What is Spring Cloud and how to cook it - an interview with Evgeny Borisov and Kirill Tolkachev
You need to develop using microservice architecture. Everyone advises Spring Cloud, but why? Is it enough run-in? How does it work inside, what logic guided the developers, how convenient is it to use all this?
These and other questions were answered in an interview with the editorial staff of the JUG.ru Group by speakers for the Joker 2017 conference - Yevgeny Borisov and Kirill Tolkachev.
 Evgeny Borisov works at Naya Technologies. He has been developing in Java since 2001, and has participated in a large number of enterprise projects. Having gone from a simple programmer to an architect and tired of the routine, he became a free artist. Today, Zhenya writes and conducts courses, seminars and workshops for various audiences: live courses on J2EE for officers of the Israeli army, Spring - on WebEx for Romanians, Hibernate through GoToMeeting for Canadians, Troubleshooting and Design Patterns for Ukrainians.
Evgeny Borisov works at Naya Technologies. He has been developing in Java since 2001, and has participated in a large number of enterprise projects. Having gone from a simple programmer to an architect and tired of the routine, he became a free artist. Today, Zhenya writes and conducts courses, seminars and workshops for various audiences: live courses on J2EE for officers of the Israeli army, Spring - on WebEx for Romanians, Hibernate through GoToMeeting for Canadians, Troubleshooting and Design Patterns for Ukrainians. Kirill Tolkachev works at Alpha Laboratory. He develops various banking APIs. Forms principles and toolkits for working with microservice architecture. A big fan of Groovy, Gradle, Spring, and the Netflix technology stack. Permanent resident of the podcast "Debriefing". DevOps methodology knows firsthand and has almost two years of experience in its application.
Kirill Tolkachev works at Alpha Laboratory. He develops various banking APIs. Forms principles and toolkits for working with microservice architecture. A big fan of Groovy, Gradle, Spring, and the Netflix technology stack. Permanent resident of the podcast "Debriefing". DevOps methodology knows firsthand and has almost two years of experience in its application.
- Spring Cloud is a pretty new thing, can you tell us what it is intended for? As I understand it, this is add. architecture, which makes it easier to deploy microservices in the clouds.
Eugene : Yes, indeed. Spring Cloud is a new thing. About two years ago he had just begun to come into use, but he was already spreading very quickly. What is it for? Spring Cloud is a module Spring, in which there is a lot of everything different for the development of microservice architecture. There are pieces of infrastructure and other useful buns. One of the main things that is there is Service Discovery. One of the urgent tasks existing in the world of microservices is to maximally automate the mechanism by which each other finds microservices that do not know where each other is. They know that, in principle, there are some other microservices to which you can access and receive something from them, but they do not know where to turn, because today we are launching it on one cluster, tomorrow - on another, the day after tomorrow This is run on Amazon, then somewhere else. An example of a module entering the world of Spring Cloud is Service Discovery, through which all microservices can learn about each other's whereabouts.
That is, there are some names that they know about and can find out real urls. For example, one microservice knows everything about users of the system, and the other - all about serials. You turn to the first microservice and ask if there is a user with such an id, will he like the Game of Thrones? Accordingly, the first microservice, which is responsible for users, climbs into its database, pulls information specifically about this user, looks at what tastes he has, and now he will need to clarify information about the “Game of Thrones”, compare and understand, it fits or not. Accordingly, he should go to another microservice. He knows that there is a microservice called the Game of Thrones, but he doesn’t know exactly where he is. Our microservice, with the help of Service Discovery, says: "Please give me the URL where I can refer to the microservice I need." And after that, he can contact him by REST after he receives this URL. This is if quite in a nutshell. By the way, the Spring Cloud module does not imply mandatory work in the cloud. He serves as an assistant for the developers of microservice architecture in his project. And the fact that, more often than not, the entire system built is launched exactly in the cloud, and gave birth to the name Spring Cloud. But in fact, there is no problem to have the entire cluster of microservices on the same local machine. From this the meaning does not change. After all, microservice does not know where it will start.
