Analysis of robots.txt files of the largest sites
Robots.txt tells the web crawlers of the world which files can or cannot be downloaded from the server. He, as the first watchman on the Internet, does not block requests, but asks not to do them. Interestingly, robots.txt files show webmaster guesses how automated processes should work with the site. Although the bot can easily ignore them, but they indicate idealized behavior, how a crawler should act.
Essentially, these are quite important files. So I decided to download the robots.txt file from each of the 1 million most visited sites on the planet and see which templates could be detected.
I took a list of 1 million of the largest sites from Alexa and wrote a small program to download the robots.txt file from each domain. After downloading all the data, I skipped every file through the urllib.robotparser Python package and began to study the results.
')
Found in yangteacher.ru/robots.txt
Among my favorite pets are sites that allow content to be indexed only by a Google bot and banned by everyone else. For example, the Facebook robots.txt file starts with the following lines:
This is slightly hypocritical, because Facebook itself began working with crawling student profiles on the website of Harvard University - it is this kind of activity that they now prohibit everyone else.
Requiring written permission before starting a website crawling spits in the face of the ideals of an open Internet. It prevents research and puts a barrier to the development of new search engines: for example, the DuckDuckGo search engine is prohibited from downloading Facebook pages, and Google can be.
In the quixotic rush to name and shame the sites that show this behavior, I wrote a simple script that checks domains and identifies those that Google has white listed those who are allowed to index the main page. Here are the most popular of these domains:
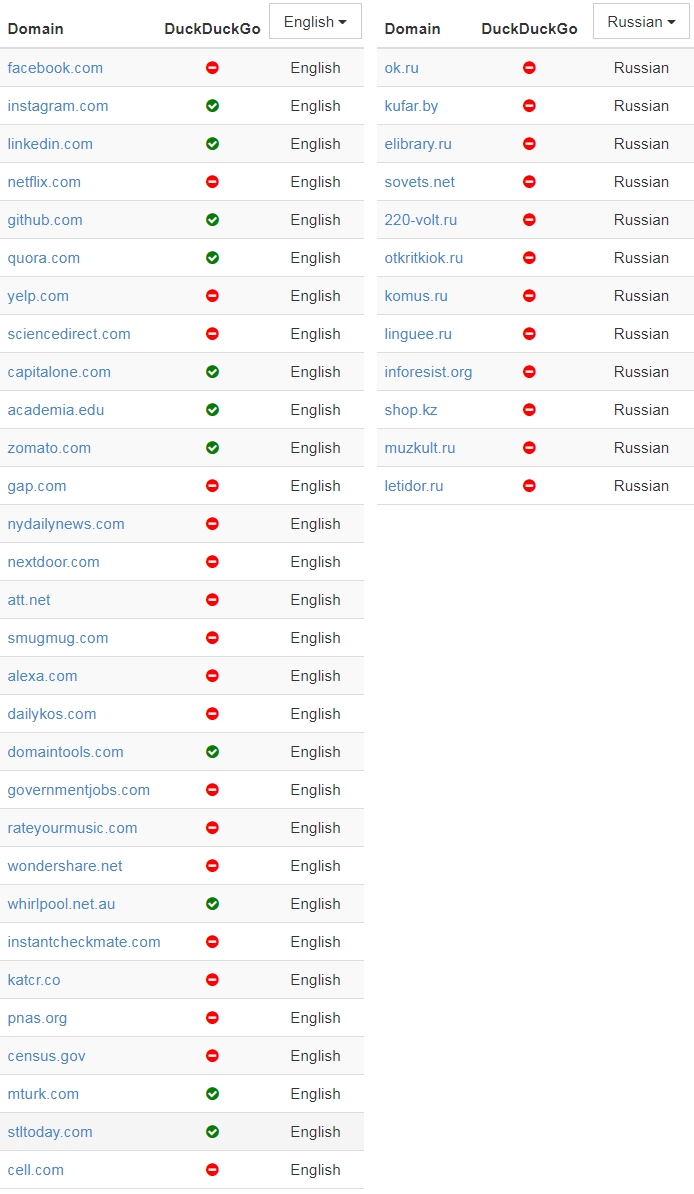
(The original article also lists similar lists of Chinese, French, and German domains.)
