Asynchrony 3: Subject model

Foreword
This article is a continuation of a series of articles about asynchrony:
After 3 years, I decided to expand and summarize the existing range of asynchronous interaction using coroutines. In addition to these articles, it is also recommended to familiarize yourself with the universal adapter :
')
Introduction
Consider an electron. What he really is? A negatively charged elementary particle, a lepton with a certain mass. This means that it can participate at least in electromagnetic and gravitational interactions.
If we place a spherical electron in a vacuum, then all that it will be able to do is to move uniformly and straightforwardly. 3 degrees of freedom and spin, and only uniform rectilinear motion. Nothing interesting and unusual.

Everything changes in a completely surprising way if there are other particles nearby. For example, a proton. What do we know about him? Many things. We will be interested in the mass character and the presence of a positive charge, equal in absolute value to an electron, but with a different sign. This means that the electron and proton will interact with each other in an electromagnetic manner.
The result of this interaction will be a curvature of the rectilinear trajectory under the action of electromagnetic forces. But this is half the trouble. An electron flying near the proton will experience acceleration. The electron-proton system will be a dipole, which suddenly begins to create bremsstrahlung . Those. generate electromagnetic waves propagating in a vacuum.
But that's not all. Under certain circumstances, the electron is captured into the orbit of the proton and it turns out the well-known system - the hydrogen atom. What do we know about such a system? Also a lot of things. In particular, this system has a discrete set of energy levels and a line spectrum of radiation, which is formed during the transition between each pair of stationary states.
And now let's take a look at this picture from a different angle. Initially, we had two particles: a proton and an electron. The particles themselves do not emit (they simply cannot), they do not manifest any discreteness, and generally behave calmly. But the picture changes completely when they find each other. There are new, completely unique properties - continuous and discrete spectrum, stationary states, the minimum energy level of the system. In reality, of course, everything is much more complicated and interesting:
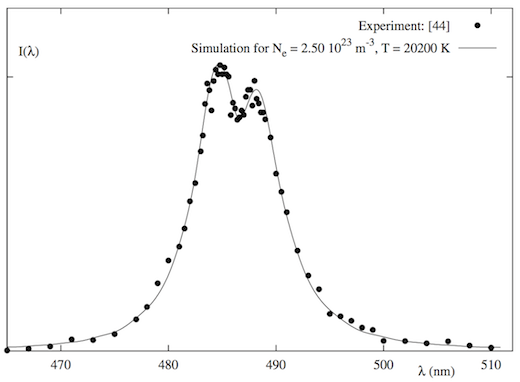
Asymmetry of the Stark broadening of the Hβ spectral line of the hydrogen atom, Phys. Rev. E 79 (2009)
This reasoning can go on and on. For example, if you put two hydrogen atoms side by side, you get a stable configuration called the hydrogen molecule . Here the electron-vibrational-rotational energy levels appear with a characteristic change in the spectrum, the appearance of the P, Q, R branches and many other things.
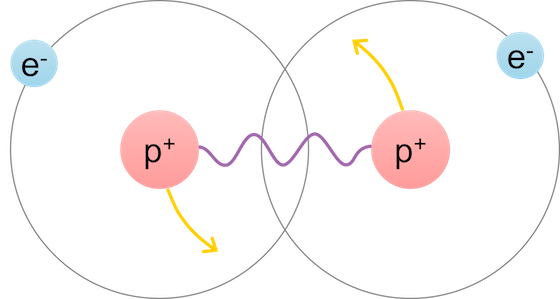
How so? Is not the system described by its parts? Not! This is the essence of the fact that with the complication of the physical system, qualitative changes take place, which are not described by each part separately.
Synergy of interaction manifests itself in many areas of scientific knowledge. That is why chemistry is not reduced to physics, and biology to chemistry. Despite the most powerful achievements of quantum mechanics, nevertheless chemistry as a section of scientific knowledge exists separately from physics. It is interesting to note the fact that there are areas of knowledge at the interface of sciences, for example, quantum chemistry . What does this mean? That with the complication of the system there are new areas of research that were not at the previous level. We have to take into account new circumstances, introduce additional qualitative factors, complicating each time the already difficult model of describing a quantum-mechanical system.
