We design microservice architecture taking into account failures
Translation of the article Designing a Microservices Architecture for Failure .
Microservice architecture due to precisely defined boundaries of services allows you to isolate failures . However, as in any distributed system, there is a higher probability of problems at the network level, equipment or applications. As a consequence of service dependencies, any component may be temporarily unavailable to users. To minimize the impact of partial failures, we need to build services that are resistant to them, which can correctly respond to certain types of problems.
This article presents the most common techniques and architectural patterns for building and operating a highly available microservice system .
If you are not familiar with the templates mentioned here, then it is not at all necessary that you do something wrong. Building a reliable system always requires additional investments.
')
With this architecture, the application logic is transferred to the services, and the network layer is used for interaction between them. Interaction over the network, rather than through calls within memory, increases the latency and complexity of the system, which requires the cooperation of numerous physical and logical components. And the increasing complexity of a distributed system leads to the fact that the chances of the occurrence of certain network failures increase.
One of the main advantages of the microservice architecture in comparison with the monolithic one is that teams can independently design, develop and deploy services. They fully manage the entire life cycle of their services. It also means that teams do not have control over service dependencies, as they are usually managed by other people. When using the microservice architecture, you need to remember that the provider services may be temporarily unavailable due to jigsaw releases, configurations and various changes, since this does not depend on the developers, and the components change independently of each other.
One of the most attractive aspects of microservice architecture is the ability to isolate failures, and due to the fact that the components fail separately from each other, it is possible to achieve a gradual degradation of service (graceful service degradation). For example, when an application that allows sharing of photos fails, users may not be able to upload new images, but they will be able to view, edit and share existing photos.
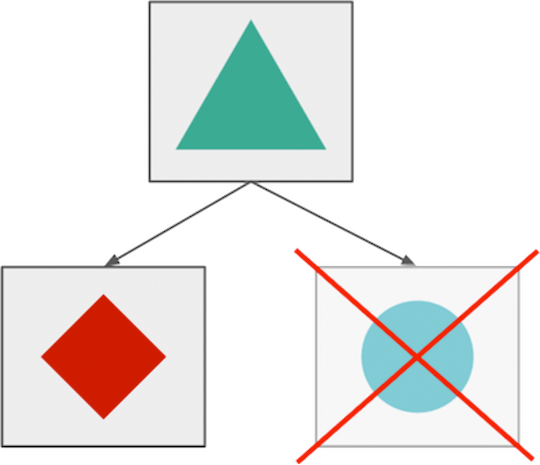
Separate failures of microservices (in theory).
However, in most cases it is difficult to implement this type of gradual degradation of service, because applications in distributed systems are dependent on each other, and you need to apply several different types of failure handling logic (some of them will be discussed below) to prepare for temporary difficulties and failures.

Without failure handling logic, services depend on each other and fail all together.
The Google reliability team found that about 70% of the failures are caused by changes in living systems. Changing something in your system — deploying a new version of the code or changing some configuration — you risk causing a crash or adding new bugs.
In microservice architecture, services depend on each other. Therefore, it is necessary to minimize failures and limit their negative impact. To cope with problems caused by changes, you can implement change management strategies and automatic rollbacks .
For example, when making changes, gradually apply them to a subset of your instances, track and automatically roll back the deployment if you notice a deterioration in key metrics.
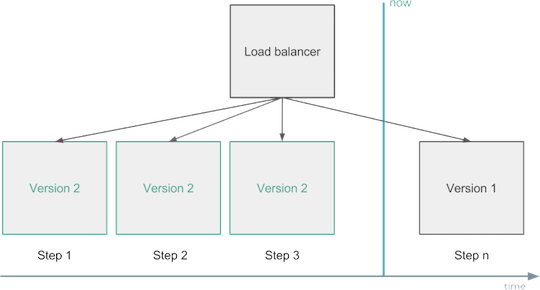
Change Management - Rolling Deployment.