I included a note in the table about whether the site still allows DuckDuckGo to index its main page, in an attempt to show how hard it is for the new search engines these days.
Most of the domains at the top of the list — such as Facebook, LinkedIn, Quora, and Yelp — have one thing in common. All of them post user-generated content, which is the main value of their business. This is one of their main assets, and companies do not want to give it away for free. However, for the sake of fairness, such bans are often presented as protecting the privacy of users, as in this statement by Facebook’s technical director of the decision to ban crawlers or deep in the robots.txt file from Quora, which explains why the site banned Wayback Machine .
Further down the list, the results become more controversial - for example, I don’t quite understand why census.gov allows access to its content to only three main search engines, but blocks DuckDuckGo. It is logical to assume that the data of the state censuses belong to the people, and not just Google / Microsoft / Yahoo.
Although I am not a fan of such behavior, I can quite understand the impulsive attempt to add to the white list only certain crawlers, given the number of bad bots around.
I wanted to try something else: identify the worst web crawlers on the Internet, taking into account the collective opinion of a million robots.txt files. To do this, I calculated how many different domains completely banned a specific useragent - and ranked them according to this indicator:
In the list there are bots of several specific types.
The first group is crawlers that collect data for SEO and marketing analysis. These firms want to get as much data as possible for their analytics - generating a noticeable load on many servers. Ahrefs bot even boasts: “ AhrefsBot is the second most active crawler after Googlebot, ” so it's understandable why people want to block these annoying bots. Majestic (MJ12Bot) is positioning itself as a competitive intelligence tool. This means that it downloads your site in order to provide your competitors with useful information - and also declares “the world's largest index of links ” on the main page.
The second group of user-agents is from tools that seek to quickly download a website for personal use offline. Tools like WebCopier , Webstripper and Teleport all quickly download a full copy of the website to your hard drive. The problem is in the multithreaded download speed: all these tools obviously block traffic so much that sites often prohibit them.
Finally, there are search engines like Baidu (BaiduSpider) and Yandex, which can aggressively index content, although they only serve languages / markets that are not necessarily very valuable for certain sites. Personally, I have both of these crawler generate a lot of traffic, so I would not advise to block them.
This is a sign of time that files that are meant to be read by robots often contain ads for hiring software developers - especially SEO specialists.
In some way, this is the first in the world (and, probably, the only) job exchange, composed entirely of robots.txt file descriptions. (The original article contains the texts of all 67 vacancies from robots.txt files - approx. Lane.).
There is some irony in the fact that Ahrefs.com , the developer of the second among the most banned bots, also placed an advertisement in their robots.txt file about searching for an SEO specialist. Also, pricefalls.com has a job posting in the robots.txt file after the entry “Warning: pricelings crawling is prohibited if you do not have written permission”.
All the code for this article is on GitHub .
Essentially, these are quite important files. So I decided to download the robots.txt file from each of the 1 million most visited sites on the planet and see which templates could be detected.
I took a list of 1 million of the largest sites from Alexa and wrote a small program to download the robots.txt file from each domain. After downloading all the data, I skipped every file through the urllib.robotparser Python package and began to study the results.
')
Found in yangteacher.ru/robots.txt
Fenced gardens: ban all but Google
Among my favorite pets are sites that allow content to be indexed only by a Google bot and banned by everyone else. For example, the Facebook robots.txt file starts with the following lines:
Notice: Crawling Facebook is prohibited unless you have express written permission. See: http://www.facebook.com/apps/site_scraping_tos_terms.phphttp://www.facebook.com/apps/site_scraping_tos_terms.php )This is slightly hypocritical, because Facebook itself began working with crawling student profiles on the website of Harvard University - it is this kind of activity that they now prohibit everyone else.
Requiring written permission before starting a website crawling spits in the face of the ideals of an open Internet. It prevents research and puts a barrier to the development of new search engines: for example, the DuckDuckGo search engine is prohibited from downloading Facebook pages, and Google can be.
