Strava's global heatmap: now 6 times hotter
I am pleased to announce the first major update of the global heat map at Strava Labs since 2015. This update includes six times more data than before - a total of 1 billion activities from the entire Strava base through September 2017.
Our global heatmap is the largest and most detailed, and it is the world's finest data set of this kind. This is a direct visualization of the activities of Strava’s global network of athletes. To give an idea of the scale, the new heatmap includes:

Moscow heat map demonstrates pan / tilt function in Mapbox GL
In addition to simply increasing the amount of data, we completely rewrote the heat map code. This has significantly improved the quality of rendering. On the highlighted areas (highlights) the resolution is doubled. The rasterization of activity data is carried out by routes, not by points. Also improved the technique of normalization, which gives a more detailed and beautiful visualization.
')
Heat maps are already available on Strava Labs and Strava Route Builder . The rest of the article is devoted to a more detailed technical description of this update.
Two technical problems prevented the renewal of the heatmap:
The heatmap generation code was completely rewritten using Apache Spark and Scala. The new code uses a new infrastructure with mass access to the activity stream and supports parallelization at each stage from start to finish. After these changes, we completely solved all the scaling problems. A complete global heatmap is built on several hundred machines in just a few hours, with a total computational cost of just a few hundred dollars. In the future, the changes will allow to update the heat map on a regular basis.
In other parts of this article, we describe in detail how each stage of the Spark task of creating a heat map works, and also describes specific improvements to rendering.
Input streams with source activity data come from the Spark / S3 / Parquet data storage. This data includes each of the 3 trillion GPS points ever downloaded to Strava. Several algorithms clean and filter this data.
On the platform, there are numerous restrictions to protect privacy , which must be respected:
Additional filters eliminate erroneous data. Activities with a running speed higher than reasonable are excluded from the thermal layer of the runners, because they were most likely erroneously marked as “running”. There are the same upper limits for maximum speed for cyclists to separate them from cars and airplanes.
Data on fixed objects has an undesirable side effect - they show addresses where people live or work. A new algorithm is much better at identifying stopping points for athletes. If the value of the time-averaged activity flow rate becomes too small at any time, then the corresponding points of this activity are filtered until the activity goes beyond a certain radius from the original stopping point.
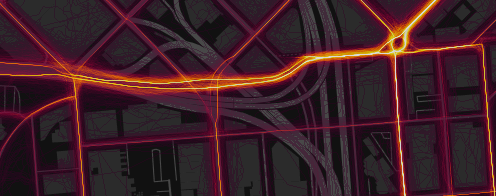
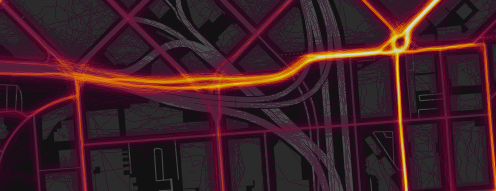
Comparison of rendering before (above) and after (below) the addition of artificial noise to eliminate artifacts from devices that adjust GPS data in accordance with the coordinates of the nearest road.
Many devices (primarily the iPhone) sometimes "correct" the GPS signal in residential areas, tying it to the known geometry of the road network, and not to real coordinates. This leads to an unsightly artifact, when on some streets the width of the thermal path is only one pixel. We are now correcting this by adding a random offset (from a normal distribution of two meters wide) to all points of each activity. This noise level is sufficient to suppress the artifact without noticeable blurring of other data.
We also exclude any “virtual” activities like the Zwift cycling race, because they include fake GPS data.
After filtering, the latitude / longitude coordinates of all points are transmitted to the Web Mercator Tile at zoom level 16. This level is a mosaic of 2 16 × 2 16 tiles in the world, each 256 × 256 pixels in size.
The old heat map rasterized each GPS point exactly one pixel. This approach has often been a hindrance, because the activity is recorded at a maximum speed of one data point per second. Because of this, visible artifacts often occur in areas with low activity: the recording speed is such that spaces appear between the pixels. In addition, there are deviations in areas where the movement of athletes slows down (compare the rise of the hill with the descent). As the additional, more detailed zoom level appeared on the new thermal card (the maximum spatial resolution was increased from 4 to 2 meters), the problem became even more noticeable. Instead of the old algorithm, the new map displays each activity as an ideal pixel route that combines continuous GPS points. The average segment length between two points at the 16th zoom level is 4 pixels, so the change is very noticeable.
