REST in the real world and the practice of hypermedia
How to build the architecture of the application, taking into account the specifics of REST? Was it with you that the word "REST" called any HTTP API indiscriminately - and how to convey the true meaning of this term? How to show that the advantages of REST manifest themselves in large long-term projects, but for a small utility it is better to take something simpler? These and other burning issues are covered by Dylan Beattie in the report “Real world REST and Hands-On Hypermedia”.
Dylan is a systems architect and developer who has managed to participate in many projects in his life, from small websites to huge distributed systems; from Legacy with a twenty-year history to the latest developments. He now works as an architect in Spotlight and is engaged in solving complex problems in modern distributed systems. Creating the right, beautiful, and efficient HTTP API is part of his job, and he really knows a lot about them.
You will be able to meet with Dylan live at the DotNext Moscow 2017 conference, where he will arrive with a new report "Life, liberty and the pursuit of APIness: the secret to happy code . " We remind you that you can buy tickets at a tasty price until October 31 inclusive.
')
This article can either be read in the text interpretation (click the button "read more" ⇩), or see the full video of the report. All the images you need to understand, slides and diagrams are present both in the video and in the text decoding, so you won't lose anything.
Comments on the article are welcome and really important - we will try to ask your best questions directly to Dylan on DotNext Moscow 2017 .
Today we will talk about the ideology of REST in the real world and the practical embodiment of hypermedia.
But first, a little about me.
My name is Dylan Beattie. The best way to ask any questions about the report is to find me on twitter (@dylanbeattie). I have a VK page, but I don’t speak Russian, so I don’t have friends on this social network.
For a long time I have been creating websites. I created my first web page back in 1992, when the World Wide Web was one year old. In addition, I develop web applications.
Currently, I am a systems architect at Spotlight in London, which is working on various projects in the film industry - a very interesting direction.
My website: dylanbeattie.net . There I publish my notes on software architecture, REST and other such things. I also want to mention that the code from all the slides is on GitHub: github.com/dylanbeattie/dotnext/ . You can download it from there and test it yourself.
But let's talk about REST.
REST is a fairly well-known concept. Many have heard about it, many work with it. However, there is still a lot of confusion about what REST is, why this concept is important and how you can use it to solve your problems. Today we will look at the answers to some of these questions. But first of all, I will try to form a clear idea of which systems correspond to REST. Therefore, we start from the beginning - refer to the source.

This is Roy Fielding. Roy invented REST and determined what it is. There are many materials devoted to software and computing, which explains how everything works. The words used have different meanings for different people. But REST has a very clear definition, which we will discuss first.
Roy is now a senior research scientist at Adobe. He previously worked on Apache. In fact, he is one of the founders of the Apache web server project, and he was also one of the authors of HTTP, the underlying protocol that binds the World Wide Web together. In 2000, Roy published his thesis "Architectural styles and design of network software architectures." In this paper, he describes the styles of scalable software architecture on the web.
This is the very first point that needs to be understood. REST is not a framework or a library; it cannot be simply downloaded or installed. REST is a set of rules, restrictions, and guidelines for how you should solve the problems you encounter in your applications.
Abstracts Roy is very popular. They are worth seeing if you are interested in looking at the basics. In his work, I want to highlight a few maxims.
The first is a related set of architectural constraints; having a name, it becomes an architectural style . In his opinion, this question was influenced by architecture (in the context of construction), he thought a lot, including about architectural styles. Buildings are not distinguished from each other by a project, not by design - but by style: a set of individual peculiarities and limitations. And REST is like him. This is a set of patterns that you can apply to your systems.
I also find it very important that “ REST in software development has existed for decades. Every detail ensures the durability and independent evolution of software . ” REST is designed to create systems that will work for years and maybe decades. If next month you are expecting the end of financing, you probably should not create a system that complies with the REST postulates, because many of the limitations presented in this concept are directly opposed to short-term effectiveness.
It often happens that in a project you are working on there are two or more ways to solve a problem. And the path that leads to REST often takes more time. Along the way, you should think about a lot of things that may not be a problem for you and your company. So be very careful. Think about what exactly you are trying to achieve. If you are lucky to work on a system that will function for many years, in the framework of this article you will find many ideas that I hope will be useful to you.
If you build a prototype, conduct a lot of experiments to see if something will work, the situation is ambiguous. REST doesn't hurt - but some requirements may slow you down.
Roy Fielding proposed the definition of REST - this is a coordinated set of architectural constraints.
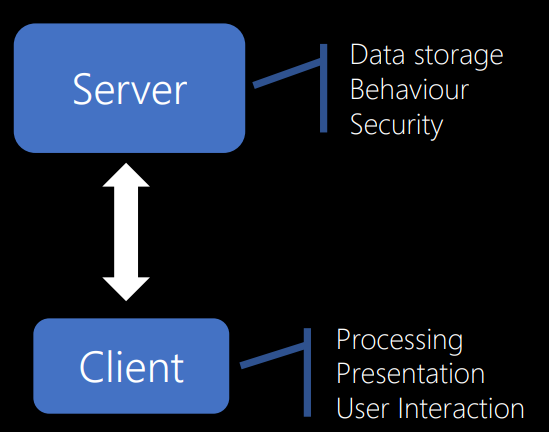
First of all, according to him, the software system should be built to work on the client and on the server. I hope this doesn’t surprise anyone. Most of us, I think, have already created client-server applications - websites, email systems, FTP. Now it is very common.
I will not describe the details. Your server is somehow shared between clients, providing data storage, basic functions, and security — those things that you want to manage centrally.
One of the nice things about customers is that each one comes from a computer. Therefore, if you have calculations that you need to perform, you can distribute them to a large number of clients. In this way, customers provide data processing, presentation and user interaction.
The server serves several clients. And this is a big advantage. You can serve many thousands of users with the help of one server, if, of course, correctly design your system.
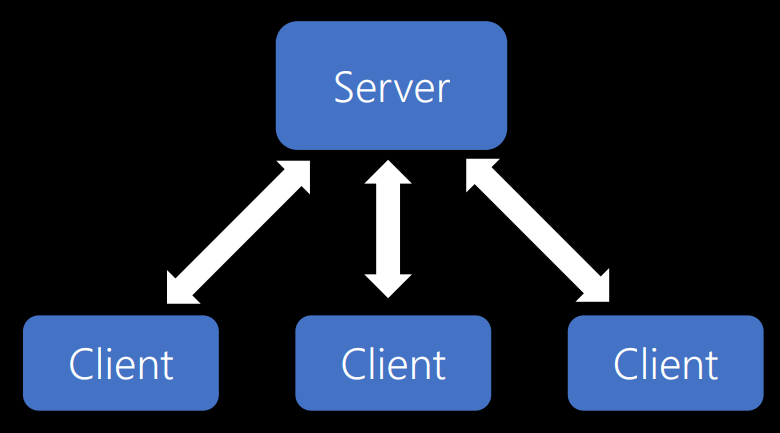
The second limitation relates to the rejection of state storage. In ASP.NET, PHP, ColdFusion, or classic ASP, you are confronted with the idea of a session. So you have a session cookie. But this idea no longer works. When you had something like ASP.NET and you ran one web server, it started to slow down a bit. Then you installed another web server, and in the end everything ceased to work due to the fact that each time a request was sent to the server, some storage space was allocated only for that client. Like that:
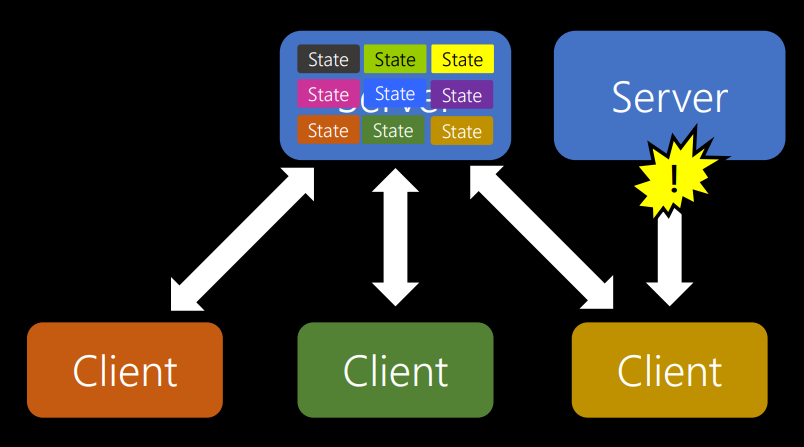
The server kept its status. At the same time comes the next person, who also has some kind of condition.
What happens when the server fills up and then one of the clients leaves? We do not know whether he will return, so we have to keep the state for a period of time. But what should be the session timeout? 5 minutes, 10 minutes, 24 hours? It is very difficult to determine. But the biggest problem is that if you run another server, which gives you even more options, and then one of the clients tries to switch from one server to another, the connection is interrupted, because the session information is stored in a different place.
Therefore, by avoiding state storage, you get more flexibility regarding how many clients you can service and how you can scale the system.
The third constraint that Roy defines is caching.
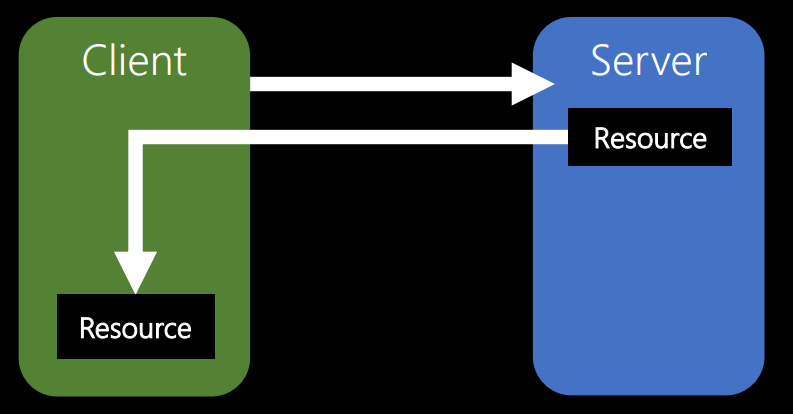
Suppose there is some resource on the server. The client requests it. If the same resource is required by the client again, he will not have to re-request it. He should be able to use what is already there.
When you perform a task on a server, you spend resources. You may be processing a video or photo. And all that costs resources, you need to reuse. This is the best you can do. You need to save the processing result so that anyone who ever returns and asks for the same data again can simply get the same resource.
The following limitation is directly related to the idea of caching. This is the idea of multi-level systems. My favorite example of this idea is a caching proxy server between clients and the server.
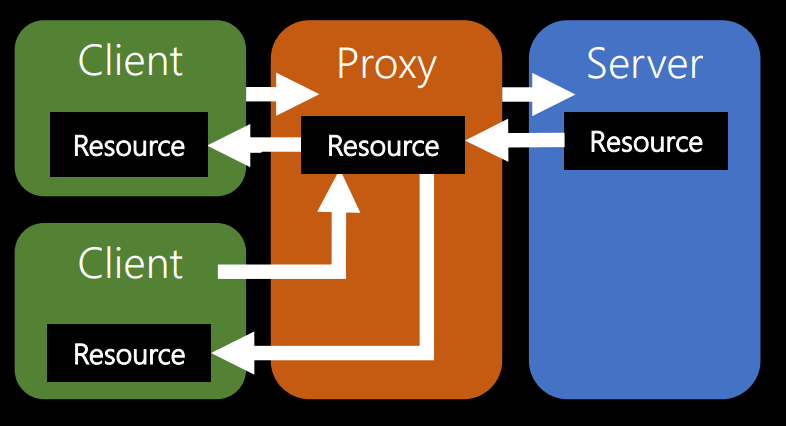
Clients in this diagram on the left. Suppose these are different variants of smartphones - iPhone, Samsung, Android - anything. Proxy server - in the middle of the chain. Suppose it is managed by a certain large telecommunications company. As the owner of the server, you pay for the work of what is to the right of the proxy. After all, when a request comes from the client, the server performs some calculations. And it costs money - electricity, equipment depreciation, etc.
If the telecommunications company saves a copy of the results, the next time someone requests information, he will receive a proxy copy. You will not need to spend money on the execution of the request. Thus, the idea of caching on a proxy is incredibly good, because it allows other people to pay to make your software faster without additional investments.
Even in the framework of the idea of a multi-level system, you can add more intermediate levels. In multi-tier systems, servers and clients do not care about what levels the request passes through.
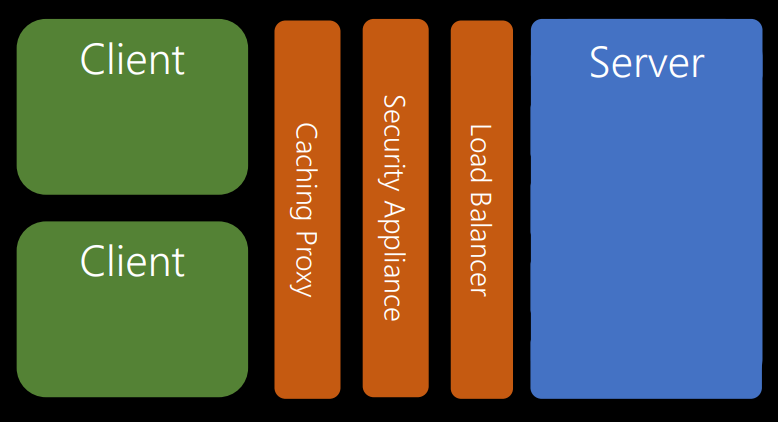
In this example, the clients interact with the proxy server. The proxy thinks that it interacts with the server, but in fact it sends requests for a security level (for example, a firewall). That, in turn, believes that it communicates with the server, it actually sends requests to the load balancer.
The load balancer believes that it interacts with the server, but in fact it is about five servers. We can deploy new ones, close old ones, and thanks to the load balancer, this does not affect other levels.
The concept of multi-level systems gives you tremendous flexibility when planning applications.
Resource identification
Before the advent of HTTP and REST, if you wanted to get some information from the server, you had to choose one of several dozen protocols - Gopher, FTP, Telnet, etc. All these were different systems, and each meant its own way of interacting with remote information and remote services.
HTTP and REST have standardized this. First of all, the identification of resources was standardized - a URL appeared (it’s funny to think that someone came up with a URL). One part of the address defines the protocol (HTTP), the other the path to the resource, and the third part defines the port. Everything on the Internet that is available for network requests can be identified using one of these URLs.
Manipulations with views
By manipulating representations means that you can request data in different formats. If you need a piece of data, you can get it as a CSV table, Excel file, text document, jpeg. These are all real representations of some basic results.
Self-descriptive messages
You should be able to understand what is happening on the network. HTTP has GET, PUT, POST, DELETE requests. They are descriptive: GET is an English word that means you want to get something. PUT means to put something, DELETE - to delete. You can view the network traffic in some intelligent debugging tool and see which requests were actually sent.
Hypermedia as a mechanism for managing application state
About this we talk more.
The last constraint Roy defined was the idea of creating code that would be provided to clients on demand. It implies that your server must be able to send data that includes code. The client can extract this code, disconnect from the server and run it later.
I have never seen the API that does it. I have seen many web applications: Google Docs Offline, Gmail, and many other single-page applications. I do not support the idea of getting run code from someone else's API for later launch on my system. But it's nice to know that there is the possibility of such a launch of operations on clients.
I came to the industry when the first web browsers that were not email clients were created. Then someone decided that you can run javascript, and now we can create a mail client in javascript and send it to the client so that it can run it in the browser.
The important thing is that Roy Fielding says bluntly: there are 6 limitations, and only one of them is optional.

