How to tie a normal search to an outdated SQL backend
Suppose you need to collect personal information, such as birthdays, name, gender, number of children, etc., as well as some marketing data — how often users use buttons in the mobile app cart, etc. We already have a SQL-based application, but (as we will see later) continuing to use SQL for searching is not the best idea. For the search you will have to fasten some NoSQL engine.
How to combine the worlds of SQL and NoSQL? In this article there will be several living examples of integrating Elasticsearch's advanced search engine into legacy applications that work with RestX, Hibernate, and PostgreSQL / MySQL.
David Pilato (David Pilato) - the expert of the Elastic company (these are the guys who did Elasticsearch, Kibana, Beats, and Logstash - that is, the Elastic Stack). David has a wealth of experience in conducting reports on Elastic products (Devoxx conferences in England, Belgium and France, various JUG, Web5, Agile France, Mix-IT, Javazone, reports for specific companies, and so on). In other words, David sets out very clearly and intelligibly, and his reports replace training for hundreds of oil.
')
The basis of this publication is David's report at the Joker 2016 conference, which was held in St. Petersburg last October. Nevertheless, the topics discussed over the past year have not lost their relevance.
The article is available in two versions: a video recording of the report and a full text transcript (press the "read more" button). In the text version, all the necessary data is presented in the form of screenshots, so that you do not lose anything.
My name is David Pilato, I have been working at Elastic for four years now.
This report is based on personal experience gained while working in the French customs service, where I was involved in installing Elasticsearch and connecting SQL-based applications to it.
Now we look at a similar example - the search for marketing data. Suppose you need to collect personal information, such as birthdays, name, gender, number of children, etc., as well as some marketing data — how often users use buttons in the mobile app cart, etc. We already have a SQL-based application, but the search requires using a third-party engine.
The application is as follows:
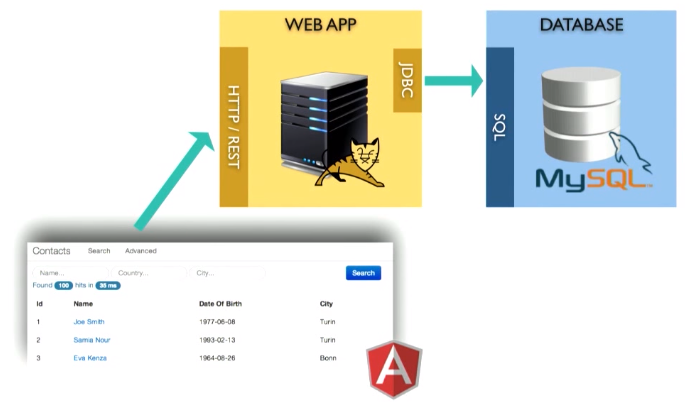
This is a web application running, say, in a Tomcat container. It stores data inside the MySQL database. Over there is a REST interface.
For example, build a certain application. Of course, I didn’t use all the JSP tools, since the object of today's conversation is the backend, not the frontend.

Here are 4 types of beans (beans):
If we look at MySQL, where we have a database, we will see a similar picture, that is, the tables:
If you want to repeat all these examples, you can find the necessary materials on GitHub .

You can repeat everything we do today:
I use IDEA in my examples.
The application has a small search part:

First you need to insert some data. To do this, we use a random generator. It generates random personal data and adds it to an array.
While the data is generated, you can use the search:
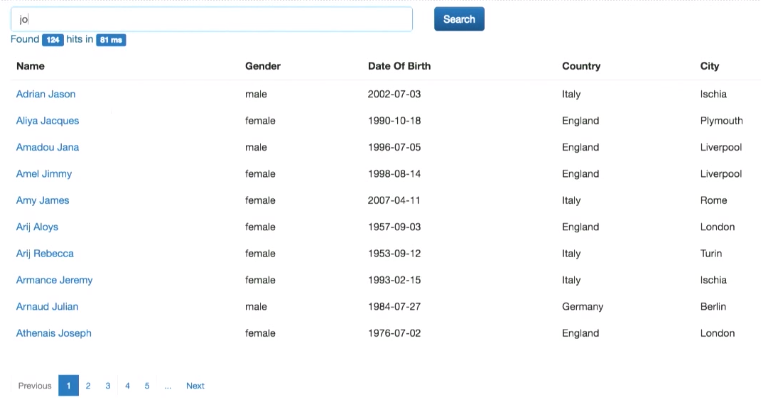
It's like a Google search: you can search by name, country, etc. In addition, an advanced search is implemented - by several fields at the same time:
Let's look at the code (SearchDaoImpl.java).
There is a fingLikeGoogle method. From the interface comes a query query. There is also a division of search results per page (from and size variables). To connect to the database using hibernate.
That is, we generate hibernateQuery. Here is what it looks like:
This uses the toLikeQuery query. You must also combine the address field: c.createAlias ("address", "address"). Further, if there is an element in the database that matches the query by the name, address.country or address.city fields, we return it as a result.
Let's look at the advanced search:
From the interface, we get the fields name, country, city. If the combination entered in these interface elements is found in the corresponding fields of the database element, this element is returned as a result.
Before changing anything, you need to answer the question what problem in this SQL search we want to fix. Let me give you some examples.
This is a simple table with two fields - name and comments. Insert four of these documents into the database:

Perform a simple search. Suppose the user has entered David into the search box in the application. There are no matches in this database:

How to fix it? You can use LIKE by enclosing a custom search string in% signs:
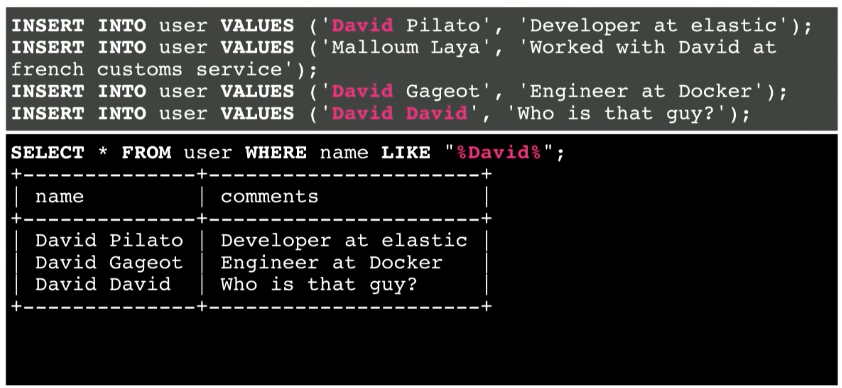
As a result, we found some information. This method works.
Take another example. Now look for David Pilato:
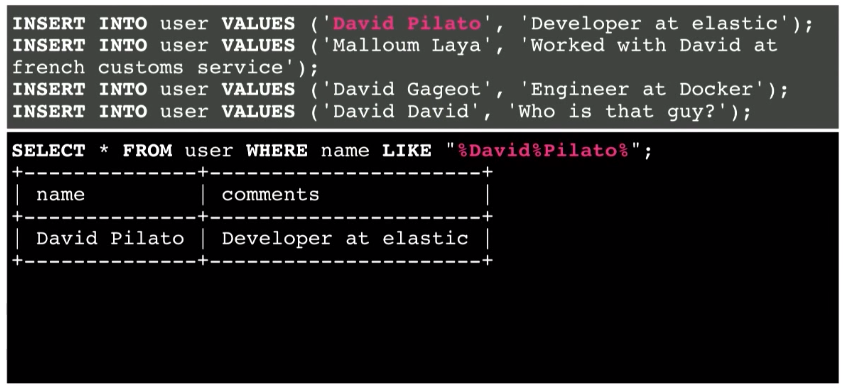
Between individual words, you can put both the% sign and the space. It will still work.
But what if the user searches for Pilato David instead of David Pilato?
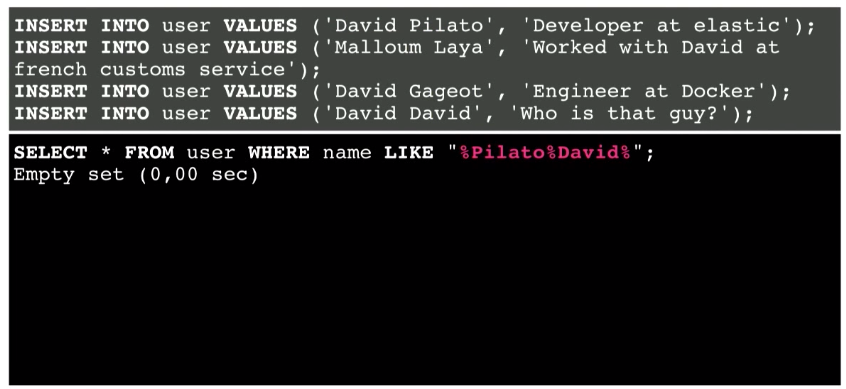
This does not work anymore, despite the fact that this combination is present in the database.
How can I fix this? We divide the user query entered in the interface and use several queries into the database.
Another example is searching by two fields - both in the name field and in the comments field:
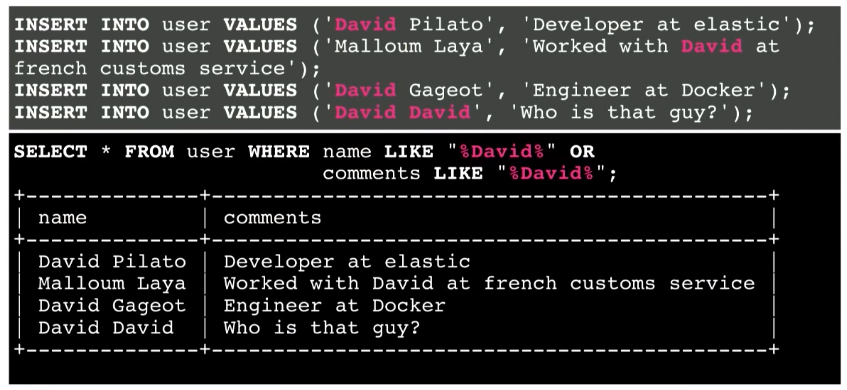
As a result, I get all the information. But what happens if it is a million or billion records? What information is more relevant here? Probably the fourth line. Since the discovery of the required information in the name field, most likely, is more relevant than in the comments field. That is, I want to get this information at the top of the list. However, there is no relevance view in the SQL database. It's like looking for a needle in a haystack.