To achieve this in parallel computations, it is necessary to handle the case when adjacent route points belong to different tiles. Each such pair of points is re-processed to include intermediate points along the route line on the border of each tile it crosses. After such processing, all segments of a straight line begin and end on the same tile or have zero length and can be skipped. Thus, we can present our data as direct products (Tile, Array [TilePixel]) , where Array [TilePixel] is a continuous series of coordinates that describes the route of each activity inside the tile. The data set is then grouped into tiles, so that all the data needed to draw each tile is mapped to one machine.
Each successive pair of pixels in the tile is then rasterized as a line segment using the Bresenham algorithm . This stage of drawing a segment should be extremely fast, since it is launched trillions of times. The tile itself at this stage is simply an array of Array [Double] (256 * 256) , representing the total number of segments that include each pixel.
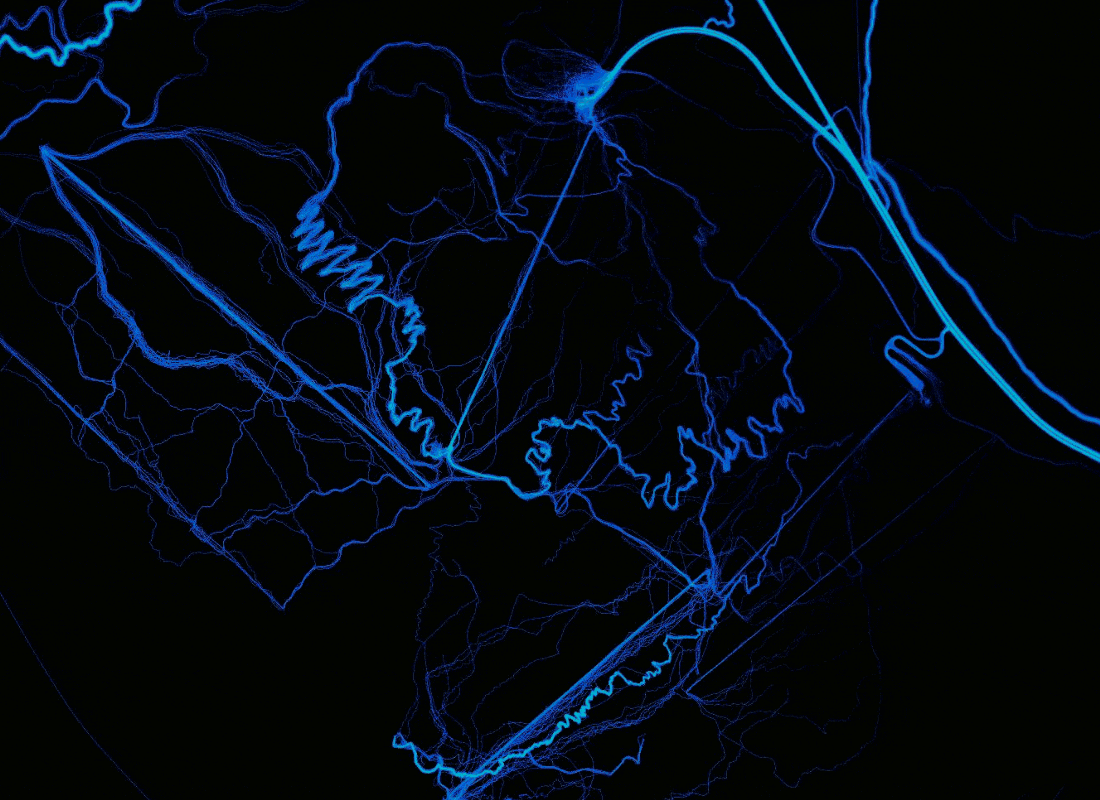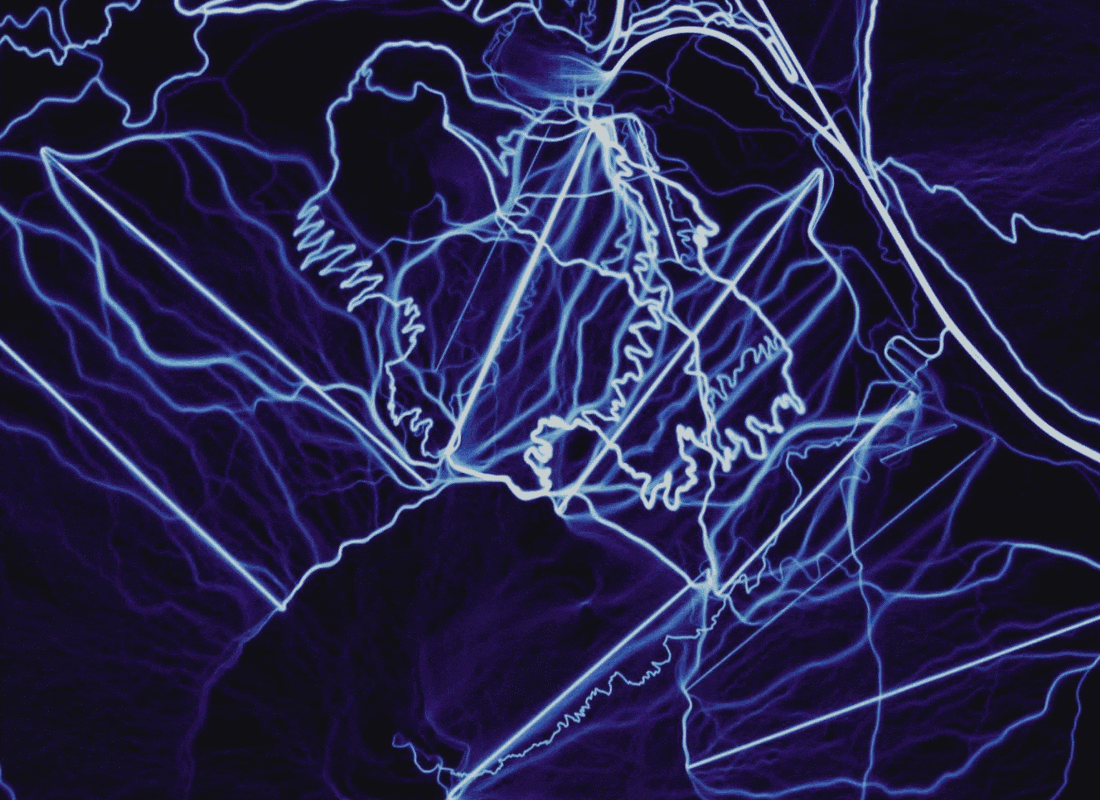
Comparison of rendering shows the advantages of rasterizing paths over points and adding additional data. Location: Bachelor Volcano, Oregon .
On the largest zoom we fill out over 60 million tiles. This presents a problem, because direct storage in memory of each tile in the form of double arrays will require a minimum of 60 million × 256 × 256 × 8 bytes = ~ 30 terabytes of memory. Although this amount of memory can be allocated in a temporary cluster, it will be a waste of resources, given that tiles usually allow strong compression, because the main part of pixel values is zero. For performance reasons, we decided that a sparse array would not be an effective solution. In Spark, you can greatly reduce the maximum amount