Search for documents in network balloons and file dumps

Almost every one of us has ever worked in a company where everyone has the hated file-care facility — a ball with thousands of documents without any structure. And surely everyone had a moment when he needed to find something in this garbage can. “And Vasilich threw this report on the ball last month, look there” - we heard from a colleague, and that same Vasilich to the question “And in which folder?” Of course, he answered, "And x ... I do not remember, in general, look for yourself." And we plunged into many hours of hell - wandered through folders with documents from the 90s, photos of cats, contracts, mixed with anecdotes and other slag in the hope of finding a treasured document.
Surely many of us tried to bring order in this ball, "I have enough, now I will take, rake everything and arrange it on the shelves," we said to everyone, wasting hours, days and weeks of our time, raking debris. And at the same time Vasilisa Semyonovna from the accounting department, or the same Vasilich, again diluted the parsed files with his documents, cats, anecdotes and other things, returning the usual chaos to its place. And so it went until you gave up. And the ball turned back into the usual trash.
How to be?
Since the idea to force all users to maintain order in the ball has failed, then you need to look for alternative approaches. An obvious choice with minimal effort would be a search engine that allows you to search by names and metadata, and by the contents of all files in the garbage.
When we were at the stage of solving this problem for our clients, we first of all examined the existing systems for searching and managing documents, giving priority to open-source solutions. Without going into details of the search and research, I immediately declare the result: there was simply no quick, simple and convenient solution for indexing and searching in balls, with OCR, tagging and highlighting named entities.
What's next? Decision
Therefore, seeing this problem in many companies, we decided to create our own product, of course, open-source.
As a result, we got Ambar - a system for searching and structuring documents, which finally met all our requirements ( GitHub ), namely:
- Instant search by document content, incl. of images
- Tagging of documents, incl. automatic (for example, mark all images with an image tag, or mark all documents where there are IP addresses with an ip tag)
- Support for all office formats (including openoffice), pdf with pictures and old encodings like CP866
- Automatic collection and synchronization of documents from the ball trash
Consider a solution to our problem with Ambar, in steps:
- Install Ambar on Linux server: Docker and Ubuntu Server 16.04 and above are needed (
Installation instructions in English ) - Configure SMB or FTP Krauler ( English manual )
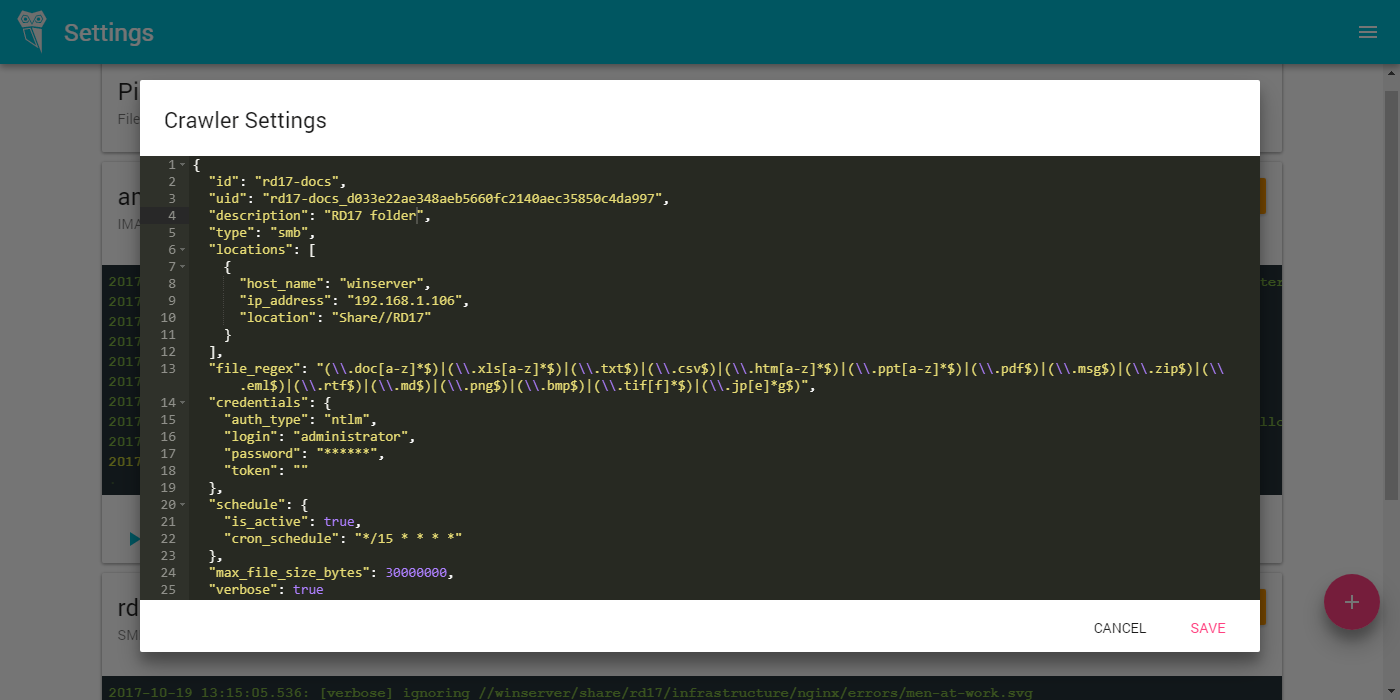
- Watch the process of indexing your documents on the statistics page
- Use search with tags and other goodies.
