Photo storage and upload architecture in Badoo

Artem Denisov ( bo0rsh201 , Badoo )
Badoo is the world's largest dating site. At the moment, we have about 330 million users worldwide. But what is much more important in the context of our conversation today is that we store about 3 petabytes of user photos. Every day, our users upload about 3.5 million new photos, and the reading load is about 80 thousand requests per second . This is quite a lot for our backend, and sometimes there are difficulties with this.

')
I will talk about the design of this system, which stores and gives away pictures as a whole, and will give a look at it from the point of view of the developer. There will be a brief retrospective about how it developed, where I will outline the main milestones, but I will only speak in more detail about the solutions that we are currently using.
Now let's get started.
As I said, this will be a retrospective, and in order to start somewhere with it, let's take the most banal example.

We have a common task, we need to take, store and give photos of users. In this form, the overall task, we can use anything:
- modern cloud storage,
- a boxed solution, which is also a lot now;
- we can populate several machines in our data center and put big hard disks on them and store photos there.
Badoo historically - and now, and then (at the time when it was in its infancy) - lives on our own servers, inside our own DC. Therefore, for us this option was optimal.
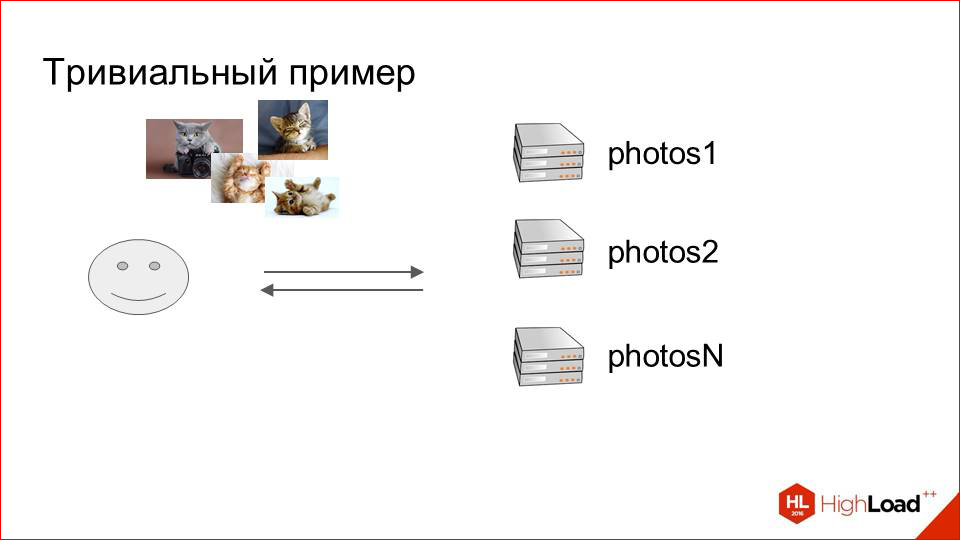
We just took a few cars, called them "photos", we got such a cluster that stores photos. But it seems that something is missing. In order for all this to work, you need to somehow determine which machine we will store which photos. And here, too, do not need to discover America.
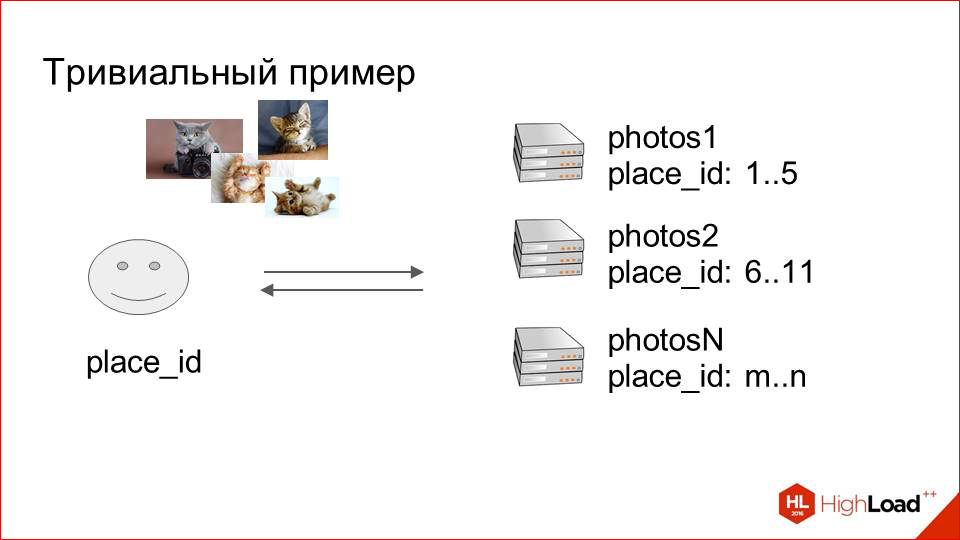
We add some field to our repository with user info. This will be the sharding key. In our case, we called it place_id, and this id of the place indicates the place where the photos of the users are stored. We make maps.
At the first stage, you can even do it with your hands - we say that a photo of this user with such a play will land on such a server. Thanks to this map, we always know when a user uploads a photo, where to save it, and we know where to get it from.
This is an absolutely trivial scheme, but it has quite significant advantages. The first is that it is simple, as I said, and the second is that with this approach we can easily scale horizontally by simply delivering new cars and adding them to the map. Nothing more to do.
So it was for some time with us.
It was somewhere in 2009. Delivered cars, delivered ...
And at some point we began to notice that this scheme has certain disadvantages. What are the disadvantages?
First of all, it is limited capacity. We can not push as many hard drives as we would like on a single physical server. And this over time and with the growth of dataset has become a definite problem.
And the second. This is an atypical configuration of machines, since such machines are difficult to reuse in some other clusters, they are quite specific, i.e. they should be weak in performance, but at the same time with a large hard drive.
It was all for 2009, but, in principle, these requirements are still relevant today. We have a retrospective, so in 2009 everything was bad with this at all.
And the last point is the price.
The price then was very biting, and we needed to look for some alternatives. Those. we needed to somehow better dispose of both the place in the data centers, and directly the physical servers on which all this is located. And our system engineers began a large study, which reviewed a bunch of different options. They also looked at cluster file systems, such as PolyCeph and Luster. There were performance problems and quite heavy maintenance. Refused. We tried to mount the entire dataset on NFS for each wheelbarrow, so that somehow scaled. Reading too badly went, tried different solutions from different vendors.
And in the end we stopped at the fact that we began to use the so-called Storage Area Network.
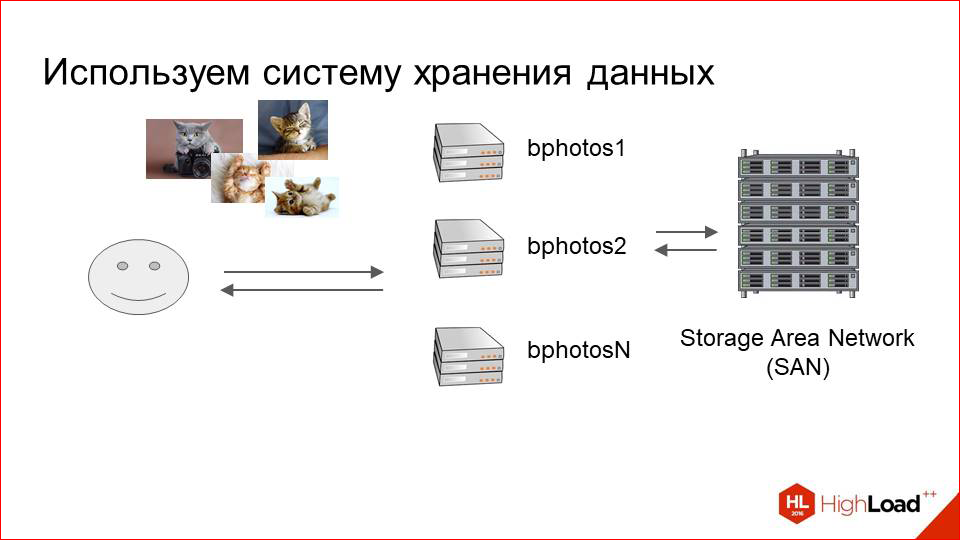
These are such large SHD, which are just focused on storing large amounts of data. They are shelves with discs that are mounted on the final optics returning machines. So we have some kind of a small pool of machines, and these SHDs that are transparent to our rendering logic, i.e. for our nginx or someone else, service requests for these photos.
This solution had obvious advantages. This is SHD. It is focused on storing pictures. It turns out cheaper than we just setup machines with hard disks.
The second plus.
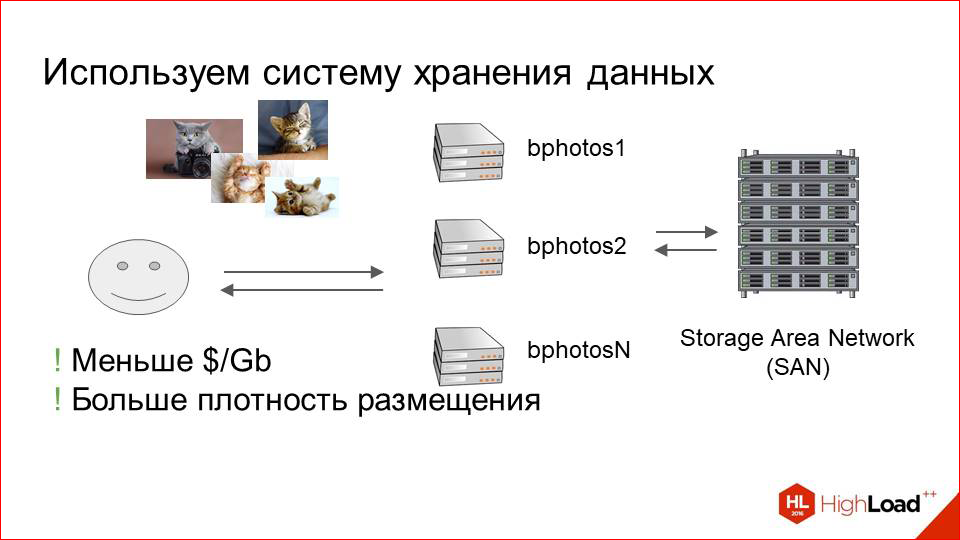
This is what capacity has become much more, i.e. we can accommodate much more storage in a much smaller volume.
But there were also minuses, which showed up quickly enough. With the increase in the number of users and the load on this system, performance problems began to arise. And the problem here is quite obvious - any SHD designed to store a lot of photos in a small volume, as a rule, suffers from intensive reading. This is actually true for any cloud storage, and whatever it is. Now we don’t have an ideal storage, which would be infinitely scalable, we could push anything into it, and it would endure reading very well. Especially random reads.

