R, Asterisk and wardrobe
It is a continuation of previous publications . The main purpose of publications is to demonstrate the capabilities of R in solving various “routine” tasks of processing data arising in business. The main focus is on creating a complete solution for the end user, and not on the fundamental solution of a particular task by typing commands in the console. A schematic prototype and product from the conveyor have more differences than similarities.
On the fine mechanics of R there are a huge number of specialized blogs, books, and also github. But they usually turn to them only after they see that the solution of the problem by means of R is possible and very elegant.
How it all began
In general, the initial situation is very typical for companies that have at least some semblance of a call center serving the requests of external users. There is a PBX (in our case - several geographically separated Asterisk instances, version 13LTS). There is an information system / system in which operators contribute what they have heard from users. And there is a pile of automated business processes for processing user requests.
There is also a vertical of leadership from the head of the call center to top management, as well as related units, for example, marketing, which for strategic management require a summary of how people live, how KPIs behave and where business goes. And here the wishes and capabilities of each other find themselves very weakly.
If in part of the desk service some report generator already existed, then Asterisk initially had nothing but logs and cdr.
Step # 1
We tried to follow the standard path, we looked at the existing Asterisk tools. As a first approximation, we stopped at free software versions:
It got a little better. The required analytical report was finally prepared by the responsible employees. However, the quality of this reporting was very poor for several reasons:
- Processing scripts in asterisk were very complex and written through macros. Normally, CDR files are generated with a focus on minimizing the number of records. Therefore, in the resulting CDRs, when the internal transfers and shoulders were collapsing, a number of important data was lost. Both A numbers (due to macros) and B numbers (when combining the shoulders initiated by the operator).
- Queues also contain incomplete information. No IVR records, no information on transfer to the outside. And a lot of things not.
- The programs themselves can and produce generally accepted statistics on call centers, but in relation to our tasks, more than half of the output results were not very useful for business, because they did not answer the right questions.
- Free versions are trimmed by functionality + I had to “finish my” php with my hands, so that at least it did not fall. I ignore the wrong duration calculations, because of their insignificance (~ 10%). For simplicity, I write it off on our specific asterisk settings.
- Data from external directories and systems can not be attached. Everything is just hands in excel. For example, to submit a report not by numbers, but by the name of the operator, taking into account the shift schedule.
- There is no graphic representation, and those that are offered in paid versions are far from what is required.
- Different systems almost always gave different numerical results. Sometimes the difference reached hundreds of percent. Obviously, this was due to the complexity of calls, as well as differences in the algorithms of calculations embedded in the programs.
Step 2
Undertook the independent analysis of cdr and log files. R. was used as an analysis tool. In fact, the data itself is not very much. Several thousand calls to the CNN result in 1-2 GB records in packed form for a year of work. For modern laptops - this is complete nonsense, not to mention the server hardware.
And here began interesting things. Even the most cursory glance various data cuts caused a lot of technical issues leading to the tuning of asterisks.
- Why don't macros give out the right information for certain types of conversations?
- Why are identifiers sometimes lost, allowing us to link tripartite sessions in which the operator is an intermediary?
- Why do the time metrics in cdr not always coincide with real time events? The time in the IVR is not always and not in full must be considered (depending on logic), and the IVR may be different.
- Why are there not a number of required parameters in the queues?
But this is only the technical side of the issue. After a careful study of the data, it was decided to abandon the use of cdr (too incomplete and unreliable data were recorded there, and radically modifying the logic of cdr formation on production did not inspire anyone in optimism. Therefore, they switched to the call-flow analysis model based on data obtained from the log queues (queue log) with the following logic:
- we reconstruct all events within the call flow using the identifiers of the primary session and linked sessions;
- we perform event thinning based on the kpi business logic (multiple RING NO ANSWER; multiple ENTER QUEUE in the same queue or to another; ATTENDENT TRANSFER \ BLIND TRANSFER to external numbers, etc.);
- for lined up cleared call flow we recalculate the real duration of all events based on their time stamps;
- We are enriching the call-flow with data from external sources, in particular, from the schedule of duty shift operators, in order to get a full name from the operator number;
- we get a "clean" set of "raw" data for which we are already building all the necessary reporting.
