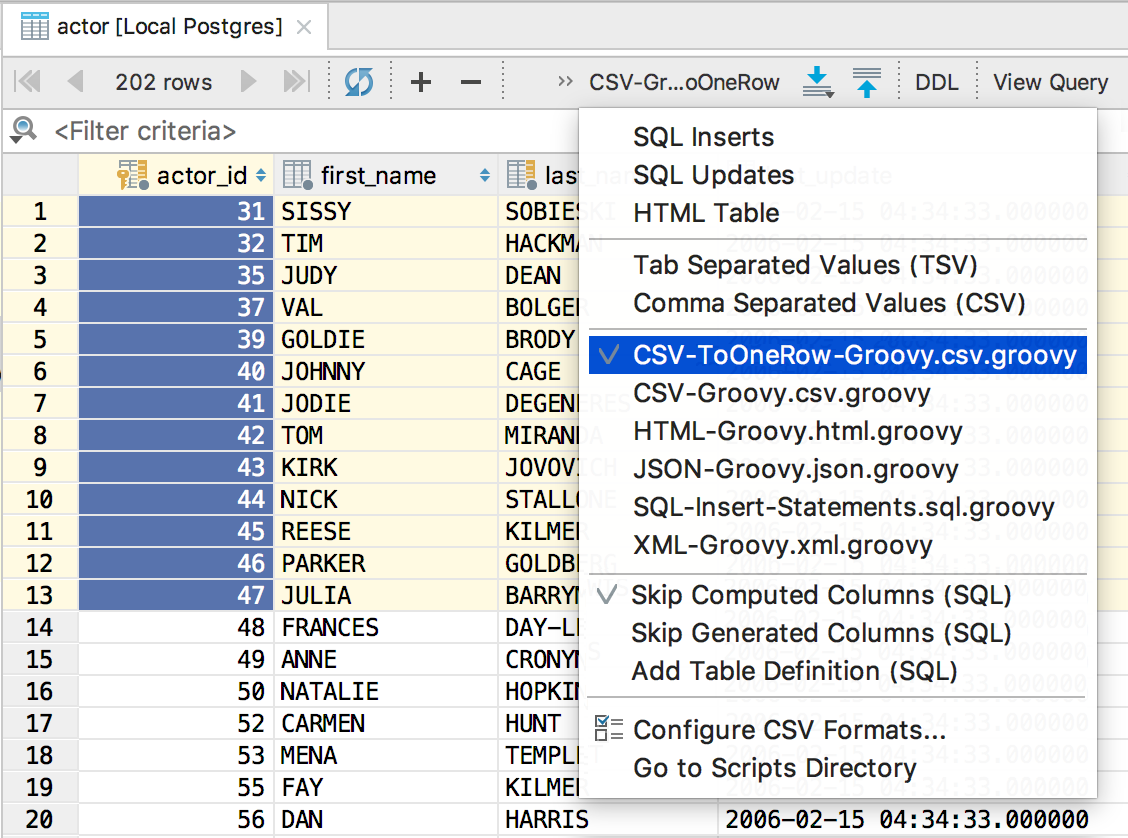
For example, copy these values and paste into the query.

Another example: in MySQL and PostgreSQL, multiline syntax for INSERT is allowed. Changing the current extractor for INSERTs, we get a new file: SQL-Inserts-MultirowSynthax.sql.groovy .
