A complete guide to writing a utility for Go

Some time ago I started making a utility that would simplify my life. It is called gomodifytags . The utility automatically fills the fields of structural tags (struct tag) with the help of field names. Example:
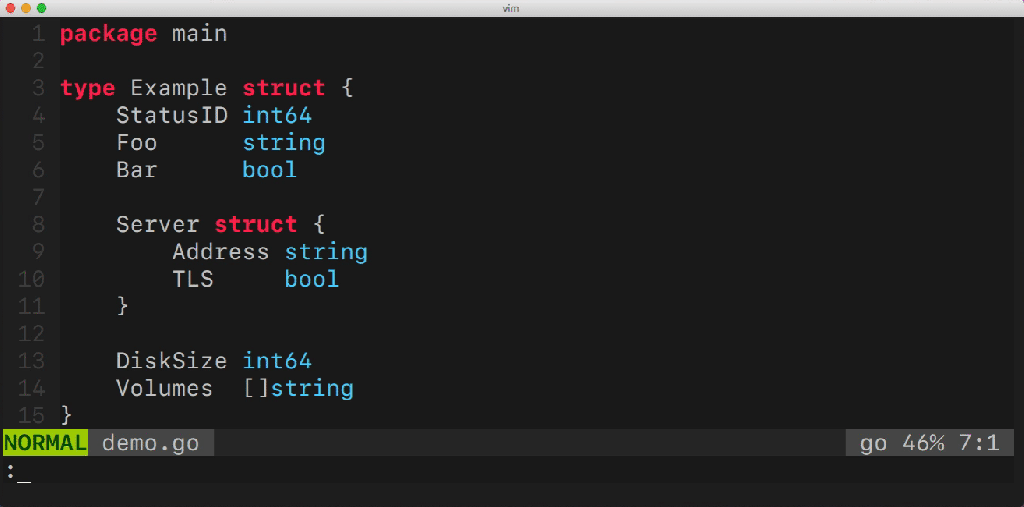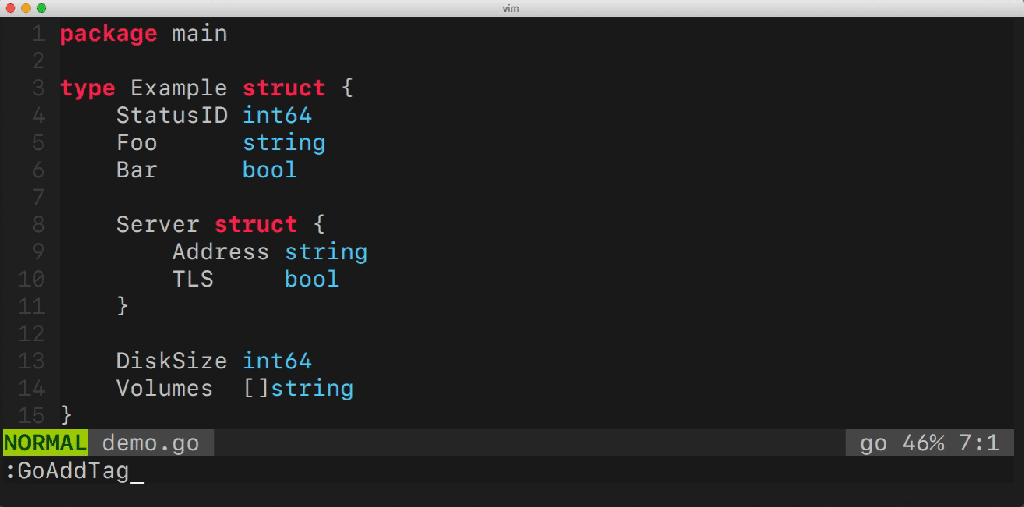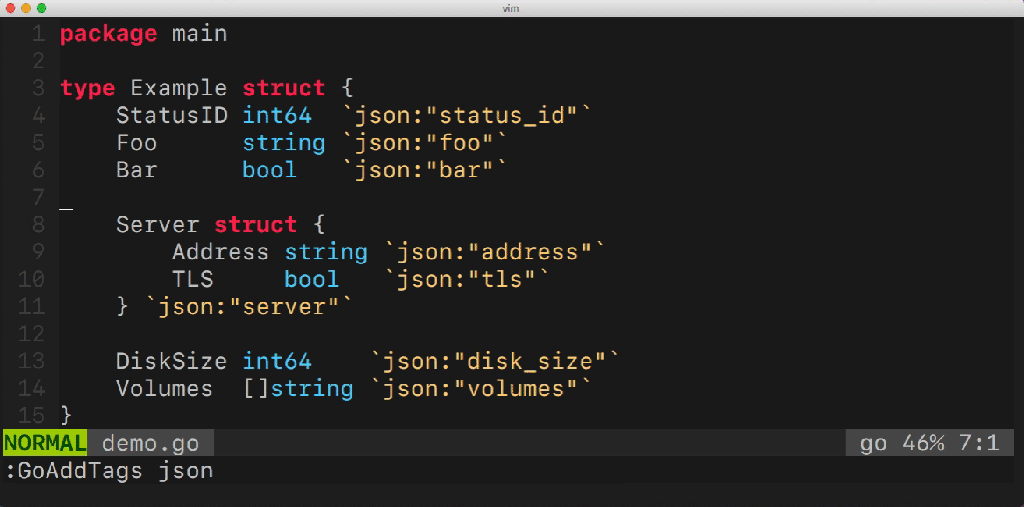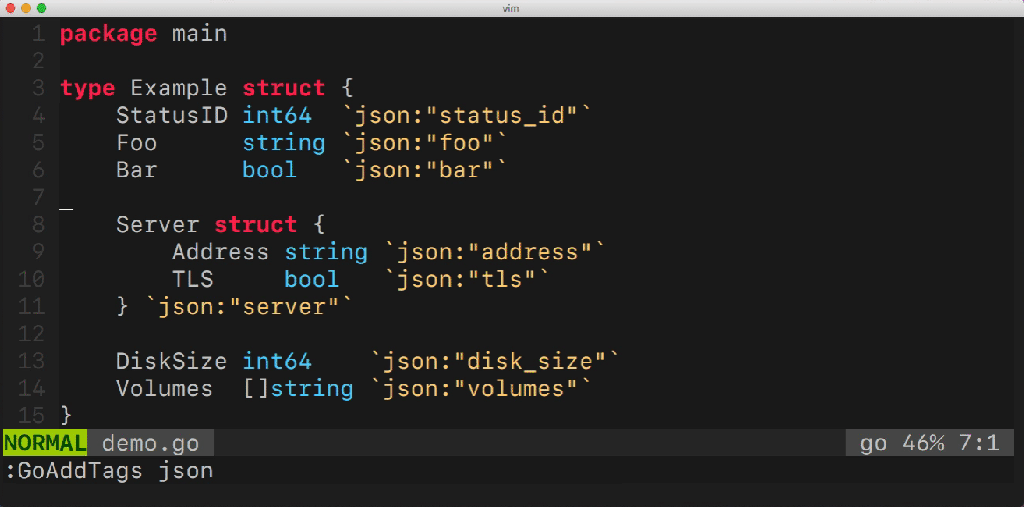
This utility facilitates the management of multiple fields of the structure. She can add and remove tags, manage their options (for example, omitempty), define transformation rules ( snake_case, camelCase , etc.) and much more. How does this utility work? What go-packages does she use? You probably have a lot of questions.
In this very long article I will talk in detail about how to write and build such a utility. Here you will find a lot of tips and tricks, as well as Go code.
Pour coffee and start reading!
First, let's figure out what the utility should do:
