Graylog2 incremental setup

In the first article of this series, I explained how and why we chose open-sourced Graylog2 for the centralized collection and viewing of logs in the company. This time I will share how we deployed the greylog in production, and what problems we encountered.
Let me remind you that the cluster will be located on the hosting site, logs will be collected from all over the world via TCP, and the average number of logs will be about 1.2 TB / day under normal conditions.
')
We currently use CentOS 7 and Graylog 2.2, so all configurations and options will be described exclusively for these versions (in Graylog 2.2 and Graylog 2.3, a number of options are different).
Placement planning
According to our calculations, we need 6 servers. Each server has 2 network interfaces; the first is 100MB per world and 1GB private network. On the external interface, it will listen to the web interface and on the part, the nodes will listen to HAproxy, but more on that later. Private 1GB network is used to report the rest.
In total, we have 6 Hp DL380p Gen8 servers, 2x Intel Octa-Core Xeon E5-2650, 64 GB RAM, 12x4TB SATA. This is the standard host configuration. We broke the disks like this: 1 disk for the system, Mongu and the log of the greyloga, the rest - 0 raid and for the elastic storage. Since replication occurs at the level of the elastic itself, we do not need other raids very much.
Servers are distributed as follows:
- in the first 4: HAproxy, elasticsearch, graylog, mongod, keepalived, cerebro;
- on the remaining 2 only elasticsearch and graylog.
Schematically, it looks like this:
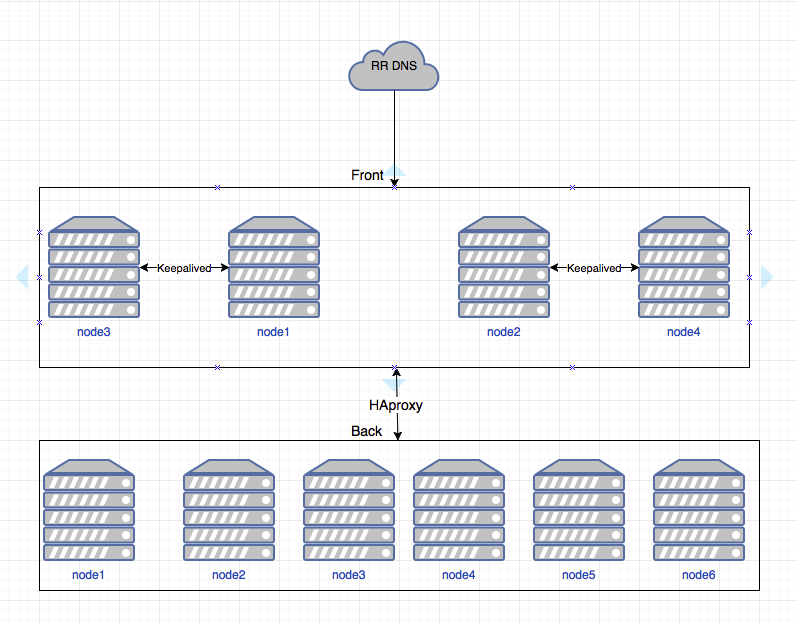
Settings:
- DNS shows 2 addresses, which are usually located on 1 and 2 nodes;
- Between 1-3 and 2-4, HAproxy is configured so that in the event of a node falling, the address rises on another node;
- then each node using HAproxy spreads traffic across all graillogs nodes;
- The greylog in turn also balances the processing of logs by nodes.
(We will not stop at setting up HAproxy and keepalived, as this is beyond the scope of this article.)
Initial setup
The initial setup of Graylog2 is quite simple and trivial, so I simply strongly advise everyone to act according to official instructions:
- docs.graylog.org/en/2.2/pages/installation/operating_system_packages.html
- docs.graylog.org/en/2.2/pages/architecture.html#big-production-setup
- docs.graylog.org/en/2.2/pages/configuration/multinode_setup.html#configure-multinode
There is a lot of useful information that will further help in understanding the principles of configuration and tuning. During the initial setup, I have never had any problems, so let's move on to the configuration files.
