Fuzzy string comparison: understand me if you can

Hello!
In natural language, the same fact can be said in an infinite number of ways. You can rearrange words in places, replace them with synonyms, incline according to cases (if we are talking about a language with cases), and so on.
The need to determine the similarity of two phrases arose in solving one small practical problem. I didn’t use machine learning, I didn’t use neural networks, but I used simple metrics and statistics collected to calibrate the coefficients.
')
The result of the work, a description of the process, the code on git is ready to share with you.
So, briefly, the task can be voiced as follows: “With a certain periodicity, relevant news comes from various sources. It is necessary to filter them in such a way that the output did not have two news about the same fact. ”
Warning: in the article there are headlines of real news. I treat them exclusively as a working material, I do not represent any point of view on the political or economic situation in any country.
Task Restrictions
The task is of an applied nature, it is necessary to set restrictions:
- Each news item consists of a headline and body (content).
- A headline is a meaningful sentence in a natural language by which a person can understand the essence of the news.
- The header has a length of no more than 100 characters. It can consist of any characters, including numbers, punctuation, and special characters.
- The maximum number of new news that may appear in the period of 5 minutes - 20 pieces.
- New news should be compared with all the news that came in the last day.
From 4 and 5 points of restrictions, you can generate a new limit: the maximum number of news with which you need to compare the new news is 24 hours * (60 min. / 5 min.) * 20 pieces = 5760 news. (It should be noted that 20 new news in 5 minutes is a hypothetically possible value, but in fact 1 or 2 really new news comes in 15-20 minutes, which means the actual value will be 24 * (60/15) * 1 = 96) .
From constraint 2, we conclude that it is enough to analyze the news headlines without paying attention to their content.
Header examples
sixteen; The government has made changes to the Kuril development program.
18; The Cabinet of Ministers has increased funding for the federal program for the development of the Kuril Islands
nineteen; The government has increased funding for the development of the Kuril Islands
6; Engineers have become the most popular in the labor market
12; Named the most popular profession in Russia
20; The most popular professions in Russia have become known.
26; Engineers are recognized as the most popular on the labor market in the Russian Federation
32; Engineers became the most popular on the labor market of the Russian Federation in September
51; Named the most popular profession in Russia
53; Ministry of Labor named the most popular professions in Russia
25; Sberbank since October 16, reduces the rate on consumer loans
31; Sberbank reduced interest rates for a number of loans
37; Sberbank reduced interest rates on a number of loans
0; Russia will release its own cryptocurrency - crypto-ruble
five; Russia urgently creates a crypto-ruble
27; In Russia, will be engaged in the release of crypto-ruble
35; Russia will create its own cryptocurrency
36; Russia will begin to produce crypto rubles
42; Russia will release its own cryptocurrency - crypto-ruble
Ways of fuzzy string comparison
I will describe several methods for solving the problem of determining the degree of similarity of two strings.
Levenshtein distance
Returns a number that indicates how many operations need to be done (insert, delete, or replace) in order to turn one string into another.
Properties: simple implementation; dependence on word order; number on output; which should be compared with something.
Shingle algorithm
Splits texts into shingles (English - scales), that is, chains of 10 words (with intersections), applying hash functions to shingles, gets matrices that they compare to each other.
Properties: to implement the algorithm it is necessary to study the material part in detail; works on large texts; There is no dependence on the order of sentences.
Jacquard Ratio (quotient - Tanimoto coefficient)
Calculates the coefficient by the formula:
here a is the number of characters in the first line, b is the number of characters in the second line, c is the number of matching characters.
Properties: easy to implement; low accuracy, since “abc” and “bca” are the same for him.
Combined approach
Each of the above algorithms has critical shortcomings for the problem being solved. In the process, the calculation of the Levenshtein distance and the Tanimoto coefficient was implemented, but, as expected, they showed poor results.
Empirical reasoning combined approach is reduced to the following steps.
Normalization of compared sentences
Strings are converted to lower case, all characters other than letters, numbers and spaces are deleted.
Normalization of sentences
/// <summary> /// : /// - /// - /// </summary> /// <param name="sentence">.</param> /// <returns> .</returns> private string NormalizeSentence(string sentence) { var resultContainer = new StringBuilder(100); var lowerSentece = sentence.ToLower(); foreach (var c in lowerSentece) { if (IsNormalChar(c)) { resultContainer.Append(c); } } return resultContainer.ToString(); } /// <summary> /// . /// </summary> /// <param name="c">.</param> /// <returns>True - , False - .</returns> private bool IsNormalChar(char c) { return char.IsLetterOrDigit(c) || c == ' '; } Word highlighting
Words are all sequences of characters without spaces, which have a length> = 3. This removes almost all prepositions, conjunctions, and so on. - to what extent this can be attributed to the continuation of normalization.
Word highlighting
/// <summary> /// . /// </summary> /// <param name="sentence">.</param> /// <returns> .</returns> private string[] GetTokens(string sentence) { var tokens = new List<string>(); var words = sentence.Split(' '); foreach (var word in words) { if (word.Length >= MinWordLength) { tokens.Add(word); } } return tokens.ToArray(); } Matching words by substrings
Here, the Tanimoto coefficient is applied, not to symbols, but to tuples of consecutive characters, and the tuples are composed with an overlap.