- Read the source file, understand it, convert to a Go-file.
- Find the appropriate structure.
- Get field names.
- Update structural tags with regard to field names (in accordance with the transformation rule, for example, snake_case ).
- And finally, make these changes to the file or give them to the programmer in a different, convenient way.
We begin with the definition of a structural tag , and then we will consistently build a utility, studying its parts and their interaction with each other.

The value tag (for example, its contents is json:"foo" ) is not mentioned in the official specification . But there is an informal specification in the package that defines this tag in a format that stdlib packages also use (like encoding / json ). Made it through the type reflect.StructTag :
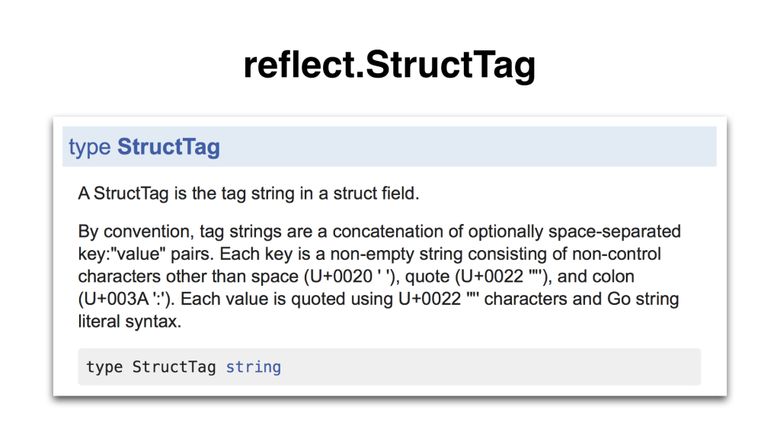
Definition is not easy, let's look at it:
- A structural tag is a string literal (because it refers to a string type).