If you build the system and solve the problems as described, the system will be RESTful. If you solve them differently - the system will not be RESTful. This does not mean that it is good or bad. The definition above says nothing about the quality of the system. However, it is very important that we agree on what constitutes a RESTful API by definition (according to the original source).
Let's see how these restrictions will look in real life, or rather, in the life of comic book characters. Let's try to write a social network code for superheroes in accordance with REST. It will be fun.

Here are some really interesting characters from comics (and movies from comics). Let's try to create a social network for them. But we don’t want to get bogged down in UI development, just as we don’t want to test JavaScript. So let's just create an API.
Here is our entry point:
in response, we get:
Let's create an endpoint called here "/ profiles", which will have two methods:
The method returns an array of JavaScript - JSON from the profiles of all superheroes who have joined the social network:
At the moment we are not worried about security, this question is beyond the scope of our conversation.
The second method is POST. By sending POST to / profiles, you give the payload as JSON.
Answer - a message about the successful creation of the profile and its address:
Let's place the description of the service and its API anywhere on the Internet, so that everyone knows how to use our system:

... and go for the weekend.
Returning on Monday, we find that the information about our service was sold online: someone put it on Reddit, tweeted it on Twitter, and we had two million users. Wow!
And suddenly the phone rings. We pick up the phone, and on the other end of the line, someone says: “Your API scored our entire channel!”. And then another call: "Your idiotic API overloads our database."
What is the problem here? What happened? Why are we all unhappy? Because in response to a request we send two million records. We have only one endpoint - / profiles. The only thing you can do with the API is to get or publish the data. And if you try to do this, you will receive 2 million records each time. Thus, every time someone tries to use our API, it gets megabytes of data. The network crashes, so does the database. The whole system does not scale.
What can we do about it? Let's take the end point and split it:
Next we can request page 2:
then page 3:
and so on:
It's very simple, and it works. I’m sure most of us can create a system that does this. And when we get “No Content”, it means that you have all the profiles of the system.
However, this is not REST. And the reason is that the API does not use hypermedia as an application state engine. When we get the first page, theoretically we can go from there to pages 2, 3. But there is nothing in the server’s response that tells us about this possibility.
What are we going to do about it?
Before giving the answer, let me remind you of one series of books from childhood.

These are the books in the Choose Your Adventure series. They existed before we learned what even an 8-bit computer is. The first page shows a part of the story, and at the end - the choice of what you want to do next.
As an example, I created a special text for our situation:

This is “Choose Your Adventure” especially for DOTNEXT in St. Petersburg.
“You had an AWESOME first day on DotNext in St. Petersburg. Now you are at the conference after the party. It was a busy day; maybe you should go to your room and sleep? But some people are going to order sushi. Or can you stay at the party and see how Eugene sings karaoke? ”
This content is the beginning of the story. And then we have hypermedia operations embedded in the results view:
“To go to your room and sleep, go to page 23,
To eat sushi, go to page 41,
To stay at the party and watch karaoke, go to page 52. "
This is hypermedia. Our result contains a hypermedia annotation describing how we can interact with the system.
Let's see how it actually looks in code. We will use the hal + json format for this. This is json with extra bits for hypermedia replication language. The reason I use it is because the format is rather short, so it’s easy to place on PowerPoint slides.
So instead of just returning an array, we're going to create a collection of items. We will return the payload (our content) inside the collection, as well as complement the results with links to other places where we can go (available state transitions implemented via hypermedia).
Enter the variable index - this is the page where you are. Total - the total number of entries in the collection.
Let's look at the code.
But first I want to warn you: you may notice some strange characters here. This is C #. I use FiraCode , which stands for the following:

Don't worry when you meet them. These are not funny little runes, these are mathematical symbols. I like them. FiraCode is an open source project. You can download it here .
For the demonstration, I will use a tool that I created to work with such things. It can be found in my GitHub repository (link at the beginning of the article).