of memory needed if you organize at this stage parallelism, which is many times more than the number of active tasks in the cluster. Tiles from the completed task are immediately converted, compressed and written to disk, so that at any given moment only a set of tiles corresponding to the active set of tasks is stored in uncompressed form in memory.
Normalization is a function that compares the initial heat value for each pixel after rasterization from the unrestricted area [0, Inf) to the bounded area [0, 1] of the color map. The choice of the normalization method greatly influences how the heatmap looks. This function should be monotonous in order for higher values to correspond to stronger “heat”, but there are many ways to tackle this problem. If we apply a single globalization function to the entire map, then the color for the maximum level of heat will be displayed only in the most popular areas of Strava.
The method of smooth normalization (slick normalization) involves calculating the CDF (distribution function) for the original values. Thus, the normalized value of this pixel will be the percentage of pixels with the lowest heat level. This method provides maximum contrast, guaranteeing the same number of pixels of each color. In photo processing, this technique is called histogram alignment . We use it with small changes to avoid quantization artifacts in less visited areas.
Calculating the CDF for the initial heat values in only one tile will not give a very good result in practice, because the screen usually displays a map of at least 5 × 5 tiles (256 × 256 pixels each). Therefore, we compute the total CDF for a tile using its heat values and the values of neighboring areas within a radius of five tiles. This ensures that the normalization function can only be changed to a scale larger than the size of the normal viewing screen.