The described metamorphosis can be reversed: if it is necessary to obtain a complex system of the simplest components, then these components should have a synergistic principle. In particular, we all know that any problem can be solved by introducing an additional level of abstraction. Except for the problem of the number of abstractions and the resulting complexity. And only the synergy of abstractions reduces their number.
Unfortunately, quite often our programs do not exhibit the described synergistic properties. Is that in the bugs - there are new, hitherto unprecedented glitches that were not detected at the previous stage. And how I wish that the application was not described by a set of parts and libraries of the program, but was something unique and ambitious.
Let us now try to penetrate the essence of OOP and coroutines to obtain new and surprising properties of their synthesis in order to create a generalized model of interaction.
Object oriented programming
Consider OOP. What do we know about him? Encapsulation, inheritance, polymorphism? SOLID principles ? And let's ask Alan Kay, who introduced this concept:
When I talked about OOP, I did not mean C ++.
Alan Kay .
This is a serious blow for C ++ programmers. Even somehow it became insulting for the language. But what did he mean? Let's figure it out.
The concept of objects was introduced in the mid-1960s with the advent of the Simula 67 language. This language introduced such concepts as object, virtual methods, and coroutines (!). Then in the 1970s, the language Smalltalk, influenced by the language Simula 67, developed the idea of objects and introduced the term object-oriented programming . It was there that the foundations of what we now call the PLO were laid. Alan Kay himself commented on his sentence:
I regret having coined the term “objects” many years ago because it forces people to concentrate on small ideas. A really big idea is messages.
Alan Kay .
If you recall Smalltalk, it becomes clear what it means. Sending messages was used in this language (see also ObjectiveC). This mechanism worked, but was inhibitory. Therefore, we went further along the path of the Simula language and replaced the sending of messages with regular function calls, as well as virtual function calls through the table of these virtual functions to support late binding.
To return to the origins of OOP, let's take a fresh look at the classes and methods in C ++. To do this, as an example, consider the
Reader class, which reads the data from the source and returns an object of the Buffer type: class Reader { public: Buffer read(Range range, const Options& options); // ... }; In this case, I will be interested only in the
read method. This method can be converted to the next, almost equivalent, call: Buffer read(Reader* this, Range range, const Options& options); Calling the object's method we simply turned into a stand-alone function. This is exactly what the compiler does when it transforms our code into machine code. However, such a path leads us away, or rather towards the language of S. Here the PLO does not even smell close, so let's go the other way.
How do we call the
read method? For example: Reader reader; auto buffer = reader.read(range, options); Transform the
read method call as follows: reader <- read(range, options) -> buffer; This entry means the following. An object named
reader is given some kind of read(range, options) input, and the output is an object named buffer .What can
read(range, options) ? Some input message: struct InReadMessage { Range range; Options options; }; struct OutReadMessage { Buffer buffer; }; reader <- InReadMessage{range, options} -> OutReadMessage; This transformation gives us a slightly different understanding of what is happening: instead of calling the function, we synchronously send the
InReadMessage message and then wait for the OutReadMessage response message. Why synchronous? Because call semantics implies that we are waiting for a response. However, generally speaking, the response message in the place of the call can not wait, then it will be an asynchronous message sending.Thus, all methods can be represented as handlers for various types of messages. And our object automatically dispatches received messages, realizing the static pattern matching through the mechanism of the declaration of various methods and overloading the same methods with different types of input parameters.