- The key is a string literal, not enclosed in quotes .
- The value is a string literal enclosed in quotes .
- The key and value are separated by a colon (:) . Everything is called a key-value pair .
- A structure tag can contain several key-value pairs (if desired). Couples are separated by spaces .
- Setting options are not described in the definition. Packages like encoding / json read values in the form of a list, where commas are used as separators. Everything that comes after the first comma is part of the options. For example, the list “ foo, omitempty, string“ lists the value “foo” and the options [“omitempty”, “string”] .
- Since the structure tag is a string literal, it must be enclosed in double quotes or back quotes (left single quotes).
We repeat all these rules:

There are many unclear details in the definition of structural tags.
Now we know what the structure tag is, and we can easily change it as we need it. The question is, how can you now parse it so that it is easy to change? Fortunately, reflect.StructTag also has a method that allows you to parse the tag and return values for the specified key. Example:
package main import ( "fmt" "reflect" ) func main() { tag := reflect.StructTag(`species:"gopher" color:"blue"`) fmt.Println(tag.Get("color"), tag.Get("species")) } Displays:
blue gopher If the key does not exist, an empty string is returned.
Very useful, but there are limitations that make this opportunity useless for us, because we need a more flexible solution. List of restrictions:
- Does not recognize errors in the tag (for example, key in quotes, value without quotes, etc.).
- Does not recognize the semantics of options.
- Can not pass on existing tags or return them. You need to know in advance which tags we want to change. And if the name is unknown?
- Cannot modify existing tags.
- You cannot build new structural tags from scratch.
I wrote my Go package that fixes all the listed flaws and provides an API that makes it easy to change any parts of the structure tag.

The package is called structtag , you can download it from here: github.com/fatih/structtag . A package can accurately parse and modify tags . Below is a fully working example, you can copy it and test it:
package main import ( "fmt" "github.com/fatih/structtag" ) func main() { tag := `json:"foo,omitempty,string" xml:"foo"` // parse the tag tags, err := structtag.Parse(string(tag)) if err != nil { panic(err) } // iterate over all tags for _, t := range tags.Tags() { fmt.Printf("tag: %+v\n", t) } // get a single tag jsonTag, err := tags.Get("json") if err != nil { panic(err) } // change existing tag jsonTag.Name = "foo_bar" jsonTag.Options = nil tags.Set(jsonTag) // add new tag tags.Set(&structtag.Tag{ Key: "hcl", Name: "foo", Options: []string{"squash"}, }) // print the tags fmt.Println(tags) // Output: json:"foo_bar" xml:"foo" hcl:"foo,squash" } Now we can parse the structure tag, modify it and create a new one. Now you need to change the correct source Go file. In the above example, the tag is already there, but how do we get it from the existing Go-structure?
Answer: via AST . AST ( Abstract Syntax Tree, abstract syntax tree ) allows you to extract any identifier (node) from the source code. Below is a simplified tree of structural type:

Basic view of the go ast.Node structural type
In this tree, you can extract any identifier and manipulate it with a string, a bracket, etc. Each of them is represented by an AST node . For example, you can change the field name from “Foo” to “Bar” , replacing the node representing it. The same with the structural tag.
To get Go AST , you need to parse the source file and convert it to AST. All this is done in one step.
To parse the file, we will use the go / parser package (to build the entire file tree), and then use the go / ast package to go through the tree (manually, but this is a topic for a separate article). Here is a fully working example:
package main import ( "fmt" "go/ast" "go/parser" "go/token" ) func main() { src := `package main type Example struct { Foo string` + " `json:\"foo\"` }" fset := token.NewFileSet() file, err := parser.ParseFile(fset, "demo", src, parser.ParseComments) if err != nil { panic(err) } ast.Inspect(file, func(x ast.Node) bool { s, ok := x.(*ast.StructType) if !ok { return true } for _, field := range s.Fields.List { fmt.Printf("Field: %s\n", field.Names[0].Name) fmt.Printf("Tag: %s\n", field.Tag.Value) } return false }) } Result of performance:
Field: Foo Tag: `json:"foo"` What are we doing:
- Using a single structure, we define an example of a valid Go package.
- Use the go / parser package to parse this line. The package can also read a file (or the entire package) from disk.
- After parsing the file, go to our node (assigned to the file variable) and look for the AST node defined by * ast.StructType (see the AST scheme). Using the
ast.Inspect()function,ast.Inspect()go down the tree. The function iterates over all nodes until it finds the wrong value. It turns out very convenient, because we do not need to memorize nodes. - Display the structure field name and structure tag.