In the quixotic rush to name and shame the sites that show this behavior, I wrote a simple script that checks domains and identifies those that Google has white listed those who are allowed to index the main page. Here are the most popular of these domains:
(The original article also lists similar lists of Chinese, French, and German domains.)
I included a note in the table about whether the site still allows DuckDuckGo to index its main page, in an attempt to show how hard it is for the new search engines these days.
Most of the domains at the top of the list — such as Facebook, LinkedIn, Quora, and Yelp — have one thing in common. All of them post user-generated content, which is the main value of their business. This is one of their main assets, and companies do not want to give it away for free. However, for the sake of fairness, such bans are often presented as protecting the privacy of users, as in this statement by Facebook’s technical director of the decision to ban crawlers or deep in the robots.txt file from Quora, which explains why the site banned Wayback Machine .
Further down the list, the results become more controversial - for example, I don’t quite understand why census.gov allows access to its content to only three main search engines, but blocks DuckDuckGo. It is logical to assume that the data of the state censuses belong to the people, and not just Google / Microsoft / Yahoo.
Although I am not a fan of such behavior, I can quite understand the impulsive attempt to add to the white list only certain crawlers, given the number of bad bots around.
Bad behavior bots
I wanted to try something else: identify the worst web crawlers on the Internet, taking into account the collective opinion of a million robots.txt files. To do this, I calculated how many different domains completely banned a specific useragent - and ranked them according to this indicator:
| user-agent | Type of | amount |
|---|---|---|
| MJ12bot | SEO | 15156 |
| AhrefsBot | SEO | 14561 |
| Baiduspider | Search system | 11473 |
| Nutch | Search system | 11023 |
| ia_archiver | SEO | 10477 |
| Webcopier | Archiving | 9538 |
| Webstripper | Archiving | 8579 |
| Teleport | Archiving | 7991 |
| Yandex | Search system | 7910 |
| Offline explorer | Archiving | 7786 |
| SiteSnagger | Archiving | 7744 |
| psbot | Search system | 7605 |
| TeleportPro | Archiving | 7063 |
| Emailsiphon | Spam scraper | 6715 |
| EmailCollector | Spam scraper | 6611 |
| larbin | Unknown | 6436 |
| BLEXBot | SEO | 6435 |
| Semrushbot | SEO | 6361 |
| MSIECrawler | Archiving | 6354 |
| moget | Unknown | 6091 |
In the list there are bots of several specific types.
The first group is crawlers that collect data for SEO and marketing analysis. These firms want to get as much data as possible for their analytics - generating a noticeable load on many servers. Ahrefs bot even boasts: “ AhrefsBot is the second most active crawler after Googlebot, ” so it's understandable why people want to block these annoying bots. Majestic (MJ12Bot) is positioning itself as a competitive intelligence tool. This means that it downloads your site in order to provide your competitors with useful information - and also declares “the world's largest index of links ” on the main page.
The second group of user-agents is from tools that seek to quickly download a website for personal use offline. Tools like WebCopier , Webstripper and Teleport all quickly download a full copy of the website to your hard drive. The problem is in the multithreaded download speed: all these tools obviously block traffic so much that sites often prohibit them.
Finally, there are search engines like Baidu (BaiduSpider) and Yandex, which can aggressively index content, although they only serve languages / markets that are not necessarily very valuable for certain sites. Personally, I have both of these crawler generate a lot of traffic, so I would not advise to block them.
Job listings
This is a sign of time that files that are meant to be read by robots often contain ads for hiring software developers - especially SEO specialists.
In some way, this is the first in the world (and, probably, the only) job exchange, composed entirely of robots.txt file descriptions. (The original article contains the texts of all 67 vacancies from robots.txt files - approx. Lane.).
There is some irony in the fact that Ahrefs.com , the developer of the second among the most banned bots, also placed an advertisement in their robots.txt file about searching for an SEO specialist. Also, pricefalls.com has a job posting in the robots.txt file after the entry “Warning: pricelings crawling is prohibited if you do not have written permission”.
All the code for this article is on GitHub .
Source: https://habr.com/ru/post/341774/
All Articles