As is the case with our photos, because photos are requested inconsistently, and this greatly affects their performance.
Even according to today's figures, if we have somewhere more than 500 RPS for the photos on the machine to which storage is connected, problems already begin. And it was bad enough for us, because the number of users is growing, everything should only get worse. It is necessary to optimize it somehow.
In order to optimize, we decided at that time, obviously, to look at the load profile - what, in general, is happening, what needs to be optimized.

And here everything plays into our hands.
I have already said in the first slide: we have 80 thousand requests per second for reading with only 3.5 million apploads per day. That is a difference of three orders. Obviously, it is necessary to optimize the reading and it is almost clear how.
There is another little moment. The specificity of the service is such that a person registers, fills in a photo, then begins to actively watch other people, like them, and is actively shown to other people. Then he finds a pair or does not find a pair, that's how it will turn out, and for some time he stops using the service. At this moment, when he enjoys, his pictures are very hot - they are in demand, they are watched by a lot of people. As soon as he stops doing this, he quickly falls out of such intense shows to other people as they were before, and his pictures are practically not requested.

Those. we have a very small hot dataset. But at the same time there are a lot of requests for it. And an obvious solution here is to add a cache.
Cache with LRU will solve all our problems. What are we doing?
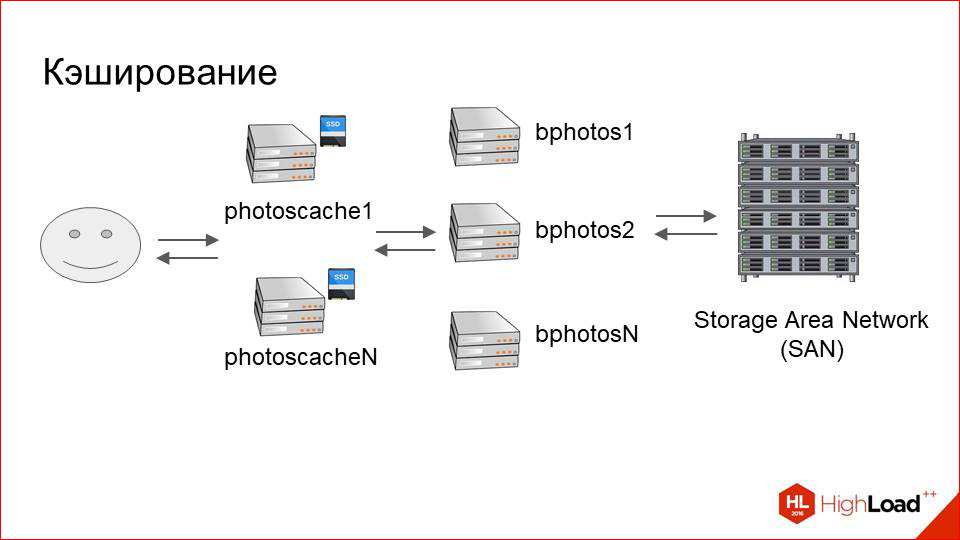
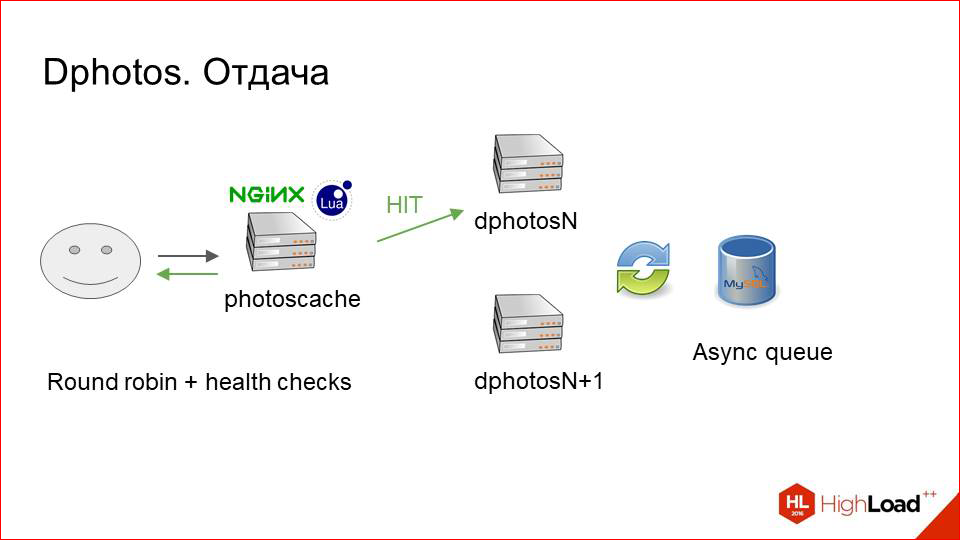
We add in front of our large cluster with storage one more relatively small one, called photoscache. This is, in essence, just a caching proxy.
How does it work from the inside? Here is our user, here is storage. Everything, as before. What do we add between them?

It is just a machine with a physical local disk, which is fast. This is with the SSD, let's say. And here on this disk any local cache is stored.
What does this look like? The user sends a request for a photo. NGINX searches for it first in the local cache. If not, it just does proxy_pass to our storage, downloads a photo from there and gives it to the user.
But this is very trite and incomprehensible what is happening inside. It works like this.