Message Interception and Action Transformation
We are working on our messages. How do we pack a message for later transformation? For this we will use the adapter:
template<typename T_base> struct ReaderAdapter : T_base { Buffer read(Range range, const Options& options) { return T_base::call([range, options](Reader& reader) { return reader.read(range, options); }); } }; Now, when calling the
read method, the call is wrapped in a lambda and T_base::call to the base method of the T_base::call method. In this case, the lambda is a functional object that will transmit its closure to our heir object T_base , automatically dispatching it. This lambda is our message, which we pass on to transform actions.The easiest way to transform is to synchronize access to an object:
template<typename T_base, typename T_locker> struct BaseLocker : private T_base { protected: template<typename F> auto call(F&& f) { std::unique_lock<T_locker> _{lock_}; return f(static_cast<T_base&>(*this)); } private: T_locker lock_; }; Inside the
call method, the lock_ lock is lock_ and the lambda is subsequently called on an instance of the T_base base class, which allows for further transformations if necessary.Let's try using this functionality:
// ReaderAdapter<BaseLocker<Reader, std::mutex>> reader; auto buffer = reader.read(range, options); What's going on here? Instead of using
Reader directly, we now replace the object with a ReaderAdapter . When the read method is called, this adapter creates a message in the form of a lambda and passes it on, where the lock is automatically taken and released strictly for the duration of this operation. At the same time, we exactly keep the original interface of the Reader class!This approach can be easily generalized and use a universal adapter. I told about him at the C ++ conference , which was held in Moscow in February 2017. You can also read my recent article about the universal adapter .
The corresponding code using the universal adapter will look like this:
DECL_ADAPTER(Reader, read) AdaptedLocked<Reader, std::mutex> reader; Here, the adapter intercepts each method of the
Reader class specified in the DECL_ADAPTER list, in this case read , and then AdaptedLocked already intercepted the message wraps in std::mutex . This is described in more detail in the article just mentioned above, so here I will not dwell on this in detail.Coroutines
With the PLO figured out a bit. Now let's go on the other side and talk about coroutines.
What are coroutines? In short, these are functions that can be interrupted anywhere, and then continue from the same place, i.e. freeze the execution and restore it from the interrupted point. In this sense, they are very similar to threads: the operating system can freeze them at any time and switch to another thread. For example, due to the fact that we ate too much CPU time.
But then what is the difference from streams? The difference is that we ourselves in the user space can switch our coroutines, our execution threads, without involving the core. What allows, firstly, to improve performance, because There is no need to switch protection rings, etc., and secondly, it adds more interesting ways of interaction, which will be discussed below.
Some interesting ways of interaction can be read in my previous articles about asynchrony .
Cospinlock
Consider the following piece of code:
namespace synca { struct Spinlock { void lock() { while (lock_.test_and_set(std::memory_order_acquire)) { reschedule(); } } void unlock() { lock_.clear(std::memory_order_release); } private: std::atomic_flag lock_ = ATOMIC_FLAG_INIT; }; } // namespace synca The code above looks like a normal spinlock. Indeed, inside the
lock method we are trying to atomically set the flag value from false to true . If we succeeded, the blocking was taken, and it was taken by us, and the necessary atomic actions can be performed. When unblocking, simply reset the flag back to the initial value false .The whole difference lies in the implementation of the strategy of backtracking (backoff). Often, either exponential randomized failures are used, or the transfer of control to the operating system via
std::this_thread::yield() . In this case, I'm acting smarter: instead of warming up the processor or transferring control to the operating system scheduler, I simply reschedule our coroutine for a later execution by calling synca::reschedule . At the same time, the current execution is frozen, and the scheduler starts another, ready-to-run coroutine. This is very similar to std::this_thread::yield() , except that instead of switching to kernel space, we always remain in user space and continue to do some meaningful work without an empty increase in the entropy of space.Apply adapter:
template <typename T> using CoSpinlock = AdaptedLocked<T, synca::Spinlock>; CoSpinlock<Reader> reader; auto buffer = reader.read(range, options); As you can see, the use code and semantics have not changed, but the behavior has changed.
CoMutex
The same trick can also be done with a regular mutex, turning it asynchronous on coroutines. To do this, you need to make a queue of waiting coroutines and launch them sequentially when the lock is released. This can be illustrated by the following scheme:

I will not give the full implementation code here. Those interested can familiarize themselves with it. I will give only an example of use:
template <typename T> using CoMutex = AdaptedLocked<T, synca::Mutex>; CoMutex<Reader> reader; auto buffer = reader.read(range, options); Such a mutex has the semantics of a regular mutex, but it does not block the stream, forcing the coroutine planner to do useful work without switching to kernel space. In this
CoMutex , CoMutex , unlike CoSpinlock , gives a FIFO guarantee, i.e. provides fair competitive access to the facility.CoSerializedPortal
The Asynchrony 2: Teleportation through Portals article examined in detail the issue of context switching between different planners through the use of teleportation and the portal. Briefly describe this process.
