Inversion of dependencies in the world frontend. Yandex lecture
The patterns of inversion of control (dependency inversion, DI) have been known for a long time, but have not yet found wide distribution in the world of frontend. This report answers the question of how to build a robust DI-based architecture using the capabilities of JS. The author of the report is Eugene ftdebugger Shpilevsky, head of the interface design group in Yandex.Collections.
- As far as I know, dependency inversion, DI-containers and other patterns, which were invented back in the 70s, did not enter the world of frontend development very tightly. There is certainly a reason for this. Partly, the fact is that many people do not understand why they are needed at all.
I will try to explain what DI is, what is dependency inversion, how it can help you in the project and what nice bonuses you can get if you start using it.
')
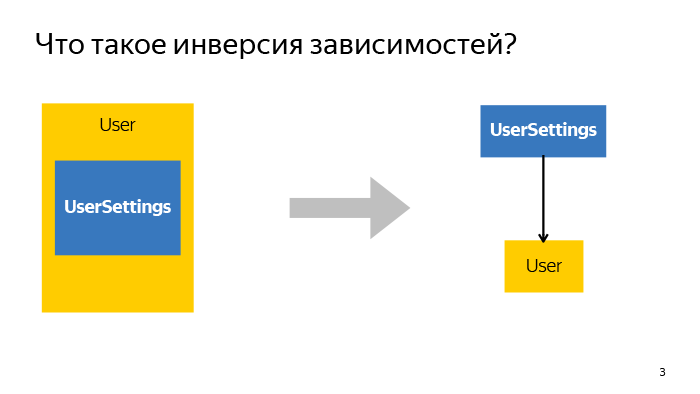
To begin with the most basic concept. What is dependency inversion? When we are engaged in designing any feature, we want to decompose it to such a small state that a particular individual class performs strictly one function and nothing more.
In the example on the slide there are User and UserSettings. Everything related to user settings was rendered into a separate class. How can I do that? There are two approaches: create an instance of this class inside or accept it outside. This is the basic principle of dependency inversion. If we create some instances from outside and then pass inwards, we get some advantage.


In fact, there is one reason - we no longer rely on a specific implementation, but begin to rely solely on interfaces. When we say that some small decomposed function has been moved to a separate class, we no longer care how it was implemented. We can simply use it, and it doesn't matter which instance of which class will be slipped if the interfaces are the same. And since there is no interface in JS, the method is invoked from the larger and is good.

The example with UserSettings is a bit torn out of context; this is hardly the code you write every day.
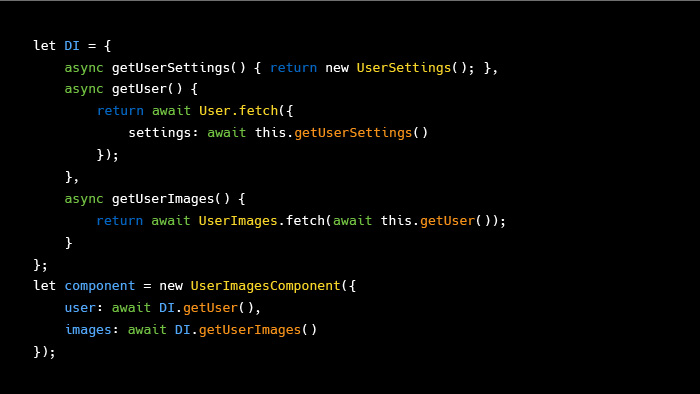
Slightly more mundane code, close to the reality and reality of JS, is synchronous. If we want to create a data model, we need to get this data from somewhere. One of the most common ways is to go to Ajax on the server, receive data synchronously, create it.
If we start writing this code in the style of dependency inversion, we get something like this. Not only is this code not written in the most optimal way, it is also pretty monstrous. We kind of wanted just one component that would display a list of pictures of our user, and for this we needed to write so much code.
In a real project, the score of components goes into the tens, and such an assembly, even on a page, will be rather monstrous.
What can be done? Make the code worse. We can make our first DI-container, the most primitive, head-on. We will take everything that we wrote before and pack into methods. Put them in hashes, which we call DI, and we will consider this as a DI container. Then we get the first step to make our future a little bit better.
The bottom line is that at any time when you need a user, settings, pictures, or some of the hundreds of other methods that could be described here, you can take a DI, call it, and you will not care how was designed.
All code that is responsible for building your models, classes, components will be isolated in one container. Naturally, it will be difficult to write code in this way, this file will quickly become large. There are already problems in it. Those who learn a little code, will find that, at least, the user is loaded twice. This is bad, this should be avoided.
In addition, all the code is template. We can replace it with some functions. And we can write our own container, which will solve all our problems, will be cool, fast. Whatever you want.
That's what I wanted from him.