Another solution would be to use two production-environments. Always deploy only one of them, and apply a load balancer to it only after making sure that the new version works as expected. This is called “blue-green” or “black-red” deployment.
Code rollback is not a problem . You can't leave broken code in production and then puzzle over what went wrong. Always roll back changes if necessary. The earlier the better.
Instances are constantly started, restarted and stopped due to crashes, deployments or autoscaling. And therefore become temporarily or permanently unavailable. To avoid such problems, your balancer should exclude failed instances from rotation if they cannot serve clients or other subsystems.
The health of application instances can be determined by external observation. You can do this with regular
You can “reanimate” the application using self-healing. You can talk about this mechanism in the event that the application performs the necessary actions to exit from the failed state. In most cases, self-healing is implemented by an external system that monitors the working capacity of the instances and restarts them if they are in a state of failure for a certain period. Self-healing is often very useful, but in some situations it can cause problems by constantly restarting the application. This is possible if the application cannot report a positive status due to overload or timeouts when connecting to the database.
It may be difficult to implement an advanced self-medication mechanism that will be ready for delicate situations like losing connection to the database. In this case, you need additional logic that will handle extreme cases and let the external system know that you do not need to restart the instance immediately.
Usually services fail due to network problems and system changes. However, most failures are temporary due to self-healing mechanisms and advanced balancing. And we need to find a solution that allows services to work during such incidents. Failover caching can help here, which will provide the necessary data to applications.
Failover caches typically use two different expiration times . A shorter one tells how long you can use the cache in a normal situation, and a longer one tells how long you can use cached data during a crash.
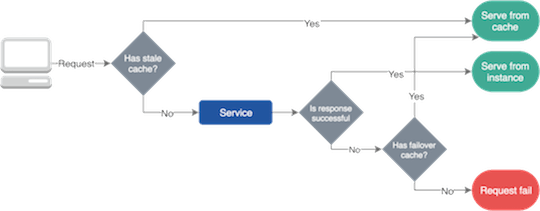
Failover caching.
It is important to mention that you can use fault-tolerant caching only when outdated data is better than nothing .
To configure the normal and fault-tolerant cache, you can use the standard HTTP response headers.
For example, using the
Modern CDN and balancers provide various caching and fault tolerance schemes, but you can also create a common library for your company that contains standard reliability solutions.
There are situations when we cannot cache data, or when we need to make changes to them, but our operations fail. Then you can try to repeat our actions , if there is a chance that resources will be restored some time later, or if our balancer sends our requests to the working instance.
Be careful with adding replay logic to your applications and clients, because a large number of repetitions can worsen the situation or even prevent applications from recovering.
In a distributed system, repeats in the microservice structure can generate numerous answers or other repetitions, which will create a cascade effect . To minimize the effect of repetitions, limit their number and use the exponential delay algorithm to increase the delay between repetitions each time until you reach the limit.
Since the replay is initiated by the client (browser, other microservice, and so on), who does not know whether the operation failed before or after processing the request, the application must be able to handle idempotency . For example, when you repeat a purchase operation, you should not duplicate the collection of funds from the buyer. You will be helped by using a unique idempotency key for each transaction.
Speed limit is a technique for determining the number of requests that can be accepted or processed by a specific consumer or application within a certain time. Using the speed limit, we can, for example, filter out our customers and microservices, because of which there are surges in traffic . Or we can make sure that the application will not be overloaded until autoscaling comes to the rescue.
You can also restrict low priority traffic to allocate more resources to critical transactions.
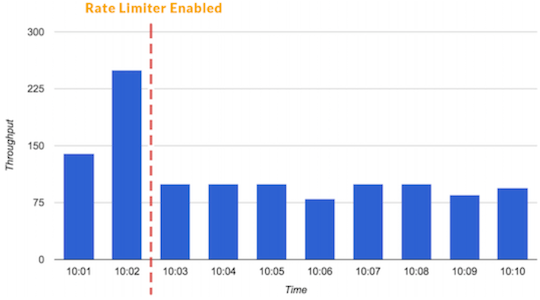
A speed limiter can prevent traffic spikes.