In addition, you must remember about spelling errors. How to consider them in the search? Using a question mark for each letter of the request and trying to replace it is inefficient.
Imagine if your database is really in demand, and a lot of information is constantly being requested from it. Can you search in parallel with the addition of new information? Perhaps in a hundred thousand documents, perhaps in a million documents. But what about a billion documents (petabytes of data)?
Why not search using the search engine?
This is what we will do today.
Suppose we chose Elasticsearch as the search engine, because, in my opinion, it is the best. And we need to connect our application to it.

How can I do that?
You can use ETL. ETL provides getting data from the source (sending a request to the database), converting the data to a JSON document, and loading it into Elasticsearch. You can use talend or other existing tools.
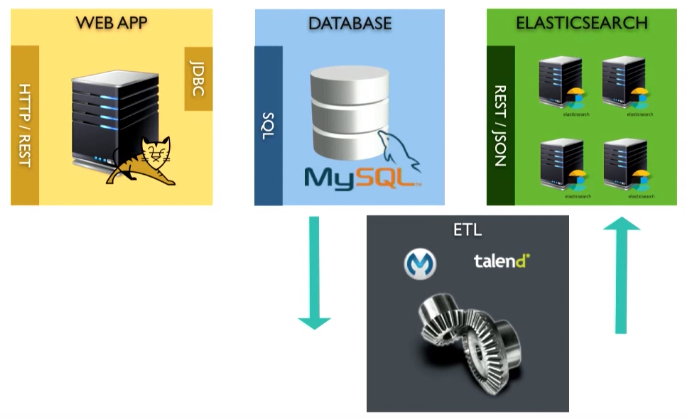
However, there is one problem. The ETL tool will run in batch mode. This means that we will probably have to run the request every 5 minutes. That is, the user enters a query, and the search result can be obtained only 5 seconds later. This is not perfect.
There are problems with the removal. Suppose you need to remove something from the database. By running the SELECT query again, I will have to delete something that is not returned as an answer. This is a super difficult task. You can use the technical table, perhaps the triggers, but all this is not easy.
My favorite way to solve such problems is to make a direct connection between the application and Elasticsearch. If you can do it, do it.

You can use the same transaction as when loading a bean into the database: just transform it into a JSON document and send it to Elasticsearch. You do not have to read the database after five minutes - it is already in memory.
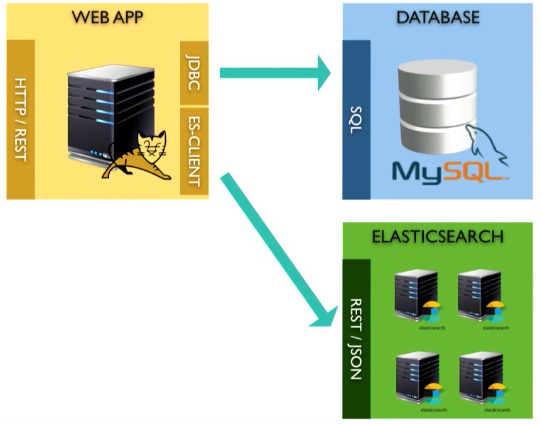
Before you do this, I want to note one thing. When you move from a relational model to a document system, as in Elasticsearch (or another similar solution), you need to think carefully about the model itself, since they reflect different approaches. Instead of adding a single document to a table and attempting to merge in memory

You can create one document with all the necessary information:
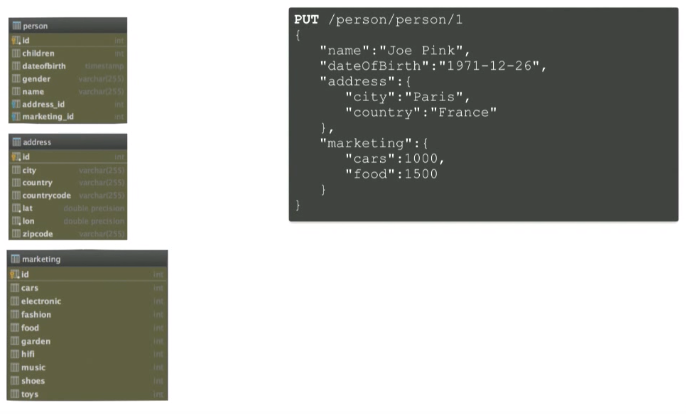
When you connect a search engine, you need to answer two questions for yourself:
Let us turn to examples.
All the steps in the examples are explained in the readme, so you can reproduce everything yourself.
So, you need to add to the project Elasticsearch. We use maven here, so the first thing to do is add elasticsearch as a dependency (here I use the latest version of elasticsearch).
We now turn directly to the application. Here is how saving personal data of a person in the database at the service level (in PersonService.java) looks like:
We open a hibernate transaction, then call personDao.save, and then we complete the transaction.
Here you can also index data using Elasticsearch. We create a new class — elasticsearchDao — and we will save our personDB object (personID, since I would like to use the same ID for Elasticsearch that was generated by hibernate).
You must add a class:
And create this class (in ElasticsearchDao.java).
Here I use the restiks framework, so I have some annotation that allows you to inject it automatically.
Here I use the Component annotation, so in my PersonService class (PersonService.java) I need to inject this component.
Now you need to implement the elasticsearchDao.save (personDb) method in ElasticsearchDao.java. To do this, you first need to create Elasticsearch clients. To do this, add:
It is necessary to implement the client. You can use an existing class to transport existing artifacts.
Next, you need to declare on which machine and on which port Elasticsearch is located. To do this, add addransportAddress and indicate that Elasticsearch is running locally in this case. By default, Elasticsearch starts on port 9300.
You also need something that converts a bean to a JSON document. For this we use the Jackson library. It is already present in my Restix, you only need to inject it.
Now you can implement the save method.
I need to convert my bean to a JSON document. Here you need to choose whether you want the output to produce a JSON document String or Byte (writeValueAsString or writeValueAsBytes, respectively) - we will use Byte, but if necessary, you can use String.
Now the JSON document is in the byte array. You need to send it to Elasticsearch.
Elasticsearch provides different levels of access, so with the same notation you can index different types of data. Here we use the document ID obtained earlier from hibernate.
.source allows us to get the JSON document itself.
Thus, using these two strings, I converted the bean to JSON and sent the latter to Elasticsearch.
Let's try to compile it. Get Exception:
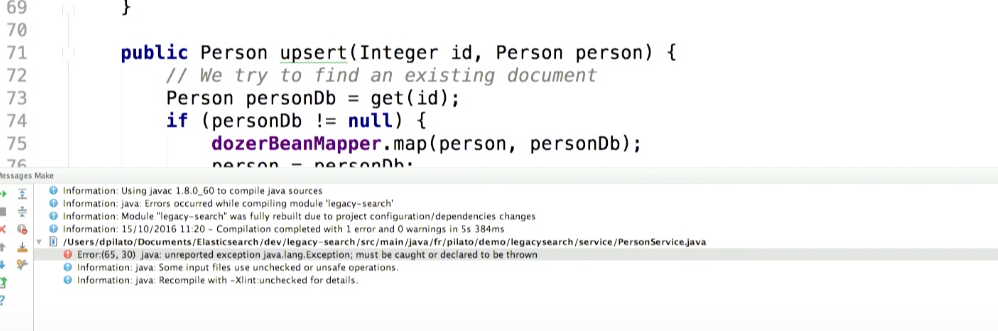
Suppose something bad is happening in the process of interacting with Elasticsearch. What can you do with this exception? Something like rollback of transaction in hibernate.
To do this, you can add to PersonService.java:
But I do not want to do that, because I believe that the presence of data in the database is much more important than the work of the search engine. Therefore, I do not want to lose user input. Instead of rolling back the transaction, simply log the exception so that you can later find out the cause of the error and correct it:
Now let's look at the delete record operation. It is identical. Elasticsearch makes it easier to delete an entry using the same transaction.
You can implement this method in ElasticsearchDao.java. Call DeleteRequest using index name - person and type - also person:
Similarly, we put catch in PersonService.java:
Now let's restart the application. It remains to run Elasticsearch (I have the usual installation of Elasticsearch):