The cache is logically divided into three layers. When I say "three layers", this does not mean that there is some kind of complex system. No, this is conventionally just three directories in the file system:
- This is the buffer where the photos just downloaded from the proxy are placed.
- This is a hot cache that stores the photos that are currently actively requested.
- And a cold cache where photos are gradually pushed out of the hot when less request'ov comes to them.
For this to work, we need to somehow manage this cache, we need to rearrange the photos in it, etc. This is also a very primitive process.
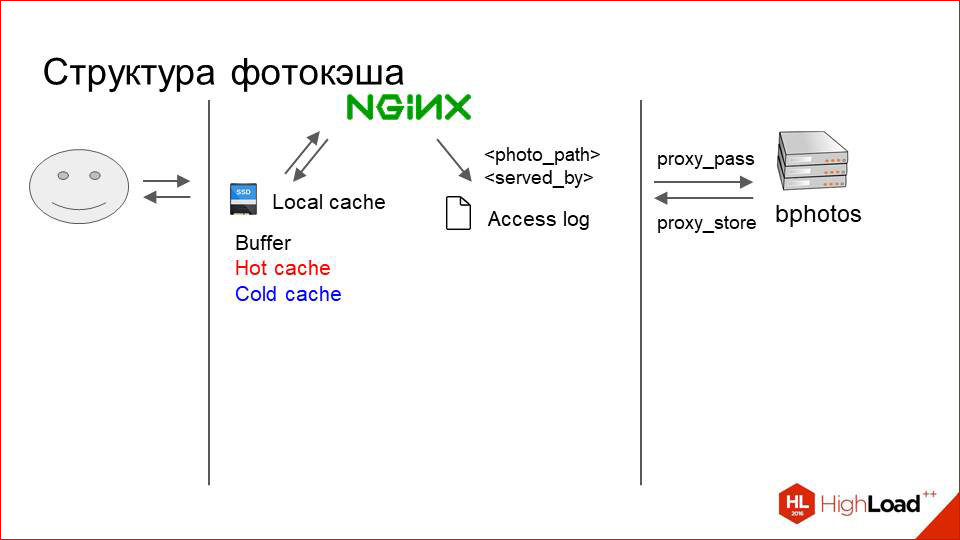
Nginx simply writes to each request on RAMDisk access.log, which indicates the path to the photo that he has served (relative path, of course), and how it was served by the partition. Those. “photo 1” can be written there and then either buffer, or hot cache, or cold cache, or proxy.
Depending on this, we need to somehow decide what to do with the photo.
We have a small daemon running on each machine, which constantly reads this log and keeps a memory of the use of certain photos in its memory.

He simply collects there, keeps counters, and periodically does the following. Actively requested photos, for which there are many requests, he moves to the hot cache, wherever they lie.

Photos that are rarely requested and are less frequently requested, it gradually pushes from the hot cache to the cold.
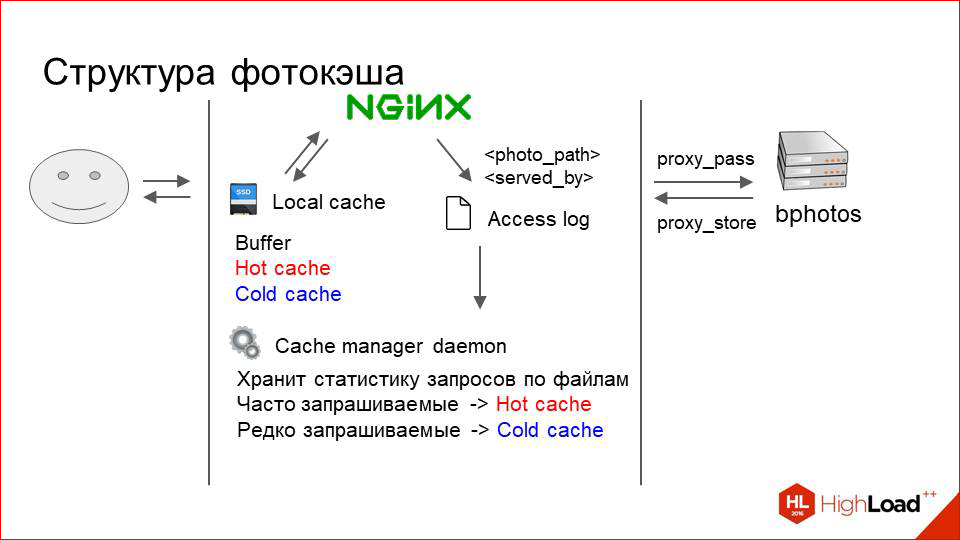
And when our cache runs out of space, we just start to delete everything from the cold cache without parsing. And this, by the way, works well.
In order for the photo to be saved immediately when proxying to the buffer, we use the proxy_store directive and the buffer is also a RAMDisk, i.e. for the user it works very fast. This is what concerns the internals of the caching server itself.
There was a question with how to distribute requests'y on these servers.
Suppose there is a cluster of twenty storage-machines and three caching servers (as it happens).

We need to somehow determine which requests for which photos and where to land.
The most banal option is Round Robin. Or do it by chance?
This obviously has a number of drawbacks, because we will be very inefficient to use the cache in this situation. Requests will land on some random machines: here it is cached, on the next it is gone. And if all this will work, it will be very bad. Even with a small number of machines in the cluster.
We need to somehow unambiguously determine which server to land on which request.
There is a banal way. We take the hash from the URL or the hash from our sharding key, which is in the URL, and divide it entirely by the number of servers. Will work? Will be.

Those. we have one hundred percent request, for example, for some “example_url” will always land on the server with the index “2”, and the cache will be constantly utilized as best as possible.
But there is a problem with rewarding in such a scheme. Resharding - I mean the change in the number of servers.
Suppose that our caching cluster stopped coping, and we decided to add another machine.
We add.

Now everything is divided completely into three instead of three. Thus, almost all the keys that we previously had, almost all URLs now live on other servers. The entire cache was invalidated just by the moment. All requests fell on our cluster-storage, he became ill, the service was denied and dissatisfied users. So do not want to do.
This option does not suit us either.
So what should we do? We must somehow effectively use the cache, constantly landing one request on the same server, but at the same time be resistant to resarding. And there is such a solution, it is not that difficult. Called consistent hashing.

What does this look like?

We take some function from the sharding key and smear all its values on the circle. Those. at point 0 we have its minimum and maximum values. Next, we place all of our servers on the same circle in a similar way:
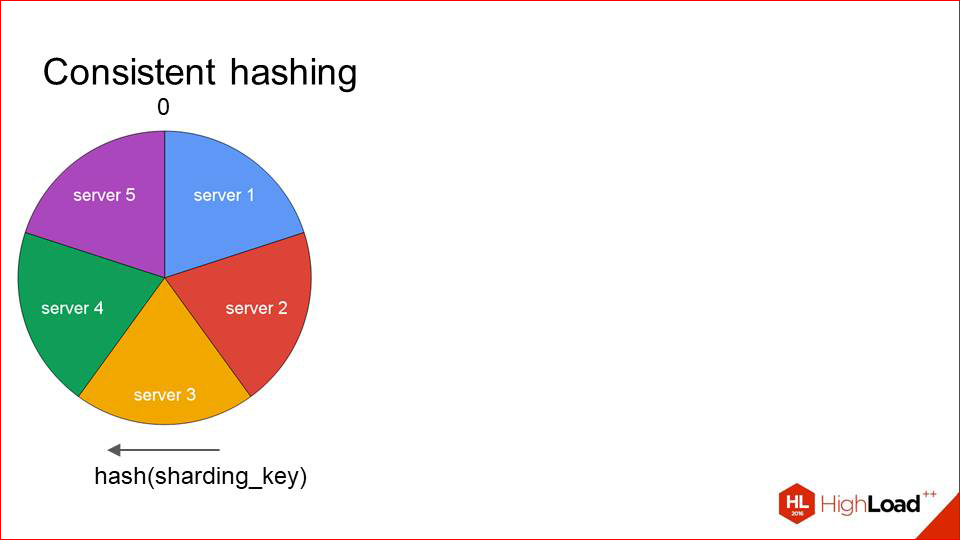
Each server is defined by one point, and the sector that goes to it in a clockwise direction, respectively, is served by this host. When requests come to us, we immediately see that, for example, request A - it has such a hash there - and it is serviced by server 2. Request B - by server 3. And so on.

