Crawler for crawler

For a number of applications related to monitoring Internet resources and collecting statistics, the task of searching for textual information in the network is relevant. What exactly is this useful for and how?
If interested, then welcome under the cat!
Vivid examples are the tasks of copywriting, search for borrowing, document leaks, in the end. Do you need your own crawler for this or you can use search engines? In the course of resolving this issue, an idea arose to write a “crawler for a crawler,” in other words, collecting data from search engines for a given request.
The first reasonable question: why not use the regular search engine API? If we use only one search engine, then the API is also possible, but for this we will need to monitor its changes and edit our code. We decided to make a universal mechanism: replacing the XPath in the settings, you can tune in to work with any search engines (but not limited to them). Of course, I had to consider working with the list of proxies so that, firstly, they would not be banned, and, secondly, so that they could receive search results for different regions (using the proxy geoIP).
When building the structure of the application, a step was taken towards cross-platform development using the microservice architecture based on docker containers.
')
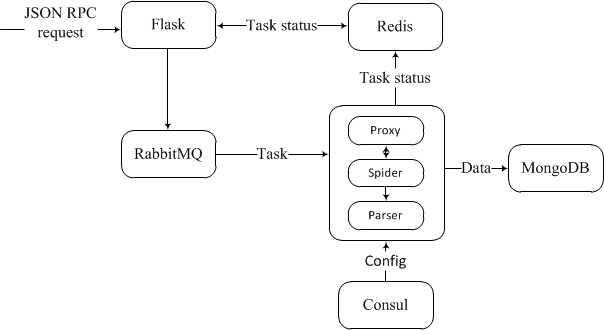
The scheme of the application is extremely simple: the interface of interaction with the system is implemented in flask, at the input of which a JSON-RPC request is expected which has the following form:
requests.post('http://127.0.0.1:5000/social', json={ "jsonrpc":"2.0", 'id':123, 'method':'initialize', 'params':{ 'settings':{ 'searcher':'< >', 'search_q':[ 'why people hate php' ], 'count':1 } } }) Next, the task is initialized in the RabbitMQ queue. When its turn comes, the task processing module takes it into development. During the process, the current proxy is provided, a browser emulator is created.
Why should we use that ill-starred emulation, and not use our favorite requests? The answer is simple:
- to solve problems with dynamically loaded content;
pretend to be a snake(a user with a real browser) to delay proxy blocking.
For this purpose, the selenium webdriver is used , which allows us to get the page in the form in which the user receives it in his browser (with all the scripts and checks that have been worked out), and, if necessary, makes it possible to simulate actions on the page, for example, to get the next piece of data.
Fortunately, in most search engines, the process of obtaining the next page occurs by clicking on a pre-arranged link, and it can be implemented using GET queries, incrementing its number.
As soon as the desired page is received by us, the business remains for the small one and it will be happy to be executed by parser (using the config file that we constructed containing the necessary elements Xpath), which, in turn, will send the information of interest to us to MongoDB.
At each stage of execution, Redis indicates the processing status of a task, based on its id.
Consider possible problems we may encounter:
- Advertisement in the issue - noise data, inflates the database;
- Sites can load content dynamically, for example, when scrolling a page;
- Captcha - well, everything is obvious here.
If the site masks ads among useful content, then firefox webdriver + adblock + selenium comes to the rescue. However, in the case of search engines, advertising is easily detected with the help of XPATH and is removed from the list.
So, captcha is our worst enemy.
Recognizing it is a non-trivial task and requires significant resources for implementation. So we will look for a way around.
And we found it by us! For this we will use a proxy. As it turned out, most of the proxies, which are in the public domain, do not allow us to bypass our opponent (since they have long since become sore and banned), the situation with paid proxies is slightly better, but also not perfect (and still gives us a ray of light in the dark kingdom).
The first thought is to play around with the user-agent. It was experimentally found out that the frequent rotation of the user agent only brought the proxy closer to a premature death (no one canceled the blocking of the proxy by search services). The correct solution for extending the life of a proxy turned out to be the inclusion of a timeout for its use, requests should go with some delay. This, of course, is not a panacea, but better than nothing.
You can also use anti-captcha service, but that's another story ...
As a result, we got the architecture and prototype of the system , which allows to collect data from search and other sources.
Thanks for attention.
Source: https://habr.com/ru/post/340994/
All Articles