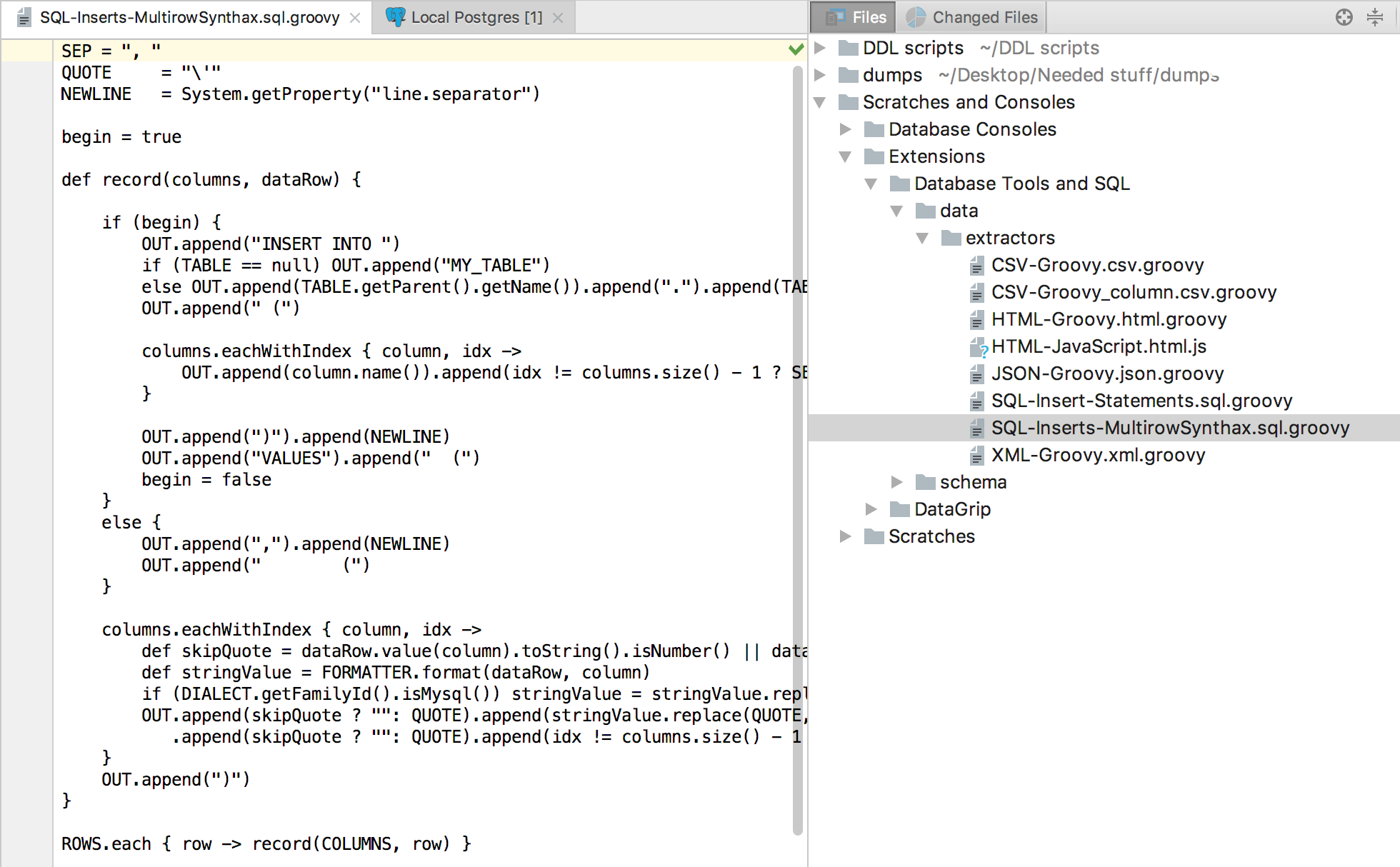
Select the newly created extractor, copy the data.