He must look for classes himself. They need to be imported from somewhere, then created, used. I do not want this, let the container do it himself.
I want it to create asynchronously instances. If we initially put such a requirement on the container, we will have no problems with how we will create instances in the future, whether they will go to Ajax, whether they will spend time or not, or whether they will go synchronously. If creation goes asynchronously, everything is already provided.
Reuse It is very important. If we start writing a large container and do not reuse instances in it, we risk receiving a lot of useless unnecessary requests to the server. This one wants to avoid.
Last point. I'm pretty sure that the imperative plain code that I showed on the previous slide didn't please anyone. Instead, I want to write the usual declarative JSON, in which all this would be described, and everything would work for me.

We learn step by step how to solve every problem.
How can we learn to dynamically find classes? You can use the webpack, it has a dynamic import function. This kind of code, which seems a bit strange, is quite enough for yourself after Webpack banding will work. Moreover, all classes that fall under these conditions will automatically become separate bundles and begin loading asynchronously. And all of our class loading code will look like this. We just synchronously ask for a class and get it. The getClass function can look exactly the way you want it. If you want to download any dependencies statically, you can write them here. Want more clever banding - you can describe it here. All this, in general, up to you.

There are two ways to create instances. You can come up with a creepy configuration of how this will happen, or introduce some kind of convention. I like the way with the convention, because there is no need to code, you just need to remember something and then always follow these standards.
In this case, I introduce the following convention: any class must have a static method factory. He will be responsible for how this class will be built, what dependencies will be thrown into it. He is responsible for everything.
CreateInstance is very simple, the factory can be both synchronous and asynchronous. Well, the code to create a trite user has become different, but still ugly.

Reuse of instances. To achieve this, we introduce a new concept. To any instance that is created within the framework of a DI container, we will assign an identifier. We will invent these identifiers; they will describe some entities from our system. In this case, on the last line we describe the current user. We will somehow get the class of the previously written function, create an instance from it and put it in the cache.
In this example, a couple of bugs are allowed. The full implementation of the CreateInstance method, taking into account the cache, takes about 100 lines. Who cares, can then read it .

The last is dependencies. We describe the usual hash, where the keys are the identifiers from the DI container, and the values are the configuration with which we can create all of the above. Take and create a class UserSettings. In currentUser, we take the user class, pop it as dependencies in UserSettings. What are UserSettings? What we previously announced.
Describing such a structure, you can develop a simple algorithm that runs through the tree with dependencies, which is formed. In fact, there is a graph formed by this tree. This algorithm will bring us all that is necessary.
To reduce the amount of noise on the slide, I will introduce another convention.

Why not write not in JSON, but in anything, and why not describe everything in a simpler form? If you need a class - we take just a string, if we want a class and dependencies - we use an array. No matter which format you choose. The main thing is that it is pleasant for you and you understand what is happening here. This is the same slide, just rewritten.