Another type of speed limiter is called a concurrent request limiter. It can be useful when you have “expensive” endpoints that are not recommended to be called more than a certain number of times if you want to serve traffic.
To always have the resources to handle critical transactions , use fleet usage load shedder. It holds part of the resources for high-priority requests and does not allow low-priority transactions to use them. Load shedder makes its decisions based on the overall state of the system, rather than the size of a single user request. LSs will also help your system recover , as they provide key functionality during the incident.
You can read more about speed limiters and load shedders in this article: https://stripe.com/blog/rate-limiters .
In the microservice architecture, you need to prepare your services to fail quickly and separately . To isolate problems at the service level, we can use the bulkhead template .
A quick component failure is needed because we don’t want to wait for the timeouts of the broken instances to end. Nothing is as annoying as a hung query and an interface that does not respond to your actions. This is not only lost resources, but also a spoiled user experience. Services cause each other in a chain, so you need to pay special attention to the prevention of hanging operations, avoiding the accumulation of delays.
Probably, you immediately got the idea of applying small timeouts (fine grade timeouts) for each service call. But the problem is that you cannot know what timeout value will be appropriate, because there are situations when network failures and other problems that occur affect only one or two operations. In this case, you probably don’t want to reject these requests due to the fact that some of them are timed out.
It can be said that the use of the “rapid failure” paradigm in microservices through timeouts is an antipattern that should be avoided. Instead of timeouts, you can use the circuit-breaker pattern, which depends on the statistics of successful / failed operations.
Bulkheads are used in shipbuilding to divide a ship into sections so that each section can be battened in the event of a hull breakdown.
The bulkhead principle can be applied in software development to share resources to protect them from exhaustion . For example, if we have two types of operations that interact with one database instance that has a limit on the number of connections, then you can use two connection pools instead of one common. As a result of this “client – resource” separation, an operation that initiates a timeout or abuses the pool will not affect the operation of other operations.
One of the main reasons for the death of the "Titanic" was the unsuccessful design of the bulkheads, in which water could flow over the decks into other compartments, filling the entire hull.
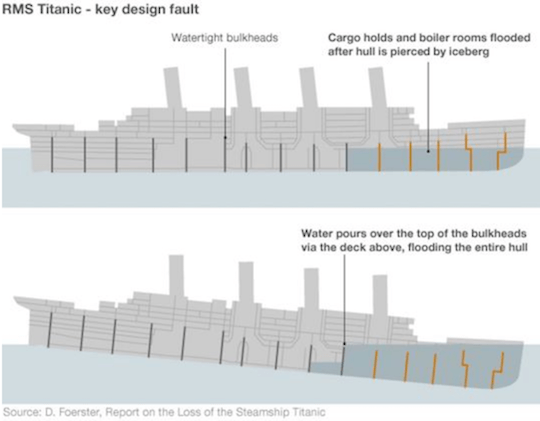
Bulkheads on the "Titanic" (they did not work).
Timeouts can be used to limit the duration of operations. They can prevent operations from hanging up and keep the system responding to your actions. The use of static, finely tuned timeouts in the microservice architecture is antipattern , since we are talking about a highly dynamic environment in which it is almost impossible to find suitable time constraints that work well in all situations.
Instead of using small, transaction-dependent timeouts, you can use circuit breakers for error handling. The action of these software mechanisms is similar to the electrotechnical devices of the same name. With the help of circuit breakers, you can protect resources and help them recover . They can be very useful in distributed systems, where repeated failures can cause an avalanche effect that puts the entire system.
The circuit breaker opens when a certain type of error occurs several times in a short time. An open automaton prevents the transmission of requests - just like a real automaton interrupts an electrical circuit and prevents current from flowing through the wires. Circuit breakers usually close after a certain time, giving services a breather for recovery.
