Why does one NGINX process take care of all the work?
The scaling method for TCP servers is usually obvious. Start with one process when you need it - just add more. Many applications do this, including HTTP servers like Apache, NGINX, or Lighttpd.

Increasing the number of servicing processes is an excellent method for solving the problem of using just one CPU core, but at the cost of other problems.
There are three ways to organize a TCP server regarding performance:
a) one passive socket, one serving process;
b) one passive socket, multiple servicing processes;
c) a set of serving processes, each has its own passive socket.

The "a" method is the simplest due to the limitation of one CPU available for processing requests. A single process accepts connections by calling accept() and servicing them. This method is preferred for Lighttpd.
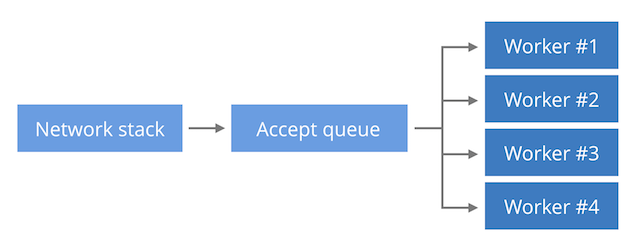
With method "b", new connections are in the same kernel data structure (passive socket). Many servicing processes call accept() on this socket and process received requests. The method allows to balance incoming connections between several CPUs within certain limits and is standard for NGINX.
Using the SO_REUSEPORT socket SO_REUSEPORT it is possible to provide each process with its own kernel structure (passive socket). This avoids the competition of serving processes for accessing a single socket, which, however, should not be a particular problem, unless your traffic is comparable to Google. The method also helps to balance the load better, which will be shown below.
In Cloudflare, we use NGINX, and therefore are more familiar with method "b". The article will describe its specific problem.
We distribute accept () load
Few people know that there are two ways to distribute new connections among several processes. Consider two pseudocode listings. Let's call the first blocking-accept:
sd = bind(('127.0.0.1', 1024)) for i in range(3): if os.fork () == 0: while True: cd, _ = sd.accept() cd.close() print 'worker %d' % (i,) One queue of new connections is shared between processes by blocking the accept() call in each of them.
The second path is called epoll-and-accept:
sd = bind(('127.0.0.1', 1024)) sd.setblocking(False) for i in range(3): if os.fork () == 0: ed = select.epoll() ed.register(sd, EPOLLIN | EPOLLEXCLUSIVE) while True: ed.poll() cd, _ = sd.accept() cd.close() print 'worker %d' % (i,) Each process has its own epoll event cycle. Non-blocking accept() will be called only when epoll announces the presence of new connections. In this case, the usual thundering herd problem (when all the processes that can process it wake up is approached by even a single event) is avoided using the EPOLLEXCLUSIVE flag. The full code is available here .
Both programs look similar, but their behavior is slightly different. This is what will happen when we try to establish several connections with each of them:
Of course, it is not fair to compare the blocking accept() with the epoll() event cycle. Epoll is a more powerful tool and allows you to create complete event-oriented programs. Using the same blocking method of receiving connections is cumbersome. For the meaningfulness of such an approach in real conditions, it will be necessary to have a thorough multi-threaded programming with a separate thread for each request.
Another surprise - using the blocking accept() on Linux is technically incorrect! Alan Burlison pointed out that if you execute close() on a passive socket, the accept() blocking calls that execute on it will not be interrupted. This can lead to sudden behavior: successful accept() on a passive socket that no longer exists. If in doubt, avoid using blocking accept() in multi-threaded programs. A workaround is to call shutdown() before close() , but it does not comply with the POSIX standard. Damn leg break.
$ ./blocking-accept.py & $ for i in `seq 6`; do nc localhost 1024; done worker 2 worker 1 worker 0 worker 2 worker 1 worker 0 $ ./epoll-and-accept.py & $ for i in `seq 6`; do nc localhost 1024; done worker 0 worker 0 worker 0 worker 0 worker 0 worker 0 In the blocking-accept program, the connections were distributed among all the serving processes: each received exactly two. In the epoll-and-accept program, all connections received only the first process, the rest did not receive anything. The fact is that Linux differently balances requests in these two cases.
In the first case, Linux will make a FIFO cyclic distribution. Each process waiting to return a call to accept() becomes a queue and receives new connections also in the order of the queue.
In the case of epoll-and-accept, the algorithm is different: Linux seems to choose the process that was added to the queue to wait for new connections last, i.e. LIFO . This behavior results in most new connections being received by the most “busy” process, which has just returned to waiting for new events after processing the request.
We see this distribution in NGINX. Below is the output of the top command from the web server during a synthetic test, in which one of the serving processes gets more work and the rest is relatively less.

