Infrastructure with Kubernetes as an affordable service

Kubernetes has become for us the technology that fully meets the stringent requirements for resiliency, scalability and quality service of the project. Despite the fact that today K8s is more common in large organizations and projects, we have learned how to use it in small applications. Reducing the cost of service has become possible for us due to the unification and generalization of all components that are found in virtually every client. This article is a look at the experience gained from business needs and their technical implementation, which allows us to offer customers a quality solution and support for reasonable money.
"Rocket science" as the norm
I will begin with general words about how we came to this in general, and an overview of the technical details on the proposed infrastructure, read below.
')
For about 10 years, “Flant” has been involved in the system administration of GNU / Linux and countless related technologies and software. All this time we have been improving our work processes, often comparing a company with a plant that goes from manual labor (the need to “manually” go to the server when a lot of the same problems occur) to stream production (typical configurations, centralized management, automatic deployment, etc. .). Even in spite of the fact that many of the projects we serve, are very different (in the stack of the applied technologies, requirements for performance and scaling ...), they have a foundation that needs to be systematized. This fact makes it possible to turn quality service into a standard service, providing the client with additional benefits for reasonable money.
Growing the best practices within the company based on the experience of working with different projects, summarizing them and, if possible, “programming” them, we extend these results to other existing installations. Previously, the configuration management system served as the key tool (we preferred Chef). Gradually introducing the Docker-containers into the infrastructure, we went to the logical step of integrating their settings with the capabilities of Chef (implemented this as part of our dapp tool) ...
But with the advent of Kubernetes, much has changed. Now we describe the configurations in Kubernetes and obtain (offer to customers) an infrastructure that:
- centrally controlled,
- quickly turns around
- easily complemented by new services,
- does not depend on the resource provider (cloud provider, data center),
- scaled in cases of project complexity or increasing loads,
- simply integrates with modern processes and technologies for continuous integration and application delivery (CI / CD).
This approach to infrastructure is the result of our long search for an optimal solution, countless trial and error, a truly multifaceted experience in servicing IT systems. This is our current vision of a reasonable "norm" for projects of different scales.
The frequent feeling that then arises from business owners: “Well, that sounds cool, but this is some kind of rocket science, and it’s not for us, because it’s too complicated and expensive.” However, our experience shows that this “rocket science” is ideal even for those who think that they are still “not at that level” for the implementation of Kubernetes:
- Benefit - an infrastructure that not only just works, is repaired in case of accidents and gradually (as required) improves ... This is an infrastructure that by its “nature” covers all needs for resiliency, scalability and development support (any test circuits, deploy, CI / Cd). It is built on the best practices of DevOps and Open Source components that are industry standard.
- Complexity is our area of responsibility, which lies precisely in, on the contrary, making the result as simple as possible for users, i.e. developers.
- Cost - the usual monthly subscription fee for servicing such a typical infrastructure for a small project ranges from 80 to 120 thousand rubles, which is comparable to hiring one “conditionally average” Linux engineer.
What we understand by a small project and what are its needs are described in the next paragraph, from which the story about the structure of a typical infrastructure begins.
Technical details
What a "small project"?
The architecture considered in the article has already been implemented in a variety of projects of various kinds: media, online stores, online games, social networks, blockchain platforms, etc.
What is a small project for which it is designed? The criteria are not very strict, but indicate the main trends and requirements:
- This is a project that already has more than 1 server (the upper bound is incorrect to call, since the architecture can be deployed on multiple servers).
- The project already requires resiliency, as it is a business tool and makes a profit.
- The project should be ready for high loads, and there is a real need for the possibility of rapid scaling (for example, an online store should temporarily increase server capacity before Black Friday).
- The project already requires a system administrator, because without it, nothing happens.
If we briefly describe the architecture as a whole, then we can say that it is “a fault-tolerant and scalable Docker-container cloud that is managed by Kubernetes”. And that's what it is ...
Kubernetes app
Hereinafter I will take as an example a typical online store. Imagine that there are 3 servers on which a Kubernetes cluster is deployed. Kubernetes is the main component of the architecture, it is the component that deals with the orchestration and management of Docker containers. It is responsible for the reliable, fault-tolerant and scalable operation of the containers within which the client application runs. Those. in essence, this is a cloud of containers running on three servers. If one of the servers on which the cloud runs fails, then Kubernetes automatically throws the fallen containers (running on the fallen server) onto the remaining two servers - this happens very quickly, within a few seconds.
