Service alert a million users with RabbitMQ
Almost at the very beginning of the creation of the platform (some foundation, the framework on which all application solutions are based) of our cloud-based VLSI web application, we realized that without a tool to let the user know about any event from the server, it would be quite difficult to live. We all want to instantly see a new message from a colleague (who is too lazy to walk 10 meters), raising the corporate spirit of news from the management, a very important task from the testing department or receiving rewards (especially money). But the path of becoming was thorny, so we will tell you a little about the difficulties that we encountered when growing up from 5.0e3 to 1.0e6 simultaneous connections from users.

Start
The solution "in the forehead" can be a periodic survey from the browser server side. But already then (back in 2013, when people were still shooting videos for Harlem Shake) we had dozens of different services, and their periodic survey could significantly raise our metrics for requests per second. Therefore, there was a question about an intermediate super-service that would allow any backend of any service to send data to any desired user (the reverse interaction works via HTTP).
At that time, web sockets have already gained enough popularity, which allows reducing the overall load and, more significantly, minimizing the delay in information delivery to users' browsers. But, unfortunately, not all browsers that were popular among our favorite users supported web sockets (also not all proxy servers could skip them in the appendix), so support was also needed for more common technologies such as XHR-polling and XHR-streaming.
The service was needed “yesterday”, and therefore, so that the development strategy did not become “chick-chik and production” , they decided to look for existing solutions. The search led us into the hole to the broker RabbitMQ, which at that time already had plug-ins for working with the web environment: Web STOMP adapter and SockJS. The first allows you to associate the binary protocol AMQP with a text STOMP , and the second - to establish a websocket-like connection to the user (he himself is concerned about the choice of supported transport). Hoping for fruitful cooperation, we deployed and tested a cluster of several nodes. RabbitMQ did not upset, and we decided to build a user alert system based on it. At first, everything went well, but the development of functionality in our web application and the increase in the number of active users began to tell us that morning does not start with coffee.
A few words about RabbitMQ
RabbitMQ is a multi-protocol message broker that allows you to organize a fault-tolerant cluster with full data replication to several nodes, where each node can serve read and write requests. It is written in the Erlang language and uses the AMQP protocol version 0.9 as the main one. Consider a casual scheme of the interaction of objects in AMQP:
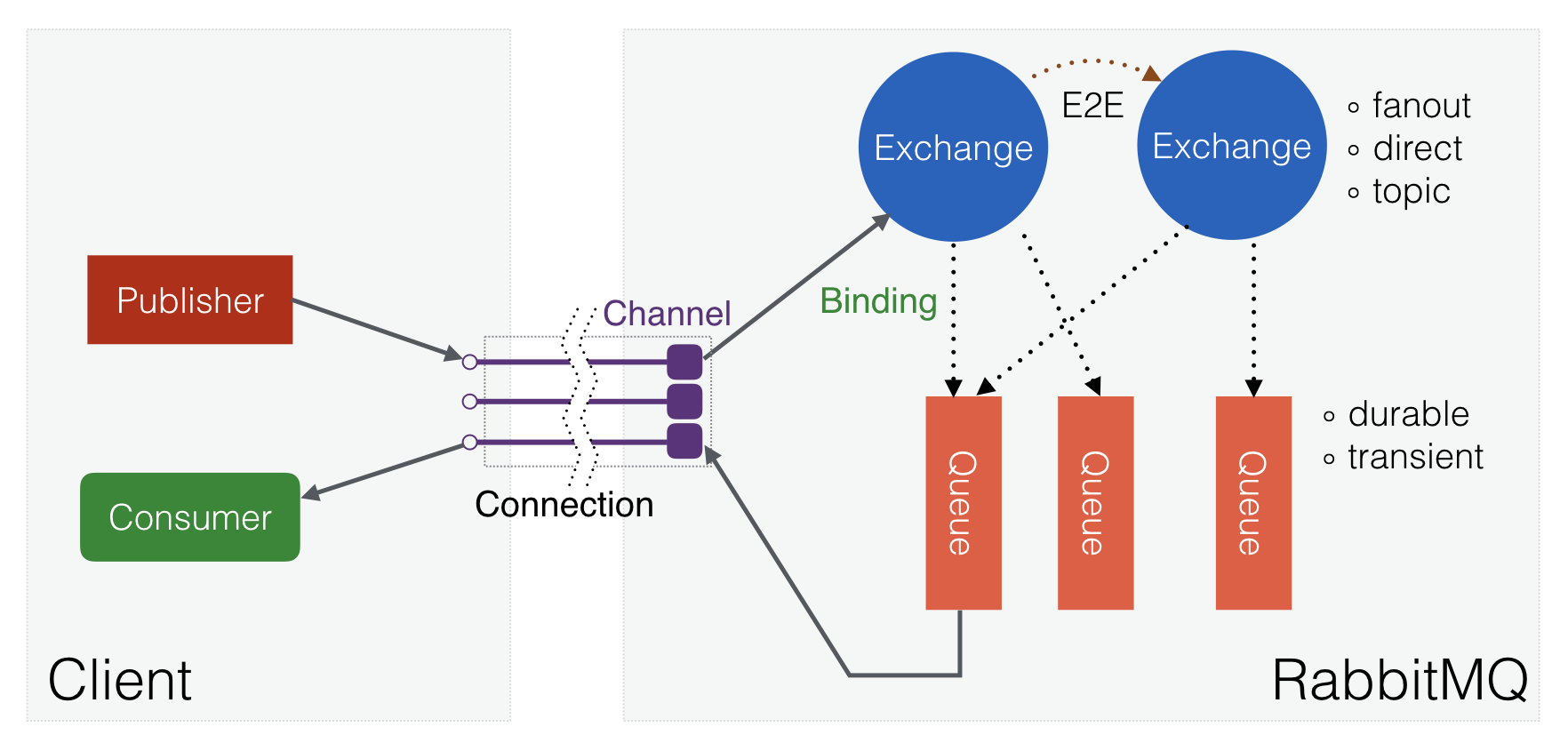
Fig. 1. The interaction of objects in the AMQP.