This is just an explorer API tool running inside the browser. On the one hand, you have web browsers that do an excellent job with browsing, buying things on Amazon and Ebay. They all work very well with the API. On the other hand, we have tools, such as Callcommandline, or special ones, like Postman. They are well suited for performing a single request. But when you want to navigate the hypermedia system, you should not use them. My tool is somewhere between these two extremes: it works in a browser (it all works in JavaScript) and understands hypermedia.
We are going to use our API. Enter / profiles and click go.

In response, we receive a message about successful execution - 200 OK - and two million records (many thanks to the Internet who took each comic superhero and put it in a large spreadsheet; I just had to copy and upload it all for demonstration).
Let's see the code that provided such an answer.
The first demo is the asp.net Web API. I think that on DotNext most people are familiar with .NET and ASP.NET. And this is just a Web API, no big deal.
The code looks like this:
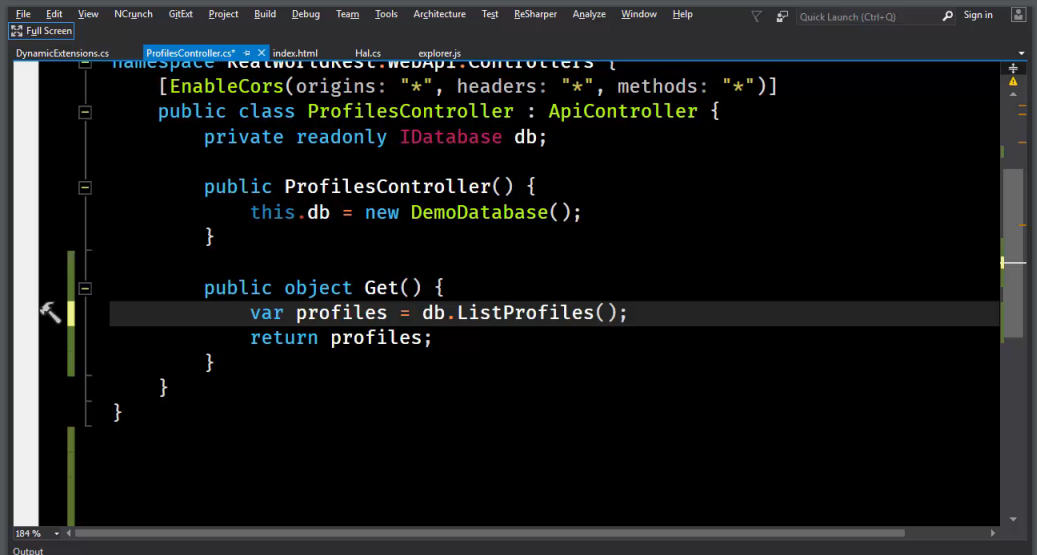
We have ProfilesController (which inherits ApiController). There is a database DemoDatabase (), as well as a public object Get (), which returns db.ListProfiles ().
How can we adapt this code to meet the requirement for hypermedia? Break the result into pages and give a link from one page to another.
The first thing we need to do is wrap our array into something. We cannot simply return data. One of the things in .NET that works well for this is the ability to create anonymous types. Subsequently, you can serialize them to get almost the same thing that they put. I think this is a really powerful tool. Anonymous types solve many problems if you try to transfer them between modules of the .NET code. But if you are just making a website, turn it straight into Json, serialize it, and then discard the unnecessary.
Here is what we get:
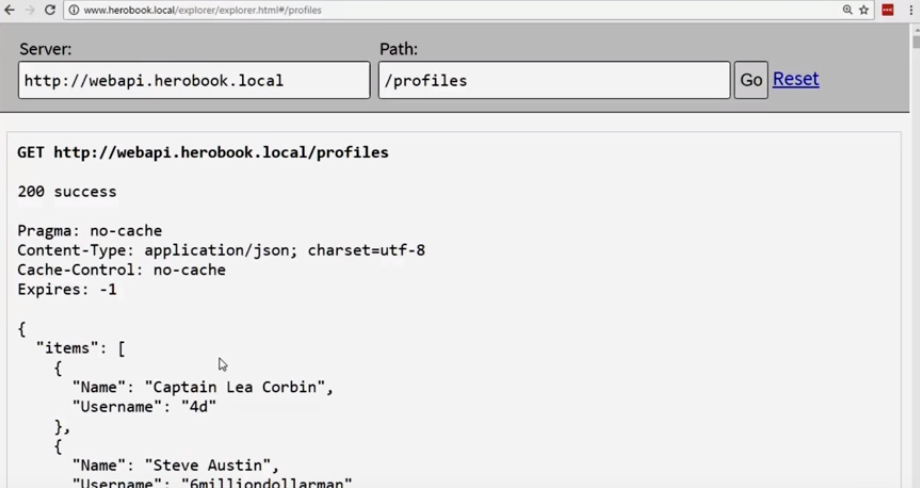
We still have two million entries, but now the array is located inside the JSON objects of JavaScript. This means that we have a place where we can integrate more functions.
The first thing we want to do is cut the output. Simply enter a constant denoting the number of results per page. It will be 10. And then we go to the database and say:
Now, when we turn to the database, it will give us only 10 profiles. Here is the full get () code:
We return to our tool and update the page. Instead of 2 million, we get 10 entries (this can be seen from the scroll bar).
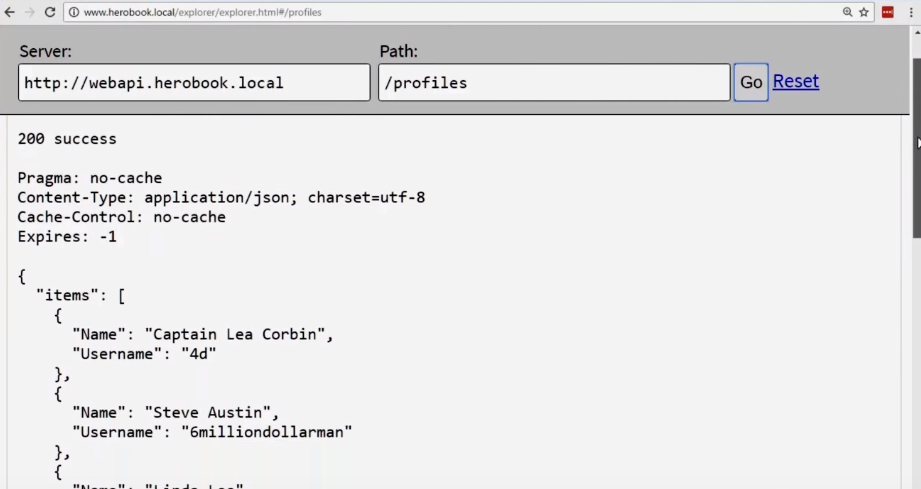
We solved the problem. Now the query / profiles will no longer cause the internet connection to fail.
The next thing we want to do is the links for the page request. Our API is smart enough to produce the right page.
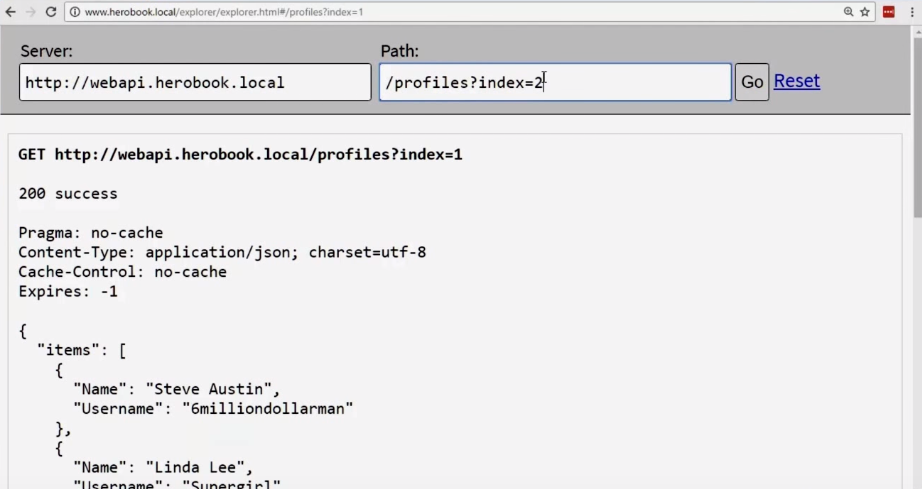
However, the user is not aware of this possibility, so for now this system does not comply with REST.
We need to go back to the code and fix something.
We have a result that is an anonymous type. Therefore, we can add to it everything that we like. In particular, links. Here we will use interpolation of C # strings:
Now, requesting profiles, we get not only the data itself, but also a collection of links.
Let's return to our API Explorer. Let's see what happens:
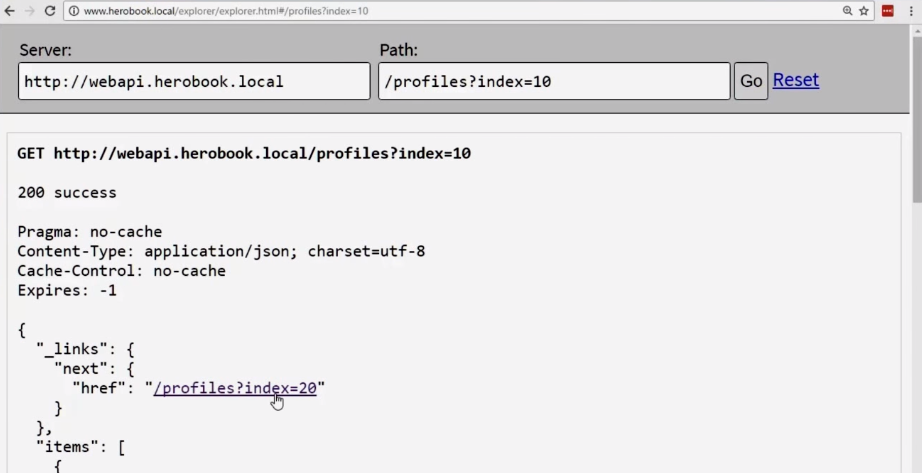
So we took the first steps towards what is called an hypermedia-enabled API.
We have page 0, and you can navigate through the pages.
But there are still some problems with the API. We need navigation: we must be able to move back and forth through the pages, and also move to the beginning or end of the list. While the API does not support this. In addition, when we reach the end of the collection, the system will begin returning empty arrays to us.
In order for the API to fully comply with the REST concept, we need to add a bit of logic to calculate where we can go from the current page.
For this, I use a small helper class.
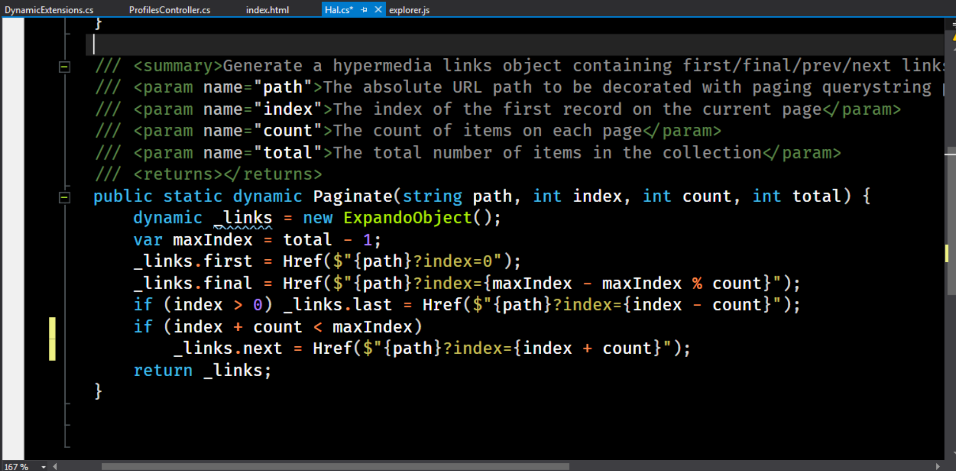
Here the static method returns a dynamic object. What is he doing? We give him the index of the current page, the number of elements on each page, as well as the total number of elements, and perform some calculations - we get the numbers of the first and last page. The first one will always be zero, the last one will always contain the profile with the maximum index in the collection. Further, for an index greater than zero, we can go back. However, we cannot go back, and if index - count is less than the minimum index; we can also go forward, but we cannot pass by the end.
The method returns links. Now back to our code, rewriting it as follows:
Run it:
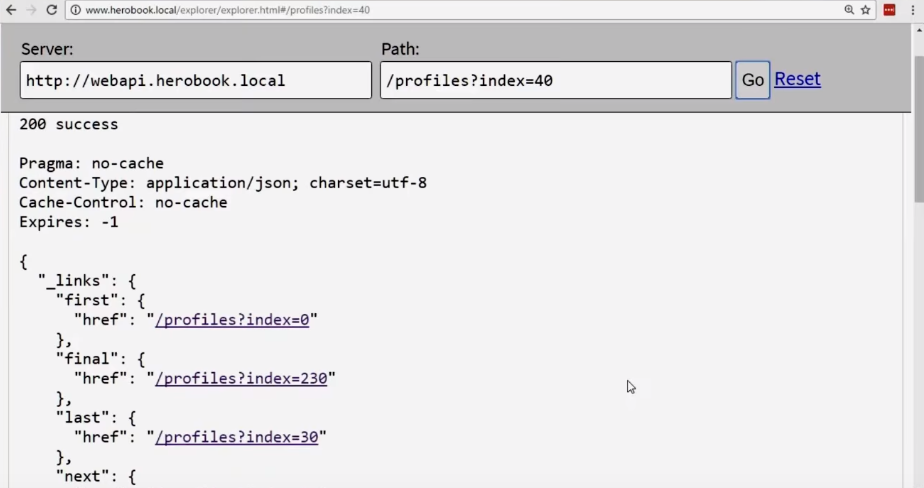
Now we have links to the first, last, next and previous pages. We can go forward or backward; The links available for the transition take into account whether you have reached the first or last page (you cannot go back from the first page, but go forward with the last page)
So we had 2 million social network posts. We broke the data into separate pages and then used hypermedia so that anyone who accesses the resource knows how it can navigate through the collection.
In social networks, people share information with their friends. They establish friendly relationships, and then publish updates: “Hey, look what I did this morning; look where I am. ”
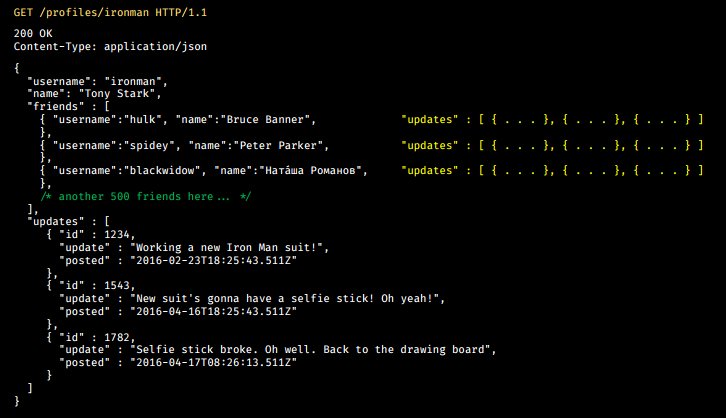
Suppose we have Iron Man - Tony Stark on the net. And he has Hulk, Spider-Man, Natasha Romanova as a friend.
Tony updates the status.
His first update: “Hey, I'm building a new suit of Iron Man,” the next is “I'm going to put a selfie stick on him, because the egoists are awesome, oh yeah.” And then he publishes another update: “The selfie stick broke. Returning to the drawing board, back to my lab. ”
Of course, his friends also have profiles. Therefore, each of these updates has a list of friends, and each of these friends has its own updates.
But friends have friends, and those have their own updates, etc.
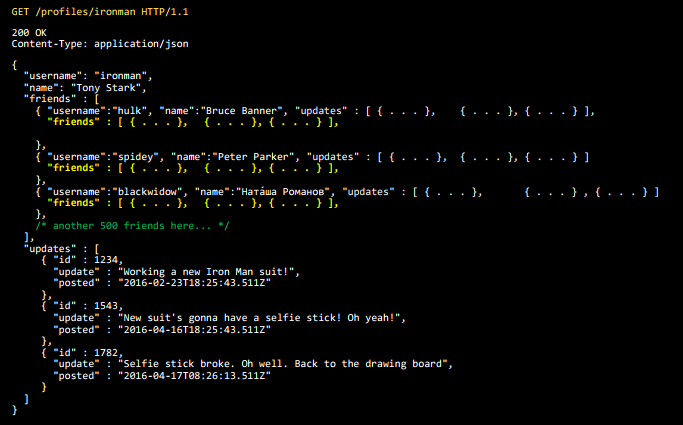
So we come to what is called Big Data.