Consider an example when we need to switch a coroutine from one thread to another. To do this, we can freeze the current state of our coroutine in the original thread, and then schedule the resumption of the coroutine in another thread:
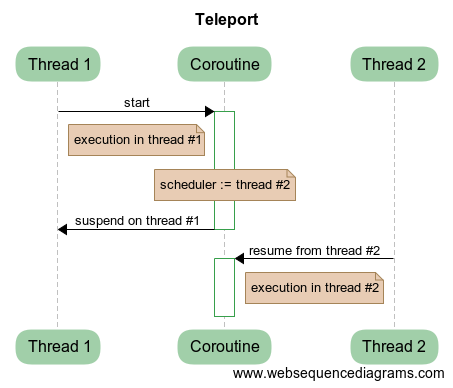
This is exactly what will correspond to switching the performance from one thread to another. Coroutine provides an additional level of abstraction between code and stream, allowing you to manipulate the current performance and perform various tricks and tricks. Switching between different schedulers is teleportation.
If we need to switch first to another scheduler, and then come back, then there is a portal, in the constructor of which there is a teleportation to another scheduler, and in the destructor - to the original one. This guarantees a return to the source even when an exception is thrown.
Accordingly, a simple idea arises. Create a scheduler with one thread and reschedule our coroutines through the portals:
template <typename T_base> struct BaseSerializedPortal : T_base { // 1 BaseSerializedPortal() : tp_(1) {} protected: template <typename F> auto call(F&& f) { // 1 synca::Portal _{tp_}; return f(static_cast<T_base&>(*this)); // } private: mt::ThreadPool tp_; }; CoSerializedPortal<Reader> reader; It is clear that such a scheduler will serialize our actions, and therefore synchronize them with each other. In this case, if the thread pool gives FIFO guarantees, then
CoSerializedPortal will have a similar guarantee.CoAlone
The previous approach with portals can be used somewhat differently. To do this, use another scheduler:
synca::Alone .This scheduler has the following wonderful property: at any given time, no more than one task of this scheduler can be executed. Thus,
synca::Alone guarantees that no handler will be launched in parallel with another. There are tasks - only one of them will be performed. No tasks - nothing is executed. It is clear that with this approach, actions are serialized, which means that access through this scheduler will be synchronized. Semantically, this is very similar to CoSerializedPortal . However, it is worth noting that such a scheduler runs its tasks on a certain thread pool, i.e. it does not create any new threads on its own, but works on existing ones.For more details, I send the reader to the original article Asynchrony 2: teleport through portals .
template <typename T_base> struct BaseAlone : T_base { BaseAlone(mt::IScheduler& scheduler) : alone_{scheduler} {} protected: template <typename F> auto call(F&& f) { // .. Alone - , synca::Portal _{alone_}; return f(static_cast<T_base&>(*this)); } private: synca::Alone alone_; }; CoAlone<Reader> reader; The only difference in implementation compared to
CoSerializedPortal is the replacement of the mt::ThreadPool synca::Alone with synca::Alone .CoChannel
We introduce the concept of a channel on coroutines. Ideologically, it is similar to
chan channels in the Go language, i.e. This is a queue (not necessarily, by the way, of limited size, as is done in Go), in which several data producers can simultaneously write and simultaneously read consumers without additional synchronization on their part. Simply put, a channel is just a pipe into which you can add and take messages without fear of a race condition.The idea of using the channel is that users of our objects write messages to the channel, and the consumer is a specially created coroutine that reads messages in an infinite loop and dispatches them to the appropriate method.
template <typename T_base> struct BaseChannel : T_base { BaseChannel() { // synca::go([&] { loop(); }); } private: void loop() { // // for (auto&& action : channel_) { action(); } } synca::Channel<Handler> channel_; }; CoChannel<Reader> reader; Two questions immediately arise: the first and the second.