The queue (queue) stores and gives to consumers (consumer) all incoming messages. The exchanger is engaged in routing messages (does not store them) on the basis of the created connections (binding) between it and the queues (or other exchangers ). From the RabbitMQ point of view, a queue is an Erlang process with a state (where the messages themselves can be cached), and the exchanger is a “link” to the module with the code where the routing logic lies. That is, for example, 10 thousand exchangers will consume about 12 MB of memory, when 10 thousand queues are already about 800 MB.
In cluster mode , meta-information is copied to all nodes. That is, each node contains a complete list of exchangers, queues, their connections, consumers and other objects. The processes themselves with queues by default are located only on one node, but using policies you can enable replication ( mirrored queues ), and the data will be copied automatically to the required number of nodes.
Naive implementation
The first implementation was quite simple:
- RabbitMQ cluster of three nodes, to which both backends and clients were connected;
- At the start, backends created exchangers with the names of their events (including the name of the website, for example, “online.sbis.ru: contacts.new-message”) and the direct type;
- Clients connected via SockJS and “listened” to the events they needed by subscribing (subscribe) to the corresponding exchangers with a key equal to the user ID;
- At the time of the origin of the event, the backend sent an AMQP message to the appropriate exchanger. As the routing key, the message had a recipient identifier.
Schematically, it all looked like this:
Fig. 2. Connection diagram.

Fig. 3. Scheme of objects in the broker.
There are three main types of exchangers in AMQP: fanout, direct and topic.
The easiest and fastest type is fanout. Communication with him does not have any parameters, to receive messages, only their presence is important.
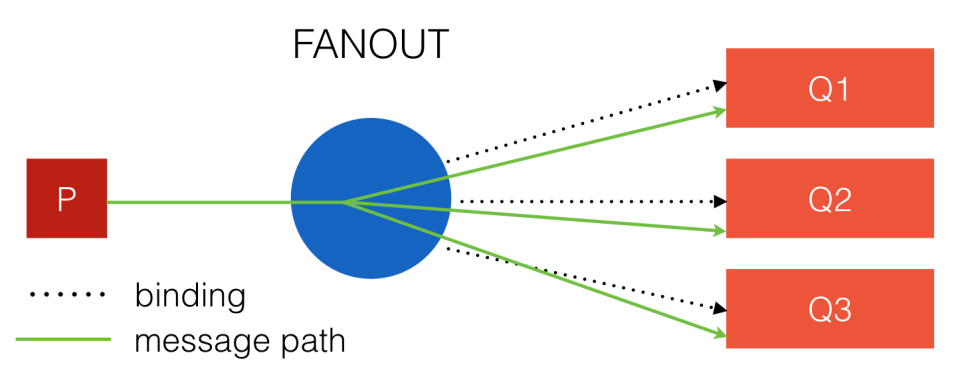
Fig. 4. Fanout exchanger.
Here the dotted line shows the connection, and the green line - the path of the message. It will be copied to all queues.
For the direct exchanger, when creating a connection, a string key is specified, which participates in the selection of candidates for receiving the message. The speed of its work is slightly inferior to the speed of the fanout. When you publish a message, it indicates the routing key (routing key) and, if this key coincides completely with the communication key, then the final queue will receive a message.

Fig. 5. Direct exchanger.
Topic treats a key not just as a string, but as a set of tokens separated by a dot. You can use the asterisk symbol to indicate the unimportance of the value of the token for us or the grid symbol, which replaces zero or more tokens.

Fig. 6. Topic exchanger.
The speed of such an exchanger depends on the complexity of the key and the number of tokens in it, and in the simplest case it is similar to the speed of the direct exchanger.
There is another type of exchanger - headers, but it is not recommended to use it because of the speed of work, so we omit it.
The increase in the number of events
At that time, the client code in the browser “listened” to an average of about 10 events per page, but their growth did not take long (now, for example, only about 70 of them are on the main page). Their unpredictable life adds pain - an event may be required at any time and for any interval of time.
But the main problem, of course, was created by the fact that when you subscribe to the STOMP for any exchanger, a queue is automatically created, which is already associated with the exchanger. And if there are 30 such subscriptions, then there will be 30 queues (within one connection), which can not but affect the resources consumed and the frequency of the call to the OOM killer service.
To solve this problem, we changed the approach and removed the name of the event from the name of the exchanger in the header of the AMQP message itself. The structure is simplified and began to look something like this:

Fig. 7. The structure of the objects after the first improvement.
Thus, we have removed the dependence on the number of events on the page, and now only one subscription was required by the user. But I had to sacrifice traffic, since in the new approach, it was possible to understand whether an event is necessary for the user, only after it is delivered to the user.
Publication areas
In our system, there are the concepts of "client" - any company that uses our product, and "user" - an employee of the client. Companies are completely different, and someone may have two or three employees, and someone may have a few thousand. If you wanted to send a message to all users of the client, you had to go over the entire list in a loop, which could take a long time. Therefore, it was urgent to do something about it.
The solution was the creation of three areas of publication: the user, the client and globally everything. The global area is required to send system information, for example, please reload the page after updating the backends. Each region was implemented in RabbitMQ as an exchanger with the direct type and, in order not to force the client to make several subscriptions again, another exchanger with the fanout type was added - the user's personal exchanger.
