Optimization of Viola and Jones method for Elbrus platform
 The method (algorithm) of Viola and Jones [1] is one of the ways to identify the boundaries of objects in an image. Although the algorithm developed by P. Viola and M. Jones back in 2001, was originally focused on a quick search for faces in images, now various variations of this popular algorithm are successfully used in various problems of searching for boundaries:
The method (algorithm) of Viola and Jones [1] is one of the ways to identify the boundaries of objects in an image. Although the algorithm developed by P. Viola and M. Jones back in 2001, was originally focused on a quick search for faces in images, now various variations of this popular algorithm are successfully used in various problems of searching for boundaries:
- images of pedestrians [2],
- car images [3],
- road signs images [4],
as well as other objects present in the images from approximately the same angle. This kind of popularity of modifications of the method of Viola and Jones is explained by the high accuracy of the search for objects and high resistance to both geometric distortions and brightness changes.
Description of the method of Viola and Jones
The Viola and Jones algorithm reduces the task of detecting objects in an image to the problem of binary classification at each point of the image. The method was based on the "sliding window" technique. For each rectangular region of an image taken with various shifts and scales, with the help of a previously trained classifier (detector) the hypothesis of the presence or absence of a search object in a given region should be tested. A complete study of all regions leads to hundreds of thousands of classifier launches in a single image. That is why the classifier has two stringent requirements: high performance and a small number of false positives.
In this paper, Viola and Jones described a classifier for a human face. The training sample consisted of 4,916 images of faces scaled to 24x24 pixels ( positive sample ) and 9,500 full-size images in which there were no faces and from which areas that did not contain faces ( negative sample ) were randomly extracted.
To construct the feature space, Haar features were chosen, informative for characteristic brightness variations. Haar signs are easily calculated using the integral representation of the image. It turned out that for images with sizes of 24x24, the number of configurations of one feature is 45396.
In the Viola and Jones method, the AdaBoost algorithm [5] was applied, which simultaneously allows the selection of the most informative features and the construction of a binary classifier. For this, the authors associated with each attribute a weak classifier representing a single-level decision tree, which are then fed to the AdaBoost algorithm.
A necessary part of the Viola and Jones method is the procedure of combining the constructed strong classifiers, which can significantly increase the productivity of the face detection process by localizing those regions of the image under study that could contain images of faces.
As noted above, in the Viola and Jones algorithm, when teaching classifiers, the Haar family of attributes, dating back to the Haar wavelets, is used to describe objects [6]. This choice is primarily due to the fact that the signs of Haar allow us to adequately describe the characteristic features of the detected objects related to the brightness differences. The signs of Haar allow us to see that the image of a person’s face is darker than the area of the nose (Fig. 1d). In the described algorithm, three classes of features were involved: 2-rectangular signs (Figure 1a), 3-rectangular signs (Figure 1b) and 4-rectangular signs (Figure 1c).
The value of each sign of the Haar was equal to the difference of the sums of pixels of image areas inside black and white rectangles of equal size. 2-rectangular and 3-rectangular signs of the Haar can be oriented vertically (see figure 1) or horizontally. To quickly calculate the signs of Haar, an integral image representation is used [7].
In the AdaBoost algorithm, when learning the method of Viola and Jones, as weak classifiers, recognition trees with one branch and two leaves are used (called the decision stump and comparing the value of the corresponding attribute with the threshold value). The formally weak classifier b j ( x ), based on the attribute f j , the threshold θ j and the parity p j is defined as:
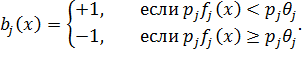
Such a set of weak classifiers along with the training sample is fed to the input of the AdaBoost algorithm.

Figure 1 - Rectangular signs of Haar used in training
classifier: a) 2-rectangular sign; b) 3-rectangular feature;
c) 4-rectangular feature; d) example of the location of the sign
regarding the scanning window (source [7])
The cascade classifier ( cascade ) is created under the assumption that for any examined image the number of "positive" areas that do not contain the search object exceeds by several orders the number of areas containing this object ("negative" areas). To improve the performance of the object detector, it is useful to abandon the negative image areas as soon as possible. Or the number of signs for the analysis of negative areas should be substantially less than the number of signs calculated for positive areas.