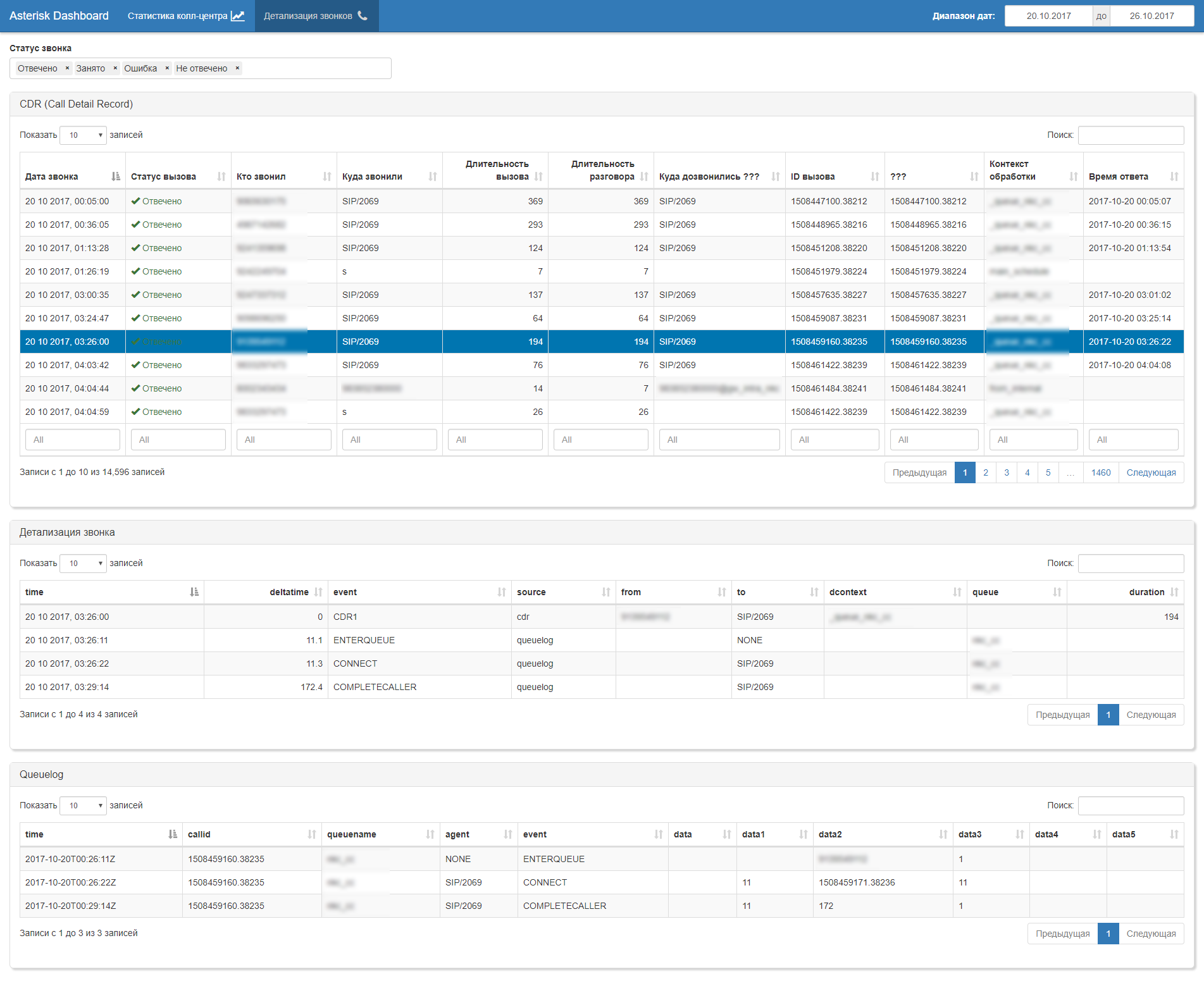
In general, automatic generation of a set of business artifacts follows: dashboards, reports, uploads (xls, pdf, csv, doc, ppt, ...)
The AWP itself for the head of the call center is built on Shiny.

It is important that after such a “cleansing” of data one could sit at the table with the business and discuss the metrics (KPI) and the method of their calculation. Does the subscriber's time in the internal IVR count as the duration of the call or not? Does CONNECT consider the subsequent instant return to the queue as the response of the operator or not? How to decompose KPI operators and queues subscriber in multiple queues? How to compare the average waiting time in the queue with the time of day and the number of operators in a shift? What are the typical "optimization" scenarios for operators? And a lot of other questions. The best part is that all questions can be given a clear and unequivocal answer.
An additional advantage to switching to call-flow event analysis is the possibility of studying call center operation scenarios. In fact, reverse engineering of business processes by their tracks in the call center logs. Curious things show up!