Now we can solve two important tasks . First, we know how to parse the source Go file and extract the structure tag (using go / parser). Secondly, we can parse the structure tag and modify it the way we need (using github.com/fatih/structtag ).
Now you can start building our utility (gomodifytags) using these two skills. She must:
- Get a configuration that indicates which structure needs to be changed.
- Find and modify this structure.
- Display the result.
Since gomodifytags will most often be executed by editors, we will transmit the configuration via CLI flags. The second stage consists of several steps, such as parsing a file, finding the correct structure and modifying it (through AST). Finally, we will output the result either to the original Go-file, or through some protocol (like JSON, we'll talk about it below).
Simplified gomodifytags main function:

Let's take a closer look at each step. I will try to tell simpler. Although everything is the same here, and having finished reading, you will be able to deal with the source code without any help (links to the sources are given at the end of the manual).
Let's start with getting the configuration . Below is a configuration that has all the necessary information.
type config struct { // first section - input & output file string modified io.Reader output string write bool // second section - struct selection offset int structName string line string start, end int // third section - struct modification remove []string add []string override bool transform string sort bool clear bool addOpts []string removeOpts []string clearOpt bool } The configuration consists of three sections.
The first contains settings that describe how and what file to read. This can be done through the file name from the local file system or directly from stdin (usually used when working in editors). Also in the first section it is indicated how to output the results (to the source Go file or JSON) and whether the file should be rewritten instead of output to stdout.
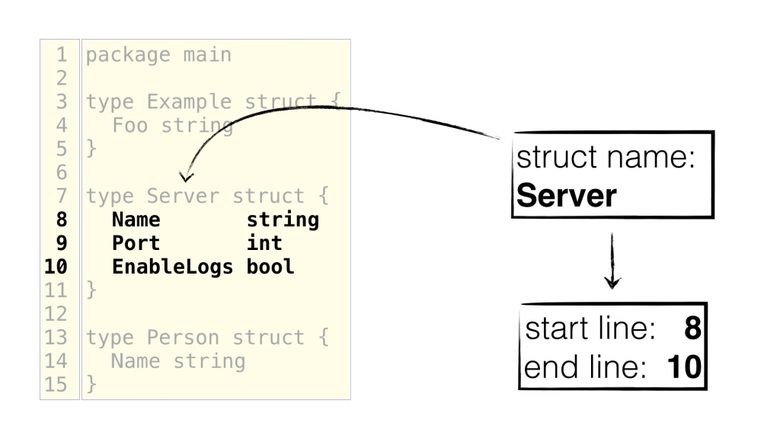
The second section shows how to choose a structure and its fields. This can be done in different ways: using an offset (cursor position), a structure name, a single line (which simply selects a field), or a range of lines. At the end, you must extract the starting and ending lines. The following shows how we select a structure by its name, and then retrieve the starting and ending rows to select the correct fields:
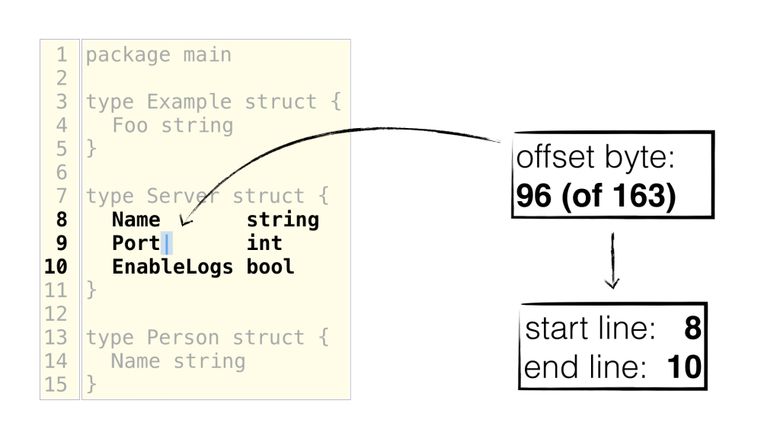
At the same time, it is more convenient for editors to use a byte offset . In the illustration below, the cursor stands immediately after the name of the field "Port" , where you can easily get the starting and ending lines:
The third section of the configuration is dedicated to transferring data to our structtag package. After reading all the fields, the configuration is transferred to the package structtag , which allows you to parse the structure tag and change its parts. However, the structure fields are not overwritten and not updated.
And how do we get the configuration? Take the flag package, create flags for each field in the configuration, and link them to them. For example:
flagFile := flag.String("file", "", "Filename to be parsed") cfg := &config{ file: *flagFile, } Do the same for each field in the configuration . A complete list of flag definitions can be found in the current gomodifytag wizard.