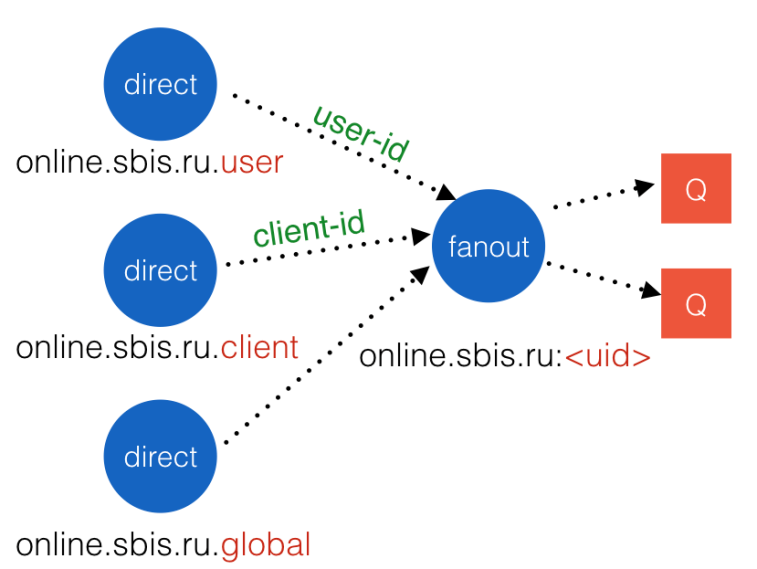
Fig. 8. The structure of objects with areas of publication and personal exchanger.
The personal exchanger contacted the exchangers of the regions with the necessary identifiers, and the user needed to simply connect to it without any parameters. But now we had to create personal exchangers before users would subscribe, otherwise there would be an error. Pre-creating objects for all existing users is quite expensive. Therefore, we decided to create them dynamically at the moment of connection. To do this, a nugget was made on Nginx (faced RabbitMQ), jerking a helper utility before proxying a broker request. The utility checked the existence of all necessary and created in the absence. Later, they made a utility call only for the request / info , which is mandatory for SockJS.
Auto-delete queue
Initially, we created queues that were automatically deleted after disconnecting (auto-delete), but this led to two big problems:
With a short break in communication, we lost messages that had not yet reached;
- A large number of operations were performed in the system for creating / deleting queues and connections, especially before the optimization of the number of subscriptions. In the cluster mode, such a large workflow sprawled across all nodes and created an increased load. This phenomenon is called binding churn.
As a result, they switched to permanent (persistent) queues that are not deleted at the time of disconnecting the connection, but the “expire” policy was hung on them if the user is not longer than 5 minutes. (The system does not pursue the goal of storing data that is not received by the user forever, but is developed only for their prompt delivery.)
The load on the RabbitMQ cluster has decreased, but user growth has continued. After a pass of 50 thousand simultaneous users, the system approached its border in terms of resource consumption. We had to change something again.
Alerts 2.0
After the problems we experienced earlier, we realized that in this case scaling up the RabbitMQ cluster nodes is not a very optimal way, since problems on one node affected the performance of other nodes, and some kind of fault tolerance at the level of data duplication was not required for our system. But on the other hand for backends it is very convenient to have a single point for connection. After some discussion, they came to the conclusion that the system should be divided into two layers: 1) RabbitMQ cluster for connecting backends and 2) independent RabbitMQ nodes for connecting users. As a result, we have the following scheme:

Fig. 9. Two-layer wiring diagram.
Independent nodes were given the name "Web", since users connect to them via web protocols. These nodes themselves connect to the cluster using the Federation RabbitMQ plugin .
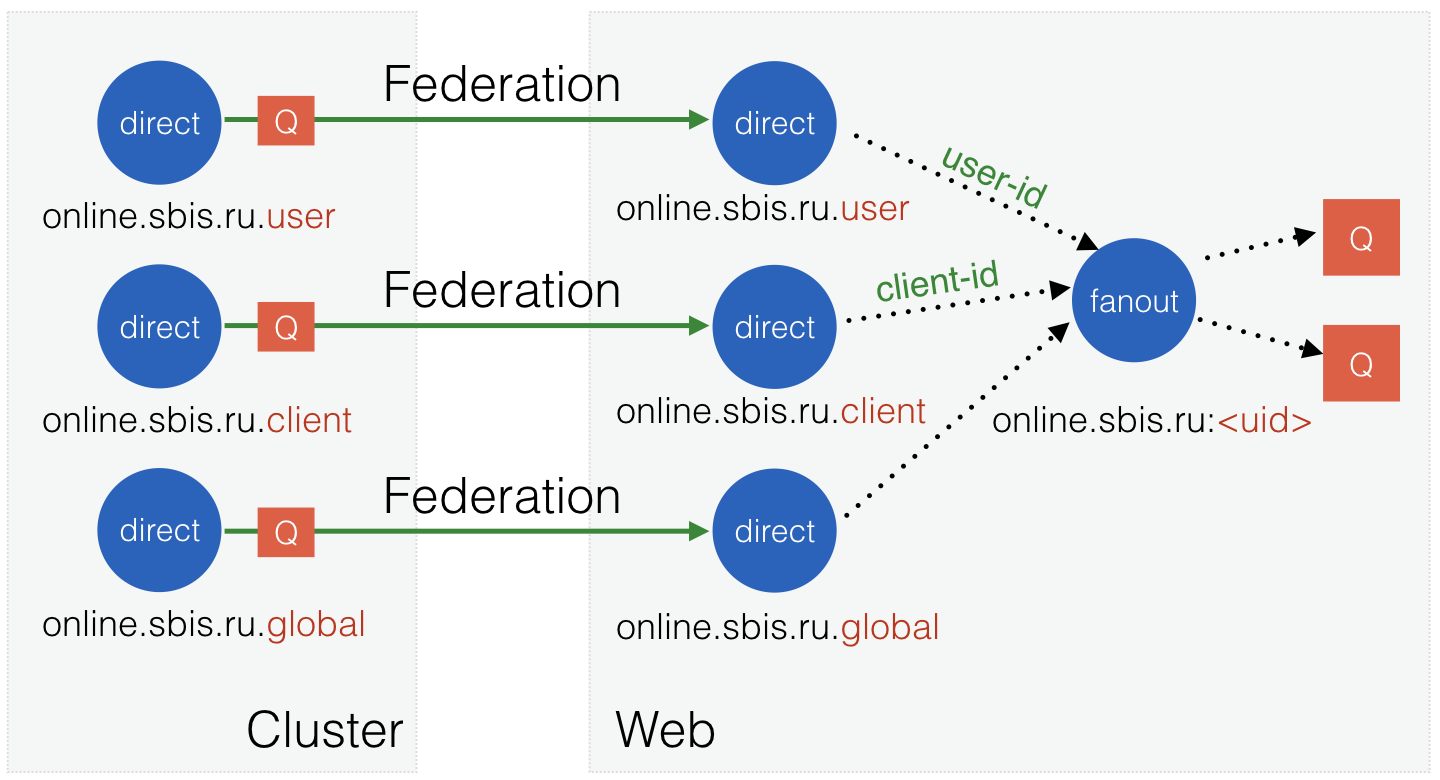
Fig. 10. The structure of objects in a two-layer scheme.
Setting up federation on websites is quite simple:
- We create an upstream (upstream, source), it can consist of both a single node and a list of nodes for fault tolerance;
- We create a policy in which we say that exchangers with such a name template should be synchronized with upstream.
After that, the Federation will connect to the upstream nodes, create their own queues for them and subscribe them to the necessary exchangers, then start receiving messages and duplicate them into local exchangers.
Thus, the message published in the exchanger on the cluster, will fall into the same exchangers on all Web sites. And the latter we can scale almost linearly depending on the number of users. Great how!
Customer distribution
The most ideal scenario would be the even distribution of client connections among all websites, as well as their “loyalty” to only one of them, which would help reduce the overhead of the user. But do not forget that the nodes fail, and the user does not have to wait until this node is repaired. In front of N websites we have M dispatchers (Nginx, which proxies the request to the desired backend). And all we had to do was make sure that the configuration on the dispatchers was identical and configure them to choose the backend by user ID (for example, through the hash directive).