Because Big Data is something too big for JSON to put this data on a PowerPoint slide. Let it be my definition.
We have implemented support for statuses and their updates. And then the phone rings: "Your API scored our entire channel ... again!", "Your API is overloading the database. Again! .. I said we needed to use PHP ... (you have never heard of such problems in PHP before, right?) "
How do we fix this? What will we do to solve this problem? We will again share our data. Instead of returning the entire graph associated with a particular entry, we will offer links. We have already discussed how to use links to move forward / backward. Now expand this idea.
self - points to the profile that you are looking at, because you can walk away from it along different routes and would like to be able to quickly return back (this is a common practice for such systems). You can also quickly access your friends, photos and updates - friends, photos and updates.
or
Let's also try to request a photo:
Someone left comments for this photo:
Let's request photo 1345:
And here, too, have someone's comments:
And the phone rings again: “I have to make 50 API calls just to issue 1 page ?? !!!”. “Our web server crashed due to the fact that IIS logs filled the C: drive (we never had such problems with PHP)” - indeed, this is one of the most common reasons for the drop in services.
What do we do?
We took a lot of data that caused problems, and we shared it. And now small data already causes other problems.
The so-called deployment of resources will help us in solving these problems. If you are familiar with something like ORM, then you know that during the loading process you can request a specific object and include another object there.
Deploying resources is a similar idea for hypermedia API. Thus, we can request the profile of Iron Man and deploy his updates.
I again want to make a demo version of the code showing how to implement this. For the second demo, we will actually use another server - Nancy.

The code that does this is the Nancy module:

We go to ProfileModules in our application. For those of you who have not worked with Nancy, I note that there is a great function here — a dictionary for each of the HTTP methods — GET, PUT, POST, DELETE.
We get an object with a dynamic argument that will include everything that matches the pattern of the route. Next is the method we need to call.