After getting the configuration, let's perform a basic check:
func main() { cfg := config{ ... } err := cfg.validate() if err != nil { log.Fatalln(err) } // continue parsing } // validate validates whether the config is valid or not func (c *config) validate() error { if c.file == "" { return errors.New("no file is passed") } if c.line == "" && c.offset == 0 && c.structName == "" { return errors.New("-line, -offset or -struct is not passed") } if c.line != "" && c.offset != 0 || c.line != "" && c.structName != "" || c.offset != 0 && c.structName != "" { return errors.New("-line, -offset or -struct cannot be used together. pick one") } if (c.add == nil || len(c.add) == 0) && (c.addOptions == nil || len(c.addOptions) == 0) && !c.clear && !c.clearOption && (c.removeOptions == nil || len(c.removeOptions) == 0) && (c.remove == nil || len(c.remove) == 0) { return errors.New("one of " + "[-add-tags, -add-options, -remove-tags, -remove-options, -clear-tags, -clear-options]" + " should be defined") } return nil } If the check is performed in one function, then it is easier to test it.
Let's go to the file parsing:
In the beginning we already talked about how to parse the file. In this case, the method in the config structure deals with parsing. In fact, all methods are part of this structure:
func main() { cfg := config{} node, err := cfg.parse() if err != nil { return err } // continue find struct selection ... } func (c *config) parse() (ast.Node, error) { c.fset = token.NewFileSet() var contents interface{} if c.modified != nil { archive, err := buildutil.ParseOverlayArchive(c.modified) if err != nil { return nil, fmt.Errorf("failed to parse -modified archive: %v", err) } fc, ok := archive[c.file] if !ok { return nil, fmt.Errorf("couldn't find %s in archive", c.file) } contents = fc } return parser.ParseFile(c.fset, c.file, contents, parser.ParseComments) } The parse function can only parse source code and return ast.Node . It's very simple, if we transfer the file, in our case the parser.ParseFile() function is used. Notice the token.NewFileSet() , which creates the type *token.FileSet . We store it in c.fset , but also pass it to the parser.ParseFile() function. Why?
Because the fileset is used to store information about the location of each node independently for each file. Later it will be very useful to get the exact location of ast.Node . (Note that ast.Node uses compact location information called token.Pos . If you decrypt token.Pos with the token.FileSet.Position() function , you get token.Position , which contains more information.)
Go ahead. The situation becomes more interesting if you transfer the source file through stdin. The config.modified field is an io.Reader for easy testing, but in fact we pass stdin. And how to determine what we want to read from stdin?
We ask the user if he wants to transfer content via stdin. In this case, the user needs to pass the --modified flag (this is a boolean flag). If it passes, then we simply attach stdin to c.modified :
flagModified = flag.Bool("modified", false, "read an archive of modified files from standard input") if *flagModified { cfg.modified = os.Stdin } If you look again at the config.parse() function, you will see that it checks the attachment of the .modified field. Stdin is an arbitrary data stream that needs to be parsed according to the selected protocol. In our case, we assume that the archive contains:
- File name, then a new line.
- File size in decimal, then a new line.
- File contents.
Once we know the size of the file, we can safely parse the contents. If something turns out to be larger, then we simply stop parsing.
This approach is used in several other utilities (for example, guru , gogetdoc , etc.), it is very convenient for editors, because they can transfer the contents of modified files without saving to the file system . Therefore, the "modified".
So, we have a node, let's look for a structure:
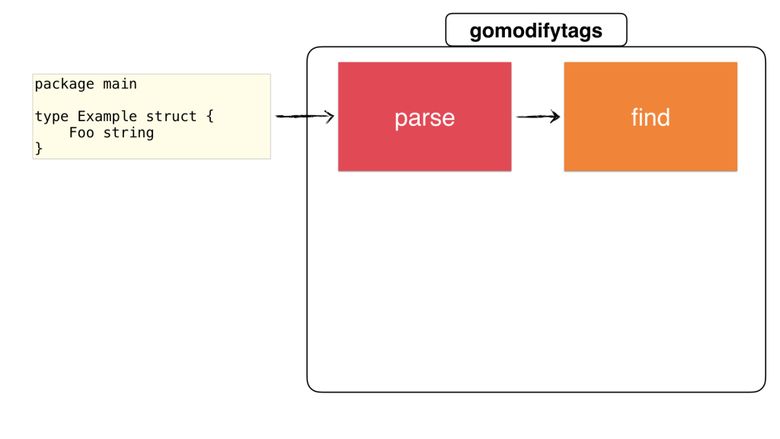
In the main function, we are going to call the findSelection() function with ast.Node, which we parsed in the previous step:
func main() { // ... parse file and get ast.Node start, end, err := cfg.findSelection(node) if err != nil { return err } // continue rewriting the node with the start&end position } The cfg.findSelection() function, based on the configuration, returns the starting and ending positions of the structure, as well as the order in which the structure is selected. It passes through a given node and returns the starting and ending positions (as explained in the section on configuration):
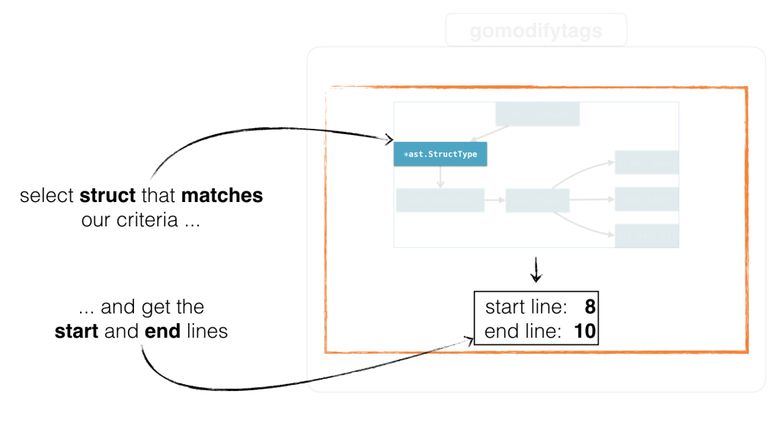
Then the function will iterate through all nodes until it finds * ast.StructType , and returns its starting and ending positions to the file.