In the graillog server.conf, at the first stage, we specified:
# Specify our time zone
root_timezone = Europe/Moscow # Since there are not so many hosts, we indicate here all the elastic hosts
elasticsearch_discovery_zen_ping_unicast_hosts = elasticsearch_discovery_zen_ping_multicast_enabled = false # We allow starting the search from wildcard, because we all understand what it is and what it threatens
allow_leading_wildcard_searches = true # This refers more to tuning, but at the first stage we specified a ring_size equal to half of the L2 cache of the processor.
# And specify the data to send letters with greylog (in the blank lines you need to insert your data).
#Email transport
transport_email_enabled = true transport_email_hostname = smtp.gmail.com transport_email_port = 465 transport_email_use_auth = true transport_email_use_tls = false transport_email_use_ssl = true transport_email_auth_username = transport_email_auth_password = transport_email_subject_prefix = [graylog] transport_email_from_email = transport_email_web_interface_url = Next you need to try out the elastic elastic in the / etc / sysconfig / elasticsearch file (31 GB recommended in the dock):
ES_HEAP_SIZE=31g At the initial stage, we did not rule anything any more and for a while did not even know any problems. Therefore, we proceed directly to launching and configuring the greilog itself.
Storage and assembly of logs, access rights
It's time to set up our greylog and start receiving data. The first thing we need is to decide how we will get the logs. We stopped at GELF TCP - it allows you to configure collectors via the web interface (I will show a little below).
We set up our first input. In the System / Inputs web interface at the top left, select GELF TCP and then Launch new input:
A window opens:
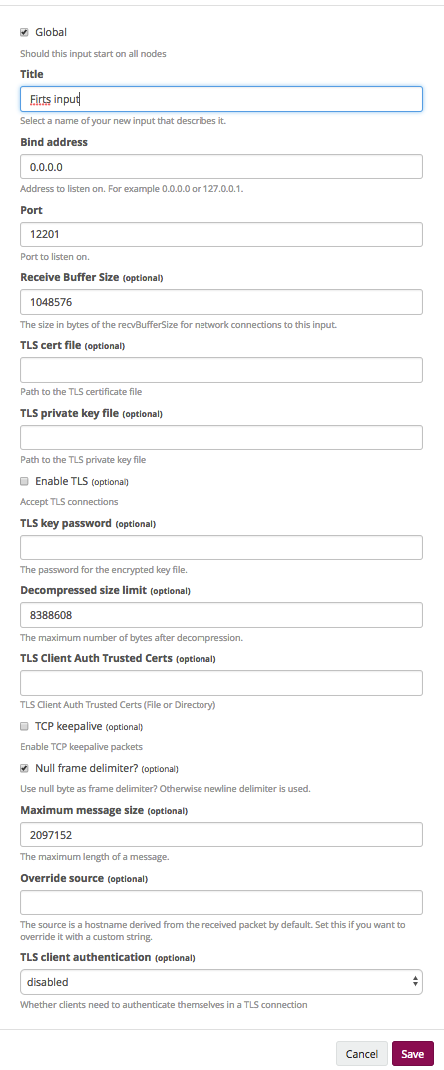
- Global. Says that the input will be raised on all nodes.
- Title. What will be called input.
- Bind address. What address will our input be sent to (in our case it is 0.0.0.0, because there are different addresses on all the nodes).
- Port. Here we must remember that HAproxy stands before our partners as a balancer, respectively, we enter here the port to which the balancer will be redirected.
- Receive Buffer Size, Decompressed size limit and Maximum message size. It is selected on the basis of specific cases.
- Customize ssl as desired.
Now we have our first input, which will receive messages. We proceed to setting up the storage of logs. It is necessary to decide how many logs and how we will store them.
We divided everything into projects and logically related services within projects, and then divided by the number of logs we need to store. Personally, we store part of the logs for 14 days, and some - 140.