It takes the username, goes to db.loadProfile and returns the profile.
What do we want to do to add hypermedia? Add a selection of links here. But we cannot, because db.loadProfile pulls us back - we cannot add links to it for various corporate reasons. So we want to add links without changing the database.
I present the coolest piece of code I've ever received from Stackoverflow. Our problem will be solved by calling the ToDynamic method:
This is an extension method built into C #. It takes an object and then uses reflex. It wraps it in an Expandable object, which is the underlying dynamic type in C #. Next, we use reflection to get all the properties of the original object. For each of these properties, we go to the dictionary and add the name and value of the property to it. And then we return the extended object (dynamic).
Why do we need it? Take everything that we pulled out of the database and call ToDynamic on it. Now these objects are open because they are dynamic. We can use any additional classes and methods. All this will be allowed in runtime. We can put self, photos, updates.

Again, we are approaching the strongly typed development of corporate C # software from the other end, turning it into JSON. This is a very good example of using two different paradigms for modeling software systems.
So, what we get:


This is the first step: we have created this tool for hypermedia navigation. You can see Iron Man's best friend. But we did not implement the deployment.
We have come to the moment when the process of creating a REST system suddenly went beyond the specification.There is not a single RFC or other document that says how to implement resource deployment. There are many different approaches. But the problematic itself is important, not the actual code. Therefore, in our example, we will do the simplest thing that will work. I'm going to parse the incoming request string. Since we use Nancy, everything is dynamic until you wish otherwise.
We translate it into a string (since string is unnullable, it is safe). Next, I'm going to say: “If the string is not empty and contains friends, then we include more things in the dynamic profile”.

And now, switching back to the API Explorer, we see the results of the deployment:

and when we add expand = friends, the list of friends will be expanded.

Having such tasks, it is very easy to decide that you need to write a whole series of .NET base classes, C #, etc. But I want to point out that you don’t need to do so much. JavaScript is a dynamic language, and JSON is a dynamic data structure type. You can do a lot of things with them.
We now have an Iron Man profile. We have his friends, photos, updates. But we need to make some money.
To make money, we have to sell the data of our clients to large evil corporations, because social networks make it this way. But we are not doing this at the moment, because we do not have the data they need. We can add them. Ask:
In addition, you need to save the date of the last changes in order to have an idea about who is actually an active new user in our system and who is not.
We run the code in production, and the phone rings again: “The attempt to update the status of Tony Stark caused a conflict”:
This is because Tony Stark flies in his suit, and he has his Apple watch with GPS, so his latitude and longitude are constantly updated. And by the time you update the status, the data is outdated.
It is logical that you are unhappy: why do you have to push the entire profile into PUT, only to update the coordinates?
I used to mention that this happens when development goes beyond the specification. There are several different ways we can solve this problem. One of them is the implementation of the rule: if there is a PUT that contains only one filled element, you do not need to delete everything else. In this case, you can simply update one field:
It works. But the problem is that in this way it is very easy to destroy the rest of the data. And there is no way to set the difference between this PUT and PUT, which removes all other fields.
As a result:
Another approach that we can use is that we can make status an independent endpoint.
However, with this approach you will get a massive API. You will have a lot of end points. This means that you need a lot of hypermedia to explain to people which endpoints are available.
There is an alternative - the HTTP PATCH method. He is very cool and powerful, but poorly documented.
The PATCH method requests that the set of changes described in the request itself be applied to a resource identified as a Request URI. The change set is presented in a format called “patch document” (identified as a media type).
Those.if you want to change an object on the server, you can send a PATCH request.
How to describe the necessary changes? The documentation (here: “PATCH Method for HTTP” - http://tools.ietf.org/html/rfc5789 ) says that you should send a description of the changes. How to implement it? It depends on you.
And again the specification ends here. You are on your own. Therefore, you can offer your own agreements on how you make PATCH, and all of them will comply with the specification.
Here is one way to do this.
We are on a Linux workstation. We download, run it to get the patch file, and then download the raw patch.
Here we will use an alternative Content-type (x in this case means that this is an extended type).
This is understood by our server and our client. We can download JSON, determine the difference before and after, and send the delta.
There are amazing libraries that give you a much greater degree of control, for example, Json-patch. It allows you to describe a set of operations that will be applied to a particular resource.
Thus, we could implement, for example, such scenarios: replace status, then add a new user as a friend and move a new friend up the list.
The last thing we’ll look at today is our own variation on how to make an HTTP patch.
We are going to fix conferences / dotnext /
We use an alternative Content-Type - epic.selfie + png. In accordance with the standard, everything we do is describe the changes. We are going to make this photo and then describe the changes. And we will send it to the server, and the server will respond “202 accepted”. I think this answer should be replaced with a “challenge accepted”, because, in my opinion, DOTNEXT has really cool support.