But how is this done? Remember that we have three modes. Select by line , by offset and by structure name :
// findSelection returns the start and end position of the fields that are // suspect to change. It depends on the line, struct or offset selection. func (c *config) findSelection(node ast.Node) (int, int, error) { if c.line != "" { return c.lineSelection(node) } else if c.offset != 0 { return c.offsetSelection(node) } else if c.structName != "" { return c.structSelection(node) } else { return 0, 0, errors.New("-line, -offset or -struct is not passed") } } Select by line is easiest. We simply return the value of the flag itself. If the user passed the flag "--line 3,50" , the function returns (3, 50, nil) . It simply selects the value and converts it into integers (and at the same time checks):
func (c *config) lineSelection(file ast.Node) (int, int, error) { var err error splitted := strings.Split(c.line, ",") start, err := strconv.Atoi(splitted[0]) if err != nil { return 0, 0, err } end := start if len(splitted) == 2 { end, err = strconv.Atoi(splitted[1]) if err != nil { return 0, 0, err } } if start > end { return 0, 0, errors.New("wrong range. start line cannot be larger than end line") } return start, end, nil } This mode is used by editors when you select a group of lines and select (highlight) them.
Selecting by offset and by structure name requires more work. First you need to collect all the available structures so that you can calculate the offset or search by name. So, we collect all the structures:
// collectStructs collects and maps structType nodes to their positions func collectStructs(node ast.Node) map[token.Pos]*structType { structs := make(map[token.Pos]*structType, 0) collectStructs := func(n ast.Node) bool { t, ok := n.(*ast.TypeSpec) if !ok { return true } if t.Type == nil { return true } structName := t.Name.Name x, ok := t.Type.(*ast.StructType) if !ok { return true } structs[x.Pos()] = &structType{ name: structName, node: x, } return true } ast.Inspect(node, collectStructs) return structs } The ast.Inspect() function ast.Inspect() down the AST and looks for structures.
First we need *ast.TypeSpec so that the name can be retrieved. Search *ast.StructType will give us the structure itself, but not its name. Therefore, we use the structType type, which contains the name and node of the structure, which is convenient. Since the position of each structure is unique, we will take the position as a key for the binding.
Now we have all the structures, and we can return the starting and ending positions for modes with an offset and the name of the structure. In the first case, we will check if the offset falls inside the given structure:
func (c *config) offsetSelection(file ast.Node) (int, int, error) { structs := collectStructs(file) var encStruct *ast.StructType for _, st := range structs { structBegin := c.fset.Position(st.node.Pos()).Offset structEnd := c.fset.Position(st.node.End()).Offset if structBegin <= c.offset && c.offset <= structEnd { encStruct = st.node break } } if encStruct == nil { return 0, 0, errors.New("offset is not inside a struct") } // offset mode selects all fields start := c.fset.Position(encStruct.Pos()).Line end := c.fset.Position(encStruct.End()).Line return start, end, nil } We use collectStructs() to collect and then iterate over the structures. Remember that we saved the initial token.FileSet that was used to parse the file?