What happens in this situation when resarding?
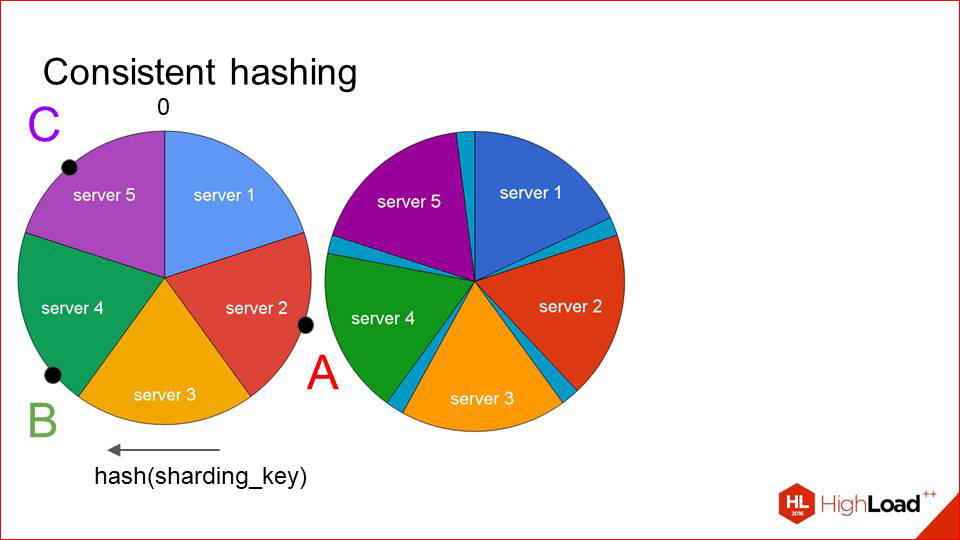
We do not invalidate the entire cache, as before, and do not shift all the keys, but we shift each sector a short distance so that, to put it that way, our sixth server that we want to add got into the free space and add it there.
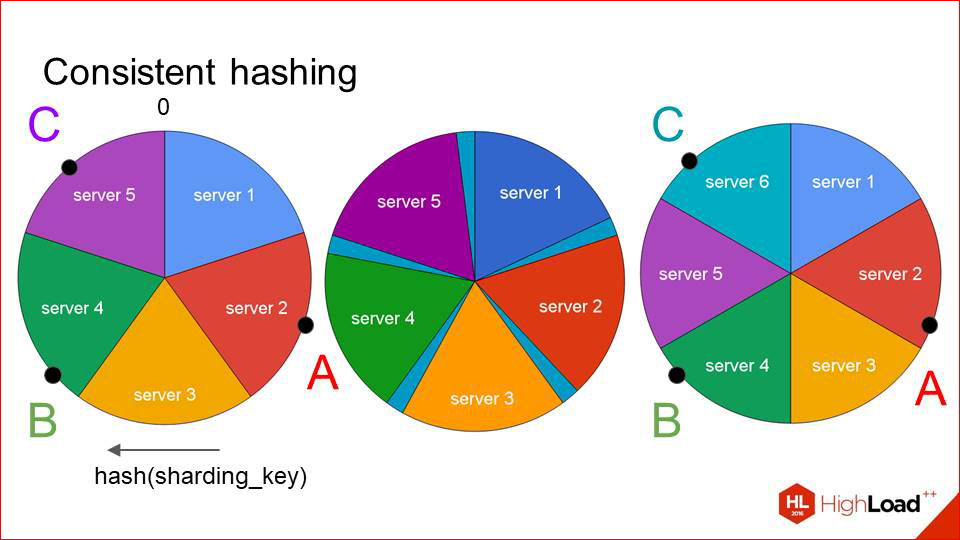
Of course, in such a situation, the keys also move out. But they move much weaker than before. And we see that our first two keys remain on their servers, and the caching server has changed only for the last key. This works quite efficiently, and if you add new hosts incrementally, there is no big problem. You add a little bit — add, wait — until the cache is full again, and everything works well.
The only question remains with failures. Suppose that we have some kind of car out of order.
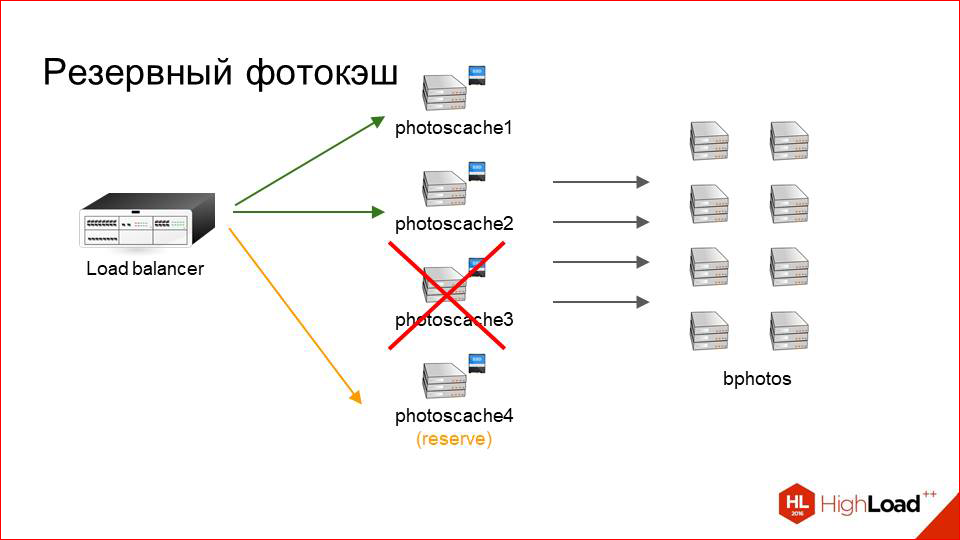
And we would not really like to regenerate this card at this moment, to invalidate a part of the cache, and so on, if, for example, the machine reboot, but we need to somehow serve the requests. We simply keep one backup photocache on each site, which serves as a replacement for any machine that has now crashed. And if suddenly we have some server became unavailable, the traffic goes there. At the same time, naturally, we have no cache there, i.e. it's cold, but at least user requests are processed. If this is a short interval, then we calmly experience it. Just more storage load goes. If this interval is long, then we can already decide whether to remove this server from the map or not, or maybe replace it with another one.
This is about the caching system. Let's look at the results.
It would seem that nothing complicated here. But this way of managing the cache gave us about 98% of the crate. Those. of these 80 thousand requests per second, only 1600 comes to storage, and this is a perfectly normal load, they calmly experience this, we always have a reserve.
We placed these servers in our three DCs, and got three points of presence - Prague, Miami and Hong Kong.

So they are more or less locally located to each of our target markets.
And as a nice bonus, we received this caching proxy, on which the CPU is actually idle, because it is not so much needed to upload content. And there with the help of NGINX + Lua, we implemented a lot of utilitarian logic.

For example, we can experiment with webp or progressive jpeg (these are effective modern formats), look at how this affects traffic, make some decisions, include for certain countries, etc .; do dynamic resize or crop photos on the fly.
This is a good usecase when, for example, you have a mobile application that shows pictures, and the mobile application does not want to spend the client's CPU to request a large photo and then resize it to a certain size in order to stuff it into a view. We can simply dynamically specify in the URL some conditional in the UPort conditional, and the photocache itself otresayzit photo. As a rule, he will select the size that we physically have on the disk, as close as possible to the requested one, and zadunskellit it in specific coordinates.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
We can also add a lot of grocery logic there. For example, we can add different watermarks by URL parameters, we can blur photos, blur or pixelate. This is when we want to show a photo of a person, but we don’t want to show his face, it works well, it’s all implemented here.
What did we get? We got three points of presence, a good hit rate, and at the same time, the CPU on these machines is not idle. He now became, of course, more important than before. We need to put the car ourselves stronger, but it's worth it.
This is with regard to the return of photos. Everything is clear and obvious here. I think that I did not discover America; almost any DN works this way.
And, most likely, the sophisticated listener might have a question: why not just not take and not change everything for DN? It would be about the same, all modern DN can do it. And here are a number of reasons.
The first is the pictures.

This is one of the key points of our infrastructure, and we need as much control over them as possible. If this is some kind of solution from a third-party vendor, and you do not have any power over it, it will be hard enough for you to live with it when you have a large dataset and when you have a very large stream of user requests.
I will give an example. Now, on our infrastructure, we can, for example, in case of any problems or underground knocks, go to the car, take it up, conditionally speaking. We can add a collection of some metrics that only we need, we can somehow experiment, see how it affects graphics, and so on. Now a lot of statistics are collected on this caching cluster. And we periodically look at it and for a long time we investigate some anomalies. If this were on the side of the DN, it would be much harder to control. Or, for example, if some kind of accident happens, we know what happened, we know how to live with it and how to overcome it. This is the first conclusion.
The second conclusion is also rather historical, because the system has been developing for a long time, and there were many different business requirements at different stages, and they do not always fit into the DN concept.
And the item arising from the previous -

This is something that on photo caches we have a lot of specific logic, which is not always possible to add upon request. It is unlikely that any CDN will add any custom items to your request. For example, URL encryption if you don’t want the client to change anything. You want to change the URL on the server and encrypt it, and then give some dynamic parameters here.
What conclusion suggests itself? In our case, a CDN is not a good alternative.

And in your case, if you have any specific business requirements, then you can absolutely calmly realize what I showed you. And this with a similar load profile will work fine.
But if you have some kind of general solution, and the task is not very private, you can safely take the CDN. Or if time and resources are much more important for you than control.

