The course of the young fighter PostgreSQL

I want to share useful techniques for working with PostgreSQL (other DBMS have similar functionality, but may have a different syntax).
I will try to cover a variety of topics and techniques that will help when working with data, trying not to delve into the detailed description of a particular functionality. I liked such articles when I was studying on my own. It's time
')
This material will be useful to those who have fully mastered the basic skills of SQL and want to learn further. I advise you to perform and experiment with examples in pgAdmin 'e, I made all the SQL queries executable without deploying any dumps.
Go!
1. Using temporary tables
When solving complex problems, it is difficult to place a solution in one request (although many try to do so). In such cases, it is convenient to place any intermediate data in a temporary table for later use.
Such tables are created as normal, but with the keyword TEMP , and are automatically deleted after the session.
The ON COMMIT DROP key automatically deletes the table (and all objects associated with it) when a transaction is completed.
Example:
ROLLBACK; BEGIN; CREATE TEMP TABLE my_fist_temp_table -- ON COMMIT DROP -- AS SELECT 1 AS id, CAST ('- ' AS TEXT) AS val; ------------ : ------------------ -- , . ALTER TABLE my_fist_temp_table ADD COLUMN is_deleted BOOLEAN NOT NULL DEFAULT FALSE; -- , , , CREATE UNIQUE INDEX ON my_fist_temp_table (lower(val)) WHERE is_deleted = FALSE; -- /, -- ( ) VAL, -- UPDATE my_fist_temp_table SET id=id+3; -- / SELECT * FROM my_fist_temp_table; --COMMIT; 2. Frequently Used Abbreviated Postgres Syntax
- Data type conversion.
Expression:
SELECT CAST ('365' AS INT); can be written less cumbersome:
SELECT '365'::INT; - Abbreviated construction entry (I) LIKE '% text%'
LIKE perceives patterned expressions . Details in the manual
LIKE operator can be replaced by ~~ (two tildes)
ILIKE operator can be replaced by ~~ * (two tildes with an asterisk)
Regular expressions search (syntax different from LIKE)
~ (one tilde) operator accepts regular expressions
~ * operator (one tilde and asterisk) case-insensitive version ~
I will give an example of searching in different ways strings that contain the word text
| Short syntax | Description | Analog (I) LIKE |
|---|---|---|
| ~ 'text' or ~~ '% text%' | Checks if the expression is case sensitive | LIKE '% text%' |
| ~ * 'text' ~~ * '% text%' | Checks if the expression is case-insensitive. | ILIKE '% text%' |
| ! ~ 'text' ! ~~ '% text%' | Checks case inconsistency | NOT LIKE '% text%' |
| ! ~ * 'text' ! ~~ * '% text%' | Checks case-insensitive expression | NOT ILIKE '% text%' |
3. Common table expressions (CTE). WITH construction
Very convenient design, allows you to put the result of the query in a temporary table and immediately use it.
Examples will be primitive to capture the essence.
a) Simple SELECT
WITH cte_table_name AS ( -- SELECT schemaname, tablename -- FROM pg_catalog.pg_tables -- , ORDER BY 1,2 ) SELECT * FROM cte_table_name; -- -- In this way, you can 'wrap up' any queries (even UPDATE, DELETE and INSERT , this will be discussed below) and use their results in the future.
b) You can create multiple tables by listing them as described below.
WITH table_1 (col,b) AS (SELECT 1,1), -- table_2 (col,c) AS (SELECT 2,2) -- --,table_3 (cool,yah) AS (SELECT 2,2 from table_2) -- , SELECT * FROM table_1 FULL JOIN table_2 USING (col); c) You can even embed the above construction into another (or more) WITH
WITH super_with (col,b,c) AS ( /* */ WITH table_1 (col,b) AS (SELECT 1,1), table_2 (col,c) AS (SELECT 2,2) SELECT * FROM table_1 FULL JOIN table_2 USING (col)-- ) SELECT col, b*20, c*30 FROM super_with; In terms of performance, it should be said that you should not put data in the WITH section that will be largely filtered by subsequent external conditions (outside the brackets of the query), because the optimizer will not be able to build an effective query. The most convenient way to put in CTE results that need to be addressed several times.
4. Function array_agg (MyColumn).
Values are stored in a relational database separately (attributes for one object can be presented in several lines). To transfer data to any application, it is often necessary to collect data in a single row (cell) or array.
In PostgreSQL, the array_agg () function exists for this purpose; it allows you to collect data from the entire column into an array (if sampling from one column).
When using GROUP BY , the data of any column relative to each group will be included in the array.