You can have a local system in a local grid, or even on the same machine. You raised 10 different microservices that sometimes want to contact each other. They do not know on which IP or URL each microservice sits, because this can always change. We will talk a bit later that each microservice can have many copies for a performance. Leave it for a second. Suppose there is one copy for each individual microservice, but still - it's wrong - to hardcode, write the URL in some property-file so that they can access each other via RestTemplate or something else, because tomorrow you will take your microservice system from the test environment and transfer it to the program: there you have other URLs, other IPs - and nothing works there. You did it all again, set it up, spent a lot of time, it worked for you in production. Then you gave it to another client, or you picked it up at Amazon, again everything else — other ports, URLs, and again nothing works. And Service Discovery in Spring Cloud provides this out of the box. Everything is very simple: you inject a certain service to which everyone is registered, and through it you can say “give me the microservice URL, which is called like this”. And that's all. This is done very simply: the Spring Cloud annotation is placed on each microservice in the main Main in the main configuration, which says that I want to register, and then it rises, he finds one single central service that everyone should know, says: “My name is this, this is my URL, this is my IP, I'm sitting right here.” And there is one who knows everything about everyone. Periodically, he pings them to know who is now available. On the other hand, everyone can inject himself a certain service, which can then be asked who is registered under such a name, what is his URL, and when you already have this data, you can access these microservices by REST. This is exactly the chip that I personally used in Spring Cloud. As you can see, this is not necessarily related to the cloud. This is simply called “Spring Cloud”, but it represents all sorts of different things. I told about the Discovery service, Cyril can add something else or correct me.
Kirill : Spring Cloud is a whole set of modules that lives by its own laws and sometimes even “breaks through” Spring Boot mechanisms.
Eugene : As I said, Spring Cloud provides a whole set of tools related to the world of clouds, microservices, etc.
Kirill : Spring Cloud itself, as the developers themselves call it, is the Release Train , which contains a set of dependencies / modules whose versions are consistent with each other and are designed for a specific version of the Spring Boot. You have already said about one of the modules - this is Spring Cloud Discovery. Service Discovery is usually useless separately from Load Balancer, and in Spring Cloud for this there is a Spring Cloud Netflix - a project with Discovery implementation for Eureka Server and client balancer Ribbon and Feign. Spring Cloud Starter Ribbon - integration of the client balancer Ribbon into the familiar Spring MVC stack (RestTemplate) and its bundle with Service Discovery. Spring Cloud Starter OpenFeign is a declarative client for making clients in RPC style for convenient communication of services via HTTP. Of course, it has integration with the previously mentioned solutions (Ribbon / Discovery).
As Zhenya said, to use the Spring Cloud “cloud” (oh God, yes, everything is understood by this word) you don’t need. My urge is simple: Why do you share your solution into different services? If there is an opportunity not to divide and work with one calmly, then it is better to do so, because it is easier. As soon as you divided the "monolith" into a handful of "microservices" - you got a complex distributed system, instead of the predictable and understandable monolithic. You have problems that you haven’t even thought about before, and some problems have surfaced at the infrastructure level. We have to manipulate a completely different list of errors, and this despite the fact that the old ones have not gone away.
But is everything so bad? Indeed, some of the difficulties are borne by Spring Cloud (for example, implementation of balancing and client detection). So, a whole pack of new calls are introduced by quite ordinary, from the development point of view, things. We have to look at typical things from the angle of the functioning of the system as a whole (and I remind you, in the case of a monolithic application, this was just super). For example, it is no longer enough to write an error message to the log, you need to take care of the transparency of its location by adding meta information to it for end-to-end search for calls involved in an erroneous request. To do this, there are solutions like Spring Cloud Sleuth, which add various meta-information to the logs, allow you to receive pass-through logs for errors, sample requests and send them to the Zipkin-server. Using the Zipkin interface, it is already convenient to search for “top slowest queries”, calculate “dirty ducklings” - specific inhibiting services, quickly assess the situation and localize the problem.