In real computation, for the sake of performance, an approximate CDF is used: for this, input data are simply sorted, from which a certain number of samples are taken. We found that it is better to calculate the offset CDF, taking more samples towards the end of the array. This is because, in most cases, interesting heat data is contained only in a small part of the pixels.

Comparison of normalization methods (left: old, right: new) on a 33% zoom to get a better look at the effect. The new method guarantees visibility on one image of any range of source data on heat. In addition, the bilinear interpolation of the normalization function between tiles prevents any visible artifacts at the boundaries of the tiles. Location: San Francisco Bay Area .
The advantage of this approach is that the heatmap is ideally evenly distributed by color. In a sense, this leads to the fact that the heatmap transmits the maximum information about the relative values of heat. We also subjectively believe that it looks really beautiful.
The disadvantage of this approach is that the heat map now does not correspond to absolute quantitative values. The same color corresponds to the same level of heat only at the local level. Therefore, for government agencies, planning, security and transport departments, we offer a more sophisticated Strava Metro product with an accurate quantitative version of the heat map.
So far, we have used the normalization function for each tile, which is a CDF of pixels within several neighboring tiles. However, the CDF is still hopping at the borders of the tiles, so that it looks like an ugly artifact, especially in areas with a large absolute heat gradient.
To solve this problem, we applied bilinear interpolation. The real value of each pixel is derived from the sum of the bilinear coefficients of the four nearest neighboring tiles: max (0, (1-x) (1-y)) , where x, y are the distances from the center of the tile. This interpolation requires more computational resources, because for each pixel you need to evaluate four CDF instead of one.
So far, we have only talked about generating heat at the same zoom level. When moving to other levels, the source data is simply added up — the four tiles merge into one with a resolution of a quarter of the source. Then the normalization process starts again. This continues until the last zoom level is reached (one tile for the whole world).
It is very exciting to see how the new stages of the Spark process capture less and less data in a geometrical progression, so the calculation requires exponentially less and less time. After spending about an hour calculating the first zoom level, the process effectively finished, calculating the last few levels in less than a second.

Zooming from a single tile in London (UK) to the whole world
As a result, the normalized heat data for each pixel occupies one byte, because we display the value on the color map, and the heat value is included in an array of 256 colors. This data is stored in S3, with the grouping of neighboring tiles in one file to reduce the total number of files on the hosting. At the time of the request, the server picks up and caches the corresponding meta-file from S3, then on the fly generates PNGs from the source data and the requested color map. Then our CDN (Cloudfront) caches all tile images.
Also made various updates frontend. Now we switched to Mapbox GL . Due to this, it became possible to smoothly zoom, as well as control bizarre turns and bends. We hope you enjoy exploring this updated heatmap .
Our global heatmap is the largest and most detailed, and it is the world's finest data set of this kind. This is a direct visualization of the activities of Strava’s global network of athletes. To give an idea of the scale, the new heatmap includes:
- 1 billion activities
- 3 trillion points of longitude / latitude
- 13 trillion pixels after rasterization
- 10 terabytes of raw data
- The total distance of the routes: 27 billion kilometers
- Record total activity time: 200 thousand years
- 5% of earth sushi is covered with tiles
Moscow heat map demonstrates pan / tilt function in Mapbox GL
In addition to simply increasing the amount of data, we completely rewrote the heat map code. This has significantly improved the quality of rendering. On the highlighted areas (highlights) the resolution is doubled. The rasterization of activity data is carried out by routes, not by points. Also improved the technique of normalization, which gives a more detailed and beautiful visualization.
')
Heat maps are already available on Strava Labs and Strava Route Builder . The rest of the article is devoted to a more detailed technical description of this update.
Prehistory
Two technical problems prevented the renewal of the heatmap:
- The previous version of the heatmap is written on a low-level C and designed to work on only one machine. Given this limitation, updating the heating card would take months.
- Accessing stream data requires one S3 request per activity, so reading the input for a billion activities would cost thousands of dollars and would be difficult to manage.