Now he will help us to obtain information about the displacement from each individual node of the structure (decipher it in token.Position and get the .Offset field ). We simply check and iterate until we find our structure (in this case with the name encStruct ):
for _, st := range structs { structBegin := c.fset.Position(st.node.Pos()).Offset structEnd := c.fset.Position(st.node.End()).Offset if structBegin <= c.offset && c.offset <= structEnd { encStruct = st.node break } } Using this information, you can extract the starting and ending positions of the found structure:
start := c.fset.Position(encStruct.Pos()).Line end := c.fset.Position(encStruct.End()).Line We apply the same logic when choosing a structure name. Simply, instead of checking whether the offset is within a given structure, we check the name of the structure until we find the one we need:
func (c *config) structSelection(file ast.Node) (int, int, error) { // ... for _, st := range structs { if st.name == c.structName { encStruct = st.node } } // ... } Received the initial and final positions, proceed to the modification of the structure fields:

In our main function, we call the function cfg.rewrite() with the node that was parsed in the previous step:
func main() { // ... find start and end position of the struct to be modified rewrittenNode, errs := cfg.rewrite(node, start, end) if errs != nil { if _, ok := errs.(*rewriteErrors); !ok { return errs } } // continue outputting the rewritten node } This is a key part of the utility. The rewrite function rewrites the fields of all structures between the starting and ending positions.
// rewrite rewrites the node for structs between the start and end // positions and returns the rewritten node func (c *config) rewrite(node ast.Node, start, end int) (ast.Node, error) { errs := &rewriteErrors{errs: make([]error, 0)} rewriteFunc := func(n ast.Node) bool { // rewrite the node ... } if len(errs.errs) == 0 { return node, nil } ast.Inspect(node, rewriteFunc) return node, errs } As you can see, we again use ast.Inspect() to traverse down the tree for a given node. Inside the rewriteFunc function rewriteFunc we rewrite the tags of each field (we'll talk more about this later).
Since the function returned by ast.Inspect() does not return an error, we will create an error scheme (defined using the errs variable), and then we will collect them by passing down the tree and processing the fields. Let's deal with rewriteFunc :
rewriteFunc := func(n ast.Node) bool { x, ok := n.(*ast.StructType) if !ok { return true } for _, f := range x.Fields.List { line := c.fset.Position(f.Pos()).Line if !(start <= line && line <= end) { continue } if f.Tag == nil { f.Tag = &ast.BasicLit{} } fieldName := "" if len(f.Names) != 0 { fieldName = f.Names[0].Name } // anonymous field if f.Names == nil { ident, ok := f.Type.(*ast.Ident) if !ok { continue } fieldName = ident.Name } res, err := c.process(fieldName, f.Tag.Value) if err != nil { errs.Append(fmt.Errorf("%s:%d:%d:%s", c.fset.Position(f.Pos()).Filename, c.fset.Position(f.Pos()).Line, c.fset.Position(f.Pos()).Column, err)) continue } f.Tag.Value = res } return true } Remember that this function is called for each AST node . Therefore, we are only looking for nodes of type *ast.StructType . Then we start to iterate over the fields of the structure.
Here we again use our favorite variables start and end . This code determines whether we want to modify the field. If his position is between start—end , then we continue, otherwise we do not pay attention:
if !(start <= line && line <= end) { continue // skip processing the field } Next, check if there is a tag. If the tag field is empty ( nil ), we initialize it with an empty tag. Later, this will help avoid confusion in the cfg.process() function:
if f.Tag == nil { f.Tag = &ast.BasicLit{} } Before proceeding, let me explain something interesting. gomodifytags tries to get the field name and process it. And if the field is anonymous?