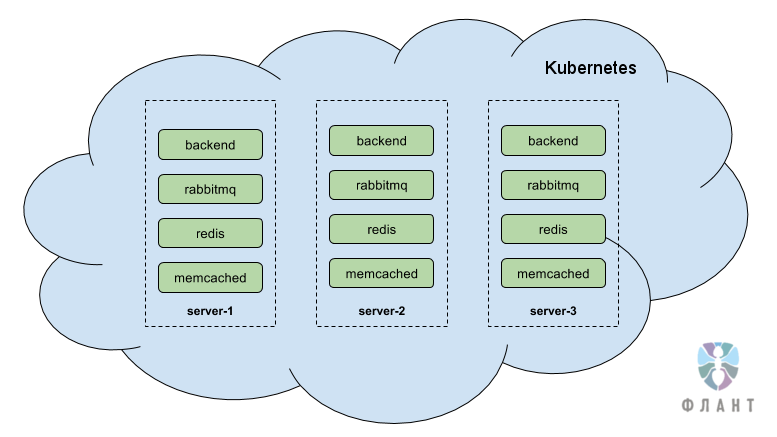
Our goal - the fall of a single server or even two servers in the cloud should be an imperceptible event. This is achieved due to the fact that each component is duplicated at least once and, within the cloud, instances of the same component are located on different servers. In this case, the backup component is ready to instantly take the load on itself. If the application supports, then it is possible that all instances of the component are working at the same time, and not in the main-reserve mode. It is also possible to click on the button “scale” and get another one-two-three or more additional copies of this component.
Imagine that an online store is written in PHP and has the following components *:
- MySQL database;
- PHP backend;
- caching in memcached;
- RabbitMQ queue;
- order storage in Redis;
- consumer accountant
- cron tasks
* In fact, it’s not so important, an online store or media site, and even the components themselves may be completely different, but the essence will remain the same.
As you might have guessed, part of our work is to pack the application (in this case, the online store) into Docker containers, and then launch these containers in the Kubernetes cloud. In addition to the application itself (PHP backend), other components work in the cloud: memcached, RabbitMQ, etc.
Note : We still do not install RDBMS in production inside the Kubernetes cloud for some technological reasons. However, they began to make the first such installations for small projects and applications not in production (dev circuits, etc.).
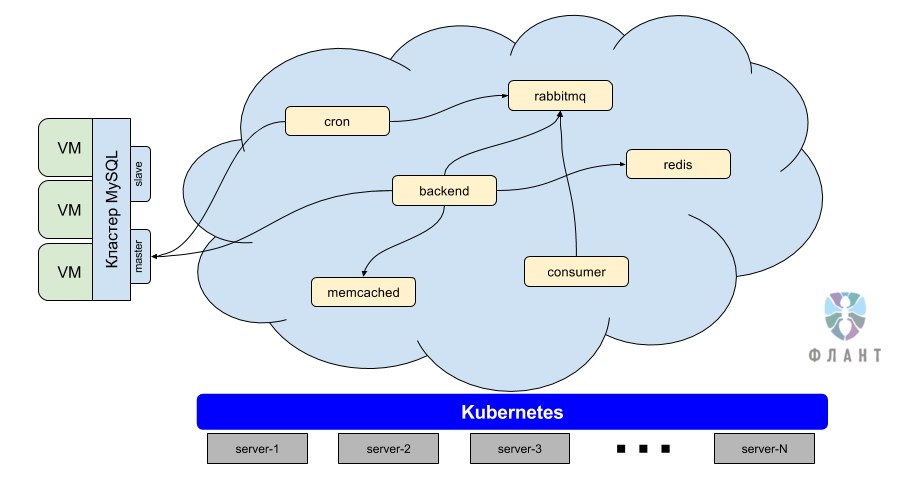
All projects often have about the same component stack, and the differences are more likely to be in programming languages and databases. The implementation of Kubernetes gave us a good opportunity to implement a typical configuration of each of these components, which is suitable for any project. At the same time, such a typical component is itself fault tolerant, easily scaled, and also placed in any Kubernetes cluster within 5 minutes. For example, consider each of the components separately.