As a result, if we have implemented all this, collected it, we will get an automatic bundling. Here you will get such an interesting option that if you request the current user, then your DI-container can simultaneously load the bundle containing this class and load the dependencies that are necessary for it asynchronously. The fact is that now he has information, where the class is located - perhaps in some kind of bundle - and what dependencies he will need. The landing example: if we want to make a component that will display a list of pictures, then the JS, where the code that draws these components with pictures lies, will still have to be loaded, and at that very moment the request for the server can go for data. When both of them are finally executed, we get it.
This can be obtained simply by using a DI container, nothing else is necessary. We have the ease of shipping addictions. When you first start using the DI container to its fullest extent, everything from your world starts to appear there: all, all common utilities, components, data models. And if at some point you need to get something, you can simply describe one line of dependencies, and not worry about how it should be created, configured, describe the whole complex process, which should go through all stages. You just get it from the container as a dependency.
Reuse code. If we start writing in such a way that in no particular class we explicitly create instances of other classes, then we cease to be tied to the implementation. We can slip whatever instances into the class as dependencies. Within the framework of the same component of pictures, we can load any kind of pictures and send them from anywhere. Within the framework of the container, all this will be different simply by a line in the configuration. You just take another dependency and that's it, it will be very easy for you.

Once the container is fixed in your project in a very important place, you begin to use it simply as the basis of everything. I want to demonstrate how you can make an ordinary multipage SPA using a DI container.
We will take some kind of router. Its implementation is not important. It is important that when it is matched to a url, it will assign a name to this page. In this case, perhaps home and profile.
Take our container and describe there as keys home and profile. We describe everything that we do not want to get there. And we want to get some component that we take and insert into the body. In this case, this is some sort of layout. Layout is used both there and there, it just encapsulates various dependencies. What to do next? What components will go deeper, already at this stage it does not matter, because they already somehow work, someone has set them up. We only care about the level of abstraction that we are working on right now.
Everything, we can from the DI-container by key, by the name of the page request some kind of dependency. In this case, this is a sign on the Layout, and this Layout will already contain all the necessary data, all the components, all that we want to do. It only remains to add it to the body.

What about the testability of all this? As soon as we begin to use it, it arises that the classes do not depend on the container directly. Nowhere and never will you use the container directly in the sense that I need such a dependency, I will take it and get it. No, rather, it will lie at the very bottom of the architecture, at the very bootstrap of your application, as demonstrated on the previous slide.
In fact, your classes do not depend on it at all; you can take them from anywhere and to port anywhere.
All dependencies are transmitted during the creation, and if we are talking about testing, in this place we can easily put mocks, fixture data and anything, simply because it already works that way. DI-container made us write code so that everything works that way.

A few examples. When creating, when we are engaged in testing and we want to blot the user settings, so that they do exactly what we want, and not what they have written, we can create a user, slip test data under it. We can use a container for this - a dependency tree has already been formed, we can override some of them. In the future, just by their logic of working with DI, everyone who ever wanted to receive UserSettings will receive them, no matter where they are. We can use it for testing.

There is another interesting example. If we assume that all data models that go somewhere to the server for data will use some specially written ajaxAdapter for this, then during the tests we can replace it with our own class TestAjaxAdapter, which can implement logic. This is how it is implemented, for example, in Sinon, if someone tried to get wet with it.

Or we can go even deeper. We implemented in this adapter such logic that when it is first used in tests, it starts recording requests and responses from a real server, and when it is restarted, it simply plays it from the cache. This cache we add to the repository to our test data. And when we want to do testing on fixtures and are afraid that they will change over time from the fact that the logic of communication with the server has already been implemented here, we replace the TestAjaxAdapter. In the repository formed some kind of cache, which will then be reused.