- What is a
Handler? - Where, actually, dispatching?
Handler is just std::function<void()> . All the magic happens not here, but in how this Handler is created for automatic dispatch. template <typename T_base> struct BaseChannel : T_base { protected: template <typename F> auto call(F&& f) { // fun auto fun = [&] { return f(static_cast<T_base&>(*this)); }; // WrappedResult<decltype(fun())> result; channel_.put([&] { try { // - result.set(wrap(fun)); } catch (std::exception&) { // result.setCurrentError(); } // synca::done(); }); // synca::wait(); // return result.get().unwrap(); } }; A fairly simple action takes place here: we intercept the intercepted method call inside the functor
f in a WrappedResult , put this call inside the channel and WrappedResult . We will call this deferred call inside the BaseChannel::loop method, thereby filling the result and resuming the fallen asleep source coroutine.It is worth saying a few words about the class
WrappedResult . This class serves several purposes:- It allows you to store either the result of a call or a caught exception.
- In addition, he solves the following problem. The fact is that if the function does not return any values (that is, returns the
voidtype), then the construction of assigning the result without a wrapper would be incorrect. Indeed, one cannot simply take the resultvoidinto avoidtype. However, it is allowed to return, which is what theWrappedResult<void>specializationWrappedResult<void>through calls to.get().unwrap().
As a result, we have synchronization of access to the object through a channel of method calls with captured parameters. In this case, all methods are processed in a separate, isolated coroutine, which ensures the sequential execution of handlers to change our object.
Normal asynchrony
For the sake of interest, let's try to implement exactly the same behavior without an adapter and coroutines in order to most clearly demonstrate the power and strength of the abstractions used.
To do this, consider the implementation of an asynchronous spinlock:
struct AsyncSpinlock { void lock(std::function<void()> cb) { if (lock_.test_and_set(std::memory_order_acquire)) { // => currentScheduler().schedule( [this, cb = std::move(cb)]() mutable { lock(std::move(cb)); }); } else { cb(); } } void unlock() { lock_.clear(std::memory_order_release); } private: std::atomic_flag lock_ = ATOMIC_FLAG_INIT; }; Here the standard interface of the spinlock has changed. This interface has become more bulky and less enjoyable.
Now let's implement the
AsyncSpinlockReader class, which will use our asynchronous spinlock: struct AsyncSpinlockReader { void read(Range range, const Options& options, std::function<void(const Buffer&)> cbBuffer) { spinlock_.lock( [this, range, options, cbBuffer = std::move(cbBuffer)] { auto buffer = reader_.read(range, options); // , unlock , // spinlock_.unlock(); cbBuffer(buffer); }); } private: AsyncSpinlock spinlock_; Reader reader_; } As we can see from the example of the
read method, the AsyncSpinlock asynchronous spinlock AsyncSpinlock surely break the existing interfaces of our classes.And now consider the use of:
// // CoSpinlock<Reader> reader; // auto buffer = reader.read(range, options); AsyncSpinlockReader reader; reader.read(buffer, options, [](const Buffer& buffer) { // // }); Let's assume for a moment that
Spinlock::unlock and the call to the Reader::read method are also asynchronous. It's easy enough to believe, assuming that Reader pulls data across the network, and Spinlock are used instead of Spinlock , for example. Then: struct SuperAsyncSpinlockReader { // , // void read(Range range, const Options& options, std::function<void(const Buffer&)> cb) { spinlock_.lock( [this, range, options, cb = std::move(cb)]() mutable { // : read reader_.read(range, options, [this, cb = std::move(cb)](const Buffer& buffer) mutable { // : spinlock_.unlock( [buffer, cb = std::move(cb)] { // cb(buffer); }); }); }); } private: AsyncSpinlock spinlock_; AsyncNetworkReader reader_; } 
Such a frontal approach hints, as it were, that things will only get worse, because the working code tends to grow and become more complex.
Naturally, the correct approach using coroutines makes such a synchronization scheme simple and straightforward.