Database
DBMS are separated into a separate entity, since in most cases they are outside of Kubernetes and usually represent 2 or 3 servers that operate in the master-slave mode (MySQL, PostgreSQL, ...) or master-master (Percona XtraDB), with automatic or manual failover in case of emergency.
PHP backend
A backend is an application code that is packaged in a Docker container. The necessary libraries and software for the application are installed in this container (for example, PHP 7). The same container is used to run consumer and cron tasks. In Kubernetes, we run several instances of the backend, one crowns and several consumer items.
Memcached
With memcached, we have historically developed two options for implementation that are used in various situations:
- N separate memcached instances (usually 3). The application knows about all three memcached and writes to all three, itself provides failover.
- Mcrouter is a universal option that will suit any application. The logic of the distributed record and failover is removed from the application to the mcrouter side.
RabbitMQ
We use the RabbitMQ regular cluster of three or more nodes with automatic failover at the Kubernetes level.
Redis
At the heart of this component, we use the regular Redis Sentinel cluster, which has some binding, which saves the application from having to implement the sentinel protocol.
Other application services
Similarly, we have ready-to-use and tested components in our arsenal, such as minio, sphinxsearch, elasticsearch, and many others. Almost any software can be installed inside Kubernetes - the main thing is to approach this process wisely.
Utility Components
Each project also has the following service components Kubernetes:
- A control panel (dashboard), which gives developers the ability to control components. You can also get into containers through it - almost as in SSH.
- Centralized log storage. Logs are collected in real time from all components in all circuits, logs are written into a single database. A web interface is available with the ability to view all logs in real time, search and filter by various parameters. To do this, use its own Open Source solution loghouse, more about which read in this announcement .
- Monitoring on Prometheus + Okmeter. Prometheus is installed inside Kubernetes and collects statistics from all components. In addition to the standard parameters (memory, disk, CPU), metrics are also removed from Apache / php-fpm, RabbitMQ, Redis, etc. - each component is separately monitored. Okmeter stands outside Kubernetes and monitors the servers themselves from the outside.
Architecture and stateless consulting
As a rule, projects that come to us initially have problems with the architecture - first of all, with scaling due to the storage of files or intermediate data on disk, local storage of sessions and many other reasons. The biggest and hardest part of the job is to help developers redo the application so that it becomes stateless.
If it is completely “on the fingers”, it means that each component of the application does not store intermediate data, or this data is of little importance and can be lost without serious consequences. This is necessary so that you can run several backends and if one of them suddenly fails, nothing would break, no files uploaded by users would be deleted, etc.
The most common reasons that prevent a stateless application from being made are:
- Local storage of sessions on the backend (in files). This issue is almost always solved by simply rendering sessions to fail-safe memcached (either through PHP settings or through application settings).
- Local storage of boot files on the backend. The issue is resolved by using dedicated file storage (for example, Amazon S3 or file storage from Selectel) or options with storage on client servers implemented on minio or Ceph (S3 / Swift API).
The answer to the emerging concerns about such a stateless future (yes, you really have to spend the resources of developers on changes in the application for this) is that it is inevitable anyway (for applications that need scaling) and that you can approach it step by step.
Other problems and features
CI / CD
Finally, a logical question arises: how is the application code deployed to such an infrastructure? It is arranged as follows:
- The code is under control of the versioning system (Git).
- We use GitLab * to invoke the Docker container after a code commit.
- After the build phase in GitLab, a “roll out to production” button appears.
- We press this button - the new version of the application rolls out and starts, the old version stops, the rollout happens seamlessly and seamlessly for the site user. Also during rollout, database migrations are performed.
There are namespaces in Kubernetes. They can be thought of as separate, isolated contours or environments that run in a single cluster. That is, we have the opportunity to make a separate contour for staging, for the master branch ... or, in general, for each branch to make our own separate contour. The contour is a complete copy of production: there are all the same components (MySQL, backends, Redis, RabbitMQ, etc.). This is achieved due to the fact that the entire infrastructure configuration (configuration of all components) is described in special YAML files and lies in the repository, that is, we are able to quickly and completely recreate the production environment in any other namespace.