And modern DN have practically everything that I told you about now. Except for the plus or minus some features.
This is about the return of photos.
Let us now move forward a little bit in our retrospective and talk about storage.
2013 was coming.
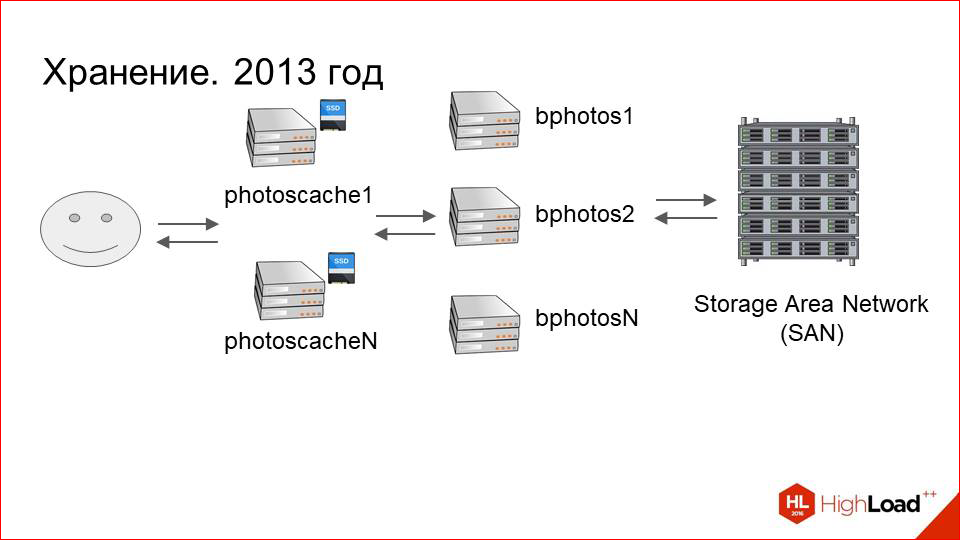
Caching servers were added, performance issues were gone. All is well. Dataset is growing.In 2013, we had about 80 servers that are connected to storage, and about 40 caching in each DC. This is 560 terabytes of data on each data center, i.e. about a petabyte in total.
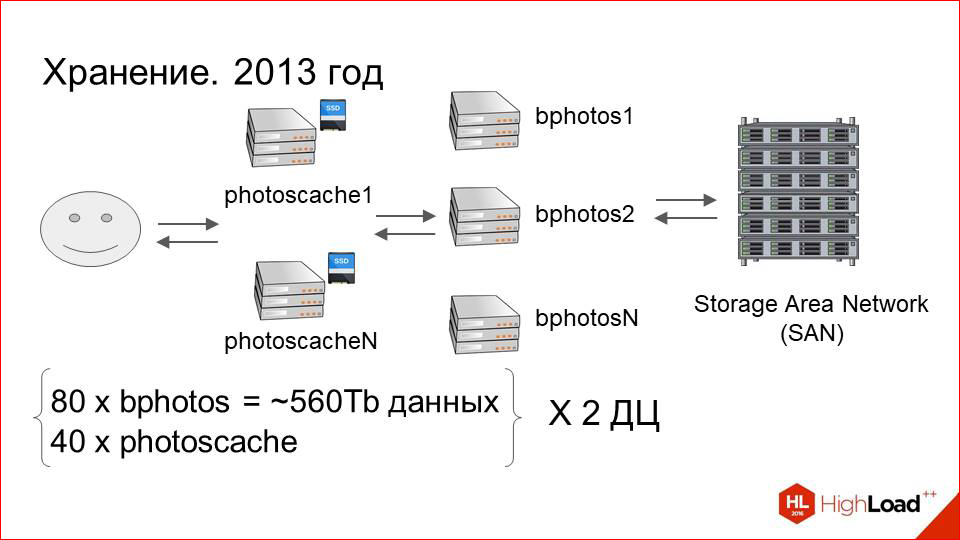
And with the growth of dataset, operational costs began to grow. What was it expressed in?
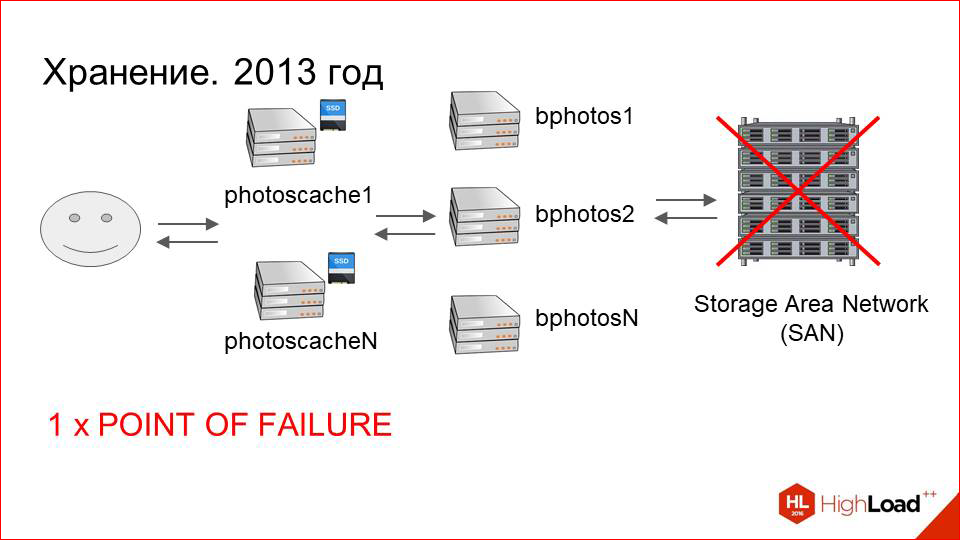
In this scheme, which is drawn - with SAN, with machines connected to it and caches - a lot of points of failure. If we had already coped with the failure of caching servers, everything is more or less predictable and understandable, then on the storage side, everything was much worse.
First, the Storage Area Network (SAN) itself, which can fail.
Secondly, it is connected via optics to the end machines. There may be problems with optical cards, candles.
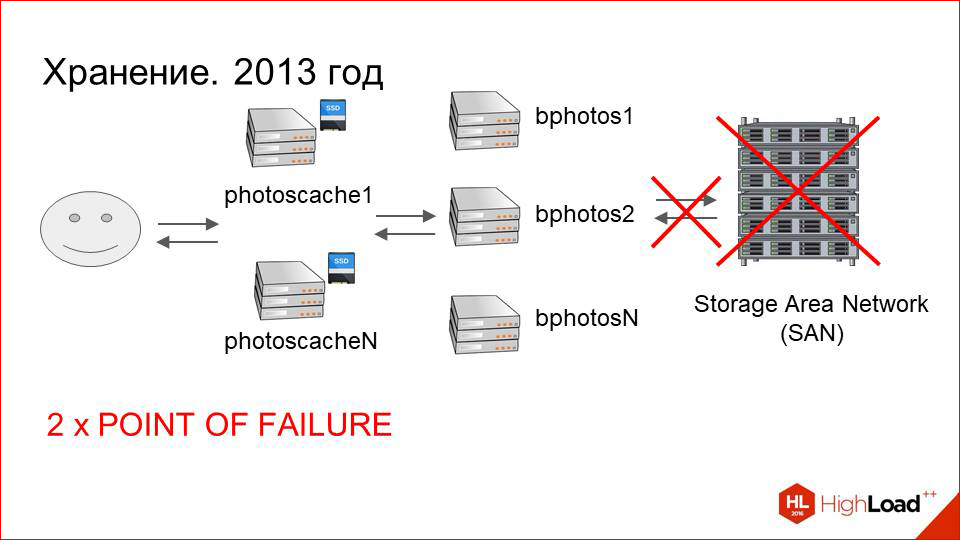
Of course, there are not so many of them as with SAN itself, but, nevertheless, these are also points of failure.
Next, the machine itself, which is connected to the storage. She, too, can fail.