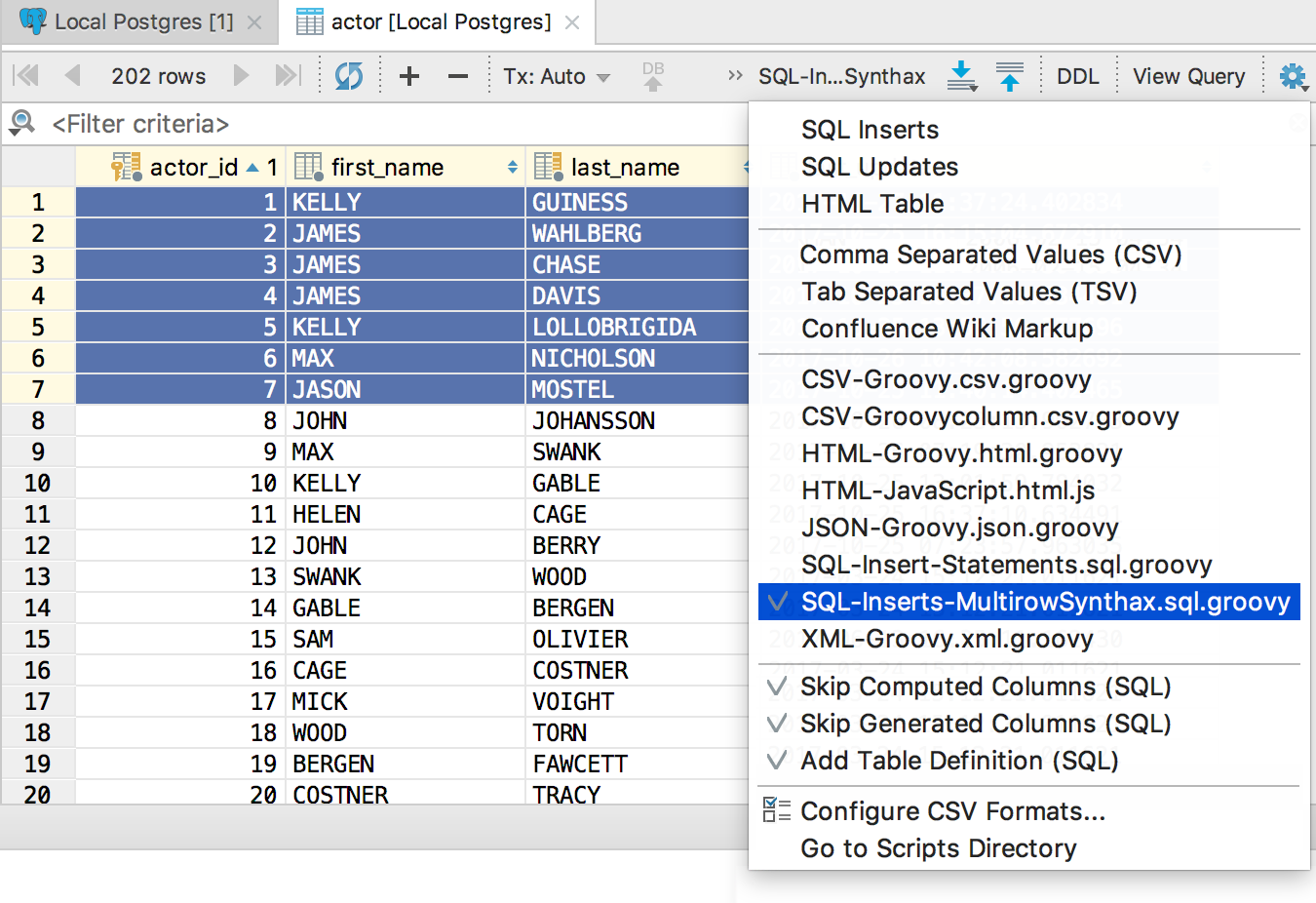
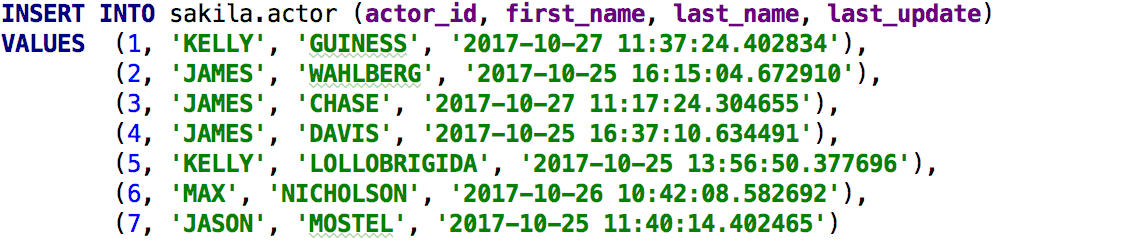
Done:
Some users have already figured out this and wrote their extractors:
- Text table . ( Looking like ).