Non-invasive asynchrony
All synchronization primitives considered are implicitly asynchronous . The fact is that in the case of an already blocked resource with competitive access, our coroutine falls asleep to wake up at the time the lockout is released by the previous coroutine. If we used the so-called stackless coroutines , which are still marinated in the new standard, we would have to use the keyword
co_await . And this, in turn, means that each (!) Call to any method wrapped through a sync adapter must add a call to co_await , changing the semantics and interfaces: // Buffer baseRead() { Reader reader; return reader.read(range, options); } // callback-style // void baseRead(std::function<void(const Buffer& buffer)> cb) { AsyncReader reader; reader.read(range, options, cb); } // stackless coroutines // , future_t<Buffer> standardPlannedRead() { CoMutex<Reader> reader; return co_await reader.read(range, options); } // stackful coroutines // Buffer myRead() { CoMutex<Reader> reader; return reader.read(range, options); } Here, using the stackless approach, all interfaces in the call chain are scrapped. In this case, there can be no transparency of speech, since you can not just take and replace the
Reader with CoMutex<Reader> . Such an invasive approach significantly limits the scope of stackless coroutines .At the same time, this problem is completely absent from the stackful- based coroutine approach used in this article.
You are given a unique choice:
- Use an invasive breaking approach tomorrow (after 3 years, maybe).
- Use a non-invasive transparent approach today (more precisely, already yesterday).
Hybrid approaches
. , , .
:
template <typename T_base> struct BasePortal : T_base, private synca::SchedulerRef { template <typename... V> BasePortal(mt::IScheduler& scheduler, V&&... v) : T_base{std::forward<V>(v)...} , synca::SchedulerRef{scheduler} // { } protected: template <typename F> auto call(F&& f) { // f(...) synca::Portal _{scheduler()}; return f(static_cast<T_base&>(*this)); } using synca::SchedulerRef::scheduler; }; mt::IScheduler , f(static_cast<T_base&>(*this)) . 1 : // mt::ThreadPool serialized{1}; CoPortal<Reader> reader1{serialized}; CoPortal<Reader> reader2{serialized}; Reader , serialized .CoAlone CoChannel : // .. CoAlone CoChannel , // mt::ThreadPool isolated{3}; // // isolated CoAlone<Reader> reader1{isolated}; // // isolated CoChannel<Reader> reader2{isolated}; , 5 :
CoSpinlockCoMutexCoSerializedPortalCoAloneCoChannel
. :
#define BIND_SUBJECTOR(D_type, D_subjector, ...) \ template <> \ struct subjector::SubjectorPolicy<D_type> \ { \ using Type = D_subjector<D_type, ##__VA_ARGS__>; \ }; template <typename T> struct SubjectorPolicy { using Type = CoMutex<T>; }; template <typename T> using Subjector = typename SubjectorPolicy<T>::Type; Subjector<T> , 5 . For example: // , Reader 3 : read, open, close // DECL_ADAPTER(Reader, read, open, close) // , Reader CoChannel . // , CoMutex, // .. BIND_SUBJECTOR(Reader, CoChannel) // - Subjector<Reader> reader; Reader , , , : BIND_SUBJECTOR(Reader, CoSerializedPortal) , .
, , , . - .
Alan Kay .
. Those. . . , , , .
Consider the following example:
class Network { public: void send(const Packet& packet); }; DECL_ADAPTER(Network, send) BIND_SUBJECTOR(Network, CoChannel) :
void sendPacket(const Packet& packet) { Subjector<Network> network; network.send(myPacket); // , // doSomeOtherStuff(); } doSomeOtherStuff() , network.send() . : void sendPacket(const Packet& packet) { Subjector<Network> network; // .async() network.async().send(myPacket); // // doSomeOtherStuff(); } — !
It works as follows.
BaseAsyncWrapper : template <typename T_derived> struct BaseAsyncWrapper { protected: template <typename F> auto call(F&& f) { return static_cast<T_derived&>(*this).asyncCall(std::forward<F>(f)); } }; Those.