Total we have three points of failure.
Further, in addition to points of failure, this is a difficult maintenance of the storage itself.
This is a complex multicomponent system, and it can be difficult for system engineers.
And the last, most important point. If a failure occurs at any of these three points, we have a non-zero probability of losing user data, as the file system may be beaten.
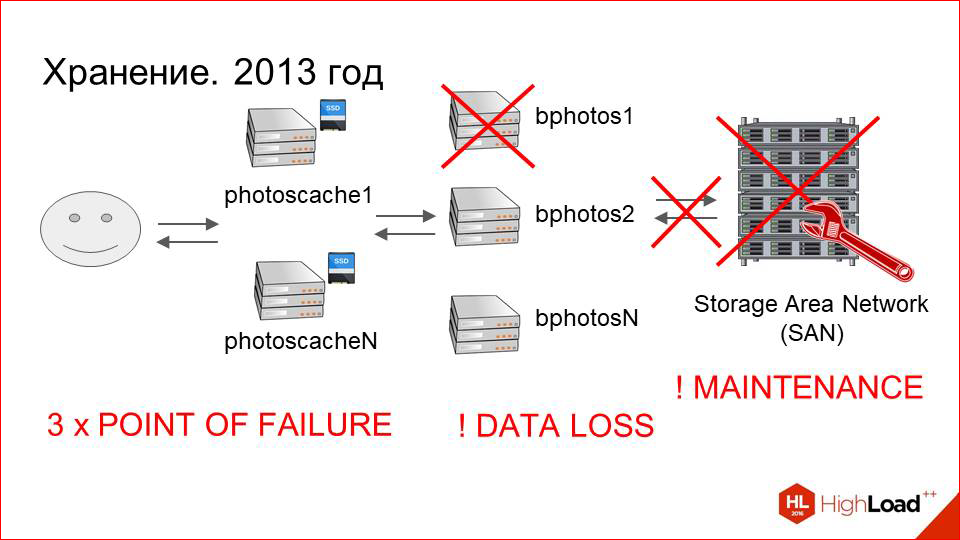
Suppose we have a beating file system. Its restoration is, firstly, long - it can take a week with a large amount of data. And secondly, as a result, we will most likely get a bunch of incomprehensible files that will need to be somehow mated to users' photos. And we risk losing data. The risk is quite high. And the more often such situations happen, and the more problems arise in this whole chain, the higher the risk.
We had to do something about it. And we decided that we just need to back up the data. This is actually an obvious solution and a good one. What have we done?

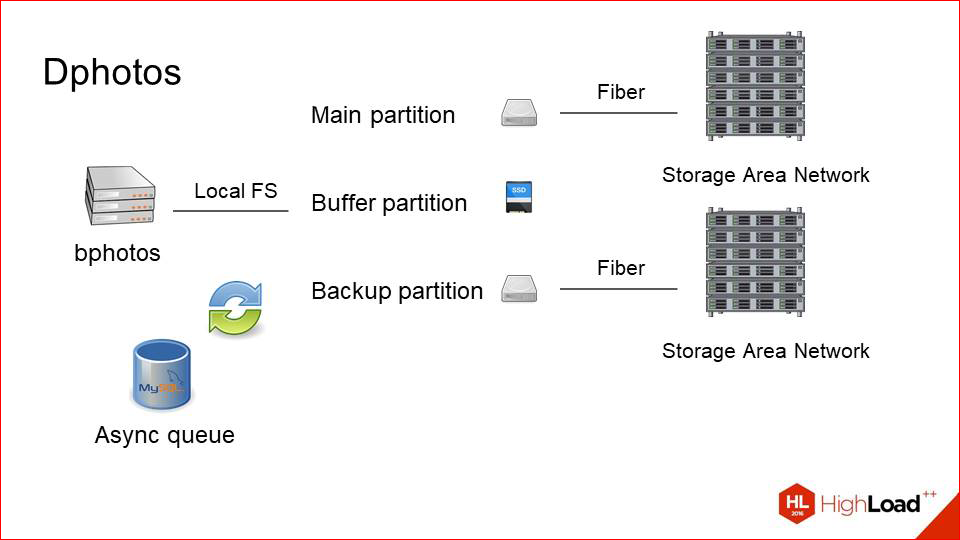
This is how our server looked like, which was connected to storage earlier. This is one main section, it’s just a block device, which actually represents a mount for remote storage over optics.
We just added the second section.
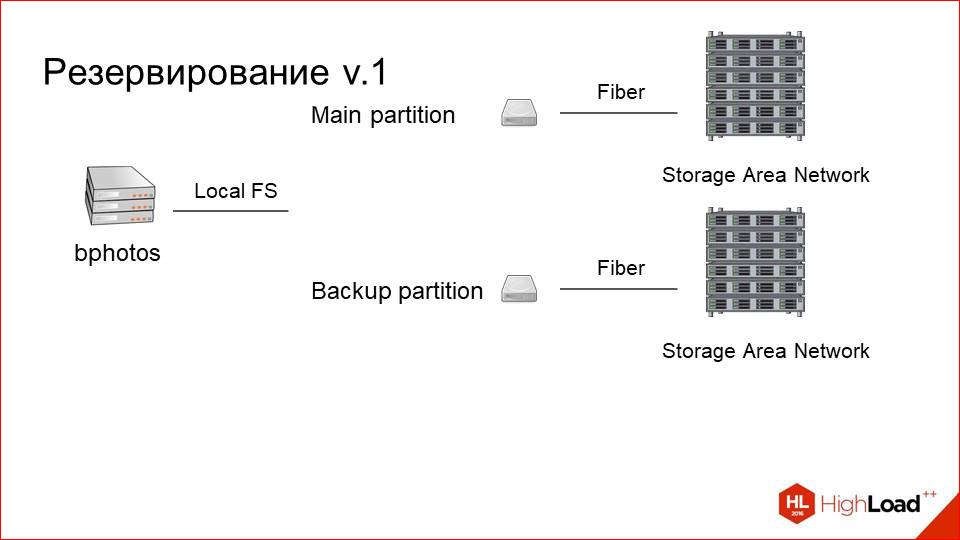
We set up a second storage (good, for the money it is not so expensive), and called it a backup partition. It is also connected via optics, is located on the same machine. But we need to somehow synchronize the data between them.
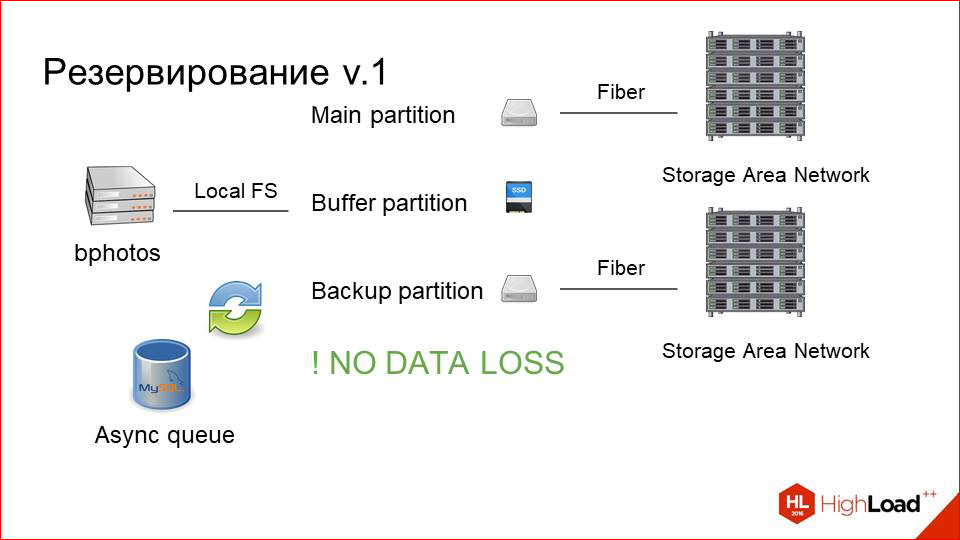
Here we just make an asynchronous queue nearby.

She is not very loaded. We know that we have few records. The queue is just a sign in MySQL, into which lines like “you need to save this photo” are written. With any change or upload, we copy from the main partition to the backup asynchronous or just some kind of background worker.
And so we always have two consistent sections. Even if one part of this system fails, we can always change the main partition with the backup, and everything will continue to work.
But because of this, the reading load greatly increases, because in addition to clients who read from the main section, because they first look at the photo there (it’s more recent there), and then they search on the backup if they don’t find it (but NGINX just does it), another plus is our system backup'a now reads from the main section. Not that it was a bottleneck, but did not want to increase the load, in fact, just like that.
And we added a third disk, which is a small SSD, and called it a buffer.

How it works now.
User upload'it photo on the buffer, then throws the event in the queue that it must be excavated into two sections. It is copied, and the photo for some time (say, a day) lives on the buffer, and only then it blurs from there. This greatly improves the user experience, because the user uploads a photo, as a rule, after it’s immediately begin to go request 's, or he himself refreshes the page, registered it. But it all depends on the application that makes the upload.
Or, for example, other people to whom he began to show, immediately for this photo send request 's. It is not in the cache yet, the first request is very fast. In fact, the same as with the photo cache. Slow storage does not participate at all in this. And when in a day it will be spoiled, it is either cached on our caching layer, or it is likely that no one needs it. Those.user experience here is very cool grown due to such simple manipulations.
Well, and most importantly: we stopped losing data.
We, so to say, stopped potentially losing data, because we didn’t lose them. But the danger was. We see that such a solution is, of course, a good one, but it is a bit like smoothing the symptoms of the problem, rather than resolving it to the end. And some problems remain.
First, this is the point of failure in the form of the physical host itself, on which all this machinery works, it has not gone anywhere.