Each image area that is analyzed for the presence of the search object is fed to the input of an ordered sequence of classifiers, called cascade levels . As you progress through the sequence of classifiers, the computational complexity of the levels increases. If the classifier fails to recognize a certain area (that is, the area is classified as negative), such area is no longer processed by the remaining classifiers.
For the cascade classifier according to its definition, the following relationships are true:
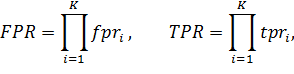
where FPR is the fraction of false detection of the cascade, TPR is the fraction of correct detection of the cascade, K is the number of levels of the cascade, fpr i is the fraction of false detection of the i -th cascade level, tpr i is the fraction of correct detection of the -th cascade level.
The estimated number of calculated signs that will be calculated for each study area is calculated by the formula:

where n i is the number of weak classifiers of the -th level, pr i is the share of the i- th level triggerings.
The learning algorithm of the classifier should solve the optimization problem, trying to build a cascade with the best indicators of FPR and TPR , while minimizing the expected number of calculated signs of N. Clearly, such a task is rather difficult to solve, primarily due to the lack of clear links between the FPR , TPR and N values.
The simple idea of learning a cascade on an existing tagged training set, including positive and negative examples, is known. You must select three parameters in advance:
- the proportion of false positives for each level of the cascade,
- the proportion of correct operations for each level of the cascade,
- the proportion of false positives for the entire cascade as a whole ( FPR * ).
After that, the cascade classifier is constructed iteratively, and at each iteration, training is conducted using the AdaBoost algorithm. Levels are added to the cascade until the target quality specified by the FPR * value is reached. The training input for each level of the cascade should be fed to the input, in which negative examples are the false alarms of the cascade classifier that has already been trained at the moment.
We described the described approach to the training of the object detector in the problem of detecting scanned images of a passport. The training set consisted of two sets:
- 1302 positive samples (cut samples of the 2nd page of the passport of a citizen of the Russian Federation) and 2000 negative samples (full-size FullHD images containing anything except the passport of the Russian Federation)
1103 positive samples (cut samples of the 3rd page of the passport of a citizen of the Russian Federation) and 2000 negative samples (full-size FullHD images containing anything except the passport of the Russian Federation)
The physical size (in pixels) for both classifiers was selected 201x141. With this size, it is still possible to understand that these are the top or bottom pages (that is, the class is determined uniquely), and the intraclass uniqueness disappears.
As a result, two classifiers were trained.
- qualifier of the 2nd page of the passport of a citizen of the Russian Federation, consisting of 8 levels and 28 weak classifiers in total
- qualifier of the 3rd page of the passport of a citizen of the Russian Federation, consisting of 8 levels and 36 weak classifiers.
The test sample consisted of 300 photographs and passport scans (both pages were on the image at the same time). The quality of the binding of the top page of the passport (second page) was 0.967. The quality of the binding of the bottom page of the passport (third page) was 0.98.
Features architecture Elbrus
Architecture Elbrus belongs to the category of architectures that use the principle of a wide command word (Very Long Instruction Word, VLIW). On processors with a VLIW architecture, the compiler generates sequences of groups of commands (broad command words), in which there are no dependencies between the commands within each group and the dependencies between the commands in different groups are minimized. Further, the commands within each group are executed in parallel, which ensures a high level of parallelism at the command level.
Due to the fact that the parallelization at the command level is entirely provided by the optimizing compiler, the equipment for executing commands is greatly simplified, since now it does not solve parallelization problems, as is the case, for example, with the x86 architecture. The power consumption of the VLIW processor is reduced: it no longer needs to analyze dependencies between operands or rearrange operations, since all these tasks are assigned to the compiler. It should be noted that the compiler has much more computational and time resources than hardware source code analyzers, and therefore can perform the analysis more carefully and find more independent operations [8].
In addition, a feature of the architecture of Elbrus are the methods of working with memory. Often, access to external memory can take considerable time and slow down calculations. Caching is used to solve this problem, but it has its drawbacks, since the cache has a strictly limited size and typical caching algorithms are aimed at storing only frequently used data in the cache.
Another way to improve the efficiency of access to memory is to use data preloading methods. These methods allow you to predict memory access and download data to a cache or other special device some time before they are used. They are divided into software and hardware. In program methods, special pre-swap instructions are scheduled at compile time. They are handled in the same way as normal memory accesses. Hardware methods work during program execution and use dynamic information about memory access to predict. They require the presence of additional modules in the microprocessor, but do not need special instructions for paging and can work asynchronously.