Elasticsearch starts listening to 2 ports:
I will also launch another tool in parallel - kibana. This open source tool we created in Elastic. Use it to view data. But today, kibana will be used to access the Console tab, which allows you to perform individual requests.
Let's generate 10,000 documents again:

Kibana shows that the index person has already been created.
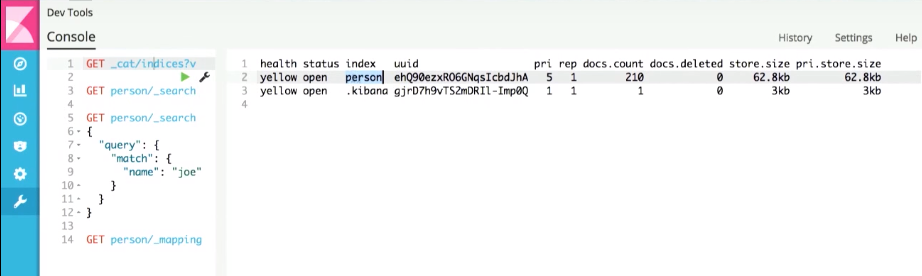
And if we run the simplest search for any document, we get the newly generated document:
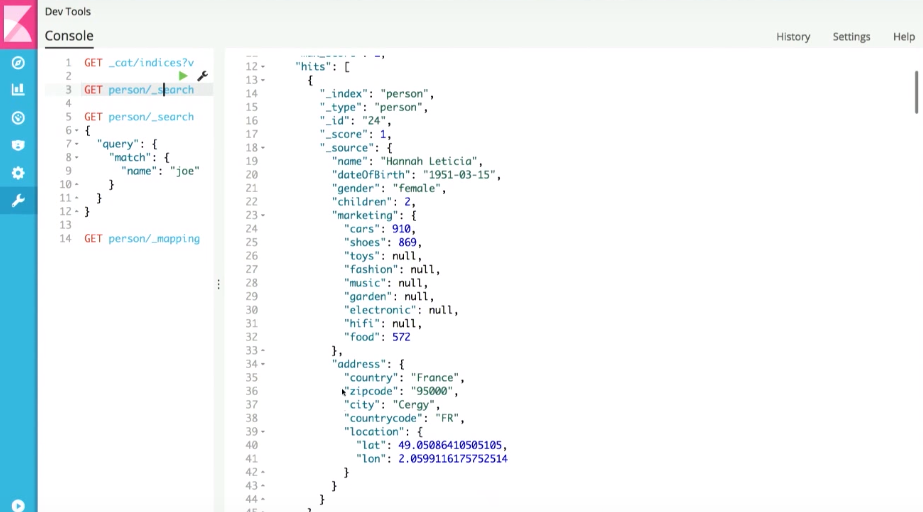
This is the JSON document that was generated from the bean.
Here you can search for individual fields.
But back to the application. Despite the changes, the interface is still getting a search on the database, because the search engine is not integrated yet. Let's do it.
PersonService.java has a search method. Let's try to replace it. Earlier I called findLikeGoogle there, now the decision will be different.
First you need to build a query to Elasticsearch.
Suppose the user has not entered anything. In this case, I want to make a special request - matchAll - issuing all that is.
Otherwise, I would like to use a different type of query - simpleQueryStringQuery. I will search for the text entered by the user in certain fields.
Now use elasticsearchDao to send a search query:
Let's implement this method.
Again you need to use esClient. Here the prepareSearch () method is used; at the same time, the search will be carried out in the person index (if necessary, I can simultaneously search in several entities), set the type and run the query created earlier. Set the pagination options. Here it is super-easy (pagination in databases is a real nightmare).
Using the get () method, I run the query, and then return the result:
Let's fix the code in PersonService.java to get an answer to the search query. All that remains is to return the result as a string (initially the answer is a JSON document):
We turn to the modernization of the advanced search. Here everything is similar to what we have done earlier.
If the user has not entered any requests in the name, country and city fields, run the matchAll query to get the entire document. Otherwise, we want to build a boolean request: if we have something in the name field, we need to look for it in the name field of our JSON document (similar to the country and city).
After that, use the same elasticsearchDao and send the result to the user.
Check how it works. Restart our application.
Now, entering a certain request, I will send it to Elasticsearch.
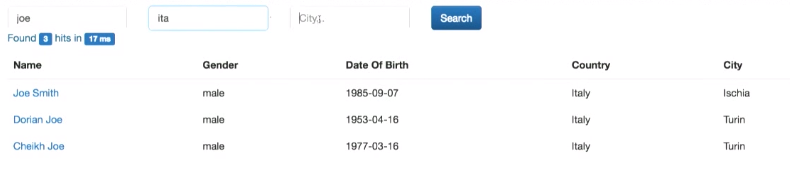
The experiment shows that only the search by complete match (not part of the string) works. This we will fix later. However, we can now search both by first name, last name, and last name by first name. In addition, the relevance of the results appeared. If we search for Joe Smith, then a full-match entry (Joe Smith) will be at the top of the list of results as the most relevant. Further records will go with the same name or surname.
I want to introduce another concept. Regardless of whether you use a Java client for Elasticsearch, it is better to use the Bulk API. Instead of inserting documents into Elasticsearch one by one, Bulk API allows you to batch them. In the Java client, the Bulk API is called bulkProcessor.
You also need to add bulkProcessor and logger:
bulkProcessor works with esClient, which was created earlier. It is filled with requests and every 10,000 operations starts a batch sending of requests to Elasticsearch. Sending will also be performed every 5 seconds, even if you do not type 10,000 requests. You can add your listener here and specify the actions to be performed before the batch sending of requests, after it, or if an exception was received during the execution of the requests.
Let's make changes to the rest of the code.
Now, instead of esClient.index will be bulkProcessor. And do not have to run the request, since the launch provides bulkProcessor.
Same for deletion:
Previously, we had a problem - the word search did not work. This is the usual behavior of Elasticsearch.
If we look at what Elasticsearch generates by default (mapping is analogous to schema in traditional databases), for example, in the city field inside the person document, we see that this field is marked as text:
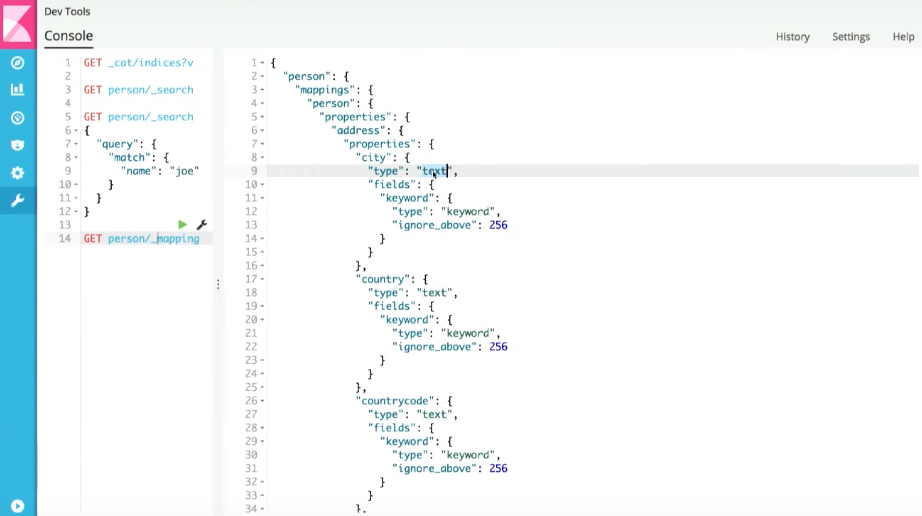
And this means that only the entire match is taken into account lines. To fix this, you need to implement your own mapping for Elasticsearch (get it to use our own search strategy).
For this, I will use the open source Beyonder library.
Add this artifact to the maven project:
, elasticsearch resources, , index ( — person), beyonder , type.json ( type — person, — person.json). mapping.
mapping, REST- Elasticsearch, Beyonder .
, city text ( ), (address.city.autocomplete) text, — .
In addition, at the indexing stage, I copy what is in the address.city field in the fulltext field, for which the same indexing and search strategy will be applied.
We make similar changes for the fields address.coutry, name and gender.
Next, you need to determine the ngram analyzer. To do this, set the indexing parameters for Elasticsearch in the _settings.json file. If this file is available, Beyonder will read it automatically.
In this file, I just ask and ask the tokenizer (unfortunately, the explanation of the process is beyond the scope of our conversation). For each word, I'm going to use an inverted index. I generate “underflows,” meaning Joe will be indexed as j, jo, and joe. Thus, the inverted index will be larger, but I can search more efficiently.
In the code, you need to call Beyonder somewhere. In ElasticsearchDao.java, where our client is specified:
Beyonder will not delete an existing index. Therefore, it must be removed manually via kibana: We
check that there is no person index:

Now we restart the application (in debug mode). In the console, we see that Beyonder is up and running:
Through kibana, you can check that the index person is created and it looks like it was set in resources.
Let's generate 10,000 documents again.

However, we still see standard behavior in the search field. Let's fix it.If you look at the search query in PersonService.java, we see that the search is performed in the name, gender, address.country and address.city fields. Now I have a fulltext field that I can use. You can also search by the name field, but if the result matches, you must raise the result in the search results (since if a complete match is found in the name field, the result is more relevant, and it should be at the top of the list):
After making changes, the search works correctly.

At the same time, in search results for Joe, people named Joe will be at the top of the list.
The same works for country and city.
Let's fix the advanced search where the standard strategy is being used. In the advanced search method in PersonService.java, instead of searching by the name field, you must search by the name.autocomplete field that was generated during the indexing (the same for the address.country and address.city fields):
Now everything works.
As part of such conversations, I am haunted by this question: you send data to Elasticsearch using the same transaction with which you send it to the database. Does this slow down the application?
Let's test it out.
In the code, instead of calling the database, I will simply access Elasticsearch.
Compile. Now I use bulk API only with Elasticsearch. Let's generate 10,000 documents again. The request is executed almost instantly.
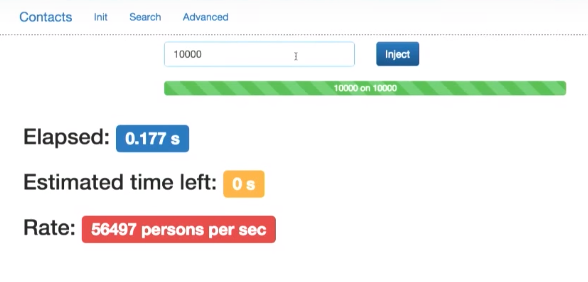
Thus, it does not slow down the application.
Even if we generate a million documents, the search will still be performed efficiently. It is seen that the results were obtained in 4 ms.
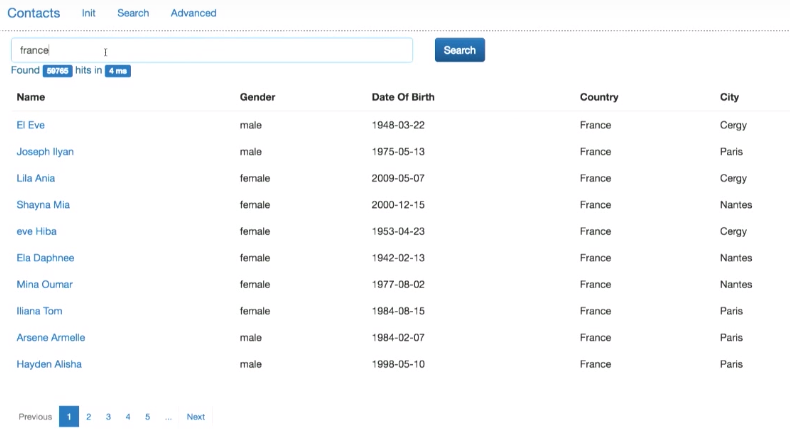
Based on the results obtained, Elasticsearch makes it possible to read various analytics. You can try to understand the data set.
In ElasticsearchDao, in addition to launching the query, add an aggregation.
What's going on here?Based on the search results, the Aggregation framework builds a by_country distribution across the address.country field (.aggs is a “subfield” of keyword type in Elasticsearch starting from version 5, which I need to generate at the indexing stage). As a result, he will issue the TOP-10 countries mentioned in the document (and the number of persons corresponding to each country).
I also want to build a by_year aggregation over the dateOfBirth field.
Let's compile it. The interface has already implemented everything, so you don’t need to change it.
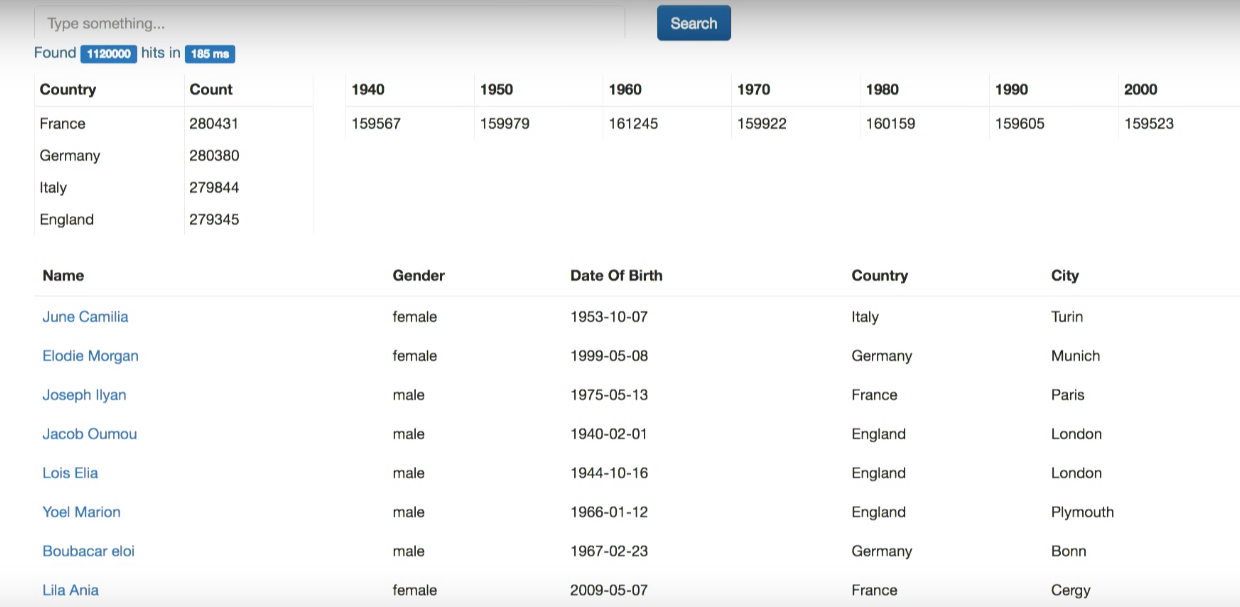
We get the distribution by country and by decades.
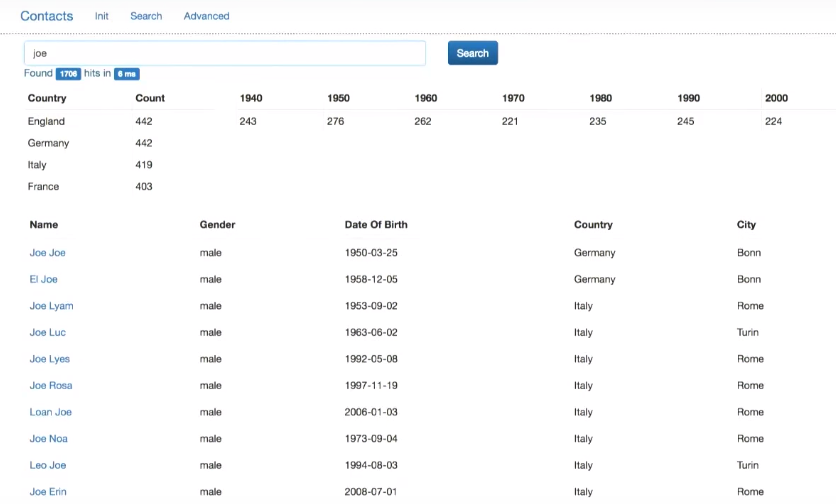
Suppose I want to click on the field and get a list of documents corresponding to this field - what is called faceted navigation. This is not automatically implemented.
If you look at the PersonService.java code, I have here a filter by country and date from the interface. I can use them to filter the results:
If there is anything in the f_country or f_date fields, we build a boolean query, including our previous query (it must match the previous query). If there is anything in the filter pr country (f_country), I filter by country. Similarly, with f_date (I consider the bounds of the user of interest for a decade and filter by date).
Checking - everything works:
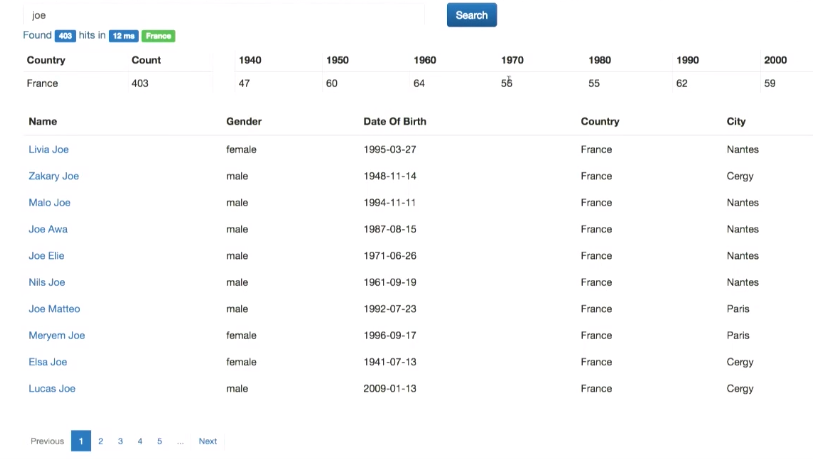
Also Elasticsearch allows you to make an aggregation tree (aggregation from aggregation, etc.). Let's implement this in ElasticsearchDao.java.
First, I use the same aggregation across the country. Then, for each individual country, I make my distribution by decades of birth, counting the average number of children that people in the database have.
Here is the result (for this I changed the interface a little):