Secondly, there were problems with the SANs, their heavy maintenance remained, etc. This is not something that was a critical factor, but I wanted to try to live somehow without it.
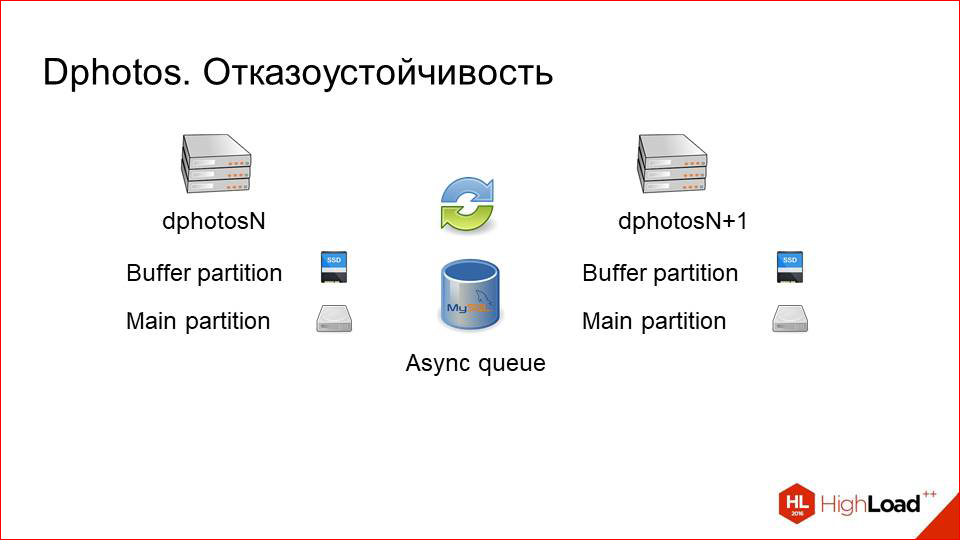
And we made the third version (in fact, the second one actually) - the reservation version. What did it look like?
This is what was -
The main problems we have with the fact that this is a physical host.
First, we remove SANs, because we want to experiment, we just want to try local hard drives.
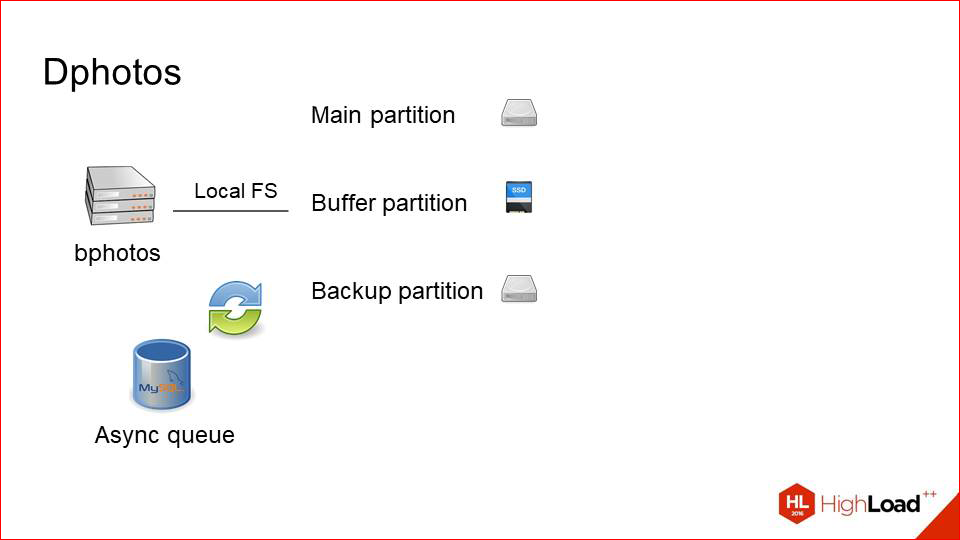
This is already the year 2014-2015, and at that time the situation with disks and their capacity in one host has become much better. We decided, why not try.
And then we just take our backup-section and transfer it physically to a separate machine.
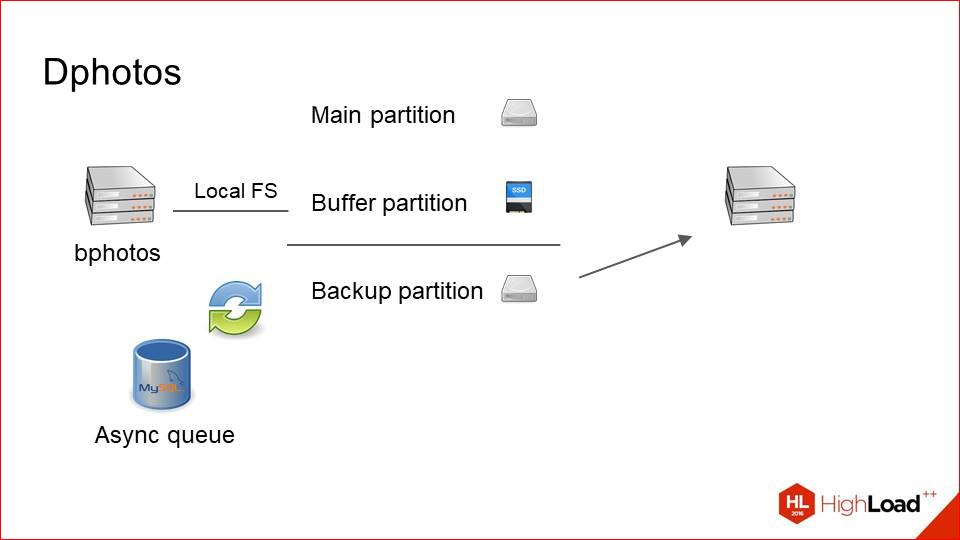
Thus, we get just such a scheme. We have two cars that store the same datasets. They reserve each other completely and synchronize data over the network through an asynchronous queue in the same MySQL.
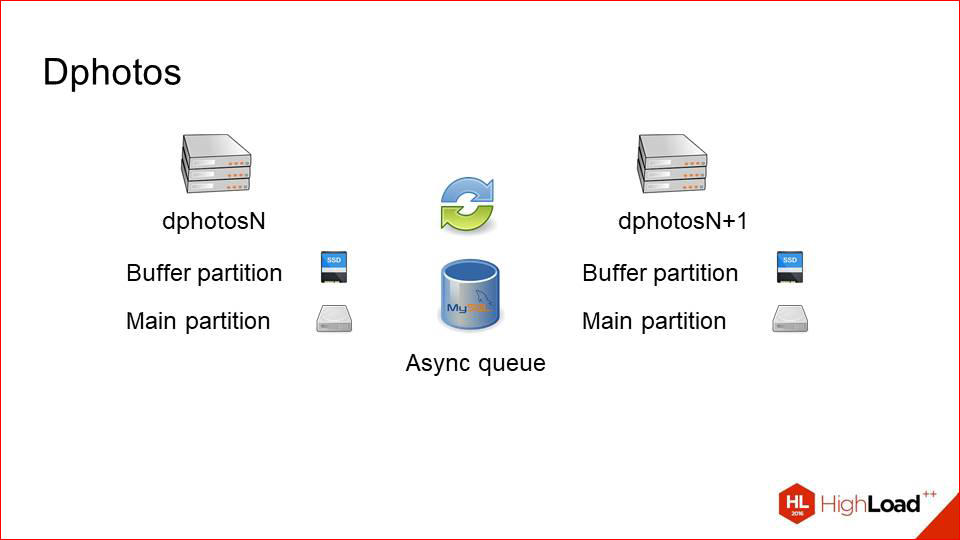
Why it works well - because we have few records. Those.if the recording were commensurate with the reading, perhaps we would get some kind of network overhead and problems. There is little writing, a lot of reading - this method works well, i.e. we rarely copy photos between these two servers.
How does this work, if a little more detailed look.

Upload. The balancer simply selects random hosts with a pair and uploads to it. At the same time, he naturally does health checks, looks to prevent the car from falling out. Those.He uploads pictures only to a live server, and then through an asynchronous queue, this is all copied to his neighbor. With upload, everything is extremely simple.
With the task a little more difficult.

Lua helped us here, because on vanilla NGINX this logic is hard to make. We first make a request to the first server, see if there is a picture there, because potentially it can be uploaded, for example, to a neighbor, but has not arrived here yet. If the photo is there, that's good. We immediately give it to the client and, perhaps, we cache it.
If it is not there, we simply make a request for a neighbor and from there we get it guaranteed.