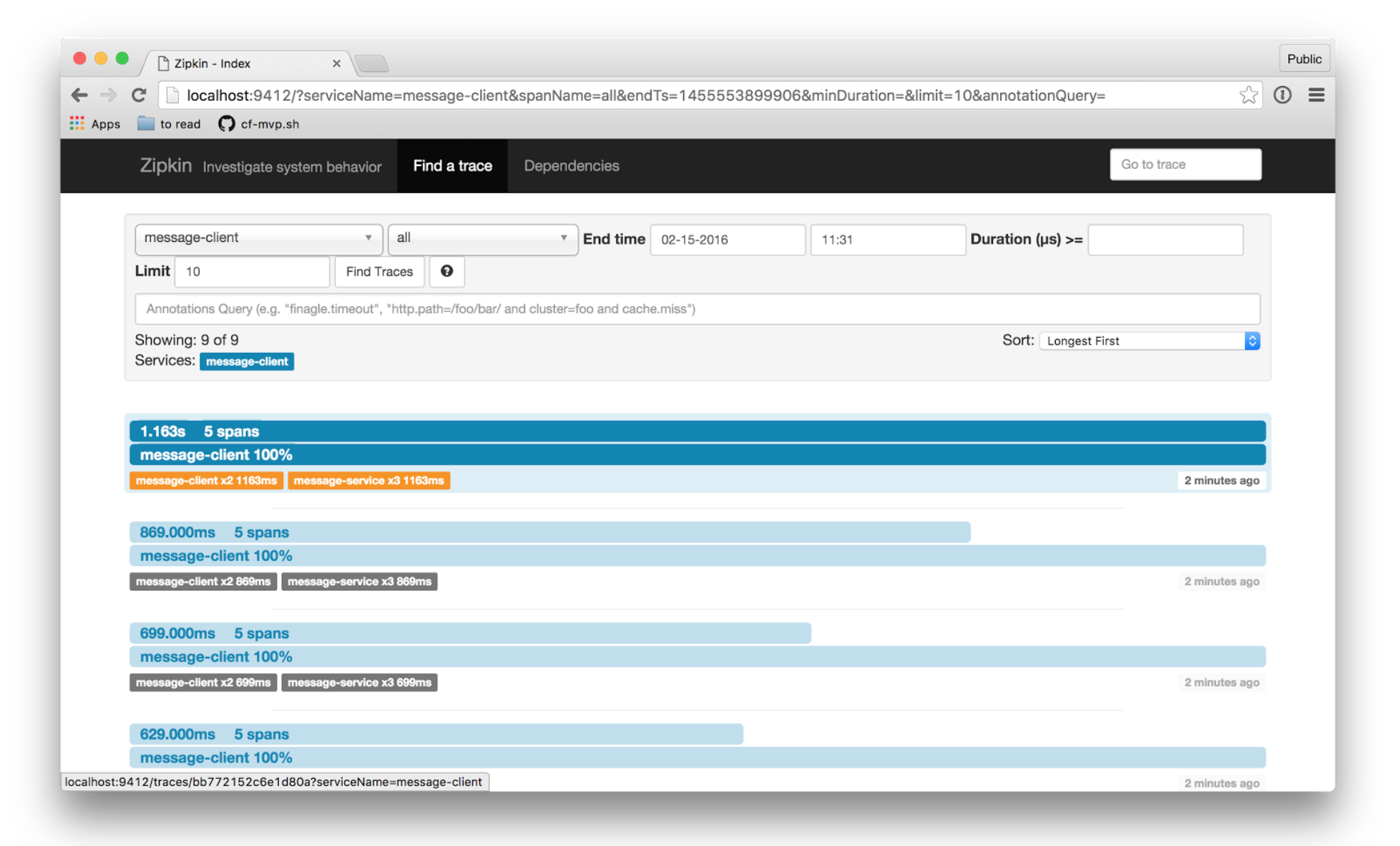
And like so much in distributed systems, all of the above is just the tip of the iceberg. The huge variability of the stack makes it necessary to continuously choose approaches, to make decisions. For example, the same Zipkin can receive samples (information about the internal processes of the application - mostly different measurements of time) to form TOP N slow requests, through queues or via HTTP API. Monitored applications are also configured to reset information either to a queue (kafka / rabbitmq) or to the Zipkin HTTP API.
The “sample” request itself, consisting essentially of response times of different systems that participated in a request, can also be stored differently after receiving:
- In-memory
- assandra
Each decision is acceptable in different conditions, and it is good if your conditions coincided with the existing solution, otherwise you have to make your own.