How can this be used even more interesting? We have already mentioned Gemini testing . This is one type of visually regressive testing. Who does not know, Gemini is a testing method in which we take a screenshot of some of our block on the finished page, put it to the test data in the repository, and when we want to do a reverse test, we re-launch, re-do the screenshot and compare it pix-by-pixel . If somewhere the pixels did not match - the test dropped. This is a very simple and effective type of testing, verification of visual regressions. We work with CSS, it has a feature: it constantly breaks. Gemini helps us get rid of these breakdowns.
What have we done in this place? Since everything was implemented through the DI-container, we specially prepared the server, which could be passed as parameters identifiers from the DI-container. He simply formed it, drawing on the page alone this component that we wanted. In this case, there is something connected with the recipes, some kind of card, real data, on which there were test runs, a real screenshot.
After the test was run, ajaxAdapters were replaced, and a cache was created related to how the server communicated. We have this data - constantly reproducible with time, and the tests become stable.
This approach is applicable to any type of test. If you want to browse by component into the Selenium browser and click on it, nothing bothers you, because you get a fully working piece of functionality that you want to commit to. And you can even make several blocks at the same time, just display them on the page and click on them. There are some event connections or something else between the blocks. Even if the blocks do not correspond to the present site, you can thus test some logic.
I read a cursory report on what DI is. I hope someone is interested. If you need details, I am available at the links: mail , GitHub , Telegram , Twitter .
Here are the links where you can find new information about what was here. For example, the fully implemented DI container I mentioned, the inversify DI container is a very cool thing for TypeScript. Here are some more links to figure out how to put everything together.
Thank.
- As far as I know, dependency inversion, DI-containers and other patterns, which were invented back in the 70s, did not enter the world of frontend development very tightly. There is certainly a reason for this. Partly, the fact is that many people do not understand why they are needed at all.
I will try to explain what DI is, what is dependency inversion, how it can help you in the project and what nice bonuses you can get if you start using it.
')
To begin with the most basic concept. What is dependency inversion? When we are engaged in designing any feature, we want to decompose it to such a small state that a particular individual class performs strictly one function and nothing more.
In the example on the slide there are User and UserSettings. Everything related to user settings was rendered into a separate class. How can I do that? There are two approaches: create an instance of this class inside or accept it outside. This is the basic principle of dependency inversion. If we create some instances from outside and then pass inwards, we get some advantage.
In fact, there is one reason - we no longer rely on a specific implementation, but begin to rely solely on interfaces. When we say that some small decomposed function has been moved to a separate class, we no longer care how it was implemented. We can simply use it, and it doesn't matter which instance of which class will be slipped if the interfaces are the same. And since there is no interface in JS, the method is invoked from the larger and is good.
The example with UserSettings is a bit torn out of context; this is hardly the code you write every day.
Slightly more mundane code, close to the reality and reality of JS, is synchronous. If we want to create a data model, we need to get this data from somewhere. One of the most common ways is to go to Ajax on the server, receive data synchronously, create it.
If we start writing this code in the style of dependency inversion, we get something like this. Not only is this code not written in the most optimal way, it is also pretty monstrous. We kind of wanted just one component that would display a list of pictures of our user, and for this we needed to write so much code.
In a real project, the score of components goes into the tens, and such an assembly, even on a page, will be rather monstrous.
What can be done? Make the code worse. We can make our first DI-container, the most primitive, head-on. We will take everything that we wrote before and pack into methods. Put them in hashes, which we call DI, and we will consider this as a DI container. Then we get the first step to make our future a little bit better.
The bottom line is that at any time when you need a user, settings, pictures, or some of the hundreds of other methods that could be described here, you can take a DI, call it, and you will not care how was designed.
All code that is responsible for building your models, classes, components will be isolated in one container. Naturally, it will be difficult to write code in this way, this file will quickly become large. There are already problems in it. Those who learn a little code, will find that, at least, the user is loaded twice. This is bad, this should be avoided.
In addition, all the code is template. We can replace it with some functions. And we can write our own container, which will solve all our problems, will be cool, fast. Whatever you want.
That's what I wanted from him.
He must look for classes himself. They need to be imported from somewhere, then created, used. I do not want this, let the container do it himself.