Data is stored in graillog indexes. Indices, in turn, are divided into shards. Shards are Primary and Replica. By default, data is written to the primeri shards and replicated to the replica. We only replicate important indexes. Large indexes have 2 primary shards and one replica, which guarantees the failure of 2 nodes without losing data.
Let's create an index that will have 2 shards and 1 replica and will store their logs for 14 days.
We go to System \ Indices, there we click Create index set:
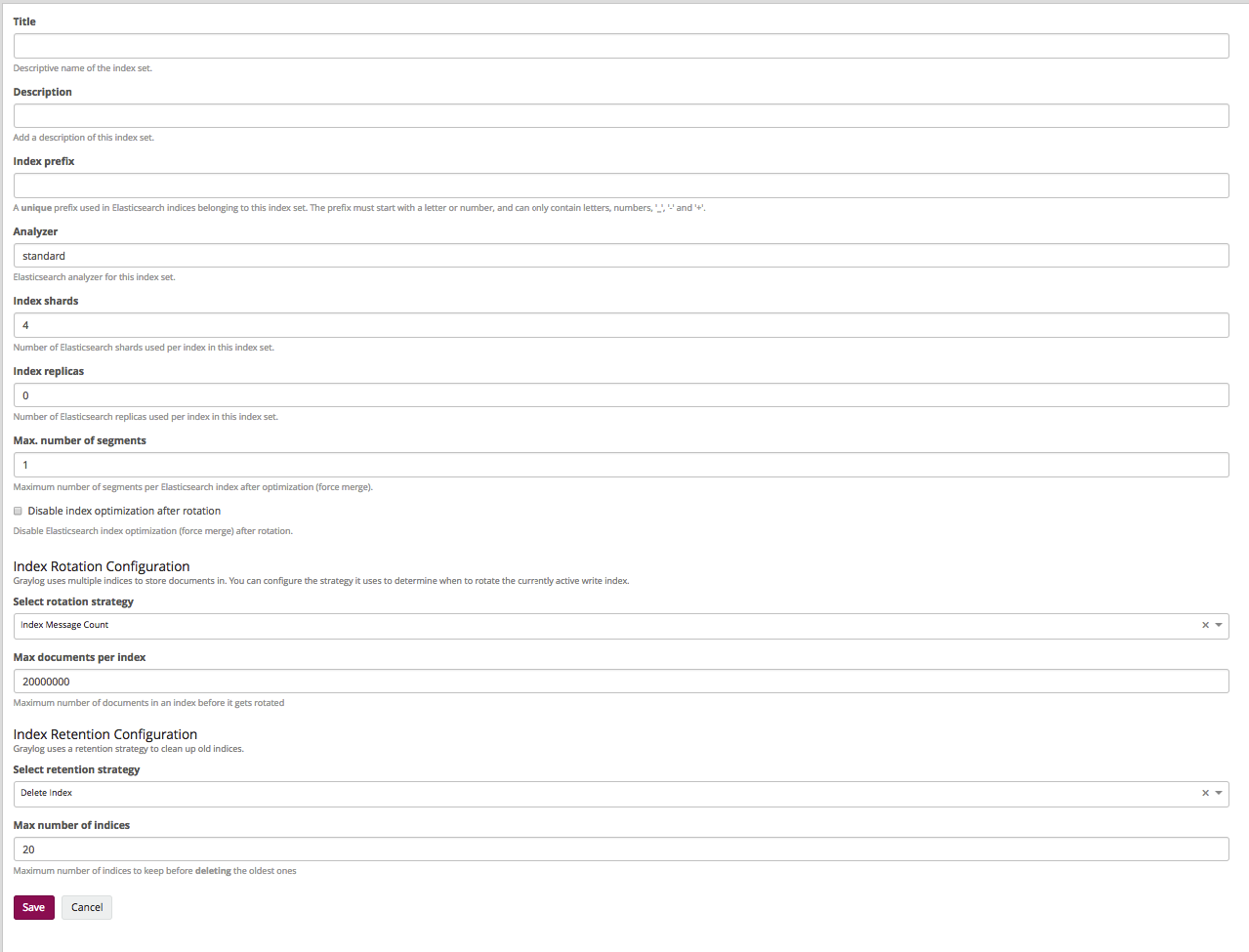
- Title and Description. Everything is clear here - the name and description.