You saw how we integrated Elasticsearch in a synchronous manner. But what happens if I need to understand the behavior of Elasticsearch. You saw how I receive exception, I log it. If you want to do this asynchronously, you can use a broker. Instead of sending data directly to Elasticsearch, we can send them to any message queue system, then, using a request similar to what we wrote earlier, read from the message queue and send the request to Elasticsearch via esClient.

And if you don’t want to write your own code that will read from the message queue, you can use something like logstash:
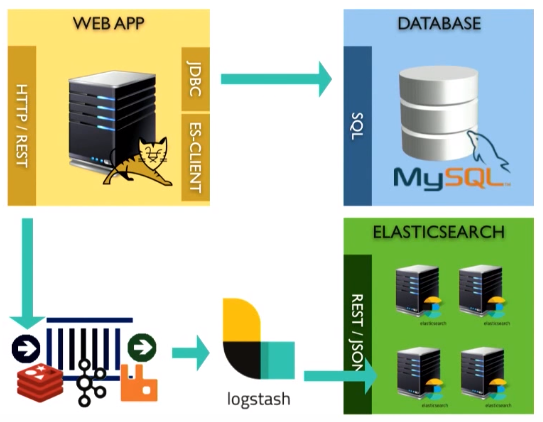
This is an open source tool created by Elastic. It provides data transfer from source, on-the-fly transformation and sending to Elasticsearch or data storage.
Logstash can be scaled - just create several different instances:

If you have any data in your company, take 1-2 days to a test project (“proof of concept”), transfer the data to Elasticsearch, build the application on the similarity of what I showed you today, and get benefits.
I already mentioned one of them - kibana, a free tool that you can use to build panels, like:
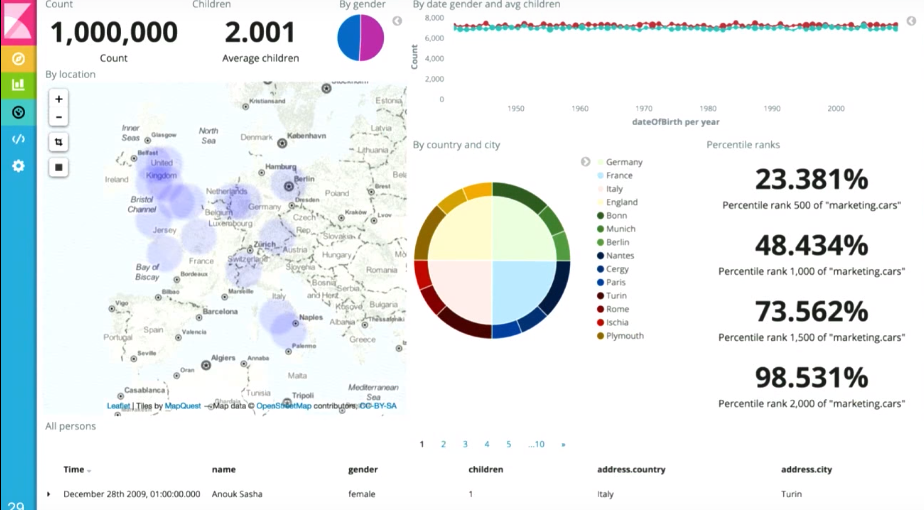
So you can explore your data from any side in real time.
If this topic is close to you and you live in Java, you will certainly be interested in the following reports of the upcoming November Joker 2017 conference :
How to combine the worlds of SQL and NoSQL? In this article there will be several living examples of integrating Elasticsearch's advanced search engine into legacy applications that work with RestX, Hibernate, and PostgreSQL / MySQL.
David Pilato (David Pilato) - the expert of the Elastic company (these are the guys who did Elasticsearch, Kibana, Beats, and Logstash - that is, the Elastic Stack). David has a wealth of experience in conducting reports on Elastic products (Devoxx conferences in England, Belgium and France, various JUG, Web5, Agile France, Mix-IT, Javazone, reports for specific companies, and so on). In other words, David sets out very clearly and intelligibly, and his reports replace training for hundreds of oil.
')
The basis of this publication is David's report at the Joker 2016 conference, which was held in St. Petersburg last October. Nevertheless, the topics discussed over the past year have not lost their relevance.
The article is available in two versions: a video recording of the report and a full text transcript (press the "read more" button). In the text version, all the necessary data is presented in the form of screenshots, so that you do not lose anything.
My name is David Pilato, I have been working at Elastic for four years now.
This report is based on personal experience gained while working in the French customs service, where I was involved in installing Elasticsearch and connecting SQL-based applications to it.
Now we look at a similar example - the search for marketing data. Suppose you need to collect personal information, such as birthdays, name, gender, number of children, etc., as well as some marketing data — how often users use buttons in the mobile app cart, etc. We already have a SQL-based application, but the search requires using a third-party engine.
application
The application is as follows:
This is a web application running, say, in a Tomcat container. It stores data inside the MySQL database. Over there is a REST interface.
For example, build a certain application. Of course, I didn’t use all the JSP tools, since the object of today's conversation is the backend, not the frontend.
Domain
Here are 4 types of beans (beans):
- Person - this bean contains information such as name, date of birth, gender, etc.
- Address,
- GeoPoint - geographic coordinates,
- Marketing - I mentioned earlier marketing information that is stored here.
If we look at MySQL, where we have a database, we will see a similar picture, that is, the tables:
- person,
- united address
- marketing.
Let's go over to examples.
If you want to repeat all these examples, you can find the necessary materials on GitHub .
You can repeat everything we do today:
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a> $ git checkout 00-legacy $ mvn clean install jetty:run I use IDEA in my examples.
What we have at the start
The application has a small search part:
First you need to insert some data. To do this, we use a random generator. It generates random personal data and adds it to an array.
While the data is generated, you can use the search:
It's like a Google search: you can search by name, country, etc. In addition, an advanced search is implemented - by several fields at the same time:
Let's look at the code (SearchDaoImpl.java).
/** * Find persons by any column (like full text). */ @SuppressWarnings("unchecked") public Collection<Person> findLikeGoogle(String query, Integer from, Integer size) { Criteria criteria = generateQuery(hibernateService.getSession(), Person.class, query); criteria.setFirstResult(from); criteria.setMaxResults(size); return criteria.list(); } There is a fingLikeGoogle method. From the interface comes a query query. There is also a division of search results per page (from and size variables). To connect to the database using hibernate.
That is, we generate hibernateQuery. Here is what it looks like:
private Criteria generateQuery(Session session, Class clazz, String query) { String toLikeQuery = "%" + query + "%"; Criteria c = session.createCriteria(clazz); c.createAlias("address", "address"); c.add(Restrictions.disjunction() .add(Restrictions.ilike("name", toLikeQuery)) .add(Restrictions.ilike("address.country", toLikeQuery)) .add(Restrictions.ilike("address.city", toLikeQuery)) ); return c; } This uses the toLikeQuery query. You must also combine the address field: c.createAlias ("address", "address"). Further, if there is an element in the database that matches the query by the name, address.country or address.city fields, we return it as a result.
Let's look at the advanced search:
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { List<Criterion> criterions = new ArrayList<>(); if (name != null) { criterions.add(Restrictions.ilike("name", "%" + name + "%")); } if (country != null) { criterions.add(Restrictions.ilike("address.country", "%" + country + "%")); } if (city != null) { criterions.add(Restrictions.ilike("address.city", "%" + city + "%")); } long start = System.currentTimeMillis(); hibernateService.beginTransaction(); long total = searchDao.countWithCriterias(criterions); Collection<Person> personsFound = searchDao.findWithCriterias(criterions, from, size); hibernateService.commitTransaction(); long took = System.currentTimeMillis() - start; RestSearchResponse<Person> response = buildResponse(personsFound, total, took); logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); String json = null; try { json = mapper.writeValueAsString(response); } catch (JsonProcessingException e) { logger.error("can not serialize to json", e); } return json; } From the interface, we get the fields name, country, city. If the combination entered in these interface elements is found in the corresponding fields of the database element, this element is returned as a result.
Formulation of the problem
Before changing anything, you need to answer the question what problem in this SQL search we want to fix. Let me give you some examples.
This is a simple table with two fields - name and comments. Insert four of these documents into the database:
Perform a simple search. Suppose the user has entered David into the search box in the application. There are no matches in this database:
How to fix it? You can use LIKE by enclosing a custom search string in% signs:
As a result, we found some information. This method works.
Take another example. Now look for David Pilato:
Between individual words, you can put both the% sign and the space. It will still work.
But what if the user searches for Pilato David instead of David Pilato?
This does not work anymore, despite the fact that this combination is present in the database.
How can I fix this? We divide the user query entered in the interface and use several queries into the database.
Another example is searching by two fields - both in the name field and in the comments field:
As a result, I get all the information. But what happens if it is a million or billion records? What information is more relevant here? Probably the fourth line. Since the discovery of the required information in the name field, most likely, is more relevant than in the comments field. That is, I want to get this information at the top of the list. However, there is no relevance view in the SQL database. It's like looking for a needle in a haystack.
In addition, you must remember about spelling errors. How to consider them in the search? Using a question mark for each letter of the request and trying to replace it is inefficient.
Imagine if your database is really in demand, and a lot of information is constantly being requested from it. Can you search in parallel with the addition of new information? Perhaps in a hundred thousand documents, perhaps in a million documents. But what about a billion documents (petabytes of data)?
Why not search using the search engine?
This is what we will do today.
Solution Architecture
Suppose we chose Elasticsearch as the search engine, because, in my opinion, it is the best. And we need to connect our application to it.
How can I do that?
You can use ETL. ETL provides getting data from the source (sending a request to the database), converting the data to a JSON document, and loading it into Elasticsearch. You can use talend or other existing tools.
However, there is one problem. The ETL tool will run in batch mode. This means that we will probably have to run the request every 5 minutes. That is, the user enters a query, and the search result can be obtained only 5 seconds later. This is not perfect.
There are problems with the removal. Suppose you need to remove something from the database. By running the SELECT query again, I will have to delete something that is not returned as an answer. This is a super difficult task. You can use the technical table, perhaps the triggers, but all this is not easy.
My favorite way to solve such problems is to make a direct connection between the application and Elasticsearch. If you can do it, do it.
You can use the same transaction as when loading a bean into the database: just transform it into a JSON document and send it to Elasticsearch. You do not have to read the database after five minutes - it is already in memory.
Before you do this, I want to note one thing. When you move from a relational model to a document system, as in Elasticsearch (or another similar solution), you need to think carefully about the model itself, since they reflect different approaches. Instead of adding a single document to a table and attempting to merge in memory
You can create one document with all the necessary information:
When you connect a search engine, you need to answer two questions for yourself:
- what am i looking for? Am I looking for a person (i .e. I am going to index a person)
- What parameters am I looking for this person? What fields do I need? For example, I am looking for people living in France. Then I need to index the country inside the document.
Let us turn to examples.
Direct connection
All the steps in the examples are explained in the readme, so you can reproduce everything yourself.
$ git clone <a href="https://github.com/dadoonet/legacy-search.git">https://github.com/dadoonet/legacy-search.git</a> $ git checkout 01-direct $ git checkout 02-bulk $ git checkout 03-mapping $ git checkout 04-aggs $ git checkout 05-compute $ mvn clean install jetty:run $ cat README.markdown So, you need to add to the project Elasticsearch. We use maven here, so the first thing to do is add elasticsearch as a dependency (here I use the latest version of elasticsearch).
<!-- Elasticsearch --> <dependency> <groupId>org.elasticsearch.client</groupId> <version>5.0.0-rc1</version> </dependency> We now turn directly to the application. Here is how saving personal data of a person in the database at the service level (in PersonService.java) looks like:
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); hibernateService.commitTransaction(); return personDb; } We open a hibernate transaction, then call personDao.save, and then we complete the transaction.
Here you can also index data using Elasticsearch. We create a new class — elasticsearchDao — and we will save our personDB object (personID, since I would like to use the same ID for Elasticsearch that was generated by hibernate).
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); elasticsearchDao.save(personDb); hibernateService.commitTransaction(); return personDb; } You must add a class:
private final ElasticsearchDao elasticsearchDao; And create this class (in ElasticsearchDao.java).
Here I use the restiks framework, so I have some annotation that allows you to inject it automatically.