type Bar string type Foo struct { Bar //this is an anonymous field } In this case , the field has no name , and then we assume the name of the field based on the name of the type :
// if there is a field name use it fieldName := "" if len(f.Names) != 0 { fieldName = f.Names[0].Name } // if there is no field name, get it from type's name if f.Names == nil { ident, ok := f.Type.(*ast.Ident) if !ok { continue } fieldName = ident.Name } After receiving the field name and tag value, you can begin processing the field. The cfg.process() function is responsible for processing (if there is a field name and a tag value). It returns the result (in our case, the formatting of the structured tag), which we use to overwrite the existing value of the tag:
res, err := c.process(fieldName, f.Tag.Value) if err != nil { errs.Append(fmt.Errorf("%s:%d:%d:%s", c.fset.Position(f.Pos()).Filename, c.fset.Position(f.Pos()).Line, c.fset.Position(f.Pos()).Column, err)) continue } // rewrite the field with the new result,ie: json:"foo" f.Tag.Value = res If you remember the structtag, then String () is actually returned here - the representation of the tag instance. Before returning the final representation of the tag, we will use various methods of the struct struct for the desired structure modification. :
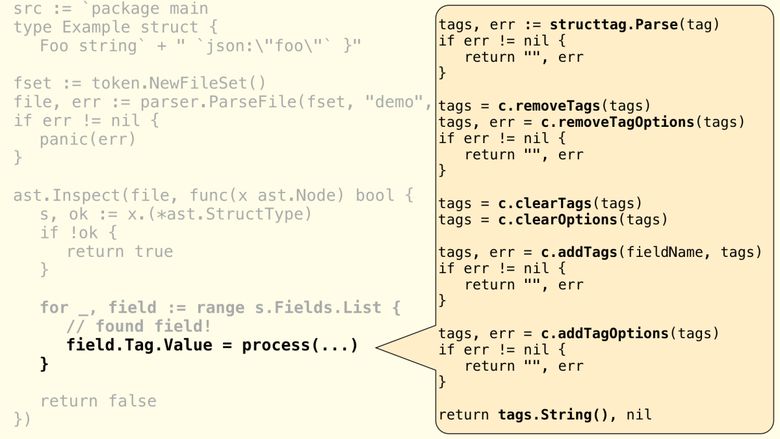
structtag
, removeTags() process() . ( ), :
flagRemoveTags = flag.String("remove-tags", "", "Remove tags for the comma separated list of keys") if *flagRemoveTags != "" { cfg.remove = strings.Split(*flagRemoveTags, ",") } removeTags() , - --remove-tags . tags.Delete() structtag:
func (c *config) removeTags(tags *structtag.Tags) *structtag.Tags { if c.remove == nil || len(c.remove) == 0 { return tags } tags.Delete(c.remove...) return tags } cfg.Process() .
, : .

cfg.format() , :
func main() { // ... rewrite the node out, err := cfg.format(rewrittenNode, errs) if err != nil { return err } fmt.Println(out) } stdout . . -, — , . -, stdout , , .
format() :
func (c *config) format(file ast.Node, rwErrs error) (string, error) { switch c.output { case "source": // return Go source code case "json": // return a custom JSON output default: return "", fmt.Errorf("unknown output mode: %s", c.output) } } .
(« ») ast.Node Go-. , , .
(“JSON”) ( ). :
type output struct { Start int `json:"start"` End int `json:"end"` Lines []string `json:"lines"` Errors []string `json:"errors,omitempty"` } ( ):

format() . , . « » go/format AST Go-. , gofmt . « »:
var buf bytes.Buffer err := format.Node(&buf, c.fset, file) if err != nil { return "", err } if c.write { err = ioutil.WriteFile(c.file, buf.Bytes(), 0) if err != nil { return "", err } } return buf.String(), nil format io.Writer . ( var buf bytes.Buffer ), , -write . , Go.
JSON . , , . . , format.Node() , lossy .
lossy- ? :
type example struct { foo int // this is a lossy comment bar int } *ast.Field . *ast.Field.Comment , .
? foo bar ?
type example struct { foo int bar int } , lossy- *ast.File . , . , , , JSON:
var buf bytes.Buffer err := format.Node(&buf, c.fset, file) if err != nil { return "", err } var lines []string scanner := bufio.NewScanner(bytes.NewBufferString(buf.String())) for scanner.Scan() { lines = append(lines, scanner.Text()) } if c.start > len(lines) { return "", errors.New("line selection is invalid") } out := &output{ Start: c.start, End: c.end, Lines: lines[c.start-1 : c.end], // cut out lines } o, err := json.MarshalIndent(out, "", " ") if err != nil { return "", err } return string(o), nil .
That's all!
, , :
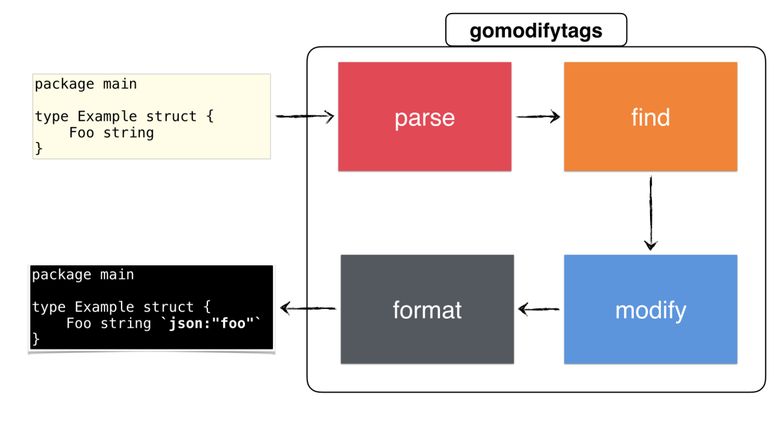
gomodifytags
:
- CLI- .
go/parser,ast.Node.- ( ) , , .
- ,
ast.Node( structtag). - Go, JSON .
gomodifytags , :
- vim-go
- atom
- vscode
- acme
')
Source: https://habr.com/ru/post/341822/
All Articles