.async() BaseAsyncWrapper , T_derived , asyncCall call . , Co - asyncCall call , .asyncCall :- :
CoSpinlock,CoMutex,CoSerializedPortal,CoAlone. .
template <typename T_base> struct Go : T_base { protected: template <typename F> auto asyncCall(F&& f) { return synca::go( [ f = std::move(f), this ]() { f(static_cast<T_base&>(*this)); }, T_base::scheduler()); } }; - :
CoChannel. .
template <typename T_base> struct BaseChannel : T_base { template <typename F> auto asyncCall(F&& f) { channel_.put([ f = std::move(f), this ] { try { f(static_cast<T_base&>(*this)); } catch (std::exception&) { // do nothing due to async call } }); } }; Specifications
:
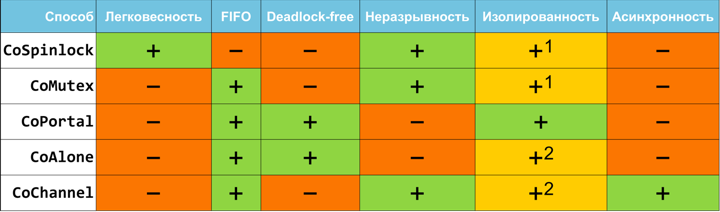
1 .
2 .
.
— , ,
CoSpinlock . , . CoSpinlock , .. . , .FIFO
FIFO first-in-first-out — , ..
.lock() , . , FIFO , CoSpinlock FIFO-.Deadlock-free
, . .
, . , deadlock-free. , .. .
CoPortal . — . CoSerializedPortal , .. . , , , : CoAlone CoChannel . . , .,
CoChannel , . CoChannel . Those. — . :- : .
- : , , .
, .
I love to ask the following task.
Task 1 . Suppose that all methods of our class are synchronized through a mutex. Attention, question: is it possible to race?

The obvious answer is no. However, there is a trick here. The thought begins to spin in the head, the brain begins to offer crazy options that do not correspond to the condition of the problem. As a result, everything turns into ashes and hopelessness arises.
I advise you to think carefully before spying the answer. But in order not to break the brain, below is the solution to this problem.
Consider the class:
struct Counter { void set(int value); int get() const; private: int value_ = 0; }; Wrap up:
DECL_ADAPTER(Counter, set, get) Subjector<Counter> counter; get set , . .:
2 . .
:
counter.set(counter.get() + 1); , , !
.
.
data race, :
The execution of a program contains a data race if it contains two potentially concurrent conflicting actions, at least one of which is not atomic, and neither happens before the other, except for the special case for signal handlers described below. Any such data race results in undefined behavior.
C++17 Standard N4659, §4.7.1 (20.2)
— - ,
std::vector::push_back(value) . , — (, — ). :- ThreadSanitizer : runtime.
- Helgrind: a thread error detector : Valgrind .
- Relacy race detector : lock-free/wait-free .
.
, . , , . , ,
counter.set(counter.get() + 1) . - , .get() .set() .. , .. :
- Node.fz: fuzzing the server-side event-driven architecture : , , (!) .
- An empirical study on the correctness of formally verified distributed systems : . Those. , !
, .
CoAlone : struct User { void setName(const std::string& name); std::string getName() const; void setAge(int age); int getAge() const; }; DECL_ADAPTER(User, setName, getName, setAge, getAge) BIND_SUBJECTOR(User, CoAlone) struct UserManager { void increaseAge() { user_.setAge(user_.getAge() + 1); } private: Subjector<User> user_; }; UserManager manager; // race condition 2- manager.increaseAge(); manager.increaseAge() 2- , increaseAge() .:
struct UserManager { void increaseAge() { user_.setAge(user_.getAge() + 1); } private: Subjector<User> user_; }; DECL_ADAPTER(UserManager, increaseAge) BIND_SUBJECTOR(UserManager, CoAlone) Subjector<UserManager> manager; manager.increaseAge(); CoAlone . : ?