- Index prefix. What prefix in the elastic will have indices (usually somehow reflects the name of the index itself in the greylog).
- Analyzer. We do not change.
- Index shards. The number of shards (we want to have 2 primari shards, so there must be 2).
- Index replicas. The number of replicas of each shard is 1.
- Max. number of segments. Usually we do not optimize shards, so we leave 1.
The following items are responsible for the number of stored logs and by name it becomes clear that they can be stored by the number of messages, by time, and by the size of the index. We want to store 14 days.
- Select rotation strategy - Index Time.
- Rotation period (ISO8601 Duration). There is in the documentation, we leave P1D, which says: one index - one day.
- Select retention strategy - Delete index. We will delete the old indexes.
- Max number of indices. The maximum number of indices, we put 14, which in this case means that 14 indices of 1 day will be stored.
Now we need to do the so-called stream. Greylog provides rights at the level of these same streams. The bottom line is this: in the stream we specify in which index to write data and on what conditions. It is located in Sterams. Setup takes place in 2 stages.
1. Creating a stream.
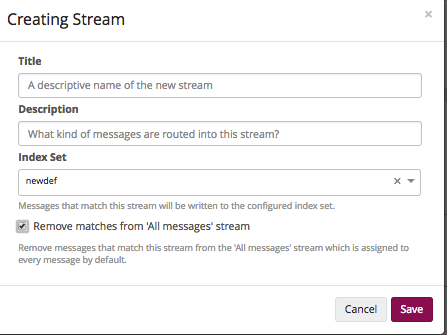
- Title and Description. As usual - the name and description.
- Index Set. In which index to write data, then choose the one that you created earlier.
- Remove matches from 'All messages' stream. Delete messages from 'All messages'. To avoid confusion - delete.
2. Further Manage Rules.
Everything is simple there: we add the necessary rules by which the logs will get there.
Now we have an input that accepts logs; the index that stores them; and stream, which essentially collects a lot of logs in one space.
Further we set up sending logs to the greylog itself.
Agent configuration
The agent configuration path is described here . It all works in the following way: Graylog Collector Sidecar is installed on the client, which manages the log collector's backend (in our case for Linux and Windows, this is nxlog).
Let's prepare the rules for assembling System \ Collectors \ Manage Configurations logs. Create a configuration and go to its configuration, there immediately go to the tab NXLog. We see 3 fields: Output, Configure NXLog Inputs and Define NXLog Snippets. These are all pieces of NXLog's configs, which will be the collector to climb to the final nodes. From here we will manage the fields and their values, as well as the files that we will be monitoring, etc.