Elbrus processors support hardware and software swap method. At the same time, a special device for accessing arrays (Array Access Unit, AAU) is included in the microprocessor hardware, but the need for swapping is determined by the compiler generating special instructions (initializing the AAU, starting and stopping the preliminary swapping program, asynchronous swapping instructions and synchronous data transfer instructions from the array swap buffer (Array Prefetch Buffer, APB) to the register file). The use of a swap device is more efficient than putting an array of elements into a cache, since array elements are often processed sequentially and rarely used more than once [9]. However, it should be noted that the use of the preliminary swap buffer on Elbrus is possible only when working with aligned data. Due to this, reading / writing of aligned data takes place noticeably faster than the corresponding operations for non-aligned data.
Also, Elbrus microprocessors support several types of parallelism besides parallelism at the command level: vector parallelism, control flow parallelism, task parallelism in a multi-machine complex.
Tools to improve the performance of software code on the platform Elbrus
To increase the speed of the developed algorithm on the Elbrus architecture processor is possible by using the high-performance library EML and intrinsics (eng. Intrinsics), implementing vector parallelism.
The EML library is a high-performance library that provides the user with a set of various methods for processing signals, images, video, as well as mathematical functions and operations [10]. It is intended for use in programs written in C / C ++ languages. The EML library includes several of the following function groups:
- Vector — () ; - Algebra — ; - Signal — ; - Image — ; - Video — ; - Volume — ; - Graphics — . For data arrays, the most requested operations are defined, for example, addition, elementwise multiplication, calculation of the average value of the array, etc.
Developers can use vector parallelism on the Elbrus platform directly, that is, perform the same operation on a single register containing several data elements at once. For this, intrinsiki functions are used, the calls of which are replaced by the compiler with high-performance code for this platform. The Elbrus-4C microprocessor supports instruction set version 3, in which the register size is 64 bits. Using a 64-bit register, you can simultaneously process 2 real 32-bit numbers, 4 16-bit integers, or 8 8-bit integers, and thus improve performance. The Elbrus microprocessor intrinsic set is in many ways similar to the SSE, SSE2 intrinsic set and includes operations for data conversion, initialization of vector elements, arithmetic operations, bitwise logical operations, permutation of vector elements, etc.
Optimization of the Viola and Jones classifier for Elbrus architecture
Experimental verification of the developed Viola and Jones classification algorithm was performed in the task of detecting the third page of the passport of the Russian Federation, containing the passport number and series, as well as the last name, first name, patronymic, gender, date and place of birth of a citizen of the Russian Federation. To solve this problem, a binary classifier was trained, to the input of which a gray image arrives, reduced to a size of 480 by 360 pixels. In case the reduction to a given size does not preserve the proportions of the input image, the smallest dimension of the image is reduced to the corresponding size, and the second decreases with the preservation of proportions. The outputs of the classifier are interpreted as the presence or absence of a passport page, oriented so that its sides are parallel to the edges of the frame.
The developed classifier operates with modified Haar double-rectangular signs, which are calculated on the basis of integral images:
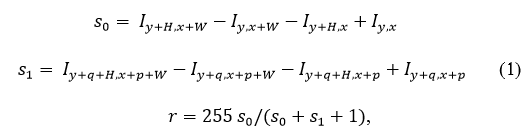
where I is the integral image, W , H is the width and height of the rectangle from which the sum is calculated, ( x , y ) is the coordinate of the upper left corner of the subwindow, ( p , q ) is the shift of the second rectangle to calculate the sum, r is the result of the sign . Unlike the classical two-rectangular feature of the Haar, this feature is more resistant to changes in brightness in the original image.