import restx.factory.Component; Here I use the Component annotation, so in my PersonService class (PersonService.java) I need to inject this component.
@Inject public PersonService(PersonDao personDao, SearchDao searchDao, HibernateService hibernateService, <b> ElasticsearchDao elasticsearchDao,</b> ObjectMapper mapper, DozerBeanMapper dozerBeanMapper) { this.personDao = personDao; this.searchDao = searchDao; this.hibernateService = hibernateService; this.mapper = mapper; this.dozerBeanMapper = dozerBeanMapper; <b> this.elasticsearchDao = elasticsearchDao;</b> } Now you need to implement the elasticsearchDao.save (personDb) method in ElasticsearchDao.java. To do this, you first need to create Elasticsearch clients. To do this, add:
@Component public class ElasticsearchDao { private final Client esClient; public void save(Person person) { } } It is necessary to implement the client. You can use an existing class to transport existing artifacts.
@Component public class ElasticsearchDao { private final Client esClient; public ElasticsearchDao() { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); } public void save(Person person) { } } Next, you need to declare on which machine and on which port Elasticsearch is located. To do this, add addransportAddress and indicate that Elasticsearch is running locally in this case. By default, Elasticsearch starts on port 9300.
public ElasticsearchDao() { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); .addTransportAddress(new InetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); } You also need something that converts a bean to a JSON document. For this we use the Jackson library. It is already present in my Restix, you only need to inject it.
@Component public class ElasticsearchDao { private final Client esClient; <b>private final ObjectMapper mapper;</b> public ElasticsearchDao(<b>ObjectMapper mapper</b>) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY); .addTransportAddress(new InetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); <b> this.mapper = mapper;</b> } public void save(Person person) { } } Now you can implement the save method.
I need to convert my bean to a JSON document. Here you need to choose whether you want the output to produce a JSON document String or Byte (writeValueAsString or writeValueAsBytes, respectively) - we will use Byte, but if necessary, you can use String.
public void save(Person person) throws Exception { <b>byte[] bytes = mapper.writeValueAsBytes(person);</b> } Now the JSON document is in the byte array. You need to send it to Elasticsearch.
Elasticsearch provides different levels of access, so with the same notation you can index different types of data. Here we use the document ID obtained earlier from hibernate.
.source allows us to get the JSON document itself.
public void save(Person person) throws Exception { byte[] bytes = mapper.writeValueAsBytes(person); <b>esClient.index(new IndexRequest("person", "person", person.idAsString()).source(bytes).actionGet());</b> } Thus, using these two strings, I converted the bean to JSON and sent the latter to Elasticsearch.
Let's try to compile it. Get Exception:
Suppose something bad is happening in the process of interacting with Elasticsearch. What can you do with this exception? Something like rollback of transaction in hibernate.
To do this, you can add to PersonService.java:
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); try { elasticsearchDao.save(personDb); } <b>catch (Exception e) { hibernateService.rollbackTransaction(); e.printStackTrace(); }</b> hibernateService.commitTransaction(); return personDb; } But I do not want to do that, because I believe that the presence of data in the database is much more important than the work of the search engine. Therefore, I do not want to lose user input. Instead of rolling back the transaction, simply log the exception so that you can later find out the cause of the error and correct it:
public Person save(Person person) { hibernateService.beginTransaction(); Person personDb = personDao.save(person); try { elasticsearchDao.save(personDb); } <b>catch (Exception e) { logger.error("Houston, we have a problem!", e); }</b> hibernateService.commitTransaction(); return personDb; } Now let's look at the delete record operation. It is identical. Elasticsearch makes it easier to delete an entry using the same transaction.
public boolean delete(Integer id) { logger.debug("Person: {}", id); if (id == null) { return false; } hibernateService.beginTransaction(); Person person = personDao.get(id); if (person == null) { logger.debug("Person with reference {} does not exist", id); hibernateService.commitTransaction(); return false; } personDao.delete(person); <b> elasticsearchDao.delete(person.idAsString());</b> hibernateService.commitTransaction(); logger.debug("Person deleted: {}", id); return true; } You can implement this method in ElasticsearchDao.java. Call DeleteRequest using index name - person and type - also person:
public void delete(String idAsString) throws Exception { esClient.delete(new DeleteRequest("person", "person", idAsString)).get(); } Similarly, we put catch in PersonService.java:
personDao.delete(person); <b>try {</b> elasticsearchDao.delete(person.idAsString()); <b>} catch (Exception e) { e.printStackTrace(); }</b> hibernateService.commitTransaction(); Now let's restart the application. It remains to run Elasticsearch (I have the usual installation of Elasticsearch):
Elasticsearch starts listening to 2 ports:
- 9300 for a Java client;
- 9200 - REST API.
I will also launch another tool in parallel - kibana. This open source tool we created in Elastic. Use it to view data. But today, kibana will be used to access the Console tab, which allows you to perform individual requests.
Let's generate 10,000 documents again:
Kibana shows that the index person has already been created.
And if we run the simplest search for any document, we get the newly generated document:
This is the JSON document that was generated from the bean.
Here you can search for individual fields.
But back to the application. Despite the changes, the interface is still getting a search on the database, because the search engine is not integrated yet. Let's do it.
PersonService.java has a search method. Let's try to replace it. Earlier I called findLikeGoogle there, now the decision will be different.
First you need to build a query to Elasticsearch.
public String search(String q, String f_country, String f_date, Integer from, Integer size) { <b>QueryBuilder query;</b> } Suppose the user has not entered anything. In this case, I want to make a special request - matchAll - issuing all that is.
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; <b>if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); }</b> } Otherwise, I would like to use a different type of query - simpleQueryStringQuery. I will search for the text entered by the user in certain fields.
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); }<b> else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); }</b> } Now use elasticsearchDao to send a search query:
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); } <b>elasticsearchDao.search(query, from, size);</b> } Let's implement this method.
Again you need to use esClient. Here the prepareSearch () method is used; at the same time, the search will be carried out in the person index (if necessary, I can simultaneously search in several entities), set the type and run the query created earlier. Set the pagination options. Here it is super-easy (pagination in databases is a real nightmare).
Using the get () method, I run the query, and then return the result:
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) .setFrom(from) .setSize(size) .get(); return response; } Let's fix the code in PersonService.java to get an answer to the search query. All that remains is to return the result as a string (initially the answer is a JSON document):
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("name") .field("gender") .field("address.country") .field("address.city"); } <b>SearchResponse response =</b> elasticsearchDao.search(query, from, size); return response.toString(); } We turn to the modernization of the advanced search. Here everything is similar to what we have done earlier.
If the user has not entered any requests in the name, country and city fields, run the matchAll query to get the entire document. Otherwise, we want to build a boolean request: if we have something in the name field, we need to look for it in the name field of our JSON document (similar to the country and city).
After that, use the same elasticsearchDao and send the result to the user.
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) { query = QueryBuilders.matchAllQuery(); } else { BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); if (Strings.hasText(name)) { boolQueryBuilder.must( QueryBuilders.matchQuery("name", name) ); } if (Strings.hasText(country)) { boolQueryBuilder.must( QueryBuilders.matchQuery("address.country", country) ); } if (Strings.hasText(city)) { boolQueryBuilder.must( QueryBuilders.matchQuery("address.city", city) ); } query = boolQueryBuilder; } SearchResponse response = elasticsearchDao.search(query, from, size); if (logger.isDebugEnabled()) logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); return response.toString(); } Check how it works. Restart our application.
Now, entering a certain request, I will send it to Elasticsearch.
The experiment shows that only the search by complete match (not part of the string) works. This we will fix later. However, we can now search both by first name, last name, and last name by first name. In addition, the relevance of the results appeared. If we search for Joe Smith, then a full-match entry (Joe Smith) will be at the top of the list of results as the most relevant. Further records will go with the same name or surname.
Batch mode
I want to introduce another concept. Regardless of whether you use a Java client for Elasticsearch, it is better to use the Bulk API. Instead of inserting documents into Elasticsearch one by one, Bulk API allows you to batch them. In the Java client, the Bulk API is called bulkProcessor.
@Inject public ElasticsearchDao(ObjectMapper mapper) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); this.mapper = mapper; this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() { @Override public void beforeBulk(long executionID, BulkRequest request) { logger.debug("going to execute bulk of {} requests", request.numberOfActions()); } @Override public void afterBulk(long executionID, BulkRequest request, BulkResponse response) { logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without"); } @Override public void afterBulk(long executionID, BulkRequest request, Throwable failure) { logger.warn("error while executing bulk", failure); } }) .setBulkActions(10000) .setFlushInterval(TimeValue.timeValueSeconds(5)) .build(); } You also need to add bulkProcessor and logger:
private final BulkProcessor bulkProcessor; private final Logger logger = LoggerFactory.getLogger(ElasticsearchDao.class); bulkProcessor works with esClient, which was created earlier. It is filled with requests and every 10,000 operations starts a batch sending of requests to Elasticsearch. Sending will also be performed every 5 seconds, even if you do not type 10,000 requests. You can add your listener here and specify the actions to be performed before the batch sending of requests, after it, or if an exception was received during the execution of the requests.
Let's make changes to the rest of the code.
Now, instead of esClient.index will be bulkProcessor. And do not have to run the request, since the launch provides bulkProcessor.
public void save(Person person) throws Exception { byte[] bytes = mapper.writeValueAsBytes(person); bulkProcessor.add(new IndexRequest("person", "person", person.idAsString()).source(bytes)); } Same for deletion:
public void delete(String id) throws Exception { bulkProcessor.delete(new DeleteRequest("person", "person", idAsString)); } Previously, we had a problem - the word search did not work. This is the usual behavior of Elasticsearch.