Remember that not all errors should initiate a circuit breaker. For example, you probably want to skip errors on the client side like requests with 4xx codes, but at the same time respond to server failures with 5xx codes. Some circuit breakers may be in a half-open state. This means that the service sends the first request to check the availability of the system, and the remaining requests are truncated. If the first request was successful, the machine goes into the closed state and does not prevent the flow of traffic. Otherwise, the machine remains open.
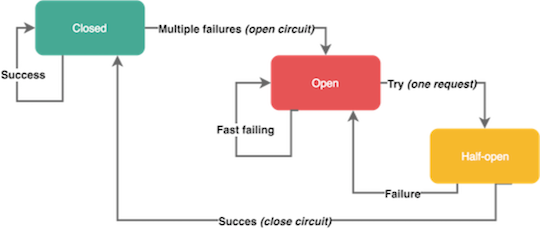
Automatic circuit.
You must constantly check the behavior of your system in the face of common problems to make sure that your services can survive various failures . Test frequently so your team is ready for incidents.
You can use an external service that identifies the group of instances and randomly interrupts the work of one of the group members. So you will be ready to crash a single instance. Or you can overlap entire regions to emulate a crash with a cloud provider.
One of the most popular solutions is the ChaosMonkey fault tolerance tool .
Implementing and maintaining reliable service is not an easy task. It requires a lot of effort and costs a lot of money.
Reliability has different levels and aspects, so it is important to find a solution that is best suited for your team. Make reliability one of the factors in the process of making business decisions and allocate enough money and time for this.
Microservice architecture due to precisely defined boundaries of services allows you to isolate failures . However, as in any distributed system, there is a higher probability of problems at the network level, equipment or applications. As a consequence of service dependencies, any component may be temporarily unavailable to users. To minimize the impact of partial failures, we need to build services that are resistant to them, which can correctly respond to certain types of problems.
This article presents the most common techniques and architectural patterns for building and operating a highly available microservice system .
If you are not familiar with the templates mentioned here, then it is not at all necessary that you do something wrong. Building a reliable system always requires additional investments.
')
The risk of microservice architecture
With this architecture, the application logic is transferred to the services, and the network layer is used for interaction between them. Interaction over the network, rather than through calls within memory, increases the latency and complexity of the system, which requires the cooperation of numerous physical and logical components. And the increasing complexity of a distributed system leads to the fact that the chances of the occurrence of certain network failures increase.
One of the main advantages of the microservice architecture in comparison with the monolithic one is that teams can independently design, develop and deploy services. They fully manage the entire life cycle of their services. It also means that teams do not have control over service dependencies, as they are usually managed by other people. When using the microservice architecture, you need to remember that the provider services may be temporarily unavailable due to jigsaw releases, configurations and various changes, since this does not depend on the developers, and the components change independently of each other.
Gradual degradation of service
One of the most attractive aspects of microservice architecture is the ability to isolate failures, and due to the fact that the components fail separately from each other, it is possible to achieve a gradual degradation of service (graceful service degradation). For example, when an application that allows sharing of photos fails, users may not be able to upload new images, but they will be able to view, edit and share existing photos.
Separate failures of microservices (in theory).
However, in most cases it is difficult to implement this type of gradual degradation of service, because applications in distributed systems are dependent on each other, and you need to apply several different types of failure handling logic (some of them will be discussed below) to prepare for temporary difficulties and failures.
Without failure handling logic, services depend on each other and fail all together.
Change management
The Google reliability team found that about 70% of the failures are caused by changes in living systems. Changing something in your system — deploying a new version of the code or changing some configuration — you risk causing a crash or adding new bugs.
In microservice architecture, services depend on each other. Therefore, it is necessary to minimize failures and limit their negative impact. To cope with problems caused by changes, you can implement change management strategies and automatic rollbacks .
For example, when making changes, gradually apply them to a subset of your instances, track and automatically roll back the deployment if you notice a deterioration in key metrics.
Change Management - Rolling Deployment.
Another solution would be to use two production-environments. Always deploy only one of them, and apply a load balancer to it only after making sure that the new version works as expected. This is called “blue-green” or “black-red” deployment.
