Ten Node.js Questions You Can't Answer
This year, at the Forward.js JavaScript conference, I gave a talk on “You don't know Node”. During the presentation, I asked the audience a few questions about Node, and most of those present could not answer many of them. But my report listened to technical experts. I didn’t make any calculations, but it looked that way, and several listeners who approached me after the performance confirmed this.

The problem that made me do this performance is that, in my opinion, the Node training system is not built correctly. Most training materials focus on Node packages, but not on the platform itself. Often these packages serve as wrappers for Node modules (like
I selected several questions and answers from that conference and included them in this article. The questions themselves are presented in the headings of sections of the article. Try reading the question, do not read further, but first answer it mentally. If you find a mistake in my answers - please let me know .
Call Stack is definitely part of the V8. This is the data structure that V8 uses to track function calls. Every time we call a function, V8 places a reference to this function on the call stack, and when other functions are called from this function, it continues to do the same with references to them. In addition, functions that call themselves recursively are added to the stack.
')

Call stack Screenshot from my Pluralsight advanced Node.js course
When, with nested function calls, the function terminates, V8 retrieves the function reference from the top of the call stack and substitutes the value returned to it where the program logic requires.
Why is it important to understand when working with Node? The fact is that there is only one call stack for each Node process. If the stack is full, the process will be loaded with some work. This is worth remembering.
Where do you think the next figure shows the event loop?

Environment V8. Screenshot from my Pluralsight advanced Node.js course
The event loop is implemented in the
The event loop is an entity that processes external events and converts them into callback calls. This is a rather complicated loop that takes events from the event queue and puts their callbacks on the call stack.
If you hear about a cycle of events for the first time, the above reasoning may not be particularly intelligible. The event loop is part of a much more general picture:

The cycle of events. Screenshot from my Pluralsight advanced Node.js course
In order to understand the essence of the event cycle, it is useful to know about the environment in which it works. You need to understand the role of V8, be aware of the Node API, and how the event queue works, the code associated with which is executed in V8.
Node's APIs are functions like
The cycle of events is in the center of all this (of course, in fact, it is all more complicated) and plays the role of an organizer. When the V8 call stack is empty, the event loop can decide what to do next.
The answer is simple: Node will just shut down.
When you start the application, Node automatically starts the event loop, and when the event loop is idle, when it has nothing to do, the process shuts down.
In order for the Node process not to complete, you need to put something in the event queue. For example, when you start a timer or HTTP server, you tell the event loop that it needs to continue to work and monitor these events.
Here are some standalone libraries that the Node process can use:
All of them, in relation to the Node, are external. They have their own source code, their distribution is governed by separate licenses. Node just uses them.
This is worth remembering in order to know exactly where the code of your program is executed. If, for example, you are doing data compression, you may encounter a problem that occurred in the depths of the
This is a tricky question. To run the Node process, you need a JS engine, but V8 is not the only available engine. Alternatively, you can use Chakra.
Take a look at this Github repository to learn more about the
To export modules API you can always use the
Why?
The
Suppose you have a
Next, there is another module,
Why? After all, if you do the same in the browser, then after connecting the scripts, you can refer to their global variables.
Each Node file is wrapped in its own immediately invoked functional expression (IIFE, Immediately Invoked Function Expression). All variables declared in the Node file are inside this IIFE and are not visible from the outside.
Here is the question related to the question under consideration: what will be displayed after running the next Node file, in which there is only one line of code:
Obviously, some arguments will fall into the console!
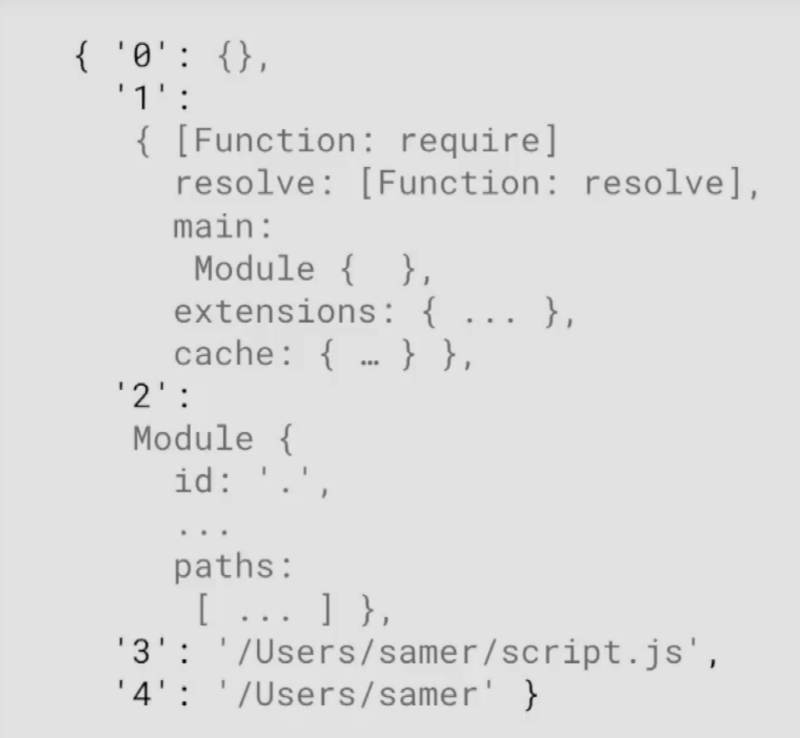
Output arguments
Why? The point is that this Node file performs as a function. Node wraps the code in a function and this function has five arguments, which can be seen in the figure.
When you need a
The whole thing - in the already familiar to us IIFE:

Study of the features of the work Node
As you can see, IIFE passes the following five arguments to the code:
These five variables appear to be global when used in Node, but they are, in fact, the usual function arguments.
If you have a module
There will be no error message. Node allows this.
So,
Each asynchronous method of the
Sometimes there is nothing wrong with synchronous methods. For example, they can be useful at the initialization stage, when the server is loaded. Often they are used like this when everything that is done after initialization depends on the data loaded at the initialization stage. Instead of building code based on callbacks in such situations, when a one-time download of any data is performed, synchronous methods are quite acceptable.
However, if you use synchronous methods inside some event handlers, such as the HTTP server callback, which is responsible for handling requests, then this is absolutely wrong without options. Doing so strongly is not recommended.
I hope you were able to answer all these questions, or at least some of them.
Dear readers! If you were at a JS conference, in the place of the author of this article, what questions about Node.js would you ask the audience?
The problem that made me do this performance is that, in my opinion, the Node training system is not built correctly. Most training materials focus on Node packages, but not on the platform itself. Often these packages serve as wrappers for Node modules (like
http or stream ). As a result, the one who does not know Node and is faced with a problem, the source of which may not be a package, but the platform, is in a very disadvantageous position.I selected several questions and answers from that conference and included them in this article. The questions themselves are presented in the headings of sections of the article. Try reading the question, do not read further, but first answer it mentally. If you find a mistake in my answers - please let me know .
Question number 1. What is the call stack and is it part of the V8 engine?
Call Stack is definitely part of the V8. This is the data structure that V8 uses to track function calls. Every time we call a function, V8 places a reference to this function on the call stack, and when other functions are called from this function, it continues to do the same with references to them. In addition, functions that call themselves recursively are added to the stack.
')
Call stack Screenshot from my Pluralsight advanced Node.js course
When, with nested function calls, the function terminates, V8 retrieves the function reference from the top of the call stack and substitutes the value returned to it where the program logic requires.
Why is it important to understand when working with Node? The fact is that there is only one call stack for each Node process. If the stack is full, the process will be loaded with some work. This is worth remembering.
Question number 2. What is the event loop? Is it part of the V8 engine?
Where do you think the next figure shows the event loop?
Environment V8. Screenshot from my Pluralsight advanced Node.js course
The event loop is implemented in the
libuv library. It is not part of the V8.The event loop is an entity that processes external events and converts them into callback calls. This is a rather complicated loop that takes events from the event queue and puts their callbacks on the call stack.
If you hear about a cycle of events for the first time, the above reasoning may not be particularly intelligible. The event loop is part of a much more general picture:
The cycle of events. Screenshot from my Pluralsight advanced Node.js course
In order to understand the essence of the event cycle, it is useful to know about the environment in which it works. You need to understand the role of V8, be aware of the Node API, and how the event queue works, the code associated with which is executed in V8.
Node's APIs are functions like
setTimeout or fs.readFile . They are not part of javascript. These are just functions that Node gives us access to.The cycle of events is in the center of all this (of course, in fact, it is all more complicated) and plays the role of an organizer. When the V8 call stack is empty, the event loop can decide what to do next.
Question number 3. What will Node do when the call stack and event loop queues are empty?
The answer is simple: Node will just shut down.
When you start the application, Node automatically starts the event loop, and when the event loop is idle, when it has nothing to do, the process shuts down.
In order for the Node process not to complete, you need to put something in the event queue. For example, when you start a timer or HTTP server, you tell the event loop that it needs to continue to work and monitor these events.
Question number 4. Besides the V8 engine and the libuv library, what other external dependencies does Node have?
Here are some standalone libraries that the Node process can use:
http-parserc-aresOpenSSLzlib