The queue can also be different, in Spring Cloud there is support for Kafka and RabbitMQ.
And the choice of any decision is a huge responsibility, because the “cooler” and more difficult, the more then someone will have to maintain, update and develop. So think about it, when instead of ConcurrentLinkedQueue in your neat and monolithic application you want to make microservices and Kafka.
To work with Kafka / RabbitMQ and create message-driven microservices, Spring Cloud also has a module - Spring Cloud Stream (based on other Spring Boot modules).
Because of such an abundance of possibilities, the quality of final solutions often suffers. Not everything fits well when you need to use different versions (for example, Kafka 0.9 is not good friends with the new Spring Cloud Stream because of the built-in version of the driver for 0.11). This is partially leveled by the “finished stack”. That is, we take the Release Train Spring Cloud Dalston.SR4 + Kafka 0.11 + ..., we act according to the documentation, do not step aside - it works. But the rake is still enough, although this is a completely different story.
- How is Spring Cloud integrated into the Spring / Spring Boot infrastructure? How easy is it to move all this if you're already sitting tight on a boot?
Cyril : As I said before - if there is an opportunity not to move, do not move. Spring Cloud is a subset of various modules already, rather, over Spring Boot, because the abstraction of a slightly different level, it affects the infrastructure level even more. It turns out that in Spring it is a framework level, various MVC / JPA / Data / ES modules and so on. Spring Boot is already a link between the infrastructure and libraries, where different modules stick together, start to be friends with your infrastructure (embedded Tomcat / settings / env property sources / etc), and all this can start in ecstasy as a systemd service on Linux -server literally with half a pint. Spring Cloud is already a glue between different services that run separately: for example, two Spring Boot applications that integrate with each other. Everything is based on this and built.
At the same time, Spring Cloud X may not be a simple library, such as Spring Cloud Eureka Server and Spring Cloud Config Server, which in essence can be full-fledged Spring Boot applications that implement Discovery Server and Configuration Server functionality ( Config Server).
- Why is all this done? What is the idea of microservices?
Eugene : The idea of microservices is that we write small pieces of an application that talk to each other, instead of writing one huge monolith. Accordingly, the question arises - how will they talk to each other? You can register a bundle between them with a hardcode, but then this, by and large, is not so very different from a monolithic application, which simply consists of many different modules, in which “everything is nailed”. We want a more flexible connection between them. And this is even before we talk about sharding inside each microservice. At some point we want a performance, and we have a Load Balancer.
Then we say that this microservice cannot cope because so many people turn to it. Accordingly, we need five copies of it. All this performance, modern architecture, horizontal sharding.
- What are the benefits of Spring Cloud solutions? Are there any alternatives?
Kirill : This is originally a set of different solutions, stacks of other companies, for example, a lot of things are taken from the Netflix stack. Spring-cloud-netflix is a pretty important part of Spring Cloud.
But at the same time, Spring Cloud does not bind you tightly to the Netflix stack, no, he says, if you want, use Hashicorp's Consul as a Discovery Server, and even offers the implementation, if you want, something else (but there are nuances everywhere, khe).
I think Spring Boot has learned a lot from Dropwizard , now it even has some integrations with it. There is, in my opinion, the Axon framework, which also has various garters in order to make CQRS-services with integration, there is some kind of Discovery. In general, there are frameworks, there is no special reason to call them, because Spring Boot has already sucked in itself more or less popular. The only thing that stands apart is Bootique , which is also a pleasant framework, but not so large-scale, of course. Confesses the concept of a static configuration, as opposed to the approach of Spring. You can even listen to the report with Joker / Jpoint.
- As far as I understand, we already said about the minuses: if you can not do microservices, then it is better not to do them.
Kirill : It is really difficult. Microservices are a complication, a complication of both the business application infrastructure itself, and the complication of support systems (monitoring / logging). They need to be done only if there are powerful arguments that outweigh all the disadvantages.