Code rollback is not a problem . You can't leave broken code in production and then puzzle over what went wrong. Always roll back changes if necessary. The earlier the better.
Health Check and Load Balancing
Instances are constantly started, restarted and stopped due to crashes, deployments or autoscaling. And therefore become temporarily or permanently unavailable. To avoid such problems, your balancer should exclude failed instances from rotation if they cannot serve clients or other subsystems.
The health of application instances can be determined by external observation. You can do this with regular
GET /health endpoint calls or by automatically sending reports. Modern solutions for service discovery constantly collect health information from the instances and configure balancers to allow traffic only to fully functioning components.Self-healing
You can “reanimate” the application using self-healing. You can talk about this mechanism in the event that the application performs the necessary actions to exit from the failed state. In most cases, self-healing is implemented by an external system that monitors the working capacity of the instances and restarts them if they are in a state of failure for a certain period. Self-healing is often very useful, but in some situations it can cause problems by constantly restarting the application. This is possible if the application cannot report a positive status due to overload or timeouts when connecting to the database.
It may be difficult to implement an advanced self-medication mechanism that will be ready for delicate situations like losing connection to the database. In this case, you need additional logic that will handle extreme cases and let the external system know that you do not need to restart the instance immediately.
Failover caching (failover caching)
Usually services fail due to network problems and system changes. However, most failures are temporary due to self-healing mechanisms and advanced balancing. And we need to find a solution that allows services to work during such incidents. Failover caching can help here, which will provide the necessary data to applications.
Failover caches typically use two different expiration times . A shorter one tells how long you can use the cache in a normal situation, and a longer one tells how long you can use cached data during a crash.
Failover caching.
It is important to mention that you can use fault-tolerant caching only when outdated data is better than nothing .
To configure the normal and fault-tolerant cache, you can use the standard HTTP response headers.
For example, using the
max-age header, you can set the time during which the resource will be considered fresh. And with the help of the stale-if-error header - how long the resource will be provided from the cache in case of failure.Modern CDN and balancers provide various caching and fault tolerance schemes, but you can also create a common library for your company that contains standard reliability solutions.
Retry Logic
There are situations when we cannot cache data, or when we need to make changes to them, but our operations fail. Then you can try to repeat our actions , if there is a chance that resources will be restored some time later, or if our balancer sends our requests to the working instance.
Be careful with adding replay logic to your applications and clients, because a large number of repetitions can worsen the situation or even prevent applications from recovering.
In a distributed system, repeats in the microservice structure can generate numerous answers or other repetitions, which will create a cascade effect . To minimize the effect of repetitions, limit their number and use the exponential delay algorithm to increase the delay between repetitions each time until you reach the limit.
Since the replay is initiated by the client (browser, other microservice, and so on), who does not know whether the operation failed before or after processing the request, the application must be able to handle idempotency . For example, when you repeat a purchase operation, you should not duplicate the collection of funds from the buyer. You will be helped by using a unique idempotency key for each transaction.
Speed Limit and Load Shedders
Speed limit is a technique for determining the number of requests that can be accepted or processed by a specific consumer or application within a certain time. Using the speed limit, we can, for example, filter out our customers and microservices, because of which there are surges in traffic . Or we can make sure that the application will not be overloaded until autoscaling comes to the rescue.
You can also restrict low priority traffic to allocate more resources to critical transactions.
A speed limiter can prevent traffic spikes.
Another type of speed limiter is called a concurrent request limiter. It can be useful when you have “expensive” endpoints that are not recommended to be called more than a certain number of times if you want to serve traffic.
To always have the resources to handle critical transactions , use fleet usage load shedder. It holds part of the resources for high-priority requests and does not allow low-priority transactions to use them. Load shedder makes its decisions based on the overall state of the system, rather than the size of a single user request. LSs will also help your system recover , as they provide key functionality during the incident.
You can read more about speed limiters and load shedders in this article: https://stripe.com/blog/rate-limiters .
Fail quickly and separately
In the microservice architecture, you need to prepare your services to fail quickly and separately . To isolate problems at the service level, we can use the bulkhead template .