The resulting scheme is not without flaws, but in the end it allowed us to serve more users and withstand about 300 thousand simultaneous connections to 8 web sites.
Alerts 3.0: New Hope
Federation, be smart enough!
The Federation is convenient because it creates everything itself, but its goal is also to minimize traffic between nodes. Therefore, it creates connections for its queues on upstream only with the keys that are on the exchanger under its control. And in our case, it turned out that the keys were the number of users who visited this or that web site. During the day, they could run up to 50 thousand. And when a collapse happened on one of the nodes or it was simply overloaded, its users could “inherit” on other nodes.
It would seem, what is wrong with that? But there are 2 points:
- There were a very large number of links on the upstream nodes (on cluster nodes), equal to the total number of active users — for any sent message, it was necessary to first search for interested queues of web sites. With the growth of users, this could not affect the performance.
- And the cherry on the cake - synchronization. After the website returned from reboot or restored the lost connection to an upstream, the Federation plugin started the synchronization process, which usually lasted several minutes. During this time, processor utilization on cluster nodes was high and caused delays in the delivery of messages.
As a replacement, we decided to look at another similar plugin - Shovel. His goal is to transfer data from one node to another without unnecessary problems (or between the queues of one node).
When replacing, we saw the expected increase in network load, but the cost of the processor and the reduction of delays were worth it. As a result, when switching to a working system, we noticed a sharp “weight loss” of cluster nodes for a couple of gigabytes of memory, and reloading the web site did not create any additional load.
A large number of connections between the layers
In addition to the growth in the number of users and services, there has also been an increase in the number of websites that should have been served by our alert system. If at the beginning there were 3 of them, then this number increased to 10, and no one was going to stop. As can be understood from the last picture of the structure of objects, in the current implementation the number of connections depends on the number of sites served, and even by a factor of 3 (the number of publishing areas). Moreover, the Shovel plugin does not work through policies (as Federation can do), and we need to create all the connections manually after creating each publishing area exchanger (the same script that runs when the user connects). And can we get rid of this dependence and use one connection for all sites? - Need to!
Immediately remembered another type of exchanger "out of the box" - headers. What he is not an assistant? The principle of its operation is such that when creating a connection to it, a certain set of parameters and their values are specified, which are also specified in the message headers, and if they match, the connection is triggered. In our case, there were two such parameters: the site name and the publish area. For example, site = "online.sbis.ru" and scope = "user" . This pair was set for communication and for the message. The only thing that stopped was the postscript in the documentation, that the speed of such an exchanger is small compared to others. But we had few links with him, and the number of messages is not that big. Tests have shown that he quite cheerfully copes with the load. We decided to go for it.
This was the first failure of this magnitude, since the tests were insufficient in duration. The behavior of the exchanger was very strange, the first few hours everything worked well, and then the processing speed slowly decreased to zero, although the number of links did not change. I had to quickly write an external script that performed the work of this exchanger. Pechalka.