If you liked this material from Dylan, at our November DotNext 2017 Moscow conference, he will touch on another interesting topic - Life, liberty and the pursuit of APIness . In this new report, he will tell you how to make your code leave smiles on users' faces.
Of course, Dylan will not be the only speaker. You will also be interested in:
A full list of speakers and a brief overview of their speeches are on our website .
Dylan is a systems architect and developer who has managed to participate in many projects in his life, from small websites to huge distributed systems; from Legacy with a twenty-year history to the latest developments. He now works as an architect in Spotlight and is engaged in solving complex problems in modern distributed systems. Creating the right, beautiful, and efficient HTTP API is part of his job, and he really knows a lot about them.
You will be able to meet with Dylan live at the DotNext Moscow 2017 conference, where he will arrive with a new report "Life, liberty and the pursuit of APIness: the secret to happy code . " We remind you that you can buy tickets at a tasty price until October 31 inclusive.
')
This article can either be read in the text interpretation (click the button "read more" ⇩), or see the full video of the report. All the images you need to understand, slides and diagrams are present both in the video and in the text decoding, so you won't lose anything.
Comments on the article are welcome and really important - we will try to ask your best questions directly to Dylan on DotNext Moscow 2017 .
Today we will talk about the ideology of REST in the real world and the practical embodiment of hypermedia.
But first, a little about me.
My name is Dylan Beattie. The best way to ask any questions about the report is to find me on twitter (@dylanbeattie). I have a VK page, but I don’t speak Russian, so I don’t have friends on this social network.
For a long time I have been creating websites. I created my first web page back in 1992, when the World Wide Web was one year old. In addition, I develop web applications.
Currently, I am a systems architect at Spotlight in London, which is working on various projects in the film industry - a very interesting direction.
My website: dylanbeattie.net . There I publish my notes on software architecture, REST and other such things. I also want to mention that the code from all the slides is on GitHub: github.com/dylanbeattie/dotnext/ . You can download it from there and test it yourself.
But let's talk about REST.
REST is a fairly well-known concept. Many have heard about it, many work with it. However, there is still a lot of confusion about what REST is, why this concept is important and how you can use it to solve your problems. Today we will look at the answers to some of these questions. But first of all, I will try to form a clear idea of which systems correspond to REST. Therefore, we start from the beginning - refer to the source.
This is Roy Fielding. Roy invented REST and determined what it is. There are many materials devoted to software and computing, which explains how everything works. The words used have different meanings for different people. But REST has a very clear definition, which we will discuss first.
Roy is now a senior research scientist at Adobe. He previously worked on Apache. In fact, he is one of the founders of the Apache web server project, and he was also one of the authors of HTTP, the underlying protocol that binds the World Wide Web together. In 2000, Roy published his thesis "Architectural styles and design of network software architectures." In this paper, he describes the styles of scalable software architecture on the web.
This is the very first point that needs to be understood. REST is not a framework or a library; it cannot be simply downloaded or installed. REST is a set of rules, restrictions, and guidelines for how you should solve the problems you encounter in your applications.
Abstracts Roy is very popular. They are worth seeing if you are interested in looking at the basics. In his work, I want to highlight a few maxims.
The first is a related set of architectural constraints; having a name, it becomes an architectural style . In his opinion, this question was influenced by architecture (in the context of construction), he thought a lot, including about architectural styles. Buildings are not distinguished from each other by a project, not by design - but by style: a set of individual peculiarities and limitations. And REST is like him. This is a set of patterns that you can apply to your systems.
I also find it very important that “ REST in software development has existed for decades. Every detail ensures the durability and independent evolution of software . ” REST is designed to create systems that will work for years and maybe decades. If next month you are expecting the end of financing, you probably should not create a system that complies with the REST postulates, because many of the limitations presented in this concept are directly opposed to short-term effectiveness.
It often happens that in a project you are working on there are two or more ways to solve a problem. And the path that leads to REST often takes more time. Along the way, you should think about a lot of things that may not be a problem for you and your company. So be very careful. Think about what exactly you are trying to achieve. If you are lucky to work on a system that will function for many years, in the framework of this article you will find many ideas that I hope will be useful to you.
If you build a prototype, conduct a lot of experiments to see if something will work, the situation is ambiguous. REST doesn't hurt - but some requirements may slow you down.
REST definition
Roy Fielding proposed the definition of REST - this is a coordinated set of architectural constraints.
Client server
First of all, according to him, the software system should be built to work on the client and on the server. I hope this doesn’t surprise anyone. Most of us, I think, have already created client-server applications - websites, email systems, FTP. Now it is very common.
I will not describe the details. Your server is somehow shared between clients, providing data storage, basic functions, and security — those things that you want to manage centrally.
One of the nice things about customers is that each one comes from a computer. Therefore, if you have calculations that you need to perform, you can distribute them to a large number of clients. In this way, customers provide data processing, presentation and user interaction.
The server serves several clients. And this is a big advantage. You can serve many thousands of users with the help of one server, if, of course, correctly design your system.
Do not store state
The second limitation relates to the rejection of state storage. In ASP.NET, PHP, ColdFusion, or classic ASP, you are confronted with the idea of a session. So you have a session cookie. But this idea no longer works. When you had something like ASP.NET and you ran one web server, it started to slow down a bit. Then you installed another web server, and in the end everything ceased to work due to the fact that each time a request was sent to the server, some storage space was allocated only for that client. Like that:
The server kept its status. At the same time comes the next person, who also has some kind of condition.
What happens when the server fills up and then one of the clients leaves? We do not know whether he will return, so we have to keep the state for a period of time. But what should be the session timeout? 5 minutes, 10 minutes, 24 hours? It is very difficult to determine. But the biggest problem is that if you run another server, which gives you even more options, and then one of the clients tries to switch from one server to another, the connection is interrupted, because the session information is stored in a different place.
Therefore, by avoiding state storage, you get more flexibility regarding how many clients you can service and how you can scale the system.
Caching
The third constraint that Roy defines is caching.
Suppose there is some resource on the server. The client requests it. If the same resource is required by the client again, he will not have to re-request it. He should be able to use what is already there.
When you perform a task on a server, you spend resources. You may be processing a video or photo. And all that costs resources, you need to reuse. This is the best you can do. You need to save the processing result so that anyone who ever returns and asks for the same data again can simply get the same resource.
Multi-level system
The following limitation is directly related to the idea of caching. This is the idea of multi-level systems. My favorite example of this idea is a caching proxy server between clients and the server.
Clients in this diagram on the left. Suppose these are different variants of smartphones - iPhone, Samsung, Android - anything. Proxy server - in the middle of the chain. Suppose it is managed by a certain large telecommunications company. As the owner of the server, you pay for the work of what is to the right of the proxy. After all, when a request comes from the client, the server performs some calculations. And it costs money - electricity, equipment depreciation, etc.
If the telecommunications company saves a copy of the results, the next time someone requests information, he will receive a proxy copy. You will not need to spend money on the execution of the request. Thus, the idea of caching on a proxy is incredibly good, because it allows other people to pay to make your software faster without additional investments.
Even in the framework of the idea of a multi-level system, you can add more intermediate levels. In multi-tier systems, servers and clients do not care about what levels the request passes through.
In this example, the clients interact with the proxy server. The proxy thinks that it interacts with the server, but in fact it sends requests for a security level (for example, a firewall). That, in turn, believes that it communicates with the server, it actually sends requests to the load balancer.
The load balancer believes that it interacts with the server, but in fact it is about five servers. We can deploy new ones, close old ones, and thanks to the load balancer, this does not affect other levels.
The concept of multi-level systems gives you tremendous flexibility when planning applications.
Single interface
Resource identification
Before the advent of HTTP and REST, if you wanted to get some information from the server, you had to choose one of several dozen protocols - Gopher, FTP, Telnet, etc. All these were different systems, and each meant its own way of interacting with remote information and remote services.
HTTP and REST have standardized this. First of all, the identification of resources was standardized - a URL appeared (it’s funny to think that someone came up with a URL). One part of the address defines the protocol (HTTP), the other the path to the resource, and the third part defines the port. Everything on the Internet that is available for network requests can be identified using one of these URLs.
Manipulations with views
By manipulating representations means that you can request data in different formats. If you need a piece of data, you can get it as a CSV table, Excel file, text document, jpeg. These are all real representations of some basic results.
Self-descriptive messages
You should be able to understand what is happening on the network. HTTP has GET, PUT, POST, DELETE requests. They are descriptive: GET is an English word that means you want to get something. PUT means to put something, DELETE - to delete. You can view the network traffic in some intelligent debugging tool and see which requests were actually sent.
Hypermedia as a mechanism for managing application state
About this we talk more.
Encoding on request
The last constraint Roy defined was the idea of creating code that would be provided to clients on demand. It implies that your server must be able to send data that includes code. The client can extract this code, disconnect from the server and run it later.
I have never seen the API that does it. I have seen many web applications: Google Docs Offline, Gmail, and many other single-page applications. I do not support the idea of getting run code from someone else's API for later launch on my system. But it's nice to know that there is the possibility of such a launch of operations on clients.
I came to the industry when the first web browsers that were not email clients were created. Then someone decided that you can run javascript, and now we can create a mail client in javascript and send it to the client so that it can run it in the browser.
Binding constraints
The important thing is that Roy Fielding says bluntly: there are 6 limitations, and only one of them is optional.
If you build the system and solve the problems as described, the system will be RESTful. If you solve them differently - the system will not be RESTful. This does not mean that it is good or bad. The definition above says nothing about the quality of the system. However, it is very important that we agree on what constitutes a RESTful API by definition (according to the original source).
Let's see how these restrictions will look in real life, or rather, in the life of comic book characters. Let's try to write a social network code for superheroes in accordance with REST. It will be fun.
REST in practice
Here are some really interesting characters from comics (and movies from comics). Let's try to create a social network for them. But we don’t want to get bogged down in UI development, just as we don’t want to test JavaScript. So let's just create an API.