! , 2- . ,
UserManager Alone . user_.getAge() Alone , User . Those.another coroutine is now able to enter the method increaseAge()in parallel with the current one, which is currently inside user_.getAge(). This is possible because Aloneit guarantees only the absence of parallel execution in its scheduler. In this case, parallel execution takes place in two different schedulers: CoAlone<User>and CoAlone<UserManager>.
Thus, there is a break of atomic execution in the case of synchronization based on the schedulers:
CoAloneand CoPortal.To remedy this situation, it is enough to replace:
BIND_SUBJECTOR(UserManager, CoMutex) 
This will prevent the race condition of the second kind.
Waiting for execution
In some cases, a sync break when executing code is extremely useful. To do this, consider the following example:
struct UI { // , void onRequestUser(const std::string& userName); // void updateUser(const User& user); }; DECL_ADAPTER(UI, onRequestUser, updateUser) // UI UI BIND_SUBJECTOR(UI, CoPortal) struct UserManager { // User getUser(const std::string& userName); private: void addUser(const User& user); User findUser(const std::string& userName); }; DECL_ADAPTER(UserManager, getUser) BIND_SUBJECTOR(UserManager, CoAlone) struct NetworkManager { // User getUser(const std::string& userName); }; DECL_ADAPTER(NetworkManager, getUser) // BIND_SUBJECTOR(NetworkManager, CoSerializedPortal) // , Subjector<UserManager>& getUserManager(); Subjector<NetworkManager>& getNetworkManager(); Subjector<UI>& getUI(); void UI::onRequestUser(const std::string& userName); { updateUser(getUserManager().getUser(userName)); } void UserManager::getUser(const std::string& userName) { auto user = findUser(userName); if (user) { // , return user; } // , // user = getNetworkManager().getUser(userName); // , addUser(user); return user; } 
UI::onRequestUsername . UI UserManager::getUser . UI Alone , . UI . , , UI, .UserManager — , . NetworkManager . UserManager . - UserManager , ! Those. . , . , !, — . :
// forward declaration struct User; DECL_ADAPTER(User, addFriend, getId, addFriendId) struct User { void addFriend(Subjector<User>& myFriend) { auto friendId = myFriend.getId(); if (hasFriend(friendId)) { // - return; } addFriendId(friendId); auto myId = getId(); myFriend.addFriendId(myId); } Id getId() const; void addFriendId(Id id); private: bool hasFriend(Id id); }; // void makeFriends(Subjector<User>& u1, Subjector<User>& u2) { u1.addFriend(u2); } 
Since
CoMutex , makeFriends . , ? : BIND_SUBJECTOR(User, CoAlone) 
, , , . - , ? , .
, : , deadlock-free , . , , . , . .
Discussion
5 . 3 16 . , - , , . , , .
16 , :
CoChannel<T>.async().someMethod(...) . , , . , mailbox , , , ++, . , , , , , , ., . , , , . , .
:
:
- . , — .
- . - . , .
- . , - .
- . . , . , , , .
- . .
- . , .
- , . ,
guard, , , .. , , .
, . - - . , , , , , , , , , , : .
: .
https://github.com/gridem/Subjector

Literature
[1] :
[2] 2:
[3] Blog: God Adapter
[4]
[5] :
[6] :
[7] S. Djurović, M. Ćirišan, AV Demura, GV Demchenko, D. Nikolić, MA Gigosos, et al., Measurements of Hβ Stark central asymmetry and its analysis through standard theory and computer simulations, Phys. Rev. E 79 (2009) 46402.
[8]
[9] : SOLID
[10]
[11] C++17 Standard N4659
[12] ThreadSanitizer
[13] Helgrind: a thread error detector
[14] Relacy race detector
[15]
[16] J.Davis, A.Thekumparampil, D.Lee, Node.fz: fuzzing the server-side event-driven architecture. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 145-160
[17] P.Fonseca, K.Zhang, X.Wang, A.Krishnamurthy, An empirical study on the correctness of formally verified distributed systems. EuroSys '17 Proceedings of the Twelfth European Conference on Computer Systems, pp 328-343
[18]
[19]
[20]
[21]
Source: https://habr.com/ru/post/340732/
All Articles