All of them, in relation to the Node, are external. They have their own source code, their distribution is governed by separate licenses. Node just uses them.
This is worth remembering in order to know exactly where the code of your program is executed. If, for example, you are doing data compression, you may encounter a problem that occurred in the depths of the
zlib stack. Perhaps the reason - in the library error, so do not blame all the blame on Node.Question number 5. Can I run the Node process without V8?
This is a tricky question. To run the Node process, you need a JS engine, but V8 is not the only available engine. Alternatively, you can use Chakra.
Take a look at this Github repository to learn more about the
node-chakra project.Question number 6. What is the difference between module.exports and exports?
To export modules API you can always use the
module.exports command. You can, with the exception of one situation, use and exports : module.exports.g = ... // Ok exports.g = ... // Ok module.exports = ... // Ok exports = ... // Ok Why?
The
exports — command is just a link, an alias for the module.exports construct. When you try to write something directly to exports , you change the link that is stored there, as a result, during subsequent calls to exports you no longer work with what this variable refers to in the official API (and this is module.exports ) . By writing something to exports , you turn this keyword into a local variable within the scope of the module.Question number 7. Why aren’t top-level variables global?
Suppose you have a
module1 module in which a top-level variable g defined: // module1.js var g = 42; Next, there is another module,
module2 , to which module1 connected and trying to access the variable g , receiving in response an error message g is not defined .Why? After all, if you do the same in the browser, then after connecting the scripts, you can refer to their global variables.
Each Node file is wrapped in its own immediately invoked functional expression (IIFE, Immediately Invoked Function Expression). All variables declared in the Node file are inside this IIFE and are not visible from the outside.
Here is the question related to the question under consideration: what will be displayed after running the next Node file, in which there is only one line of code:
// script.js console.log(arguments); Obviously, some arguments will fall into the console!
Output arguments
Why? The point is that this Node file performs as a function. Node wraps the code in a function and this function has five arguments, which can be seen in the figure.
Question number 8. The exports, require, and module objects are globally available in each file, but each file has its own instances. How is this possible?
When you need a
require object, you simply call it directly, as if it were a global variable. However, if you examine the require in two different files, it turns out that we have two different objects. Why is this so?The whole thing - in the already familiar to us IIFE:
Study of the features of the work Node
As you can see, IIFE passes the following five arguments to the code:
exports , require , module , __filename , and __dirname .These five variables appear to be global when used in Node, but they are, in fact, the usual function arguments.
Question number 9. What are the cyclic dependencies of modules in Node?
If you have a module
module1 , which depends on module2 , and module2 , in turn, depends on module1 , what happens? Will an error message appear? // module1 require('./module2'); // module2 require('./module1'); There will be no error message. Node allows this.
So,
module1 connects to module2 , but since module2 connects to module1 and module1 is not fully ready yet, module1 will simply receive an incomplete version of module2 . Now you know about it.Question number 10. When is it permissible to use synchronous methods for working with the file system (like readFileSync)?
Each asynchronous method of the
fs object in Node has a synchronous version. Why use synchronous methods instead of asynchronous?Sometimes there is nothing wrong with synchronous methods. For example, they can be useful at the initialization stage, when the server is loaded. Often they are used like this when everything that is done after initialization depends on the data loaded at the initialization stage. Instead of building code based on callbacks in such situations, when a one-time download of any data is performed, synchronous methods are quite acceptable.
However, if you use synchronous methods inside some event handlers, such as the HTTP server callback, which is responsible for handling requests, then this is absolutely wrong without options. Doing so strongly is not recommended.
Results
I hope you were able to answer all these questions, or at least some of them.
Dear readers! If you were at a JS conference, in the place of the author of this article, what questions about Node.js would you ask the audience?
Source: https://habr.com/ru/post/341646/
All Articles