Transformer - new neural network architecture for working with strings
Necessary preface: I decided to try the modern format of carrying light to the masses and try to stream on YouTube about deep learning.
In particular, at some point I was asked to tell about attention, and for this you need to tell about machine translation, and about sequence to sequence, and about applying to pictures, and so on. The result was such a stream for an hour:
I understand from other posts that c video is taken to post his transcript. Let me better talk about what is not in the video - about the new neural network architecture for working with sequences based on attention. And if you need an additional background about machine translation, current approaches, where attention, etc. came from, you watch the video, okay?
The new architecture is called Transformer, it was developed in Google, described in the article Attention Is All You Need ( arxiv ) and there is a post about it on the Google Research Blog (not very detailed, but with pictures).
Go.
Over-summary of previous episodes
The task of machine translation in deep learning comes down to working with sequences (as well as many other tasks): we train a model that can receive a sentence as an input for a sequence of words and produce a sequence of words in another language. In the current approaches, inside the model there is usually an encoder and a decoder - the encoder converts the words of the input sentence into one or more vectors in a certain space, the decoder - generates a sequence of words in another language from these vectors.
The standard architectures for an encoder are RNN or CNN, for a decoder it is most often RNN. Further development has put the mechanism of attention on this scheme and about it is better to see stream.
And now a new architecture is proposed to solve this problem, which is neither RNN nor CNN.
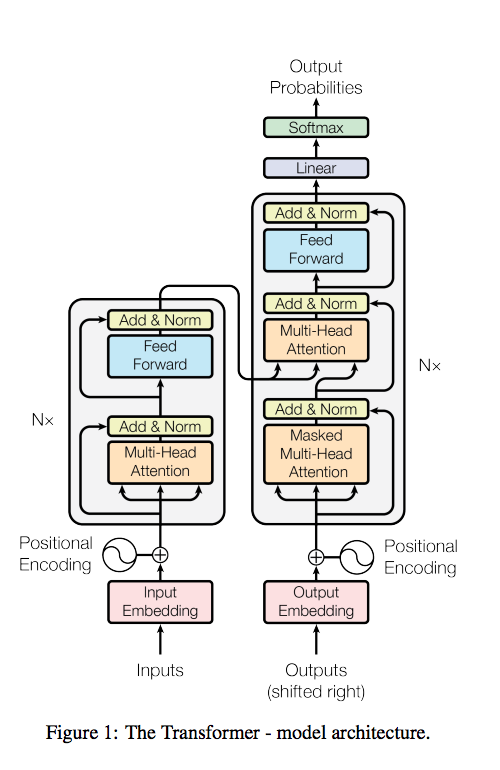
Here is the main picture. What's in it that!
Encoder and Multi-head attention layer
Let us first consider an encoder, that is, the part of the network that receives words at the input and outputs some embeddings that correspond to the words that will be used by the decoder.
Here it is specifically: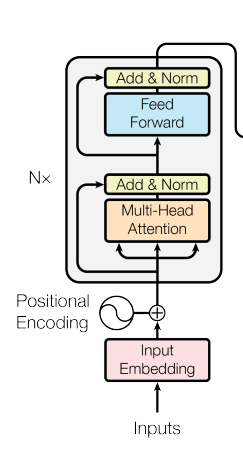
The idea is that each word in parallel passes through the layers shown in the picture.
Some of them are standard fully-connected layers, some are shortcut connections like in ResNet (where in the Add picture).
But the new interesting thing in these layers is Multi-head attention. This is a special new layer that allows each input vector to interact with other words through the attention mechanism, instead of transmitting the hidden state as in RNN or neighboring words as in CNN.

Query vectors are given as input, and several Key and Value pairs (in practice, Key and Value are always the same vector). Each of them is transformed by a learning linear transformation, and then the scalar product Q is calculated with all K in turn, the result of these scalar products is run through softmax, and with the resulting weights, all the vectors V are summed into a single vector. This wording of attention is very close to previous works where attention is used.
The only thing that they complement it is that there are several such interests in parallel (their number in the picture is indicated by h), i.e. several linear transformations and parallel scalar products / weighted sums. And then the result of all these parallel interests is concatenated, once again it is run through the learning linear transformation and goes to the output.
But in general, each such module receives as input a Query vector and a set of vectors for Key and Value, and returns one vector of the same size as each of the inputs.
It is not clear what it gives. In standard attention, “intuition” is clear - the network “attention” tries to match one word to another in a sentence if they are close to something. And this is one network. Here, the same thing, but a bunch of networks in parallel? And they do the same thing, but the output concludes? But then what is the point, will they learn exactly the same thing?
Not. If there is a need to pay attention to several aspects of words, then this gives the network the opportunity to do this.
Such a trick is used quite often - it turns out that there are enough stupidly different initial random weights to push different layers in different directions.
What are several aspects of words?
For example, a word has features about its meaning and pro grammatical.
I would like to get vectors corresponding to the neighbors in terms of the semantic component and the grammatical one.
Since the output of such a block produces a vector of the same size as it was at the input, this block can be inserted into the network several times, adding network depth. In practice, they use a combination of Multi-head attention, the residual layer and the fully-connected layer 6 times, then this is such a deep enough network.
The last thing to say is that one of the features of each word is positional encoding — that is, his position in the sentence. For example, from this, when processing words, it is easy to “pay attention” to adjacent words if they are important.
They use as a feature a vector of the same size as the word vector, and which contains sine and cosine from a position with different periods, so that they say it is easy to pay attention to the relative offset by choosing a coordinate with the desired period.
Tried instead, embeddingings of the positions were also taught and it turned out the same thing as with the sinuses.