Here is our entry point:
GET / HTTP/1.1 in response, we get:
200 OK Content-Type: application/json { "message": "Welcome to Herobook!" } Let's create an endpoint called here "/ profiles", which will have two methods:
GET /profiles HTTP/1.1 The method returns an array of JavaScript - JSON from the profiles of all superheroes who have joined the social network:
200 OK Content -Type: application/json [ { "username": "ironman", "name": "Tony Stark", } ] At the moment we are not worried about security, this question is beyond the scope of our conversation.
The second method is POST. By sending POST to / profiles, you give the payload as JSON.
POST /profiles HTTP/1.1 { "username" : "blackwidow" "name": " ", } Answer - a message about the successful creation of the profile and its address:
201 Created Location: http://api.herobook.local/profiles/blackwidow { "username": "blackwidow", "name": " " } Let's place the description of the service and its API anywhere on the Internet, so that everyone knows how to use our system:
... and go for the weekend.
Returning on Monday, we find that the information about our service was sold online: someone put it on Reddit, tweeted it on Twitter, and we had two million users. Wow!
GET /profiles HTTP/1.1 200 OK { "_links" : { … }, "items" : { { "username":"ironman", "name":"Tony Stark" } { "username":"blackwidow", "name":" " }, { "username":"spidey", "name":"Peter Parker" }, { /* +2 million users! Wow! */ }, { "username":"ducky", "name":"Howard the Duck" } } ] And suddenly the phone rings. We pick up the phone, and on the other end of the line, someone says: “Your API scored our entire channel!”. And then another call: "Your idiotic API overloads our database."
What is the problem here? What happened? Why are we all unhappy? Because in response to a request we send two million records. We have only one endpoint - / profiles. The only thing you can do with the API is to get or publish the data. And if you try to do this, you will receive 2 million records each time. Thus, every time someone tries to use our API, it gets megabytes of data. The network crashes, so does the database. The whole system does not scale.
What can we do about it? Let's take the end point and split it:
GET /profiles<b>?page=1</b> HTTP/1.1 200 OK { "_links" : { … }, "items" : [ { "username":"ironman", "name":"Tony Stark" } { "username":"spidey", "name":"Peter Parker" }, { "username":"blackwidow", "name": " " }, { "username":"cap", "name":"Steve Rogers" }, { "username":"storm", "name":"Ororo Munroe" } ] } Next we can request page 2:
GET /profiles<b>?page=2</b> HTTP/1.1 200 OK then page 3:
GET /profiles<b>?page=3</b> HTTP/1.1 200 OK and so on:
GET /profiles?page=4 HTTP/1.1 200 OK GET /profiles?page=5 HTTP/1.1 204 No Content It's very simple, and it works. I’m sure most of us can create a system that does this. And when we get “No Content”, it means that you have all the profiles of the system.
However, this is not REST. And the reason is that the API does not use hypermedia as an application state engine. When we get the first page, theoretically we can go from there to pages 2, 3. But there is nothing in the server’s response that tells us about this possibility.
What are we going to do about it?
Before giving the answer, let me remind you of one series of books from childhood.
These are the books in the Choose Your Adventure series. They existed before we learned what even an 8-bit computer is. The first page shows a part of the story, and at the end - the choice of what you want to do next.
As an example, I created a special text for our situation:
This is “Choose Your Adventure” especially for DOTNEXT in St. Petersburg.
“You had an AWESOME first day on DotNext in St. Petersburg. Now you are at the conference after the party. It was a busy day; maybe you should go to your room and sleep? But some people are going to order sushi. Or can you stay at the party and see how Eugene sings karaoke? ”
This content is the beginning of the story. And then we have hypermedia operations embedded in the results view:
“To go to your room and sleep, go to page 23,
To eat sushi, go to page 41,
To stay at the party and watch karaoke, go to page 52. "
This is hypermedia. Our result contains a hypermedia annotation describing how we can interact with the system.
Let's see how it actually looks in code. We will use the hal + json format for this. This is json with extra bits for hypermedia replication language. The reason I use it is because the format is rather short, so it’s easy to place on PowerPoint slides.
So instead of just returning an array, we're going to create a collection of items. We will return the payload (our content) inside the collection, as well as complement the results with links to other places where we can go (available state transitions implemented via hypermedia).
Enter the variable index - this is the page where you are. Total - the total number of entries in the collection.
GET /profiles HTTP/1.1 200 OK Content -Type: application/hal+json { "_links" : { "self" : { "href" : "http://herobook/profiles?index=0" }, "next" : { "href" : "http://herobook/profiles?index=5" }, "last" : { "href" : "http://herobook/profiles?index=220" } }, "count" :5, "index" :0, "total" : 223, "items:" [ { "username":"ironman", "name":"Tony Stark" } { "username":"spidey", "name":"Peter Parker" }, { "username":"blackwidow", "name":"́ " }, { "username":"pepper", "name":"Pepper Potts" }, { "username":"storm", "name":"Ororo Munroe" } ] } Let's look at the code.
But first I want to warn you: you may notice some strange characters here. This is C #. I use FiraCode , which stands for the following:
Don't worry when you meet them. These are not funny little runes, these are mathematical symbols. I like them. FiraCode is an open source project. You can download it here .
For the demonstration, I will use a tool that I created to work with such things. It can be found in my GitHub repository (link at the beginning of the article).
This is just an explorer API tool running inside the browser. On the one hand, you have web browsers that do an excellent job with browsing, buying things on Amazon and Ebay. They all work very well with the API. On the other hand, we have tools, such as Callcommandline, or special ones, like Postman. They are well suited for performing a single request. But when you want to navigate the hypermedia system, you should not use them. My tool is somewhere between these two extremes: it works in a browser (it all works in JavaScript) and understands hypermedia.
We are going to use our API. Enter / profiles and click go.
In response, we receive a message about successful execution - 200 OK - and two million records (many thanks to the Internet who took each comic superhero and put it in a large spreadsheet; I just had to copy and upload it all for demonstration).
Let's see the code that provided such an answer.
Web API
The first demo is the asp.net Web API. I think that on DotNext most people are familiar with .NET and ASP.NET. And this is just a Web API, no big deal.
The code looks like this:
We have ProfilesController (which inherits ApiController). There is a database DemoDatabase (), as well as a public object Get (), which returns db.ListProfiles ().
How can we adapt this code to meet the requirement for hypermedia? Break the result into pages and give a link from one page to another.
The first thing we need to do is wrap our array into something. We cannot simply return data. One of the things in .NET that works well for this is the ability to create anonymous types. Subsequently, you can serialize them to get almost the same thing that they put. I think this is a really powerful tool. Anonymous types solve many problems if you try to transfer them between modules of the .NET code. But if you are just making a website, turn it straight into Json, serialize it, and then discard the unnecessary.
public object Get() { var profiles = db.ListProfiles(); var result = new { items = profiles }; return result; } Here is what we get:
We still have two million entries, but now the array is located inside the JSON objects of JavaScript. This means that we have a place where we can integrate more functions.
The first thing we want to do is cut the output. Simply enter a constant denoting the number of results per page. It will be 10. And then we go to the database and say:
profiles = db.ListProfiles().Take(REULTS_PER_PAGE) Now, when we turn to the database, it will give us only 10 profiles. Here is the full get () code:
<code>public object Get() { var RESULTS_PER_PAGE = 10; var profiles = db.ListProfiles().Take(RESULTS_PER_PAGE) var result = new { items = profiles }; return result; } We return to our tool and update the page. Instead of 2 million, we get 10 entries (this can be seen from the scroll bar).
We solved the problem. Now the query / profiles will no longer cause the internet connection to fail.
The next thing we want to do is the links for the page request. Our API is smart enough to produce the right page.
However, the user is not aware of this possibility, so for now this system does not comply with REST.
We need to go back to the code and fix something.
We have a result that is an anonymous type. Therefore, we can add to it everything that we like. In particular, links. Here we will use interpolation of C # strings:
var result = new { _links = new { next = new { href = $"/profiles?index={index+RESULTS_PER_PAGE}" } }, items = profiles }; return result; Now, requesting profiles, we get not only the data itself, but also a collection of links.
Let's return to our API Explorer. Let's see what happens:
So we took the first steps towards what is called an hypermedia-enabled API.
We have page 0, and you can navigate through the pages.
But there are still some problems with the API. We need navigation: we must be able to move back and forth through the pages, and also move to the beginning or end of the list. While the API does not support this. In addition, when we reach the end of the collection, the system will begin returning empty arrays to us.
In order for the API to fully comply with the REST concept, we need to add a bit of logic to calculate where we can go from the current page.
For this, I use a small helper class.
Here the static method returns a dynamic object. What is he doing? We give him the index of the current page, the number of elements on each page, as well as the total number of elements, and perform some calculations - we get the numbers of the first and last page. The first one will always be zero, the last one will always contain the profile with the maximum index in the collection. Further, for an index greater than zero, we can go back. However, we cannot go back, and if index - count is less than the minimum index; we can also go forward, but we cannot pass by the end.
The method returns links. Now back to our code, rewriting it as follows:
public object Get(index = 0) { var RESULTS_PER_PAGE = 10; var profiles = db.ListProfiles() .Skip(index) .Take(RESULTS_PER_PAGE); var total = db.CountProfiles(); var result = new { _links = Hal.Paginate("/profiles", index, RESULTS_PER_PAGE, total), items = profiles }; return result; } Run it:
Now we have links to the first, last, next and previous pages. We can go forward or backward; The links available for the transition take into account whether you have reached the first or last page (you cannot go back from the first page, but go forward with the last page)
So we had 2 million social network posts. We broke the data into separate pages and then used hypermedia so that anyone who accesses the resource knows how it can navigate through the collection.
Deploying resources
In social networks, people share information with their friends. They establish friendly relationships, and then publish updates: “Hey, look what I did this morning; look where I am. ”
Suppose we have Iron Man - Tony Stark on the net. And he has Hulk, Spider-Man, Natasha Romanova as a friend.
Tony updates the status.
GET /profiles/ironman HTTP/1.1 200 OK Content-Type: application/json { "username": "ironman", "name": "Tony Stark", "friends" : [ { "username":"hulk", "name":"Bruce Banner" }, { "username":"spidey", "name":"Peter Parker" }, { "username":"blackwidow", "name":"́ " }, /* another 500 friends here... */ ] "updates" : [ { "id" : 1234, "update" : "Working a new Iron Man suit!", "posted" : "2016-02-23T18:25:43.511Z"}, { "id" : 1543, "update" : "New suit's gonna have a selfie stick! Oh yeah!", "posted" : "2016-04-16T18:25:43.511Z"}, { "id" : 1782, "update" : "Selfie stick broke. Oh well. Back to the drawing board", "posted" : "2016-04-17T08:26:13.511Z"} ] } His first update: “Hey, I'm building a new suit of Iron Man,” the next is “I'm going to put a selfie stick on him, because the egoists are awesome, oh yeah.” And then he publishes another update: “The selfie stick broke. Returning to the drawing board, back to my lab. ”
Of course, his friends also have profiles. Therefore, each of these updates has a list of friends, and each of these friends has its own updates.
But friends have friends, and those have their own updates, etc.
So we come to what is called Big Data.
Because Big Data is something too big for JSON to put this data on a PowerPoint slide. Let it be my definition.
We have implemented support for statuses and their updates. And then the phone rings: "Your API scored our entire channel ... again!", "Your API is overloading the database. Again! .. I said we needed to use PHP ... (you have never heard of such problems in PHP before, right?) "