During the detection, these calculations are made for each sub-window of the original image. Since for our classifier, the step with which these subwindows are taken is equal to 1 both horizontally and vertically, operations of the form (1) for each row of the original picture are easily implemented using such vector EML operations as:
- eml_Status eml_Vector_AddShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s len) - 32- Src1 pSrc2 2^shift pDst. - eml_Status eml_Vector_SubShift_32S(const eml_32s *pSrc1, const eml_32s *pSrc2, eml_32s *pDst, eml_32s len, eml_32s len) - 32- Src1 pSrc2 2^shift pDst. - eml_Status eml_Vector_AddCShift_32S(const eml_32s *pSrc, eml_32s val, eml_32s *pDst, eml_32s len, eml_32s shift) - val 32- pSrc 2^shift pDst. - eml_Status eml_Vector_DivShift_32S(const eml_16s *pSrc1, const eml_16s *pSrc2, eml_16s *pDst, eml_32s len, eml_32s shift) - 32- Src1 pSrc2 2^shift pDst. Thus, the calculation of 2-rectangular signs of Haar was vectorized. Figure 2 shows the time for calculating such a sign depending on the number of applications of the classifier horizontally. The experiments were performed on a machine with an Elbrus-4C processor. You can see that the EML allows you to speed up the computation time of the 2-rectangular Haar attribute up to 10 times in the process of object detection, and this is most effective when the number of applications of the classifier is 64 or more.
Next, we estimate the time for classifying one subwindow, depending on the length of the original image (see Figure 3). It can be seen that the use of EML made it possible to reduce the time for detecting the RF passport page by up to 30 times.
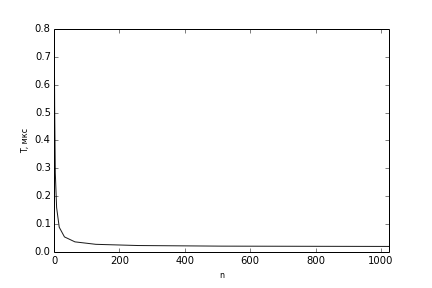
Figure 2 - Dependence of the calculation time of the modified 2-rectangular Haar characteristic T on the number of applications

Figure 3 - Dependence of the time to calculate the classification T on the number of applications of the classifier horizontally n
Similar results far exceeded the expected. Apparently, the reasons for this are the peculiarities of the STL implementation (used in the basic implementation) and the peculiarities of working with memory on Elbrus (for example, the need to align to use an array swapping device - a special Elbrus chip). It turned out that the operations of the EML library take into account these circumstances and make it possible to speed up low-level operations nicely, without requiring the developer to "deeply dive" into the nuances of the architecture.
! You can see the Elbrus computers and our products at ChipEXPO - 2017
List of used sources
- Viola P., Jones M. Robust Real-time Object Detection // International Journal of Computer Vision. 2001. [7]
- Viola P., Jones M., Snow D. Detecting pedestrians using patterns // Int. J. Comput. Vis. 2005. Vol. 63, No. 2. P. 153–161. [thirty],
- Moutarde F., Stanciulescu B., Breheret A. Real-time visual detection of vehicles and pedestrians with new efficient adaBoost features // 2008 IEEE International Conference on Intelligent RObots Systems (IROS 2008). 2008. [33]
- Chen S., Hsieh J. Boosted road sign detection and recognition // 2008 Int. Conf. Mach. Learn. Cybern. 2008. № July. P. 3823–3826. [36]
- Freund Y., Schapire RE A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer Science and System Sciences, No. 55. Issue 1, August 1997, P. 119-139
- Papageorgiou CP, Oren M., Poggio T. A general framework for object detection // Sixth Int. Conf. Comput. Vis. IEEE Cat No98CH36271. 1998. Vol. 6, No. January. P. 555-562 [47]
- Crow FC Summed-area tables for texture mapping // ACM SIGGRAPH Computer Graphics. 1984. Vol. 18, No. 3. P. 207–212 [49]
- Kim A.K., Bychkov I.N. Russian Technologies “Elbrus” for personal computers, servers and supercomputers // Modern information technologies and IT education, M .: Foundation for Assistance in the Development of Internet Media, IT Education, Human Potential “Internet Media League”, 2014, № 10. 39-50.
- Kim A.K., Perekatov V.I., Ermakov S.G. Microprocessors and computer complexes of the Elbrus family. - SPb .: Peter, 2013. - 272 C.
- Ishin PA, Loginov V.E., Vasilyev P.P. Accelerating Computations Using High-Performance Mathematical and Multimedia Libraries for the Elbrus Architecture // Bulletin of Aerospace Defense, Moscow: Almaz Scientific and Production Association. Acad. A.A. Raspletina, 2015, No. 4 (8). 64-68.
')
Source: https://habr.com/ru/post/340918/
All Articles