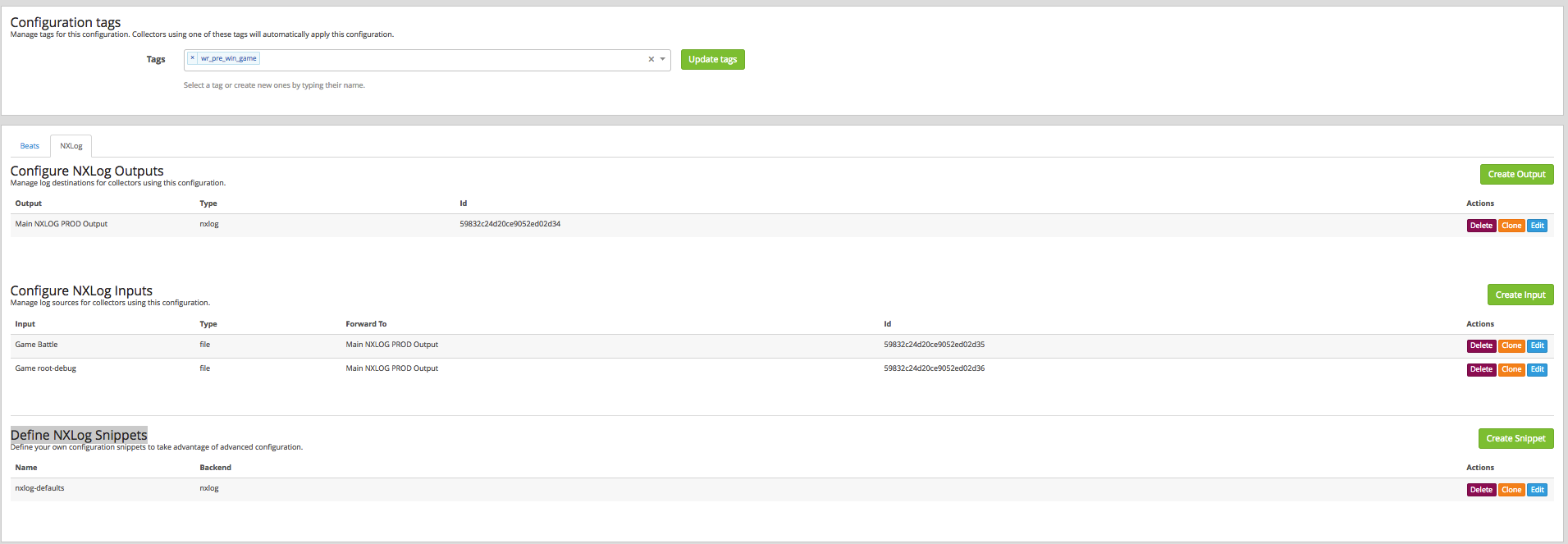
Let's start with the tags. We drive in tags according to which the client will understand which configuration he needs to pick up.
Output field, there is one configuration:
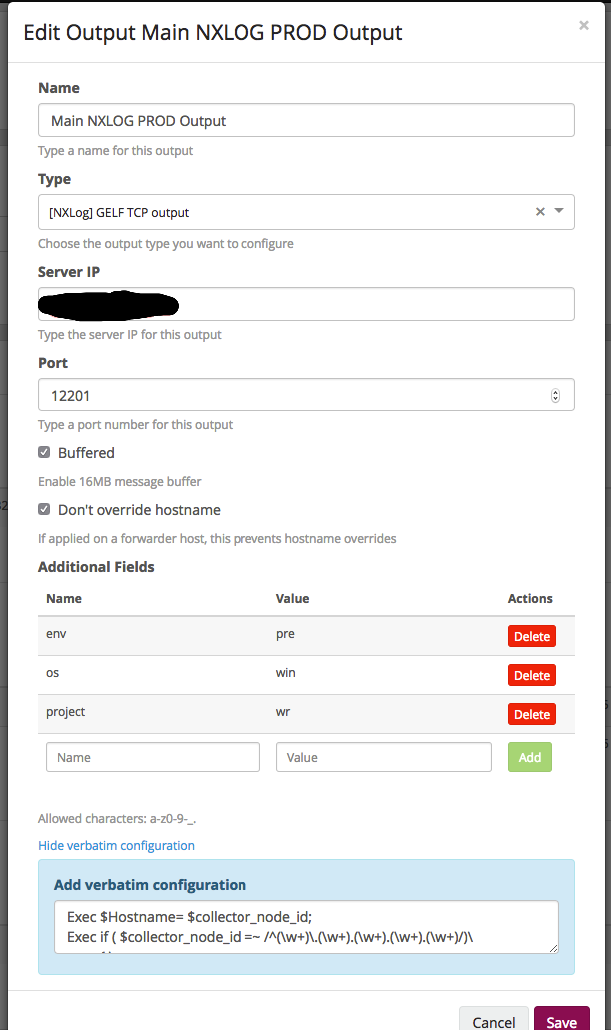
- Name. Everything is clear here - the name by which we understand what it is.
- Type. In our case, this is TCP.