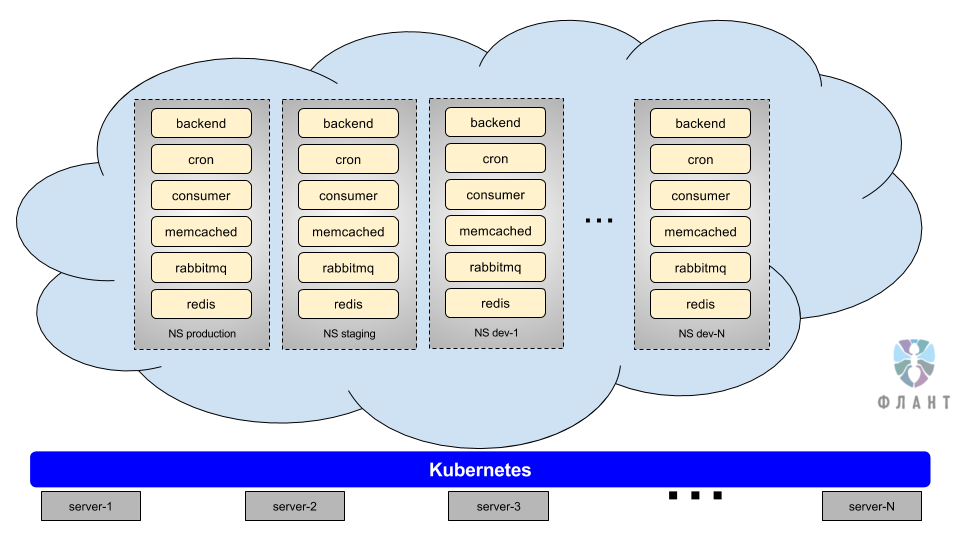
* An example of our pipeline in GitLab CI and technical details of its implementation can be found in this article .
Servers
The most typical installation is 3 hypervisor servers that have approximately the following configuration: E5-1650v4, 128G RAM, 2 × 500 GB SSD. Servers are interconnected by a local network. The resources of each server are divided by virtual machines (Linux KVM + QEMU) into the following parts:
- production loop;
- dev contours;
- Kubernetes utility services (masters and fronts);
- database.
Backup
We will back up everything that is required in the project: databases, upload-files, etc. There is no downtime during the backup (for the DBMS, the data is removed from the slave server, etc.). The backup plan and its monthly testing is consistent with the client - the personal project manager is responsible for this.
Monitoring and Interaction
These are not always technical issues, but they are important for understanding the full picture of the support being implemented:
- Thanks to our monitoring tools, all alerts flock to a centralized interface for engineers on duty. Each incident must be processed, each must have a summary. We guarantee a reaction to alerts within 15 minutes, while our average response time to an alert is 1 minute (and 10 minutes for a triage). Duty engineers around the clock in touch by phone, Slack, mail, ticket system (Redmine).
- Each of our projects has a dedicated manager, as well as a dedicated team of engineers, which includes both a leading engineer and ordinary engineers, and junior engineers. These people do not change - they “live” with the project from the very beginning and fully understand how it works.
- We offer SLA guarantees implying fines for a simple business critical infrastructure.
Summarizing
We believe that modern infrastructure solutions of the cloud native category can work for the benefit now and for all, and the cost of their use should not be comparable to the price of a spacecraft. You can draw an analogy with mobile communication: if before cellular communication was available only to the elect, today it is commonplace and a given, and the price for communication is low.
Having traveled from “manual” administration of “everything on Linux” to supporting modern infrastructure based on Kubernetes, we are striving to ensure that the service, which we consider to be a reasonable “norm”, is accessible to clients with any budget. Therefore, we offer a dedicated team of specialists to implement / maintain such infrastructure according to DevOps principles (in close cooperation with developers) with round-the-clock support and guarantees on SLA within the budget at the salary level of the system administrator / DevOps engineer hired for staff.
Many technical aspects of the infrastructure discussed here (and related best practices) are subject to considerable detail, but this is a story for individual articles: and if some of them have already been published on our blog, then requests for new ones are welcome in the comments. We will be happy and questions not on technology, but on the processes we use in our work and / or to our clients as part of our service.
PS
Read also in our blog:
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes);
- Cycle about the success stories of Kubernetes in production: “ # 1: 4200 pods and TessMaster from eBay ”, “ # 2: Concur and SAP ”, “ # 3: GitHub ”, “ # 4: SoundCloud (by Prometheus) ”;
- Statistics The New Stack on the Difficulties of Implementing Kubernetes ;
- “ Why do you need Kubernetes and why is it more than PaaS? "
Source: https://habr.com/ru/post/341760/
All Articles