As a rule, these arguments are about scaling, high loads, less often about “process scaling” for the segregation of technologies / teams. When you have a lot of teams, and you need to isolate these teams somehow from each other, think up the format of their communication. If you want to take a closer look at what Evgeny was talking about (and about the hardcode, and about the various patterns presented by Spring Cloud) - on one of the first JUGs, I and Alexander Tarasov spoke with the WILD microSERVICES report. The report has a part with a demo just about what we just talked about, but there is a theoretical part with slides and pictures, in which, in part, we tried to explain how and why we walked this way :)
- I understand correctly that Spring Cloud has no application for monolithic architecture?
Eugene : He gives the tools that help microservices. Everything. Accordingly, the monolithic architecture has nothing to do with it.
“Spring Boot is about“ magic. ” In Spring Cloud there is also “magic”, in Spring there is a lot of “magic” in general. There are such tools that create a lot of high-level infrastructure for the developer. Is this good or bad, in your opinion?
Eugene : This is good, because it allows people to go into production much faster. You do not need to cut your bike, you do not need your infrastructure from scratch, you can take a ready-made platform and start doing your business logic, instead of thinking, and how to technically implement it all. You all give out of the box.
Kirill : At the moment, this is still a rather weighty framework that allows you to make a number of decisions and embed the solution you have received, but I would not call it a box.
Eugene : This is a box in which there is a set of services and ready-made tools that can be used. And it is very convenient. These are standard things that everyone needs. Is it like arguing about whether ORM is good or bad? If you want, run and put into the database, then start to transfer the result from ResultSet to objects and so on, but everyone needs it, so you came up with an ORM so that it all happens the same way for some particular conventions. Conventions give a benefit. It's simple. So it is here. So, in principle, the programming world develops: popular things appear in any direction, a framework appears that transmits a standard set of things out of the box that everyone needs who has climbed into this area.
- Suppose there is a certain company in which everyone works at Spring Cloud or at Spring Boot, and then someone comes along and says: “I don’t want to write to Spring Boot, I will be cutting bikes in Java 7. And I don’t like streams I don't like anything. ” Do such employees usually retrain or kick out? Or are they given to work how they want?
Yevgeny : I simply don’t hire such reactionaries. In my company, I myself recruit workers and very carefully check that they are either ready to learn, or already know about modern technology. And those who know only what was once, and does not want to learn new things - I just do not need these. I just don’t have time to hand over the project with them. Here the price issue. Imagine a man who only knows the assembler. And he says: “I know the assembler very cool, I am not ready to learn Java, because everything can be done on an assembler. Yes, there is a little bit long, but everything, and I completely have control. ” How many people do you need?
Kirill : People come here, everyone does not like different things, this is normal. The main thing is that people have the opportunity to change all this and do something differently, to bring the rest to a bright future. We should not go to us at all if we are not ready to defend our ideas and plod over the transformation of the process for the better. In the end, any solution is some kind of compromise between one, second and third.
- In the announcement of your training, you say that you will start writing a microservice project. "For those who want to understand what problems they will have when switching to the microservice architecture, as promoted by the Spring Cloud, be able to deal with them, and also just be aware of this dynamic stack . " Where do the main problems arise, at what points?
Kirill : Problems, ahem, usually as soon as you start to use a solution on a large scale, to implement it in your infrastructure, in your processes, you immediately come across a huge number of bugs and problems. For example, to simplify the delivery process, we needed to package the applications in the Docker (after that, though, we found a compromise!). Docker partially encapsulates the network from the application. The application, in turn, happily registers on the Discovery Server under the internal Docker address, and pretends that it should be so. Of course, other applications cannot work with this address with it, it is necessary to do various manipulations to determine the correct address, it is even worse when applications are forced to work through reverse proxy. The problem is mainly in those places where there are white spots for the frameworks. They all work well on simple examples or prepared PCF-type PaaS (although there are some nuances here), in more complex conditions, inconsistencies immediately begin, which is logical, because it is impossible to make software for all occasions, more convenient for all commands.
There are many spots that you have to close either on your own, or take the path of least resistance - for example, to have a stack very similar to some Pivotal Cloud Foundry, it is even possible to buy a paid version. There are rough spots in Spring Boot, of course, not everything is always documented. The same Spring Boot is much more popular than the Spring Cloud, and it is clear that people of different levels write it. There are all sorts of govnokod varieties. In Spring Cloud, this is even worse. Many different developments of other companies are integrated there, for example, Netflix, and each such integration has its own legacy, because of which some kind of abstraction and begins to flow (good, the model of "magic annotations" allows developers to breathe though).