The heatmap generation code was completely rewritten using Apache Spark and Scala. The new code uses a new infrastructure with mass access to the activity stream and supports parallelization at each stage from start to finish. After these changes, we completely solved all the scaling problems. A complete global heatmap is built on several hundred machines in just a few hours, with a total computational cost of just a few hundred dollars. In the future, the changes will allow to update the heat map on a regular basis.
In other parts of this article, we describe in detail how each stage of the Spark task of creating a heat map works, and also describes specific improvements to rendering.
Input and Filtering
Input streams with source activity data come from the Spark / S3 / Parquet data storage. This data includes each of the 3 trillion GPS points ever downloaded to Strava. Several algorithms clean and filter this data.
On the platform, there are numerous restrictions to protect privacy , which must be respected:
- Private activities are immediately excluded from processing.
- Activity areas are cut off according to user-defined privacy zones.
- The data of athletes who turned off the Metro / heat card function in the privacy settings are completely excluded from the processing
Additional filters eliminate erroneous data. Activities with a running speed higher than reasonable are excluded from the thermal layer of the runners, because they were most likely erroneously marked as “running”. There are the same upper limits for maximum speed for cyclists to separate them from cars and airplanes.
Data on fixed objects has an undesirable side effect - they show addresses where people live or work. A new algorithm is much better at identifying stopping points for athletes. If the value of the time-averaged activity flow rate becomes too small at any time, then the corresponding points of this activity are filtered until the activity goes beyond a certain radius from the original stopping point.
Comparison of rendering before (above) and after (below) the addition of artificial noise to eliminate artifacts from devices that adjust GPS data in accordance with the coordinates of the nearest road.
Many devices (primarily the iPhone) sometimes "correct" the GPS signal in residential areas, tying it to the known geometry of the road network, and not to real coordinates. This leads to an unsightly artifact, when on some streets the width of the thermal path is only one pixel. We are now correcting this by adding a random offset (from a normal distribution of two meters wide) to all points of each activity. This noise level is sufficient to suppress the artifact without noticeable blurring of other data.
We also exclude any “virtual” activities like the Zwift cycling race, because they include fake GPS data.
Thermal rasterization
After filtering, the latitude / longitude coordinates of all points are transmitted to the Web Mercator Tile at zoom level 16. This level is a mosaic of 2 16 × 2 16 tiles in the world, each 256 × 256 pixels in size.
The old heat map rasterized each GPS point exactly one pixel. This approach has often been a hindrance, because the activity is recorded at a maximum speed of one data point per second. Because of this, visible artifacts often occur in areas with low activity: the recording speed is such that spaces appear between the pixels. In addition, there are deviations in areas where the movement of athletes slows down (compare the rise of the hill with the descent). As the additional, more detailed zoom level appeared on the new thermal card (the maximum spatial resolution was increased from 4 to 2 meters), the problem became even more noticeable. Instead of the old algorithm, the new map displays each activity as an ideal pixel route that combines continuous GPS points. The average segment length between two points at the 16th zoom level is 4 pixels, so the change is very noticeable.
To achieve this in parallel computations, it is necessary to handle the case when adjacent route points belong to different tiles. Each such pair of points is re-processed to include intermediate points along the route line on the border of each tile it crosses. After such processing, all segments of a straight line begin and end on the same tile or have zero length and can be skipped. Thus, we can present our data as direct products (Tile, Array [TilePixel]) , where Array [TilePixel] is a continuous series of coordinates that describes the route of each activity inside the tile. The data set is then grouped into tiles, so that all the data needed to draw each tile is mapped to one machine.
Each successive pair of pixels in the tile is then rasterized as a line segment using the Bresenham algorithm . This stage of drawing a segment should be extremely fast, since it is launched trillions of times. The tile itself at this stage is simply an array of Array [Double] (256 * 256) , representing the total number of segments that include each pixel.
Comparison of rendering shows the advantages of rasterizing paths over points and adding additional data. Location: Bachelor Volcano, Oregon .
On the largest zoom we fill out over 60 million tiles. This presents a problem, because direct storage in memory of each tile in the form of double arrays will require a minimum of 60 million × 256 × 256 × 8 bytes = ~ 30 terabytes of memory. Although this amount of memory can be allocated in a temporary cluster, it will be a waste of resources, given that tiles usually allow strong compression, because the main part of pixel values is zero. For performance reasons, we decided that a sparse array would not be an effective solution. In Spark, you can greatly reduce the maximum amount of memory needed if you organize at this stage parallelism, which is many times more than the number of active tasks in the cluster. Tiles from the completed task are immediately converted, compressed and written to disk, so that at any given moment only a set of tiles corresponding to the active set of tasks is stored in uncompressed form in memory.