Or maybe your exchanger?
In the course of solving various problems with RabbitMQ often encountered the language of Erlang - it's time to study it better. As it turned out, implementing your exchanger for RabbitMQ is not that difficult. And from that moment on we began a new era of working with this broker.
After studying the code of standard exchangers ( fanout , direct ), it became clear that the list of resources that need to send a copy of the message is waiting for the route RabbitMQ function. Standard exchangers extract this list of resources from the internal database of links. But in our case, the names of the following exchangers are generally calculated based on the incoming message.
route(#exchange{name = #resource{virtual_host = VHost}}, #delivery{message = #basic_message{content = Content}}) -> Headers = (Content#content.properties)#'P_basic'.headers, Scope = case rabbit_misc:table_lookup(Headers, <<"scope">>) of {longstr, Scope} -> Scope; _ -> <<"user">> end, Sites = case rabbit_misc:table_lookup(Headers, <<"sites">>) of {array, Sites} -> [ Site || {longstr, Site} <- Sites ]; _ -> [] end, [ rabbit_misc:r(VHost, exchange, <<Site/binary, ".", Scope/binary>>) || Site <- Sites ]. Now we need to arrange everything as a plug-in for RabbitMQ , which is also quite simple (then there was a version of RabbitMQ 3.5, and it was a bit more complicated). As a result, everything took off and even worked faster than fanout due to the lack of samples in the database. Crunchy! By the way, the type of exchanger called sbis-ep (entry point).
Problems with large messages
At one point, the web sites began to "die like flies" due to lack of memory. With the help of the rabbitmq_tracing plugin, it was possible to understand that good people arranged some kind of CDN from the alert system and sent 20 MB of data in one message. But their switching off of joy did not add - the falls continued (although with a lesser frequency). The biggest messages remained at 400 Kb. For a simple event, this is also quite a lot, but the system should not die of such. The first night of acquaintance with the debugging tools for Erlang was productive, and by the morning they were rolling out healing patches. It turned out that SockJS used the xmerl_ucs module to work with UTF8, which converted the entire binary into lists and worked with them. As a result, this led to the fact that the 400-kilobyte message during the processing ate more than 16 MB of memory. And such messages were sent to several users at once. In the patch, working with UTF8 was completely redone using only binary strings, after which there were no drops. You could go to sleep.
Note missing
There was another unpleasant problem due to the fact that in RabbitMQ there is no Expire parameter for exchangers (only for queues). When the user came, everything was created for him, but when he left, the resources were not deleted. For preventive purposes, we had to periodically overload websites. The first experience of your own exchanger left a wave of positive - can another one with TTL support do this? Wow! But what if it is a personal exchanger of the user (he is fanout so far), and during his creation he will also create all the other objects on which he depends? This is already quite grown-up! Let's call the exchanger sbis-user .
The names of the parent exchangers and linking parameters depend on the user and client identifiers, as well as on behalf of the site on which the user works. We can transfer them through the parameters (arguments) of the new exchanger when it is created. Well, add the ability to control the lifetime of the orphan exchanger, too, through the parameter.
Create exchangers and connections - you don’t need much work: just call the already existing RabbitMQ functions and there will be happiness. But for the organization of the mechanism of TTL still need to work. The fact is that the exchangers do not have their own Erlang process, where we could periodically check the number of current users and remove ourselves. Therefore, in addition to the implementation of the exchanger module, we also need our own process, which would follow everyone. To do this, you need to create an Erlang-application (application) - it will run with the start of our new broker plugin and, in fact, contain one workflow.
The process of removing orphan exchangers could be naively implemented: periodically we receive a list of all exchangers; for each of them we get the number of links; if they are not there, then we add them to the list for deletion and delete them at the required interval. But this approach creates a large load, especially if we have tens or hundreds of thousands of exchangers. The API for exchangers has functions that the broker calls when creating or deleting links. They are just what will help us make the best decision. At the time of creating a new link, we always remove the exchanger from the list of orphans, and at the time of deleting the link, we put it there, if there are no other links.
The last question: what structure do we need to use in order to be able to check the existence of the exchanger in the list, remove it from there, and also look for already expired exchangers at the lowest cost? After several tests, we stopped at a combination of two standard structures:
- gb_tree , is good for finding the minimum value (the exchanger with the shortest expiration date, which is compared with the current time), as the key structure {ExpireTime, Exchange} , and the value is 0 (not used).
- map (already worked on Erlang / OTP 18), as an Exchange key, and as an ExpireTime value, used to check for existence and search for time (for deletion from the first structure).
In addition, the number of simultaneously deleted exchangers was limited so as not to create peak loads. Everything, our second plugin is ready to work for the benefit of users.
Is hope justified?