Soagain we can say: there may be problems with performance, because constant round trips are filled up with a photo, there is no photo, we make two requests instead of one, it should work slowly.
In our situation, it does not work slowly.

We are going to have a lot of metrics on this system, and the conditional cunning rate of such a mechanism is about 95%. Those.The lag of this backup is small, and due to this we are almost guaranteed, after the photo has been uploaded, we take it away the first time and do not go anywhere twice.
So what else have we got, and what's very cool?
Previously, we had a basic backup section, and we read them sequentially. Those.we always looked first on the main, and then on the backup. It was one move.
Now we recycle reading from two machines at once. Distribute requests Round Robin'om. In a small percentage of cases we make two requests. But on the whole, we now have twice as much reading margin as before. And the load is really great and decreased on the returning cars, and directly on the storage, which we also had at that time.
As for fault tolerance. Actually, we fought for this basically. With fault tolerance, everything is gorgeous here.
One car fails.

No problem! The system engineer may not even wake up at night, wait until the morning, nothing terrible will happen.
If, even with the refusal of this machine, the queue is out of order, there are also no problems, just the log will be accumulated first on the live machine, and then get in the queue, and then on the car that will go into service after some time.
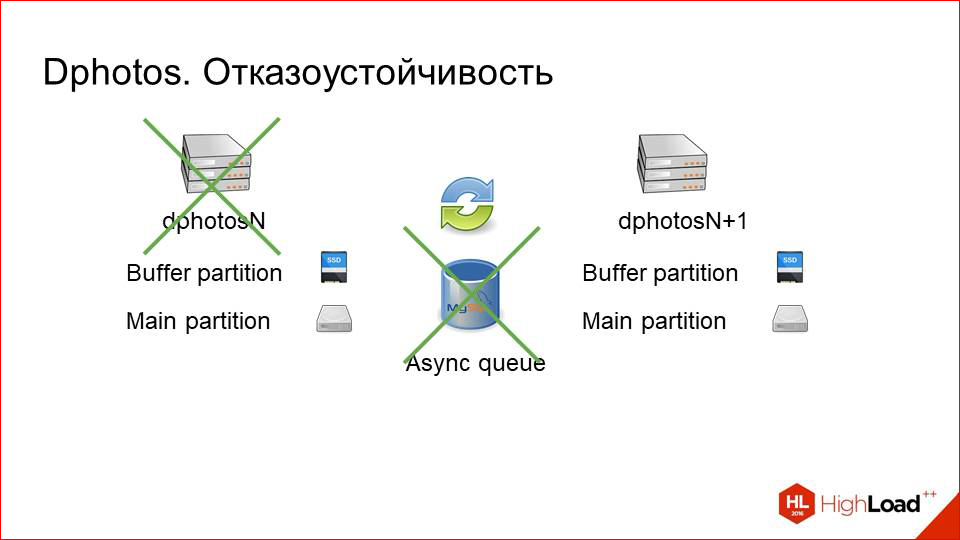
Same with maintenance. We just turn off one of the machines, pull it out of all pools with our hands, it stops traffic, we do some maintenance, we rule something, then we return it to the system, and this backup catches up pretty quickly. Those.per day downtime of one car catching up within a couple of minutes. This is directly very small. With fault tolerance, I say it again, everything is cool here.
What can be summed up from this scheme with reservation?
Received fault tolerance.
Easy operation. Since the machines have local hard drives, this is much more convenient from the point of view of the exploitation of the engineers who work with it.
Received a double margin on reading.
This is a very good bonus in addition to resiliency.
But there are problems.Now we have a much more complex development of some features related to this, because the system has become 100% eventually consistent.

We have to, say, in some background job, constantly think: “And on which server are we running now?”, “Is there really an actual photo here?”, Etc. This, of course, is all wrapped up in wrappers, and for a programmer who writes business logic, this is transparent. But, nevertheless, this large complex layer appeared. But we are ready to put up with it in exchange for those buns that we got from it.
And here again there is some conflict.
I said at first that storing everything on local hard drives is bad. And now I say we liked it.
Yes, indeed, over time, the situation has changed dramatically, and now this approach has many advantages. First of all, we get much simpler operation.
Secondly, it is more productive, because we do not have these automatic controllers, connection to disk shelves.
There is a huge machine, and these are just a few disks that are collected here on the machine in a raid.
But there are also disadvantages.

This is about 1.5 times more expensive than using SANs even at today's prices. Therefore, we decided so boldly not to convert our entire large cluster into cars with local hard drives and decided to leave the hybrid solution.
Half of the machines we work with hard drives (well, not half - 30 percent, probably). And the rest is old cars, which used to be the first reservation scheme. We simply remounted them, since we didn’t need any new data or anything else, we just moved the mount from one physical host to two.
And we have a large supply of reading, and we have enlarged. If earlier we mounted one storage on one machine, now we mount four for one pair, for example. And it works fine.
Let's summarize what we did, what we fought for, and whether it worked.
Results
We have users - as many as 33 million.
We have three points of presence - Prague, Miami, Hong Kong.
They contain a caching layer, which is a wheelbarrow with fast local disks (SSD), which is powered by unpretentious machinery from NGINX, its access.log and daemons in Python, which process all this and manage the cache.
If you wish, you are in your project, if the pictures for you are not as critical as for us, or if the trade-off control is against development speed and resource costs for you in the other direction, then you can safely replace it with CDN, modern CDN is doing well.
Next comes the storage layer, on which we have a cluster of pairs of machines that reserve each other, and asynchronously copy files from one to another for any change.
At the same time, some of these machines work with local hard drives.
Some of these machines are connected to SANs.

And, on the one hand, it is more convenient to use and a little more productive, on the other hand, it is convenient in terms of density and price per gigabyte.
This is such a brief overview of the architecture of what we got and how it all developed.
A few more tips from the cap, quite simple.
Firstly, if you suddenly decide that you urgently need to improve everything in your infrastructure of photos, first try it on, because perhaps you don’t need to improve anything.

I will give an example. We have a cluster of machines, which gives photos from attachment'a in chat rooms, and that is where the scheme is still working since 2009, and no one suffers from it. Everyone is good, everyone likes everything.
In order to measure, first hang up a bunch of metrics, look at them, and then decide what you are unhappy with, what needs to be improved. In order to measure this, we have a cool tool called Pinba.
It allows you to collect a very detailed NGINX list for each request and response codes, and the distribution of times is everything. He has a binding in all sorts of different systems for building analytics, and then you can watch all this beautifully.
At first they measured and then improved.
Further. We optimize reading with cache, writing with sharding, but this is an obvious point.

Further. If you are just starting to build your system, it is much better to take photos as immutable files. Because you lose immediately a whole class of problems with cache invalidation, with how the logic has to find the right version of the photo and so on.

Suppose, weave poured, then turned it, make it so that it was physically another file. Those. no need to think: now I will save a little bit of space, write it down in the same file, change the version. It always works bad, with this sweat a lot of headaches.
The next item. About resize on the fly.
We used to, when upload users or a photo, cut a whole bunch of sizes at once for all occasions, under different clients, and they all lay on the disk. Now we have abandoned it.
We left only three main sizes: small, medium and large. Everything else we just downscale from the size that is behind the one we were asked in Uport, just do downscale and give it to the user.
The caching layer's CPU here is much cheaper than if we constantly re-generated these sizes on each storage area. Suppose we want to add a new one, this business for a month - to get rid of the script everywhere, which would have done all this neatly, without putting down the cluster. Those. if there is an opportunity to choose now, it is better to do as little as possible of physical dimensions, but for at least some distribution to be, say, three. And everything else is easy to resize on the fly using ready-made modules. It is now all very easy and affordable.
And incremental asynchronous backup is good.
As our practice has shown, this scheme works great with deferred copying of modified files.

The last point is also obvious. If there are no such problems in your infrastructure now, but there is something that can break, it will surely break when it becomes a bit more. Therefore, it is better to think about it in advance and not to experience problems. That's all I wanted to say.
Contacts
» Bo0rsh201
» Badoo company blog
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems. Less than a month is left before the HighLoad ++ 2017 conference.
We have already prepared the conference program , now the schedule is being actively formed.
This year we continue to explore the topic of architecture and scaling:
- How to serve a billion users and give the terabit of traffic / Igor Vasilyev
- How to rewrite VKontakte personal message database from scratch and migrate to it without downtime / Dmitry Egorov
- Death from the sale: how Yandex.Money tried to accelerate to Black Friday and survive / Anatoly Plaskovsky
- Fail-safe architecture of the frontal system of the bank / Roman Shekhovtsov, Alexey Gromatchikov
- Payment system architecture: almost enterprise / Philippe Delgyado
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/340976/
All Articles