Thermal normalization
Normalization is a function that compares the initial heat value for each pixel after rasterization from the unrestricted area [0, Inf) to the bounded area [0, 1] of the color map. The choice of the normalization method greatly influences how the heatmap looks. This function should be monotonous in order for higher values to correspond to stronger “heat”, but there are many ways to tackle this problem. If we apply a single globalization function to the entire map, then the color for the maximum level of heat will be displayed only in the most popular areas of Strava.
The method of smooth normalization (slick normalization) involves calculating the CDF (distribution function) for the original values. Thus, the normalized value of this pixel will be the percentage of pixels with the lowest heat level. This method provides maximum contrast, guaranteeing the same number of pixels of each color. In photo processing, this technique is called histogram alignment . We use it with small changes to avoid quantization artifacts in less visited areas.
Calculating the CDF for the initial heat values in only one tile will not give a very good result in practice, because the screen usually displays a map of at least 5 × 5 tiles (256 × 256 pixels each). Therefore, we compute the total CDF for a tile using its heat values and the values of neighboring areas within a radius of five tiles. This ensures that the normalization function can only be changed to a scale larger than the size of the normal viewing screen.
In real computation, for the sake of performance, an approximate CDF is used: for this, input data are simply sorted, from which a certain number of samples are taken. We found that it is better to calculate the offset CDF, taking more samples towards the end of the array. This is because, in most cases, interesting heat data is contained only in a small part of the pixels.
Comparison of normalization methods (left: old, right: new) on a 33% zoom to get a better look at the effect. The new method guarantees visibility on one image of any range of source data on heat. In addition, the bilinear interpolation of the normalization function between tiles prevents any visible artifacts at the boundaries of the tiles. Location: San Francisco Bay Area .
The advantage of this approach is that the heatmap is ideally evenly distributed by color. In a sense, this leads to the fact that the heatmap transmits the maximum information about the relative values of heat. We also subjectively believe that it looks really beautiful.
The disadvantage of this approach is that the heat map now does not correspond to absolute quantitative values. The same color corresponds to the same level of heat only at the local level. Therefore, for government agencies, planning, security and transport departments, we offer a more sophisticated Strava Metro product with an accurate quantitative version of the heat map.
Interpolation of normalization functions across tile boundaries
So far, we have used the normalization function for each tile, which is a CDF of pixels within several neighboring tiles. However, the CDF is still hopping at the borders of the tiles, so that it looks like an ugly artifact, especially in areas with a large absolute heat gradient.
To solve this problem, we applied bilinear interpolation. The real value of each pixel is derived from the sum of the bilinear coefficients of the four nearest neighboring tiles: max (0, (1-x) (1-y)) , where x, y are the distances from the center of the tile. This interpolation requires more computational resources, because for each pixel you need to evaluate four CDF instead of one.
Zoom recursion
So far, we have only talked about generating heat at the same zoom level. When moving to other levels, the source data is simply added up — the four tiles merge into one with a resolution of a quarter of the source. Then the normalization process starts again. This continues until the last zoom level is reached (one tile for the whole world).
It is very exciting to see how the new stages of the Spark process capture less and less data in a geometrical progression, so the calculation requires exponentially less and less time. After spending about an hour calculating the first zoom level, the process effectively finished, calculating the last few levels in less than a second.
Zooming from a single tile in London (UK) to the whole world
Extradition
As a result, the normalized heat data for each pixel occupies one byte, because we display the value on the color map, and the heat value is included in an array of 256 colors. This data is stored in S3, with the grouping of neighboring tiles in one file to reduce the total number of files on the hosting. At the time of the request, the server picks up and caches the corresponding meta-file from S3, then on the fly generates PNGs from the source data and the requested color map. Then our CDN (Cloudfront) caches all tile images.
Also made various updates frontend. Now we switched to Mapbox GL . Due to this, it became possible to smoothly zoom, as well as control bizarre turns and bends. We hope you enjoy exploring this updated heatmap .
Source: https://habr.com/ru/post/341900/
All Articles