A quick component failure is needed because we don’t want to wait for the timeouts of the broken instances to end. Nothing is as annoying as a hung query and an interface that does not respond to your actions. This is not only lost resources, but also a spoiled user experience. Services cause each other in a chain, so you need to pay special attention to the prevention of hanging operations, avoiding the accumulation of delays.
Probably, you immediately got the idea of applying small timeouts (fine grade timeouts) for each service call. But the problem is that you cannot know what timeout value will be appropriate, because there are situations when network failures and other problems that occur affect only one or two operations. In this case, you probably don’t want to reject these requests due to the fact that some of them are timed out.
It can be said that the use of the “rapid failure” paradigm in microservices through timeouts is an antipattern that should be avoided. Instead of timeouts, you can use the circuit-breaker pattern, which depends on the statistics of successful / failed operations.
Bulkheads
Bulkheads are used in shipbuilding to divide a ship into sections so that each section can be battened in the event of a hull breakdown.
The bulkhead principle can be applied in software development to share resources to protect them from exhaustion . For example, if we have two types of operations that interact with one database instance that has a limit on the number of connections, then you can use two connection pools instead of one common. As a result of this “client – resource” separation, an operation that initiates a timeout or abuses the pool will not affect the operation of other operations.
One of the main reasons for the death of the "Titanic" was the unsuccessful design of the bulkheads, in which water could flow over the decks into other compartments, filling the entire hull.
Bulkheads on the "Titanic" (they did not work).
Circuit Breakers
Timeouts can be used to limit the duration of operations. They can prevent operations from hanging up and keep the system responding to your actions. The use of static, finely tuned timeouts in the microservice architecture is antipattern , since we are talking about a highly dynamic environment in which it is almost impossible to find suitable time constraints that work well in all situations.
Instead of using small, transaction-dependent timeouts, you can use circuit breakers for error handling. The action of these software mechanisms is similar to the electrotechnical devices of the same name. With the help of circuit breakers, you can protect resources and help them recover . They can be very useful in distributed systems, where repeated failures can cause an avalanche effect that puts the entire system.
The circuit breaker opens when a certain type of error occurs several times in a short time. An open automaton prevents the transmission of requests - just like a real automaton interrupts an electrical circuit and prevents current from flowing through the wires. Circuit breakers usually close after a certain time, giving services a breather for recovery.
Remember that not all errors should initiate a circuit breaker. For example, you probably want to skip errors on the client side like requests with 4xx codes, but at the same time respond to server failures with 5xx codes. Some circuit breakers may be in a half-open state. This means that the service sends the first request to check the availability of the system, and the remaining requests are truncated. If the first request was successful, the machine goes into the closed state and does not prevent the flow of traffic. Otherwise, the machine remains open.
Automatic circuit.
Check for failures
You must constantly check the behavior of your system in the face of common problems to make sure that your services can survive various failures . Test frequently so your team is ready for incidents.
You can use an external service that identifies the group of instances and randomly interrupts the work of one of the group members. So you will be ready to crash a single instance. Or you can overlap entire regions to emulate a crash with a cloud provider.
One of the most popular solutions is the ChaosMonkey fault tolerance tool .
Conclusion
Implementing and maintaining reliable service is not an easy task. It requires a lot of effort and costs a lot of money.
Reliability has different levels and aspects, so it is important to find a solution that is best suited for your team. Make reliability one of the factors in the process of making business decisions and allocate enough money and time for this.
Key findings
- For dynamic environments and distributed systems — such as microservices — there is an increased risk of disruption.
- Services should fail separately to ensure smooth degradation of the service and not collapse the user experience.
- 70% of failures are caused by changes, so do not be shy of code retracement.
- Failures must occur quickly and separately. The teams have no control over the dependencies of their services.
- Architectural patterns and techniques such as caching, bulkheads, circuit breakers, and speed limiters help create robust microservices.
Source: https://habr.com/ru/post/342058/
All Articles