- Php array .
- Markdown .
- DBunit XML .
It will be great if this text inspires you to write your extractors and share them with others!
DataGrip command
Export directions
A table, view, or result can be exported to a file or clipboard.
Export to file:
- Context menu on a table or view in the tree → Dump data to file.
- Context menu on request in the editor → Execute to file.
- In the toolbar of the data or result editor, click the Dump data → To File button ...
')
Export to clipboard:
- Select the data to export in the data editor or the result and press Copy or Ctrl / Cmd + C.
- In the result toolbar or data editor, click Dump data → To File ...
Default formats
Some formats are configured by default. We call the export mechanism itself “extractor”: several extractors for different formats are already built into the IDE. For example, consider exporting data to the clipboard, but it works for exporting to a file.
In the menu to the left of the Dump Data button, select the extractor.
A set of INSERT / UPDATE requests or JSON, CSV, HTML - you decide. Here is described how the built-in extractors work, we will not focus on this.
It is logical that users want to expand the built-in features.
CSV based custom extractors
To create your own extractor for a CSV-based format (or, strictly speaking, DSV), in the same menu, click on Configure CSV formats ...
Here you can make changes to existing extractors or create your own. For example, Confluence Wiki Markup.
The saved new extractor will appear in the menu:
Creating an extractor in any format using scripts
For more complex cases, use scripts. Several built-in extractors are Groovy or JavaScript scripts: CSV-Groovy.csv.groovy , HTML-JavaScript.html.js, and others. We will use Groovy in our examples.
Let 's analyze the name of the CSV-Groovy.csv.groovy file :
CSV-Groovy - the name of the script.
csv - file extension with the result.
groovy - script file extension. If you edit it in IntelliJ IDEA, it will help to have code highlighting and autocompletion.
Scripts are usually located in `Scratches and Consoles / Extensions / Database Tools and SQL / data / extractors` . To get to this folder, click Go to scripts directory in the extractors selection menu.
Change existing extractors or add new ones to this folder. For example, create an extractor to export data in one line separated by commas. This is useful if values from a single column are inserted into an IN clause of a WHERE clause.
Based on the existing extractor, we created a new one: CSV-ToOneRow-Groovy.csv.groovy .
Available in context:
OUT {append()} // FORMATTER {format(row, col); formatValue(Object, col)} // TRANSPOSED Boolean // Transpose ( ) COLUMNS List<DataColumn> // ALL_COLUMNS List<DataColumn> // // , . ROWS Iterable<DataRow> // , : DataRow { rowNumber(); first(); last(); data(): List<Object>; value(column): Object } DataColumn { columnNumber(); name() } TABLE DasTable // The DasTable has two important methods:
Up to version 2017.3:
DasObject getDbParent() JBIterable<DasObject> getDbChildren(Class, ObjectKind) Starting from 2017.3:
DasObject getDasParent() JBIterable<DasObject> getDasChildren(ObjectKind) Read more about the API here .
If you do this in IntelliJ IDEA with Groovy installed, the backlight and autocompletion will work:
Put the new script in the folder and go: it is ready for use and is visible in the menu.
For example, copy these values and paste into the query.
Another example: in MySQL and PostgreSQL, multiline syntax for INSERT is allowed. Changing the current extractor for INSERTs, we get a new file: SQL-Inserts-MultirowSynthax.sql.groovy .
Select the newly created extractor, copy the data.
Done:
Some users have already figured out this and wrote their extractors:
- Text table . ( Looking like ).
- Php array .
- Markdown .
- DBunit XML .
It will be great if this text inspires you to write your extractors and share them with others!
DataGrip command
Source: https://habr.com/ru/post/342094/
All Articles