I want it to create asynchronously instances. If we initially put such a requirement on the container, we will have no problems with how we will create instances in the future, whether they will go to Ajax, whether they will spend time or not, or whether they will go synchronously. If creation goes asynchronously, everything is already provided.
Reuse It is very important. If we start writing a large container and do not reuse instances in it, we risk receiving a lot of useless unnecessary requests to the server. This one wants to avoid.
Last point. I'm pretty sure that the imperative plain code that I showed on the previous slide didn't please anyone. Instead, I want to write the usual declarative JSON, in which all this would be described, and everything would work for me.
We learn step by step how to solve every problem.
How can we learn to dynamically find classes? You can use the webpack, it has a dynamic import function. This kind of code, which seems a bit strange, is quite enough for yourself after Webpack banding will work. Moreover, all classes that fall under these conditions will automatically become separate bundles and begin loading asynchronously. And all of our class loading code will look like this. We just synchronously ask for a class and get it. The getClass function can look exactly the way you want it. If you want to download any dependencies statically, you can write them here. Want more clever banding - you can describe it here. All this, in general, up to you.
There are two ways to create instances. You can come up with a creepy configuration of how this will happen, or introduce some kind of convention. I like the way with the convention, because there is no need to code, you just need to remember something and then always follow these standards.
In this case, I introduce the following convention: any class must have a static method factory. He will be responsible for how this class will be built, what dependencies will be thrown into it. He is responsible for everything.
CreateInstance is very simple, the factory can be both synchronous and asynchronous. Well, the code to create a trite user has become different, but still ugly.
Reuse of instances. To achieve this, we introduce a new concept. To any instance that is created within the framework of a DI container, we will assign an identifier. We will invent these identifiers; they will describe some entities from our system. In this case, on the last line we describe the current user. We will somehow get the class of the previously written function, create an instance from it and put it in the cache.
In this example, a couple of bugs are allowed. The full implementation of the CreateInstance method, taking into account the cache, takes about 100 lines. Who cares, can then read it .
The last is dependencies. We describe the usual hash, where the keys are the identifiers from the DI container, and the values are the configuration with which we can create all of the above. Take and create a class UserSettings. In currentUser, we take the user class, pop it as dependencies in UserSettings. What are UserSettings? What we previously announced.
Describing such a structure, you can develop a simple algorithm that runs through the tree with dependencies, which is formed. In fact, there is a graph formed by this tree. This algorithm will bring us all that is necessary.
To reduce the amount of noise on the slide, I will introduce another convention.
Why not write not in JSON, but in anything, and why not describe everything in a simpler form? If you need a class - we take just a string, if we want a class and dependencies - we use an array. No matter which format you choose. The main thing is that it is pleasant for you and you understand what is happening here. This is the same slide, just rewritten.
As a result, if we have implemented all this, collected it, we will get an automatic bundling. Here you will get such an interesting option that if you request the current user, then your DI-container can simultaneously load the bundle containing this class and load the dependencies that are necessary for it asynchronously. The fact is that now he has information, where the class is located - perhaps in some kind of bundle - and what dependencies he will need. The landing example: if we want to make a component that will display a list of pictures, then the JS, where the code that draws these components with pictures lies, will still have to be loaded, and at that very moment the request for the server can go for data. When both of them are finally executed, we get it.
This can be obtained simply by using a DI container, nothing else is necessary. We have the ease of shipping addictions. When you first start using the DI container to its fullest extent, everything from your world starts to appear there: all, all common utilities, components, data models. And if at some point you need to get something, you can simply describe one line of dependencies, and not worry about how it should be created, configured, describe the whole complex process, which should go through all stages. You just get it from the container as a dependency.
Reuse code. If we start writing in such a way that in no particular class we explicitly create instances of other classes, then we cease to be tied to the implementation. We can slip whatever instances into the class as dependencies. Within the framework of the same component of pictures, we can load any kind of pictures and send them from anywhere. Within the framework of the container, all this will be different simply by a line in the configuration. You just take another dependency and that's it, it will be very easy for you.