- Server IP. Here we specify the address where to send the logs (in our case, this is the DNS, the name that is allowed in 2 addresses).
- Port. As we remember, we use a balancer - at the entrance we indicate the port of the balancer, which in turn spreads on the greylogs nodes.
- Next, turn on the buffer on the host.
- And do not overwrite the hostname.
- Additional Fields. Here we add additional fields that will be applied at the configuration level.
- Next field for manual configuration fields. Details can be read on the site NXLog'a. In our case, as an example, simply splitting the hostname into the required fields:
Exec $Hostname= $collector_node_id; Exec if ( $collector_node_id =~ /^(\w+)\.(\w+).(\w+).(\w+).(\w+)/)\ { \ $name = $1;\ $datacenter = $2; \ $region = $3;\ $platform = $5;\ }; This was a general configuration setting, where to send and how to sign each log. Next in the Configure NXLog Inputs field, we indicate which files to monitor.
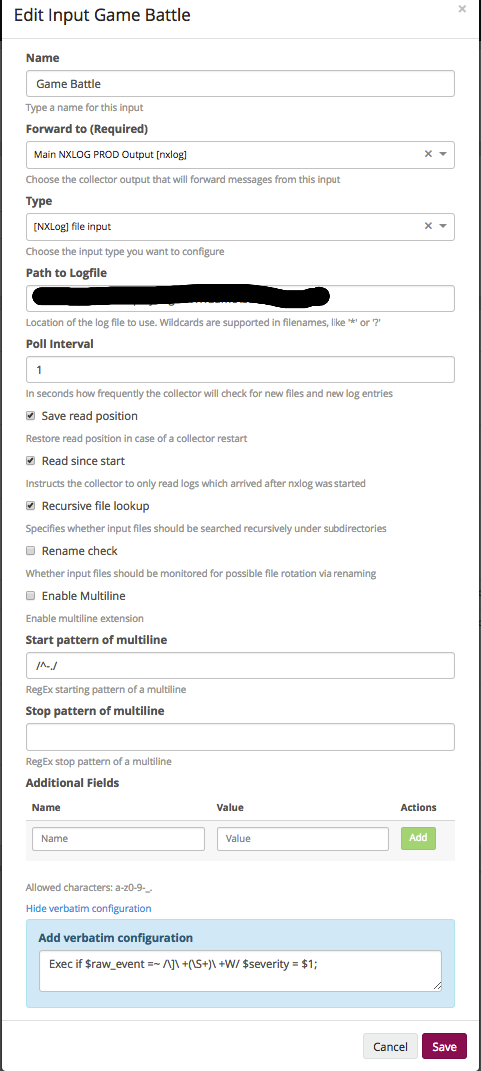
- Name - ...
- Forward to (Required). This is the above created output.
- Type. There are quite a lot of types that NXLog can do, in this case we specify the file, which means that we will take the data from the file.
- Path to Logfile. Path to file or files. Regexps are supported, you just need to remember that in the case of Windows, the file must have an extension and all the files in the directory look like this: “*. *”.
- Poll Interval. How often to check changes in seconds.
- The next set of check boxes describes the behavior of working with a file and depends on the specifics of your logs.
- And then again, custom fields and raw field. In this case, we select a field from the log and transfer it as severity.
Define NXLog Snippets, we usually do not touch.
At this point, we assume that the default setting is complete, you can add more files, fields, etc. there.
Let's proceed to the installation of the agent. In general, it is very well described by reference , so here we will not stop at the manual rolling of agents, but immediately proceed to automation. We make it ansiblom.
Under Linux, there is nothing complicated, and on Windows there is a problem in the automatic installation, so we simply unpack the file and generate unique UUIDs on the ansibla side. Roles for ansibla:
At this setting can be considered complete and the first logs will begin to appear in the system.
I would also like to talk about how we have tuned the system to fit our needs, but since the article has already turned out to be quite voluminous, it will be continued.
Source: https://habr.com/ru/post/341274/
All Articles