They also have LayerNormalization ( arxiv ) stuck . This is the normalization procedure, which normalizes the outputs from all the neurons in the trainer inside each sample (unlike each neuron, separately inside the batch, as in Batch Normalization, apparently because they did not like BN).
They say that BN in recurrent networks does not work, since the normalization statistics for different sentences of one batch only spoils everything, but does not help, because the sentences are all of different lengths and all that. In this architecture, too, is this effect expected and harmful to BN?
Why they did not take BN is an interesting question, the article does not particularly comment. It seems to have been successful attempts to use with RNN for example in speech recognition. Deep Speech 2 by Baidu ( arxiv ), AFAIR
Let's try to summarize the work of the encoder on points.
Encoder operation:
- Embeddingings are made for all words of a sentence (a vector of the same dimension). For example, let it be a sentence
I am stupid. In the embedding is added the position of the word in the sentence. - The vector of the first word and the vector of the second word (
I,am) are taken, fed to a single-layer network with one output, which gives the degree of their similarity (scalar value). This scalar value is multiplied by the vector of the second word, receiving its some "weakened" by the value of similarity copy. - Instead of the second word, the third word is submitted and the same thing is done as in paragraph 2. with the same network with the same weights (for vectors
I,stupid). - By doing the same for all the remaining words of the sentence, their "weakened" (weighted) copies are obtained, which express the degree of their similarity to the first word. Then these all weighted vectors are added to each other, getting one resultant vector of dimension of one embedding:
output=am * weight(I, am) + stupid * weight(I, stupid)
This is the mechanism of the "usual" attention. - Since the assessment of the similarity of words in just one way (according to one criterion) is considered insufficient, the same thing (p.2-4) is repeated several times with other weights. Type one one attention can determine the similarity of words on the semantic load, the other on grammatical, the rest somehow, etc.
- At the exit of p.5. several vectors are obtained, each of which is a weighted sum of all the other words of the sentence as to their similarity to the first word (
I). We conclude this rector in one. - Then another layer of the linear transformation is put, which reduces the dimension of the result of item 6. to the dimension of the vector of one embedding. It turns out a certain representation of the first word of the sentence, composed of the weighted vectors of all the other words of the sentence.
The same process is done for all other words in a sentence.
- Since the dimension of output is the same, then you can do the same thing again (p.2-8), but instead of the original embeddingdings of words, take what you get after going through this Multi-head attention, and take the neural networks of attenuation inside with other weights (weights between layers are not common). And you can do a lot of such layers (for Google 6). However, between the first and second layer, a full meshed layer and residual compound are added to add nets of expressiveness.
In a blog they have about this process being visualized by a beautiful gif - for now look only at the encoding part:
As a result, for each word we get the final output - embedding, on which the decoder will look.
Go to the decoder

The decoder is also launched one word at a time, receives the last word as input, and must output the following (at the first iteration, it receives a special token <start> ).
The decoder has two different types of using Multi-head attention:
- The first is the ability to refer to the vectors of past decoded words, as well as it was in the encoding process (but not all can be addressed, but only to those already decoded).
- The second is the ability to access the encoder output. In this case, the Query is the input vector in the decoder, and the Key / Value pairs are the final encoder embeddings, where again the same vector goes both as a key and as a value (but the linear transformations within the attention module are different for them)
In the middle there is just the FC layer, again the same residual connections and layer normalization.
And all this is repeated again 6 times, where the output of the previous block goes to the next input.
Finally, at the end of the network is the usual softmax, which gives the probabilities of words. Sampling from it is the result, that is, the next word in the sentence. We give it to the input of the next launch of the decoder and the process repeats until the decoder issues a token <end of sentence> .
Of course, this is all end-to-end differentiable, as usual.
Now you can see the whole gif.
During encoding, each vector interacts with all others. During decoding, each next word interacts with the previous ones and with the encoder vectors.
results
And this good decently improves the state of the art on machine translation.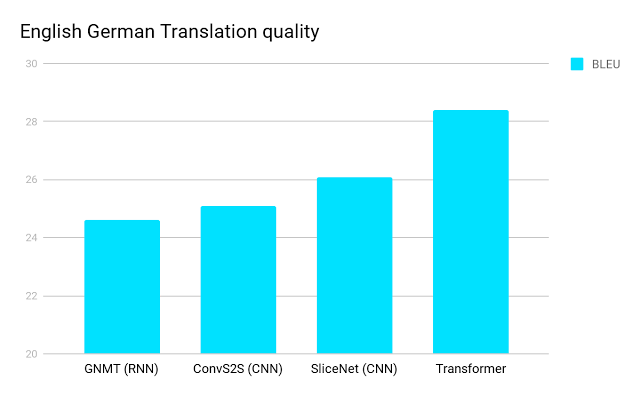
2 points BLEU - this is quite serious, especially since at these values BLEU is worse correlated with how much a person likes the translation.
In general, the main innovation is the use of the self-attention mechanism to interact with other words in a sentence instead of RNN or CNN mechanisms.
They theorize that it helps, because the network can equally easily access any information, regardless of the length of the context — accessing the last word or the word 10 steps back is equally easy.
It is easier to learn from this and it is possible to carry out calculations in parallel, in contrast to the RNN, where you need to take each step in turn.
They also tried the same architecture for Constituency Parsing, that is, grammatical analysis, and everything worked out too.
I haven’t yet seen confirmation that Transformer is already being used in the Google Translate production (although it’s necessary to think it’s being used), but the use in Yandex.Translate was mentioned in an interview with Anton Frolov from Yandex (just in case the timestamp is 32:40).
What can I say - well done and Google, and Yandex! It's very cool that new architectures are emerging, and that attention is no longer just a standard part for improving RNN, but gives an opportunity to take a fresh look at the problem. So you see and get to the memory as a standard piece get.
')
Source: https://habr.com/ru/post/341240/
All Articles