- We smoothly approached the following question: I went to the Spring Cloud website today, saw that there were a whole bunch of modules, some connectors, a Netflix module, a Consul module, a module for RabbitMQ with Kafka, a module for Amazon infrastructure and so on. Suppose there is no module for my infrastructure. What should I do: move to a new infrastructure, file my own connector or wait for the vendor of my infrastructure to make a connector for Spring? Ask Spring Cloud about this, write letters?
Kirill : Writing letters is definitely useless. You can make your project with the desired implementation, which you can then easily use, or even integrate your part as the official Spring Boot if there are requests from the community. Becoming a “part” of Spring Cloud is a very likely outcome for popular solutions, but at the same time for unpopular decisions such an alignment is unlikely.
- That is, either try to cut it yourself, or wait for a solution from the vendor, but it is not clear whether it will be or not.
Kirill : Yes, as in everything - either do it yourself or wait. You can wait as long as you want, and it’s not at all the fact that the desired will happen.
Eugene : I agree with Cyril. This question has no definite answer. If you have been drinking something of your own for a long time, and you have a month left to complete the project, you will not say: “And now I’ll leave everything and move to an existing platform.” Or: “But I’ll wait for how long I’m not sure, but what if a solution comes from a vendor”. It is clear that you will continue to make crutches, as you began. And if you have the time and opportunity, and you see that there is a cool alternative, then why not move. It is very dependent on the situation.
- So you still for the move?
Eugene : I think that when you start a new project, it is very important to check what already exists, and it is very important to put on the right horse, because if you go with some dying technology, then at some point you may be In full ass, and you will continue to rivet crutches, suffer, suffer and hate their work. And the whole world will overtake you, and while you finish your project, there will be already 100,500 alternative ones, which, thanks to a better choice of technology, have long overtaken you, although maybe you started first.
- Tell us about monitoring and logging: as I understand it, there may be problems related to the fact that if we have some microservices running, and they exist in some containers, then the monitoring and logging is an obvious problem, which is that these systems all revolve in their cars. For example, the Docker is closed, you need to reach it, and so on. Does Spring Cloud somehow help in general to monitor and log these containers, virtual machines, and so on?