Please note that the last process in the list is practically not busy (less than 1% of the CPU), and the first one consumes 30% of the CPU.
SO_REUSEPORT to the rescue
Linux supports the SO_REUSEPORT socket SO_REUSEPORT , which allows you to circumvent the described load balancing problem. We have already explained the use of this option in the "in" mode, in which incoming connections are distributed over several queues instead of one. As a rule, one queue per serving process is used.
In this mode, Linux distributes new connections using hashing, which leads to a statistically uniform distribution of new connections and, as a result, approximately equal to the amount of traffic for each process:

Now the process load variation is not so great: the leader consumes 13.2% of CPU, and the outsider - 9.3%.
Well, the load distribution has become better, but this is not the whole story. Sometimes splitting the receive queues of connections worsens the distribution of the delay in processing requests! A good explanation for this is The Engineer guy:
I call this problem "Waitrose cashiers versus Tesco cashiers" (popular retailers in Britain - approx. Transl. ). The “one turn to all cashiers” Waitrose model better reduces the maximum delay. One stalled cashier will not significantly affect the remaining customers in the queue, because they will go to less busy employees. The Tesco model “for each cashier has its own turn” in the same case will lead to an increase in the time of service for a specific customer, and all who are behind him.
In the case of increased load, method "b" does not evenly distribute the load evenly, but provides the best time to wait for a response. This can be shown by synthetic dough. Below is the distribution of response times for 100,000 relatively CPU-demanding requests, 200 simultaneous requests without HTTP keepalive, served by NGINX in the "b" configuration (one queue for all processes).
$ ./benchhttp -n 100000 -c 200 -r target:8181 http://aa/ | cut -d " " -f 1 | ./mmhistogram -t "Duration in ms (single queue)" min:3.61 avg:30.39 med=30.28 max:72.65 dev:1.58 count:100000 Duration in ms (single queue): value |-------------------------------------------------- count 0 | 0 1 | 0 2 | 1 4 | 16 8 | 67 16 |************************************************** 91760 32 | **** 8155 64 | 1 It is easy to see that the response time is predictable. The median is almost equal to the mean value, and the standard deviation is small.
The results of the same test conducted with NGINX with the configuration method "c" using the option SO_REUSEPORT :
$ ./benchhttp -n 100000 -c 200 -r target:8181 http://aa/ | cut -d " " -f 1 | ./mmhistogram -t "Duration in ms (multiple queues)" min:1.49 avg:31.37 med=24.67 max:144.55 dev:25.27 count:100000 Duration in ms (multiple queues): value |-------------------------------------------------- count 0 | 0 1 | * 1023 2 | ********* 5321 4 | ***************** 9986 8 | ******************************** 18443 16 | ********************************************** 25852 32 |************************************************** 27949 64 | ******************** 11368 128 | 58 The average value is comparable to that in the previous test, the median has decreased, but the maximum value has increased significantly and, most importantly, the standard deviation is now just huge. Service time varies widely - definitely not the situation that I would like to have on the combat server.
However, treat this test with healthy skepticism: we tried to create a significant burden in order to prove our case. Your specific conditions may allow you to limit the load on the server so that it does not enter the described state. For those who want to reproduce the test its description is available .
To use NGINX and SO_REUSEPORT , several conditions must be met. First make sure that NGINX version 1.13.6 or higher is used, or apply this patch . Second, remember that due to a defect in the Linux implementation of TCP REUSEPORT, reducing the number of REUSEPORT queues will cause some pending TCP connections to be dropped.
Conclusion
The problem of balancing incoming connections between multiple processes of a single application is far from a solution. Using the same queue using the "b" method scales well and allows you to keep the maximum response time at an acceptable level, but due to the mechanics of the epoll, the load will be unevenly distributed.
For loads that require uniform distribution between serving processes, it may be useful to use the SO_REUSEPORT flag in the "in" method. Unfortunately, in a high-load situation, the distribution of response times can deteriorate significantly.
The best solution seems to change the standard behavior of epoll from LIFO to FIFO. Jason Baron from Akamai has already tried to do this ( 1 , 2 , 3 ), but so far these changes have not fallen into the core.
Explanation: The translator is not affiliated with Cloudflare, Inc. The translation is made out of love for art, all rights are with their owners. The author of KDPV is Paul Townsend , CC BY-SA 2.0.
')
Source: https://habr.com/ru/post/340950/
All Articles