Fuzzy word comparison
/// <summary> /// . /// </summary> /// <param name="firstToken"> .</param> /// <param name="secondToken"> .</param> /// <returns> .</returns> private bool IsTokensFuzzyEqual(string firstToken, string secondToken) { var equalSubtokensCount = 0; var usedTokens = new bool[secondToken.Length - SubtokenLength + 1]; for (var i = 0; i < firstToken.Length - SubtokenLength + 1; ++i) { var subtokenFirst = firstToken.Substring(i, SubtokenLength); for (var j = 0; j < secondToken.Length - SubtokenLength + 1; ++j) { if (!usedTokens[j]) { var subtokenSecond = secondToken.Substring(j, SubtokenLength); if (subtokenFirst.Equals(subtokenSecond)) { equalSubtokensCount++; usedTokens[j] = true; break; } } } } var subtokenFirstCount = firstToken.Length - SubtokenLength + 1; var subtokenSecondCount = secondToken.Length - SubtokenLength + 1; var tanimoto = (1.0 * equalSubtokensCount) / (subtokenFirstCount + subtokenSecondCount - equalSubtokensCount); return ThresholdWord <= tanimoto; } Applying Tanimoto Ratio to Header
We know how many words there are in each of the sentences, we know the number of “indistinctly matching” words and apply the familiar formula to this.
Fuzzy comparison of sentences
/// <summary> /// . /// </summary> /// <param name="first"> .</param> /// <param name="second"> .</param> /// <returns> .</returns> public double CalculateFuzzyEqualValue(string first, string second) { if (string.IsNullOrWhiteSpace(first) && string.IsNullOrWhiteSpace(second)) { return 1.0; } if (string.IsNullOrWhiteSpace(first) || string.IsNullOrWhiteSpace(second)) { return 0.0; } var normalizedFirst = NormalizeSentence(first); var normalizedSecond = NormalizeSentence(second); var tokensFirst = GetTokens(normalizedFirst); var tokensSecond = GetTokens(normalizedSecond); var fuzzyEqualsTokens = GetFuzzyEqualsTokens(tokensFirst, tokensSecond); var equalsCount = fuzzyEqualsTokens.Length; var firstCount = tokensFirst.Length; var secondCount = tokensSecond.Length; var resultValue = (1.0 * equalsCount) / (firstCount + secondCount - equalsCount); return resultValue; } /// <summary> /// . /// </summary> /// <param name="tokensFirst"> .</param> /// <param name="tokensSecond"> .</param> /// <returns> .</returns> private string[] GetFuzzyEqualsTokens(string[] tokensFirst, string[] tokensSecond) { var equalsTokens = new List<string>(); var usedToken = new bool[tokensSecond.Length]; for (var i = 0; i < tokensFirst.Length; ++i) { for (var j = 0; j < tokensSecond.Length; ++j) { if (!usedToken[j]) { if (IsTokensFuzzyEqual(tokensFirst[i], tokensSecond[j])) { equalsTokens.Add(tokensFirst[i]); usedToken[j] = true; break; } } } } return equalsTokens.ToArray(); } The algorithm was tested on hundreds of headers for several days, the results of its work were visually quite acceptable, but it was necessary to optimally choose the following factors:
ThresholdSentence - threshold for making fuzzy equivalence of the whole sentence;
ThresholdWord - the threshold for making fuzzy equivalence between two words;
SubtokenLength - the size of the substring when comparing two words (from 1 to MinWordLength)
Performance evaluation algorithms
To assess the quality of the work were allocated 100 different news headlines that came one after another. Next, a square matrix of 100x100 was marked up, where I put 0 if the headings were on different topics and 1 if the topics were the same. I understand that the sample is small and will probably not very accurately demonstrate the accuracy of the algorithm, but I did not have enough for more.
Now, when there is a sample with which you can compare the output of the algorithm, we will estimate the accuracy with a simple formula - the ratio of correct answers to the total number of comparisons. In addition, as a metric, you can estimate the number of false positives.
The best results with an accuracy of 87% and the number of false positives of 3% are obtained with the following parameters: ThresholdSentence = 0.25, ThresholdWord = 0.45, SubtokenLength = 2;
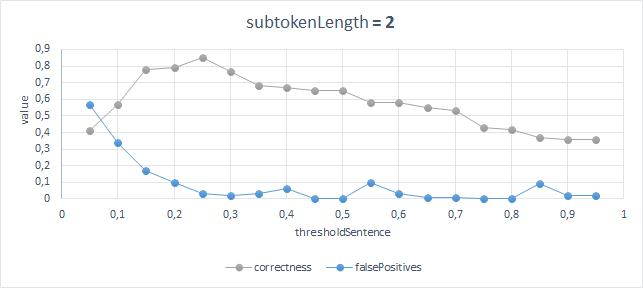
You can interpret the results as follows:
The best accuracy and the smallest number of errors are obtained when comparing words to consider the length of substrings equal to 2 characters, while there must be a ratio of the number of matching substrings to the number of mismatching greater than or equal to 0.45, and the two headers will be equivalent if at least a quarter of the words are the same.
If you take into account the restrictions, it is quite correct results. Of course, you can artificially come up with as many options as you like, on which false positives will appear.
A real example of a false positive
VTB lowered the minimum rate on cash loans
Sberbank reduced interest rates on a number of loans
Conclusion
The origins of this task lie in the fact that I needed to organize for myself the prompt delivery of relevant news. Sources of information - the media, which I constantly read, sitting on the Internet, while losing a lot of time, distracted by unnecessary information, unnecessary clicks on the links. As a result, several small telegram channels and groups in contact were born. If suddenly someone is interested, the links are in the description of my profile.
Ready implementation of algorithms in the form of a library: SentencesFuzzyComparison .
Source: https://habr.com/ru/post/341148/
All Articles