Certainly yes. We get an even simpler, more beautiful and reliable structure:
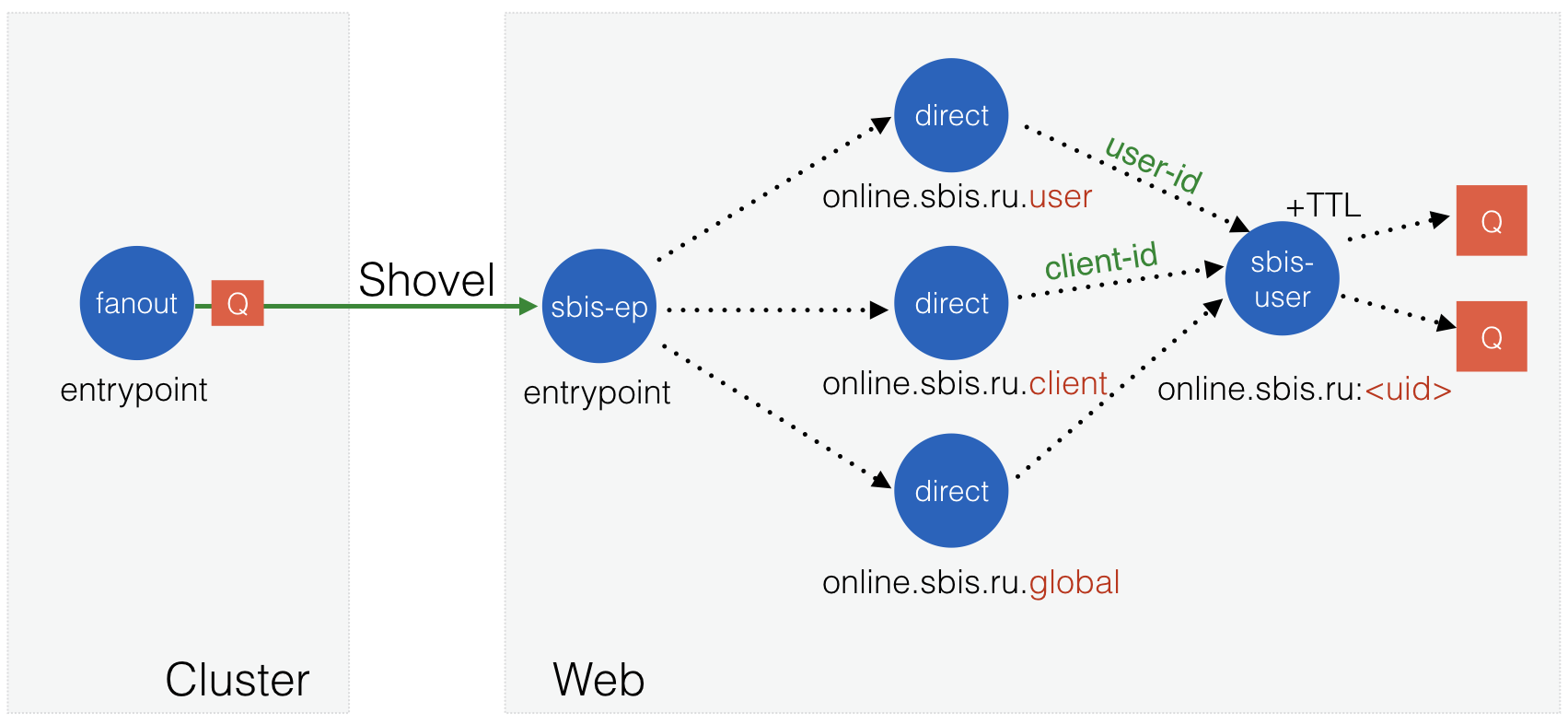
Fig. 11. The structure of objects in the scheme with its own exchangers sbis-ep and sbis-user .
On cluster nodes we have only one exchanger with fanout type, only one connection between the web site and the cluster, the scheme does not depend on the number of sites, and after the user’s absence on the site, the resources allocated to him are cleared. Just a fairy tale, what else can you dream? In this form, the system served us up to 600 thousand simultaneous connections on already 15 web-sites, there were peaks of 300 thousand outgoing messages per second. But that was not her limit.
X alerts: Infinity and beyond
It is time for new adventures, since the growth of users was not going to stop.
All inside
Already almost all service operations are working inside RabbitMQ (which gives us minimal delays). The only thing left outside is the creation of a personal user exchanger. But after all nothing prevents us and it to realize as a plug-in for RabbitMQ, truth? So it is, we can use the already working Cowboy web server and initiate the creation of exchangers from our next new plugin.
Since the browser version of SockJS from the request for / info only requires the websocket flag, and the server side in general can do without this request, we can not just intercept this request, but also fully process it. That is, the request for this resource goes to our plugin, and all other requests continue to go only to the RabbitMQ Web STOMP adapter.
64K ports will be enough for everyone
One of the problems that caused a large number of web sites to be raised was the limit on the number of open connections between Nginx and RabbitMQ on one host. Nginx could not specify the outgoing connection address, and on the side of the Web STOMP plug-in it was impossible to specify several ports. In addition, it was necessary to see how many users we now live on web sockets, and how many - on XHR-poling and streaming. Nginx we could not tell this, and had to fence not very good things.
Then HAProxy came to the rescue, which allowed us to:
- Send requests to the correct port depending on the URL (like Nginx);
- Create a large number of connections to one port (the source option allows you to specify the outgoing address, and we have a lot of them locally, 127.0.0.0/8);
- Limit the maximum number of connections to protect the service from massive influx of requests and make it more stable;
- Receive a lot of statistics about the service (the number of current connections for a particular transport, the speed of new arrivals, response time, response codes, the time to wait for a request in the queue, and others);
- Save resources. HAProxy consumed 3 times less memory on the same number of connections, and the processor load was 3-5%.
Cache and compress it!
RabbitMQ comes with a convenient web management console - Management plugin. It allows service personnel to quickly assess what is happening in the broker. Also through its API, we collect statistics on the work of the broker. The problem is that it does not have any caching mechanisms, and it collects all the information with each request. In RabbitMQ 3.5, there is no pagination output, and a full list of resources is always given. And by default, auto-update is enabled after 5 seconds. It turns out that with 40 thousand queues all information on them can be collected for 10 seconds, eating a lot of CPU time, and weigh 15-20 MB each (load on the network). That is, by default, the user will make requests constantly. And if there are several users? Scary to remember.