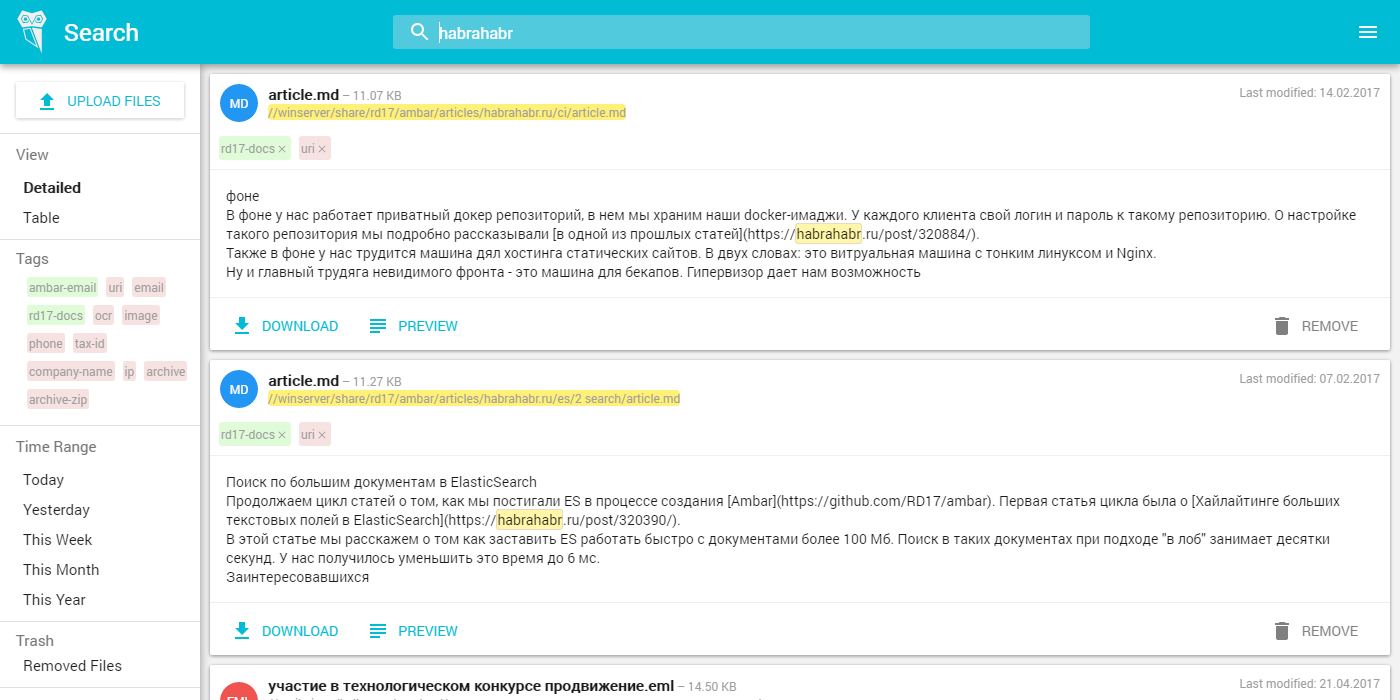
Total
In this short article we shared our pain associated with large file dumps in companies and our approach to solving this problem.
Thanks for attention!
')
Source: https://habr.com/ru/post/340518/
All Articles