How do we fix this? What will we do to solve this problem? We will again share our data. Instead of returning the entire graph associated with a particular entry, we will offer links. We have already discussed how to use links to move forward / backward. Now expand this idea.
GET /profiles/ironman HTTP/1.1 200 OK Content-Type: application/hal+json { "_links": { "self": { "href" "/profiles/ironman" }, "friends": { "href" : "/profiles/ironman/friends" }, "photos": { "href" : "/profiles/ironman/photos" }, "updates": { "href" : "/profiles/ironman/updates" } }, "username" : "ironman", "name" : "Tony Stark" } self - points to the profile that you are looking at, because you can walk away from it along different routes and would like to be able to quickly return back (this is a common practice for such systems). You can also quickly access your friends, photos and updates - friends, photos and updates.
GET /profiles/ironman HTTP/1.1 200 OK or
GET /profiles/ironman/friends HTTP/1.1 200 OK GET /profiles/ironman/updates HTTP/1.1 200 OK GET /profiles/ironman/photos HTTP/1.1 200 OK Let's also try to request a photo:
GET /profiles/ironman/photos/1234 HTTP/1.1 200 OK Someone left comments for this photo:
GET /profiles/ironman/photos/1234/comments HTTP/1.1 200 OK Let's request photo 1345:
GET /profiles/ironman/photos/1345 HTTP/1.1 200 OK And here, too, have someone's comments:
GET /profiles/ironman/photos/1345/comments HTTP/1.1 200 OK GET /profiles/ironman/photos/1456 HTTP/1.1 200 OK GET /profiles/ironman/photos/1456/comments HTTP/1.1 200 OK And the phone rings again: “I have to make 50 API calls just to issue 1 page ?? !!!”. “Our web server crashed due to the fact that IIS logs filled the C: drive (we never had such problems with PHP)” - indeed, this is one of the most common reasons for the drop in services.
What do we do?
We took a lot of data that caused problems, and we shared it. And now small data already causes other problems.
The so-called deployment of resources will help us in solving these problems. If you are familiar with something like ORM, then you know that during the loading process you can request a specific object and include another object there.
Deploying resources is a similar idea for hypermedia API. Thus, we can request the profile of Iron Man and deploy his updates.
GET /profiles/ironman?expand=updates HTTP/1.1 200 OK Content-Type: application/json { "_links": { "self" : { "href": "/profiles/ironman" }, "friends" : { "href": "/profiles/ironman/friends" }, "photos" : { "href": "/profiles/ironman/photos" }, "updates" : { "href": "/profiles/ironman/updates" } }, "username" : "ironman", "name" : "Tony Stark" "_embedded" : { "updates" : [ { "update" : "Working a new Iron Man suit – with a built-in selfie stick!", "posted" : "2016-02-23T18:25:43.511Z" }, { "update" : "Selfie stick broke. Oh well. Back to the drawing board", "posted" : "2016-04-17T08:26:13.511Z" } ] } } I again want to make a demo version of the code showing how to implement this. For the second demo, we will actually use another server - Nancy.
The code that does this is the Nancy module:
We go to ProfileModules in our application. For those of you who have not worked with Nancy, I note that there is a great function here — a dictionary for each of the HTTP methods — GET, PUT, POST, DELETE.
We get an object with a dynamic argument that will include everything that matches the pattern of the route. Next is the method we need to call.
It takes the username, goes to db.loadProfile and returns the profile.
What do we want to do to add hypermedia? Add a selection of links here. But we cannot, because db.loadProfile pulls us back - we cannot add links to it for various corporate reasons. So we want to add links without changing the database.
I present the coolest piece of code I've ever received from Stackoverflow. Our problem will be solved by calling the ToDynamic method:
using System.Collections.Generic; using System.ComponentModel; using System.Dynamic; using System.Linq; namespace RealWorldRest.NancyFX.Modules { public static class ObjectExtensions { public static dynamic ToDynamic(this object value) { IDictionary<string, object> expando = new ExpandoObject(); var properties = TypeDescriptor.GetProperties(value.GetType()); foreach (PropertyDescriptor property in properties) { expando.Add(property.Name, property.GetValue(value)); } return (ExpandoObject)expando; } public static IDictionary<string, object> ToDictionary(this object d) { return d.GetType().GetProperties() .ToDictionary(x => x.Name, x => x.GetValue(d, null)); } } } This is an extension method built into C #. It takes an object and then uses reflex. It wraps it in an Expandable object, which is the underlying dynamic type in C #. Next, we use reflection to get all the properties of the original object. For each of these properties, we go to the dictionary and add the name and value of the property to it. And then we return the extended object (dynamic).
Why do we need it? Take everything that we pulled out of the database and call ToDynamic on it. Now these objects are open because they are dynamic. We can use any additional classes and methods. All this will be allowed in runtime. We can put self, photos, updates.
Again, we are approaching the strongly typed development of corporate C # software from the other end, turning it into JSON. This is a very good example of using two different paradigms for modeling software systems.
So, what we get:
This is the first step: we have created this tool for hypermedia navigation. You can see Iron Man's best friend. But we did not implement the deployment.
We have come to the moment when the process of creating a REST system suddenly went beyond the specification.There is not a single RFC or other document that says how to implement resource deployment. There are many different approaches. But the problematic itself is important, not the actual code. Therefore, in our example, we will do the simplest thing that will work. I'm going to parse the incoming request string. Since we use Nancy, everything is dynamic until you wish otherwise.
We translate it into a string (since string is unnullable, it is safe). Next, I'm going to say: “If the string is not empty and contains friends, then we include more things in the dynamic profile”.
And now, switching back to the API Explorer, we see the results of the deployment:
and when we add expand = friends, the list of friends will be expanded.
Having such tasks, it is very easy to decide that you need to write a whole series of .NET base classes, C #, etc. But I want to point out that you don’t need to do so much. JavaScript is a dynamic language, and JSON is a dynamic data structure type. You can do a lot of things with them.
We now have an Iron Man profile. We have his friends, photos, updates. But we need to make some money.
GET /profiles/ironman HTTP/1.1 200 OK Content-Type: application/json { "_links": { "self" : { "href": "/profiles/ironman" }, "friends" : { "href": "/profiles/ironman/friends" }, "photos" : { "href": "/profiles/ironman/photos" }, "updates" : { "href": "/profiles/ironman/updates" } }, "name": "Tony Stark", "username": "ironman", To make money, we have to sell the data of our clients to large evil corporations, because social networks make it this way. But we are not doing this at the moment, because we do not have the data they need. We can add them. Ask:
- how much do you weigh? - We will try to sell you diet programs;
- Where are you? where do you live? What is your location right now?
- what are you doing?
- What is your status?
- where are you from? What is your hometown?
- What's your e-mail address?
- Do you have a website?
In addition, you need to save the date of the last changes in order to have an idea about who is actually an active new user in our system and who is not.
GET /profiles/ironman HTTP/1.1 200 OK Content-Type: application/json { "_links": { "self" : { "href": "/profiles/ironman" }, "friends" : { "href": "/profiles/ironman/friends" }, "photos" : { "href": "/profiles/ironman/photos" }, "updates" : { "href": "/profiles/ironman/updates" } }, "name": "Tony Stark", "username": "ironman", "height": 192, "weight": 85, "location": { "latitude": 59.93, "longitude": 30.33 }, "status": "Out saving the world. Again.", "hometown": "Malibu, USA" "email": "tony@stark.com", "website": "//w.ironman.com", "last_modified" : "2015-08-12T19:45:43.511Z" } We run the code in production, and the phone rings again: “The attempt to update the status of Tony Stark caused a conflict”:
PUT /profiles/ironman HTTP/1.1 Content-Type: application/json { "name": "Tony Stark", "username": "ironman", "height": 192, "weight": 85, "location": { "lat": 34.02, "lon": -118.77 }, "status" : "Just got back from saving the world. Again.", "hometown": "Malibu, USA" "email": "<a href="mailto:tony@stark.com">tony@stark.com</a>", "website": "//w.ironman.com", "birthdate": "1972-01-24" } 409 Conflict This is because Tony Stark flies in his suit, and he has his Apple watch with GPS, so his latitude and longitude are constantly updated. And by the time you update the status, the data is outdated.
It is logical that you are unhappy: why do you have to push the entire profile into PUT, only to update the coordinates?
I used to mention that this happens when development goes beyond the specification. There are several different ways we can solve this problem. One of them is the implementation of the rule: if there is a PUT that contains only one filled element, you do not need to delete everything else. In this case, you can simply update one field:
PUT /profiles/ironman HTTP/1.1 Content-Type: application/json { "status" : "Thinking about a disco Iron Man suit." /* : JSON // } It works. But the problem is that in this way it is very easy to destroy the rest of the data. And there is no way to set the difference between this PUT and PUT, which removes all other fields.
As a result:
204 No Content Another approach that we can use is that we can make status an independent endpoint.
PUT /profiles/ironman/status HTTP/1.1 "Finished saving the world. I need a drink." 204 No Content However, with this approach you will get a massive API. You will have a lot of end points. This means that you need a lot of hypermedia to explain to people which endpoints are available.
There is an alternative - the HTTP PATCH method. He is very cool and powerful, but poorly documented.
The PATCH method requests that the set of changes described in the request itself be applied to a resource identified as a Request URI. The change set is presented in a format called “patch document” (identified as a media type).
Those.if you want to change an object on the server, you can send a PATCH request.
How to describe the necessary changes? The documentation (here: “PATCH Method for HTTP” - http://tools.ietf.org/html/rfc5789 ) says that you should send a description of the changes. How to implement it? It depends on you.
PATCH /file.txt HTTP/1.1 Host: //w.example.com Content-Type: application/example If-Match: "e0023aa4e" Content-Length: 100 [description of changes] And again the specification ends here. You are on your own. Therefore, you can offer your own agreements on how you make PATCH, and all of them will comply with the specification.
Here is one way to do this.
We are on a Linux workstation. We download, run it to get the patch file, and then download the raw patch.
Here we will use an alternative Content-type (x in this case means that this is an extended type).
This is understood by our server and our client. We can download JSON, determine the difference before and after, and send the delta.
PATCH /profiles/ironman HTTP/1.1 Content-Type: application/x-unix-diff 11c11 < "status": "Just got home from saving the world.", --- > "status": "World saved. I need a drink.", 200 OK There are amazing libraries that give you a much greater degree of control, for example, Json-patch. It allows you to describe a set of operations that will be applied to a particular resource.
PATCH /profiles/ironman HTTP/1.1 Content-Type: application/json-patch+json If-Match: "abc123" [ { "op": "replace", "path": "/status", "value": "Finished saving the world. I need a drink." }, { "op": "move", "from": "/friends/hulk", "path": "/friends[0]" } ] 200 OK Thus, we could implement, for example, such scenarios: replace status, then add a new user as a friend and move a new friend up the list.
The last thing we’ll look at today is our own variation on how to make an HTTP patch.
We are going to fix conferences / dotnext /
PATCH /conferences/dotnext HTTP/1.1 Content-Type: image/epic.selfie+png We use an alternative Content-Type - epic.selfie + png. In accordance with the standard, everything we do is describe the changes. We are going to make this photo and then describe the changes. And we will send it to the server, and the server will respond “202 accepted”. I think this answer should be replaced with a “challenge accepted”, because, in my opinion, DOTNEXT has really cool support.
If you liked this material from Dylan, at our November DotNext 2017 Moscow conference, he will touch on another interesting topic - Life, liberty and the pursuit of APIness . In this new report, he will tell you how to make your code leave smiles on users' faces.
Of course, Dylan will not be the only speaker. You will also be interested in:
- Hardcore Debugging and Profiling Report by .NET Core Apps on Linux by Sasha Goldstein;
- an easy, but no less interesting story about Artificial Intelligence and neural networks for .NET developers from Dmitry Soshnikov;
- practical and technical immersion in metrics The Metrix has you ... by Anatoly Kulakov.
A full list of speakers and a brief overview of their speeches are on our website .
Source: https://habr.com/ru/post/340932/
All Articles