Before switching to HAProxy, we could make a cache on Nginx, but now we decided to try Varnish, since we have a bit of data and caching in memory more efficiently. Enabled caching ( beresp.ttl ) of all content for 15 seconds (for statics a few days) and validity of the cache ( beresp.grace ) for the same amount, as well as data compression ( beresp.do_gzip ).
As a result, received :
- The request to the resource is performed once and no more than 4 times per minute;
- Compressed data weigh almost 50 times less than the original (270 KB against 13 MB);
- The data was given in a matter of milliseconds (it seems that Varnish gives overdue data, if the grace interval is not exceeded, and in the background makes a request to the backend for updating them - it looks great);
- The load on the broker does not depend on the number of users and is computable.
Light my mirror, say
After we optimized web-sites and learned how to scale them well, problems began to emerge already on the lower layer, on cluster nodes. Tens and hundreds of thousands of outgoing messages per second were mainly due to publications in the client area. For example, in our company there may be 5,000 people online. If someone sends 60 messages per second to the entire company, then we will eventually have 60x5000 = 300 thousand / sec. For cluster nodes, the first factor is important - the number of messages published by backends in RabbitMQ. And at some point it also began to grow. It turned out that two sites with full replication (mirroring), serving 18 websites, could process no more than 2000 publications per second, and there was no longer any possibility to adequately scale. The number of backends also increased, and the number of connections from them exceeded 2500. The circuit required changes.
Since RabbitMQ showed itself to be quite stable, and for the warning system it was not required “many nines after the comma”, we decided to abandon the cluster. Moreover, the backends already knew how to work with the list of nodes and repeat the request to another node if one of them failed. It remains to teach web sites to connect immediately to all existing downstream brokers, which is not a problem at all. The new type of nodes was given the name route (in the future, routing mechanisms will also be assigned to it), and after switching to it, the scheme began to look like this:

Fig. 12. Two-layer scheme with non-cluster nodes.
Now we can scale both layers as needed. The variant with two route nodes of the same configuration as cluster nodes already processed about 13 thousand publications per second, but this is not the limit for them!
You have one new message in the chat
With the development and popularization of chat rooms in our cloud-based application, another problem arose: the mass sending of identical messages to a list of users. If there are a dozen people in the chat, then everything happens fairly quickly. But with several hundred users, posting messages in RabbitMQ could take seconds (and also create a lot of work). We needed a mechanism that would effectively send the message to the list of recipients.
It immediately became clear that we can transmit this list through the AMQP message headers (as we transmit the list of sites). The problem was the task of processing it on the Web-sites. The first solution used the fact that the names of the user's personal exchangers (sbis-user) consist precisely of the site name and user ID, and we can modify our sbis-ep exchanger to handle such cases. That is, a message comes with a list of sites and users, the code of the exchanger multiplies these lists and gives the result to RabbitMQ, which searches for its own database and sends it to them by copy of the message. The option was simple and quick to implement, but it had several disadvantages:
- Works with only one publication area (user);
- It creates a very redundant list, since one website served only about 5% of all users. In addition, they could only live on one site, for example, out of three on the list.
Despite all the shortcomings, the solution was sent to work sites and reduced the workload when communicating in large chat rooms. The only thing that was added - an artificial restriction on the length of the list of users in 50 units. Otherwise, a large load multiplier could turn out when the backend published a message within a couple of milliseconds, and all the web sites then worked for a few seconds (with great force comes great responsibility, but not all developers know and remember the second).
We will do all the same
Now, when the degree of the last problem is slightly reduced, it is possible to implement the mechanisms in an adequate way. It would be more correct to have a base of existing users and search by it, instead of generating a large list. RabbitMQ already has a table in the Mnesia embedded database with a list of all exchangers. Unfortunately, it is not organized in the best way for our search, so you have to make your own. The new table will be of type set and will contain the exchanger as the primary key, followed by all other identifiers needed for the search (which list can be expanded if necessary).
When processing messages, we now build a QLC- request containing the necessary lists of values, and give it to the base for execution. The result will be a list of existing exchangers that meet all criteria. Everything works correctly, but we immediately met a drop in performance, although we expected to see an acceleration. We must somehow correct the situation.
When we do a search on the primary key, it is performed almost instantly, and to search on other columns of the table we have to go through all its records. But there are secondary indices in Mnesia - let's turn them on and enjoy the speed! And we are waiting for another disappointment, nothing has changed. Search with 50 users and 3 sites fulfills for 30 milliseconds. The problem here is that we are looking for two fields at once (the identifier and the site), and the indices do not help much (since the source data is only about 10 MB). The fact that for the internal database there are no restrictions on data types comes to the rescue, and we can insert the tuple {Site, Ident} as the field value. Then the search will take place only in one field. Now the secondary index is working at full strength, but it got worse, 60 milliseconds, how so? The fact is that we had to expand two lists into one big one, and the search query became huge.
Well, let's go on the other side. Mnesia has the function of searching for the value of the index, which should work for the minimum time, but it works for one value, so you need to add a loop. In addition, we’ll go all out and use the dirty operations in Mnesia to increase performance.
user_find_in_index(Sites, Ids, IndexPos) -> [ element(2, Item) || Site <- Sites, Id <- Ids, Item <- mnesia:dirty_index_read(user_route, {Site, Id}, IndexPos) ]. Each index search takes about 6 microseconds, that is, with the same list sizes, we get an answer in less than 1 millisecond (with smaller sizes, the gain is even greater). This result already suits us.