Kirill : As I have already said, one of the difficulties is to have a pass-through identifier by which you can view logs as part of an external request for all services involved in it. Spring Cloud Sleuth helps us add meta information to logged messages.
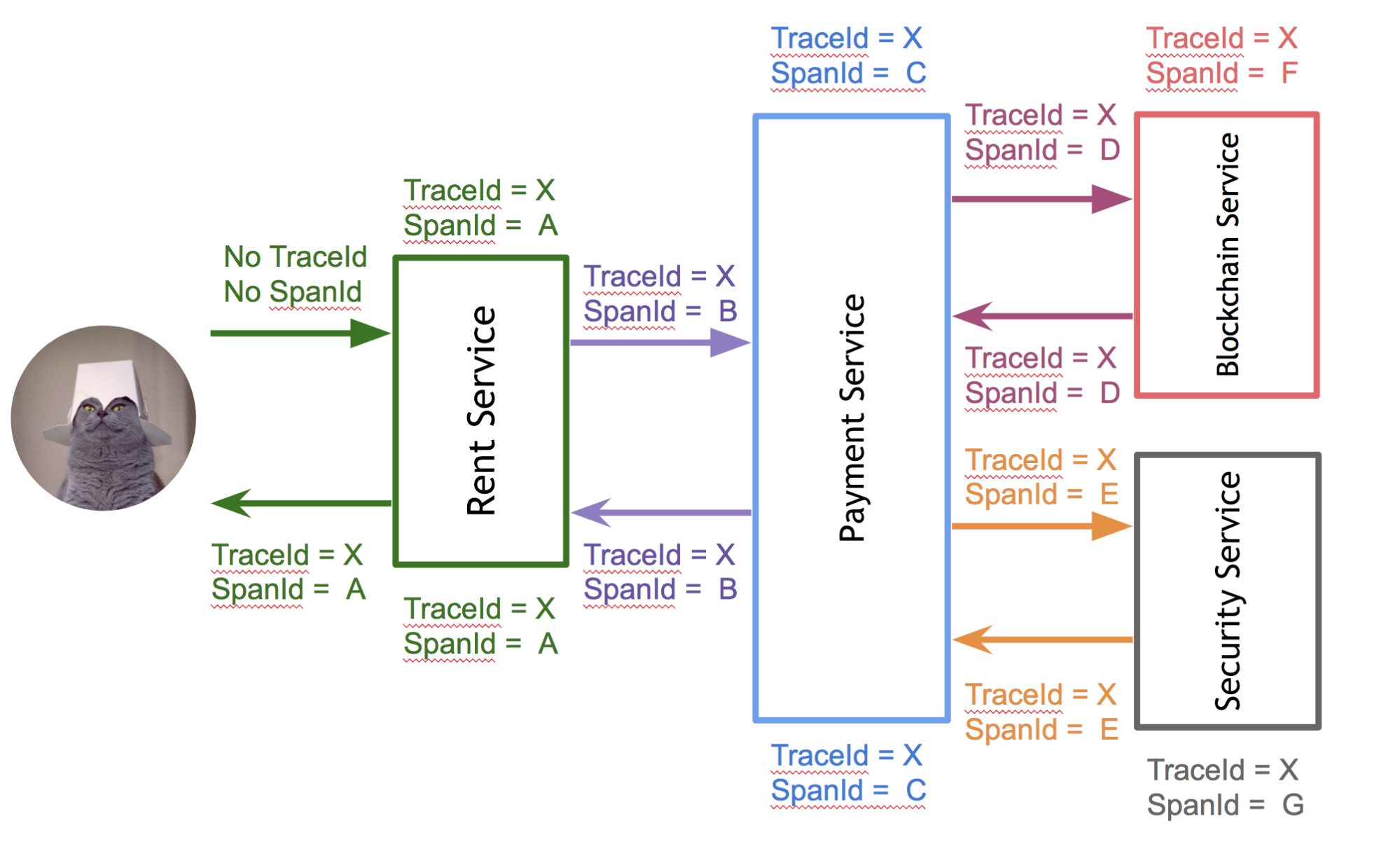
It can act quite toughly, by instrumenting some part of the code responsible for external interaction, adding the necessary meta information (pass-through identifiers, response times, etc.). Also, you can get integration from the box with the OpenZipkin tool, which accumulates various information on sent to him the traces and finds the most problematic requests that last for a long time, fall, retract, and something else like that. And there is already a question about the distribution of this information for large systems: there are options through the queue to provide information to Zipkin, you can write directly, you can store this matter in different sources. There are many variations.
It seems that these tools even solve the problems that have been posed, but, as I said, now it’s rather a white spot in a not very production form. There are many other solutions to help monitor the state of the system, for example, Hystrix dashboard, which displays the performance of individual components in the system. Turbine, which allows you to aggregate various small dashbordiki into one big one, shows the state of the whole system. But, as a rule, there are too many nuances there. Just because it does not deploy and install, it is quite difficult to integrate. It’s not friendly with the same reverse proxy, you need to do authorization of your own, and so on. In general, for a large company, the use of such tools is quite a lot of work.
- Guys, thank you very much!
By the way, if you want to chat with Eugene and Cyril - come to our conference Joker 2017 . They come with the report " Boot yourself, Spring is coming " (this is a big serious report, consisting of two parts, each of which lasts one hour).
If you want a deeper dive, they will hold two special trainings:
These trainings have different goals, programs and key topics, which you can learn more about by clicking on the links. They are held separately, i.e. You can skip the Boot and go only to the Cloud.
Please note that each of them takes the whole day (from 10 to 18 hours). It is advisable to have a laptop with the following software: IntelliJ IDEA, Docker, Docker Compose, Java 8. Trainings will take place November 1-2 , that is, before Joker, so you can look at the reports of Eugene and Cyril through the prism of acquired knowledge and skills.
')
Source: https://habr.com/ru/post/341026/
All Articles