If we look at what Elasticsearch generates by default (mapping is analogous to schema in traditional databases), for example, in the city field inside the person document, we see that this field is marked as text:
And this means that only the entire match is taken into account lines. To fix this, you need to implement your own mapping for Elasticsearch (get it to use our own search strategy).
For this, I will use the open source Beyonder library.
Add this artifact to the maven project:
<!-- Elasticsearch-Beyonder --> <dependency> <groupId>fr.pilato.elasticsearch</groupId> <artifactId>elasticsearch-beyonder</artifactId> <version>2.1.0</version> </dependency> , elasticsearch resources, , index ( — person), beyonder , type.json ( type — person, — person.json). mapping.
mapping, REST- Elasticsearch, Beyonder .
, city text ( ), (address.city.autocomplete) text, — .
In addition, at the indexing stage, I copy what is in the address.city field in the fulltext field, for which the same indexing and search strategy will be applied.
"city": { "type": "text", "copy_to": "fulltext", "fields": { <b> "autocomplete" : { "type": "text", "analyzer": "ngram", "search_analyzer": "simple" },</b> "aggs" : { "type": "keyword" } } }, We make similar changes for the fields address.coutry, name and gender.
Next, you need to determine the ngram analyzer. To do this, set the indexing parameters for Elasticsearch in the _settings.json file. If this file is available, Beyonder will read it automatically.
In this file, I just ask and ask the tokenizer (unfortunately, the explanation of the process is beyond the scope of our conversation). For each word, I'm going to use an inverted index. I generate “underflows,” meaning Joe will be indexed as j, jo, and joe. Thus, the inverted index will be larger, but I can search more efficiently.
{ "analysis": { "analyzer": { "ngram": { "tokenizer": "ngram_tokenizer", "filter": [ "lowercase" ] } }, "tokenizer": { "ngram_tokenizer": { "type": "edgeNGram", "min_gram": "1", "max_gram": "10", "token_chars": [ "letter", "digit" ] } } } } In the code, you need to call Beyonder somewhere. In ElasticsearchDao.java, where our client is specified:
@Inject public ElasticsearchDao(ObjectMapper mapper) { this.esClient = new PreBuiltTransportClient(Settings.EMPTY) .addTransportAddress(new InternetSocketTransportAddress( new InetSocketAddress("127.0.0.1", 9300) )); this.mapper = mapper; this.bulkProcessor = BulkProcessor.builder(esClient, new BulkProcessor.Listener() { @Override public void beforeBulk(long executionID, BulkRequest request) { logger.debug("going to execute bulk of {} requests", request.numberOfActions()); } @Override public void afterBulk(long executionID, BulkRequest request, BulkResponse response) { logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without"); } @Override public void afterBulk(long executionID, BulkRequest request, Throwable failure) { logger.warn("error while executing bulk", failure); } }) .setBulkActions(10000) .setFlushInterval(TimeValue.timeValueSeconds(5)) .build(); <b>try { ElasticsearchBeyonder.start(esClient); } catch (Exception e) { e.ptintStackTrace(); } } Beyonder will not delete an existing index. Therefore, it must be removed manually via kibana: We
check that there is no person index:
Now we restart the application (in debug mode). In the console, we see that Beyonder is up and running:
Through kibana, you can check that the index person is created and it looks like it was set in resources.
Let's generate 10,000 documents again.
However, we still see standard behavior in the search field. Let's fix it.If you look at the search query in PersonService.java, we see that the search is performed in the name, gender, address.country and address.city fields. Now I have a fulltext field that I can use. You can also search by the name field, but if the result matches, you must raise the result in the search results (since if a complete match is found in the name field, the result is more relevant, and it should be at the top of the list):
public String search(String q, String f_country, String f_date, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field(<b>"fulltext"</b>) .field(<b>"name", 3.0f</b>) } SearchResponse response = elasticsearchDao.search(query, from, size); return response.toString(); } After making changes, the search works correctly.
At the same time, in search results for Joe, people named Joe will be at the top of the list.
The same works for country and city.
Let's fix the advanced search where the standard strategy is being used. In the advanced search method in PersonService.java, instead of searching by the name field, you must search by the name.autocomplete field that was generated during the indexing (the same for the address.country and address.city fields):
public String advancedSearch(String name, String country, String city, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(name) && !Strings.hasText(country) && !Strings.hasText(city)) { query = QueryBuilders.matchAllQuery(); } else { BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); if (Strings.hasText(name)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>name.autocomplete</b>", name) ); } if (Strings.hasText(country)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>address.country.autocomplete</b>", country) ); } if (Strings.hasText(city)) { boolQueryBuilder.must( QueryBuilders.matchQuery("<b>address.city.autocomplete</b>", city) ); } query = boolQueryBuilder; } SearchResponse response = elasticsearchDao.search(query, from, size); if (logger.isDebugEnabled()) logger.debug("advancedSearch({},{},{})={} persons", name, country, city, response.getHits().getTotalHits()); return response.toString(); } Now everything works.
Work speed
As part of such conversations, I am haunted by this question: you send data to Elasticsearch using the same transaction with which you send it to the database. Does this slow down the application?
Let's test it out.
In the code, instead of calling the database, I will simply access Elasticsearch.
public Person save(Person person) { // hibernateService.beginTransaction(); // Person personDb = personDao.save(person); try { elasticsearchDao.save(<b>person</b>); } catch (Exception e) { logger.error("Houston, we have a problem!", e); } // hibernateService.commitTransaction(); return person; } Compile. Now I use bulk API only with Elasticsearch. Let's generate 10,000 documents again. The request is executed almost instantly.
Thus, it does not slow down the application.
Even if we generate a million documents, the search will still be performed efficiently. It is seen that the results were obtained in 4 ms.
Aggregation
Based on the results obtained, Elasticsearch makes it possible to read various analytics. You can try to understand the data set.
In ElasticsearchDao, in addition to launching the query, add an aggregation.
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) <b> .addAggregation( AggregationBuilders.terms("by_country").field("address.country.aggs") ) .addAggregation( AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.YEAR) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") )</b> .setFrom(from) .setSize(size) .get(); return response; } What's going on here?Based on the search results, the Aggregation framework builds a by_country distribution across the address.country field (.aggs is a “subfield” of keyword type in Elasticsearch starting from version 5, which I need to generate at the indexing stage). As a result, he will issue the TOP-10 countries mentioned in the document (and the number of persons corresponding to each country).
I also want to build a by_year aggregation over the dateOfBirth field.
Let's compile it. The interface has already implemented everything, so you don’t need to change it.
We get the distribution by country and by decades.
Suppose I want to click on the field and get a list of documents corresponding to this field - what is called faceted navigation. This is not automatically implemented.
If you look at the PersonService.java code, I have here a filter by country and date from the interface. I can use them to filter the results:
public String search(String q, String <b>f_country</b>, String <b>f_date</b>, Integer from, Integer size) { QueryBuilder query; if (!Strings.hasText(q)) { query = QueryBuilders.matchAllQuery(); } else { query = QueryBuilders.simpleQueryStringQuery(q) .field("fulltext") .field("name", 3.0f) } <b>if (Strings.hasText(f_country) || Strings.hasText(f_date)) { query = QueryBuilders.boolQuery().must(query); if (Strings.hasText(f_country)) { ((BoolQueryBuilder) query).filter(QueryBuilders.termQuery("address.country.aggs", f_country)); } if (Strings.hasText(f_date)) { String endDate = "" + (Integer.parseInt(f_date) + 10); ((BoolQueryBuilder) query).filter(QueryBuilders.rangeQuery("dateOfBirth").gte(f_date).lt(endDate)); } } SearchResponse response = elasticsearchDao.search(query, from, size); return response.toString(); } If there is anything in the f_country or f_date fields, we build a boolean query, including our previous query (it must match the previous query). If there is anything in the filter pr country (f_country), I filter by country. Similarly, with f_date (I consider the bounds of the user of interest for a decade and filter by date).
Checking - everything works:
Aggregation tree
Also Elasticsearch allows you to make an aggregation tree (aggregation from aggregation, etc.). Let's implement this in ElasticsearchDao.java.
public SearchResponse search(QueryBuilder query, Integer from, Integer size) { SearchResponse response = esClient.prepareSearch("person") .setTypes("person") .setQuery(query) .addAggregation( AggregationBuilders.terms("by_country").field("address.country.aggs") .subAggregation(AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.days(3652)) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") .subAggregation(AggregationBuilders.avg("avg_children").field("children")) ) ) .addAggregation( AggregationBuilders.dateHistogram("by_year") .field("dateOfBirth") .minDocCount(0) .dateHistogramInterval(DateHistogramInterval.YEAR) .extendedBounds(new ExtendedBounds(1940L, 2009L)) .format("YYYY") ) .setFrom(from) .setSize(size) )); return response; } First, I use the same aggregation across the country. Then, for each individual country, I make my distribution by decades of birth, counting the average number of children that people in the database have.
Here is the result (for this I changed the interface a little):
Exception
You saw how we integrated Elasticsearch in a synchronous manner. But what happens if I need to understand the behavior of Elasticsearch. You saw how I receive exception, I log it. If you want to do this asynchronously, you can use a broker. Instead of sending data directly to Elasticsearch, we can send them to any message queue system, then, using a request similar to what we wrote earlier, read from the message queue and send the request to Elasticsearch via esClient.
And if you don’t want to write your own code that will read from the message queue, you can use something like logstash:
This is an open source tool created by Elastic. It provides data transfer from source, on-the-fly transformation and sending to Elasticsearch or data storage.
Logstash can be scaled - just create several different instances:
Instead of totals
If you have any data in your company, take 1-2 days to a test project (“proof of concept”), transfer the data to Elasticsearch, build the application on the similarity of what I showed you today, and get benefits.
I already mentioned one of them - kibana, a free tool that you can use to build panels, like:
So you can explore your data from any side in real time.
If this topic is close to you and you live in Java, you will certainly be interested in the following reports of the upcoming November Joker 2017 conference :
- Java 9: the good parts (Cay Horstmann, San Jose State University)
- Java 8: , , ( , XP Injection)
- Birth, life and death of a class (Volker Simonis, SAP)
- Java Code Coverage mechanics (Evgeny Mandrikov, Marc Hoffmann)
Source: https://habr.com/ru/post/340856/
All Articles