Latest field reports
After all changes we get the following structure of objects:
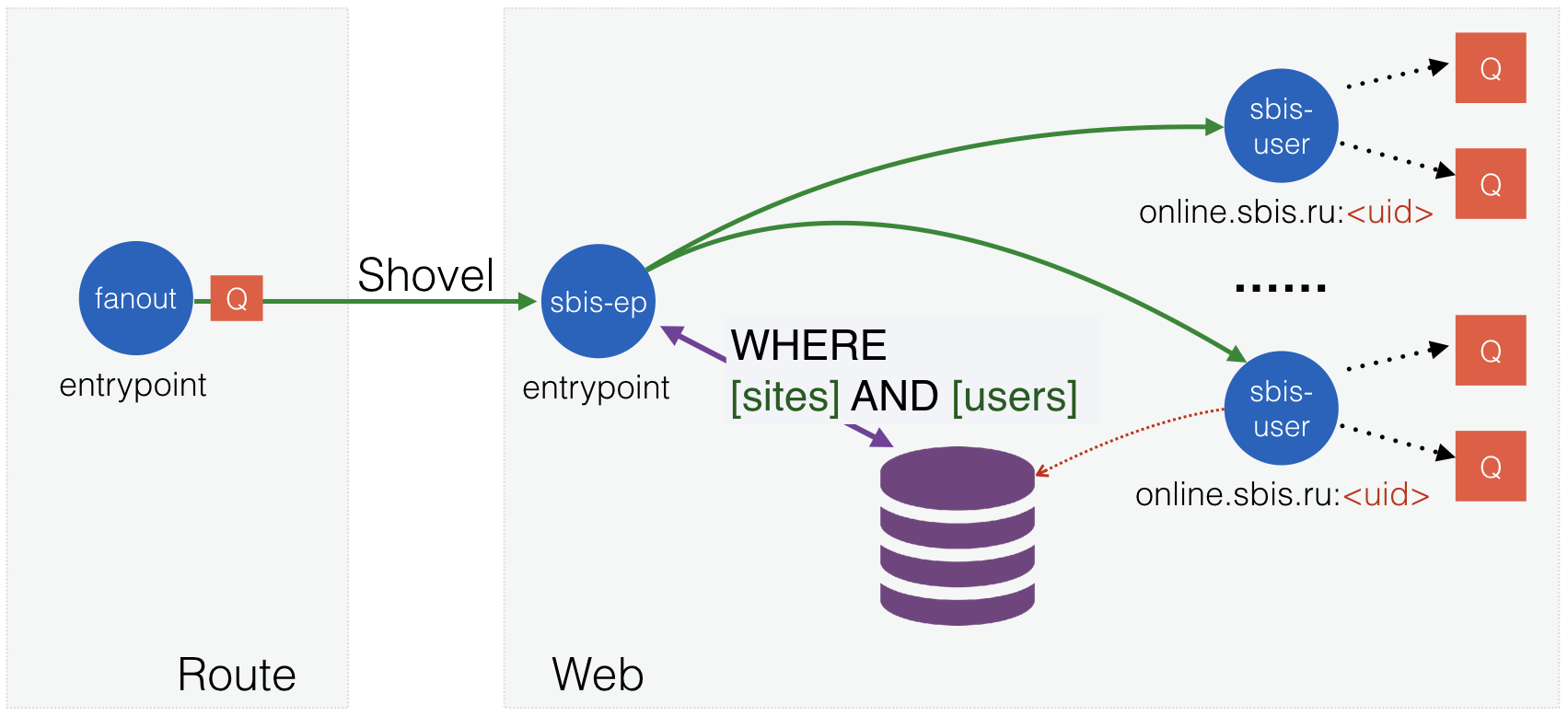
Fig. 13. The final structure of objects.
The last scheme of connecting nodes and the structure of objects in the broker allowed us to serve
1 million simultaneous web sockets on 21 web sites (there were 1.1 million, but the aggregation of history in the monitoring did not leave a trace from this figure):
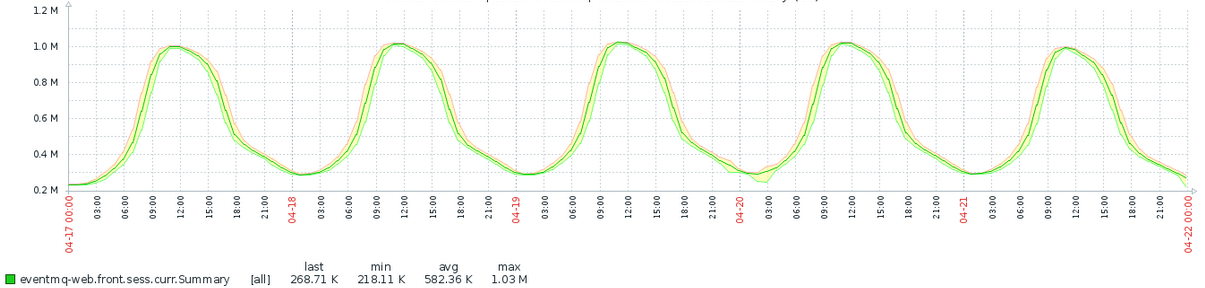
Fig. 14. Total number of connections per work week.
And also contributed to sending almost 1.3 million messages per second to users with a total traffic of more than 4.2 gigabits / sec:

Fig. 15. Processing peak loads: the number of messages and megabytes of traffic per second.
Conclusion
At the time of the start of building the system for notifying users using RabbitMQ, we could not imagine how large the system would be in the end, and how many messages could be processed. Let RabbitMQ be capricious from time to time, but allowed us to implement everything with little development costs (especially when we mastered Kung-Fu in writing plug-ins) and reduce implementation time.
We are happy to share our experience with the community and will be happy to answer all questions.
The author of the article is Sergey Yarkin
')
Source: https://habr.com/ru/post/341068/
All Articles