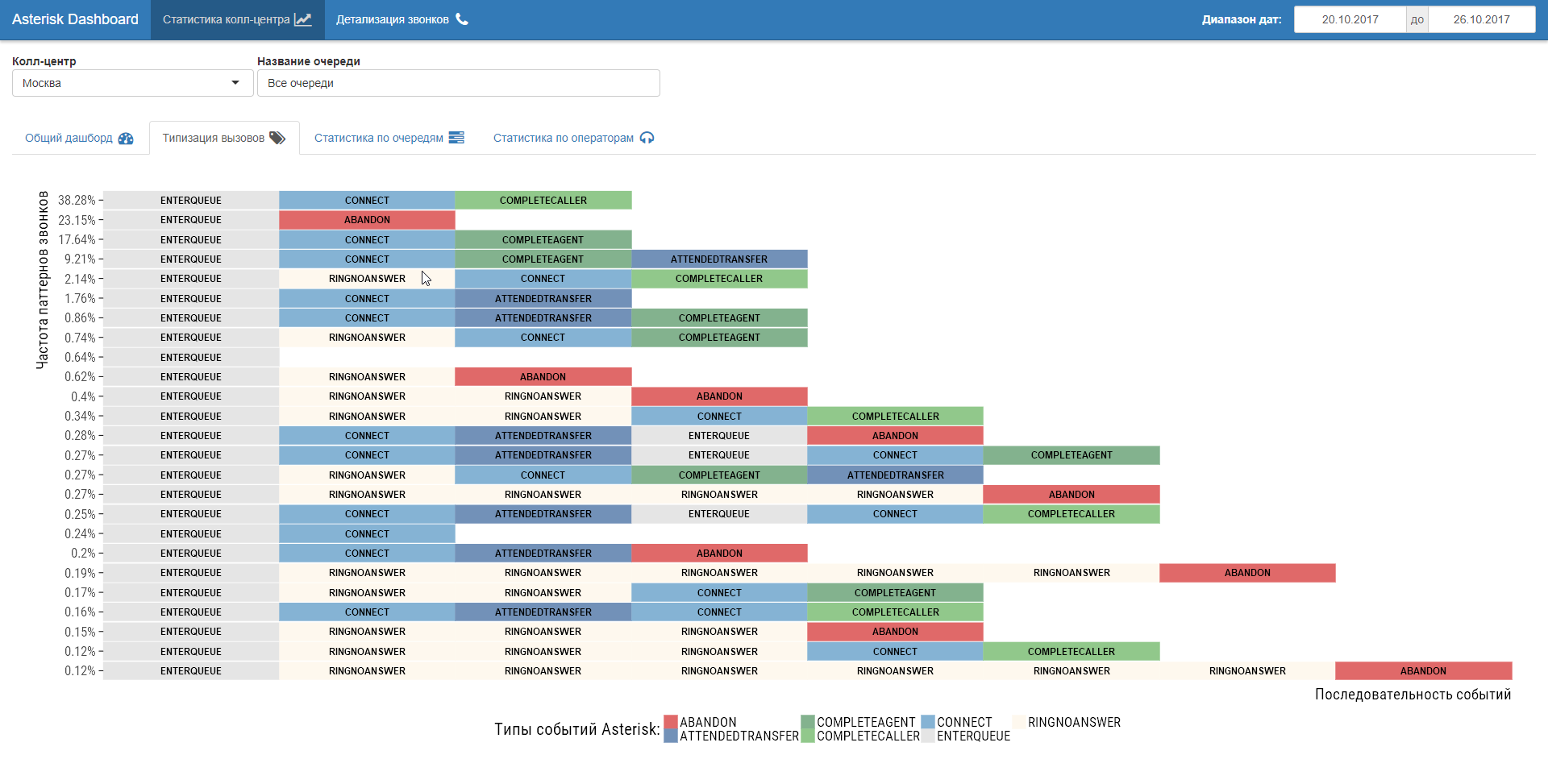
Step 3
Transition to the analysis of AMI events. In general, this is the most universal way, but it requires a little more computing power. After an insignificant adjustment of the queue logs, the sharpness in the AMI analysis disappeared for an individual asterisk, but storing them in the context of the asterisk's historical work (troubleshooting) remains useful. Also, working with AMI ensures independence from the individual settings of an individual asterisk, which will be relevant when connecting the following. To ensure the speed of working with AMI, we "dump" all 151 event types with 619 possible fields in ClickHouse.
Afterword
As many may say, the task is very private, the data volumes are small. But from this, the importance of this task for the business does not diminish. The use of the same R allowed to solve it quickly and elegantly, while creating a comfortable workplace for ordinary business users. And from the point of view of industrial programming, everything is also ok: packaging, documenting functions using roxygen, autotests, logging, everything that can be done online with checks and assertions.
Now, having a solid foundation, you can safely move on to forecasting and operational analytics.
The answer to the question “what does the wardrobe have to do with?” Is, alas, quite prosaic. Because from it came the skeletons, which were carefully hidden by call center operators. And R + Shiny served as a key to open it.
Previous Post: Do you already apply R in business?
')
Source: https://habr.com/ru/post/341668/
All Articles