Once the container is fixed in your project in a very important place, you begin to use it simply as the basis of everything. I want to demonstrate how you can make an ordinary multipage SPA using a DI container.
We will take some kind of router. Its implementation is not important. It is important that when it is matched to a url, it will assign a name to this page. In this case, perhaps home and profile.
Take our container and describe there as keys home and profile. We describe everything that we do not want to get there. And we want to get some component that we take and insert into the body. In this case, this is some sort of layout. Layout is used both there and there, it just encapsulates various dependencies. What to do next? What components will go deeper, already at this stage it does not matter, because they already somehow work, someone has set them up. We only care about the level of abstraction that we are working on right now.
Everything, we can from the DI-container by key, by the name of the page request some kind of dependency. In this case, this is a sign on the Layout, and this Layout will already contain all the necessary data, all the components, all that we want to do. It only remains to add it to the body.
What about the testability of all this? As soon as we begin to use it, it arises that the classes do not depend on the container directly. Nowhere and never will you use the container directly in the sense that I need such a dependency, I will take it and get it. No, rather, it will lie at the very bottom of the architecture, at the very bootstrap of your application, as demonstrated on the previous slide.
In fact, your classes do not depend on it at all; you can take them from anywhere and to port anywhere.
All dependencies are transmitted during the creation, and if we are talking about testing, in this place we can easily put mocks, fixture data and anything, simply because it already works that way. DI-container made us write code so that everything works that way.
A few examples. When creating, when we are engaged in testing and we want to blot the user settings, so that they do exactly what we want, and not what they have written, we can create a user, slip test data under it. We can use a container for this - a dependency tree has already been formed, we can override some of them. In the future, just by their logic of working with DI, everyone who ever wanted to receive UserSettings will receive them, no matter where they are. We can use it for testing.
There is another interesting example. If we assume that all data models that go somewhere to the server for data will use some specially written ajaxAdapter for this, then during the tests we can replace it with our own class TestAjaxAdapter, which can implement logic. This is how it is implemented, for example, in Sinon, if someone tried to get wet with it.
Or we can go even deeper. We implemented in this adapter such logic that when it is first used in tests, it starts recording requests and responses from a real server, and when it is restarted, it simply plays it from the cache. This cache we add to the repository to our test data. And when we want to do testing on fixtures and are afraid that they will change over time from the fact that the logic of communication with the server has already been implemented here, we replace the TestAjaxAdapter. In the repository formed some kind of cache, which will then be reused.
How can this be used even more interesting? We have already mentioned Gemini testing . This is one type of visually regressive testing. Who does not know, Gemini is a testing method in which we take a screenshot of some of our block on the finished page, put it to the test data in the repository, and when we want to do a reverse test, we re-launch, re-do the screenshot and compare it pix-by-pixel . If somewhere the pixels did not match - the test dropped. This is a very simple and effective type of testing, verification of visual regressions. We work with CSS, it has a feature: it constantly breaks. Gemini helps us get rid of these breakdowns.
What have we done in this place? Since everything was implemented through the DI-container, we specially prepared the server, which could be passed as parameters identifiers from the DI-container. He simply formed it, drawing on the page alone this component that we wanted. In this case, there is something connected with the recipes, some kind of card, real data, on which there were test runs, a real screenshot.
After the test was run, ajaxAdapters were replaced, and a cache was created related to how the server communicated. We have this data - constantly reproducible with time, and the tests become stable.
This approach is applicable to any type of test. If you want to browse by component into the Selenium browser and click on it, nothing bothers you, because you get a fully working piece of functionality that you want to commit to. And you can even make several blocks at the same time, just display them on the page and click on them. There are some event connections or something else between the blocks. Even if the blocks do not correspond to the present site, you can thus test some logic.
I read a cursory report on what DI is. I hope someone is interested. If you need details, I am available at the links: mail , GitHub , Telegram , Twitter .
Here are the links where you can find new information about what was here. For example, the fully implemented DI container I mentioned, the inversify DI container is a very cool thing for TypeScript. Here are some more links to figure out how to put everything together.
- github.com/ftdebugger/di.js
- dev.to/kayis/dynamic-imports-with-webpack-2
- www.npmjs.com/package/inversify
- github.com/vlyahovich/quantum-router
Thank.
Source: https://habr.com/ru/post/341710/
All Articles