Immediately describe another function and move on to an example.
array_to_string (array [], ';') allows you to convert an array into a string: the first parameter is an array, the second is a convenient separator in single quotes (apostrophes). As a separator you can use
special characters
Tab \ t - for example, will allow to insert values into columns when inserting a cell into EXCEL (use this: array_to_string (array [], E '\ t') )
Line feed \ n - decomposes the array values in rows in one cell (use this: array_to_string (array [], E '\ n') - I will explain below why)
Line feed \ n - decomposes the array values in rows in one cell (use this: array_to_string (array [], E '\ n') - I will explain below why)
Example:
-- WITH my_table (ID, year, any_val) AS ( VALUES (1, 2017,56) ,(2, 2017,67) ,(3, 2017,12) ,(4, 2017,30) ,(5, 2020,8) ,(6, 2030,17) ,(7, 2030,50) ) SELECT year ,array_agg(any_val) -- ( ) ,array_agg(any_val ORDER BY any_val) AS sort_array_agg -- ( 9+ Postgres) ,array_to_string(array_agg(any_val),';') -- ,ARRAY['This', 'is', 'my' , 'array'] AS my_simple_array -- FROM my_table GROUP BY year; -- Will give the result:

Perform the reverse action. We expand the array into strings using the UNNEST function, and at the same time demonstrate the SELECT columns INTO table_name . I'll put it in the spoiler so that the article doesn't swell too much.
UNNEST request
Result:
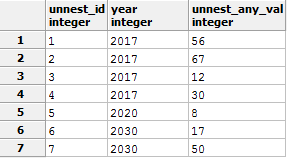
-- 1 -- tst_unnest_for_del, SELECT INTO -- , , . -- , production - , DROP TABLE IF EXISTS tst_unnest_for_del; /* IF EXISTS , */ WITH my_table (ID, year, any_val) AS ( VALUES (1, 2017,56) ,(2, 2017,67) ,(3, 2017,12) ,(4, 2017,30) ,(5, 2020,8) ,(6, 2030,17) ,(7, 2030,50) ) SELECT year ,array_agg(id) AS arr_id -- (id) ,array_agg(any_val) AS arr_any_val -- (any_val) INTO tst_unnest_for_del -- !! FROM my_table GROUP BY year; --2 Unnest SELECT unnest(arr_id) unnest_id -- id ,year ,unnest(arr_any_val) unnest_any_val -- any_val FROM tst_unnest_for_del ORDER BY 1 -- id, Result:
5. Keyword RETURNIG *
specified after INSERT, UPDATE or DELETE requests allows you to see the lines affected by the modification (usually the server reports only the number of modified lines).It is convenient in conjunction with BEGIN to look at what exactly the request will affect, in case of uncertainty as a result or to send any id to the next step.
Example:
--1 DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS , */ CREATE TABLE for_del_tmp -- AS -- SELECT generate_series(1,1000) AS id, -- 1000 random() AS values; -- --2 DELETE FROM for_del_tmp WHERE id > 500 RETURNING *; /* , RETURNING * - test, SELECT (. RETURNING id,name)*/ Can be used in conjunction with CTE , organizing a
PS
I was very confused, I'm afraid that it was difficult, but I tried to comment on everything.
--1 DROP TABLE IF EXISTS for_del_tmp; /* IF EXISTS , */ CREATE TABLE for_del_tmp -- AS -- SELECT generate_series(1,1000) AS id, -- 1000 ((random()*1000)::INTEGER)::text as values; /* . PS Postgre 9.2 Random() , 1000, , INTEGER , , .. , TEXT*/ --2 DELETE FROM for_del_tmp WHERE id > 500 RETURNING *; -- , --3 WITH deleted_id (id) AS ( DELETE FROM for_del_tmp WHERE id > 25 RETURNING id -- , id CTE "deleted_id" ) INSERT INTO for_del_tmp -- INSERT SELECT id, ' ' || now()::TIME || ' , ' || timeofday()::TIMESTAMP /* , ( , , )*/ FROM deleted_id -- "for_del_tmp" RETURNING *; -- -- , . --4 SELECT * FROM for_del_tmp; -- , Thus, the data will be deleted, and the deleted values will be passed to the next stage. It all depends on your imagination and goals. Before using complex constructions, be sure to read the documentation of your version of the DBMS! (when parallel combination INSERT, UPDATE or DELETE there are subtleties)
6. Save query result to file
The COPY team has many different parameters and assignments, I will describe the simplest application for familiarization.
COPY ( SELECT * FROM pg_stat_activity /* . : */ --) TO 'C:/TEMP/my_proc_tst.csv' -- . Windows ) TO '/tmp/my_proc_tst.csv' -- . LINUX --) TO STDOUT -- pgAdmin WITH CSV HEADER -- . 7. Run a query on another database
Not so long ago I found out that it is possible to address a request to another database, for this purpose there is a dblink function ( all details in the manual )
Example:
SELECT * FROM dblink( 'host=localhost user=postgres dbname=postgres', /* host user , */ 'SELECT '' : '' || current_database()' /* . , , ( ). */ ) RETURNS (col_name TEXT) UNION ALL SELECT ' : ' || current_database(); 
If an error occurs:
"ERROR: function dblink (unknown, unknown) does not exist"You must install the extension with the following command:
CREATE EXTENSION dblink; 8. Function similarity
The function of determining the similarity of one value to another.
Used to compare text data that was similar, but not equal to each other (there were typos). Saved a lot of time and nerves, minimizing manual binding.
similarity (a, b) gives a fractional number from 0 to 1, the closer to 1, the more accurate the match.
Let's move on to an example. With the help of WITH we organize a temporary table with fictional data (and specially distorted to demonstrate the function), and we will compare each line with our text. In the example below, we will look for what looks more like Romashka LLC (we substitute the function in the second parameter).
WITH company (id,c_name) AS ( VALUES (1, ' ') UNION ALL /* PS UNION ALL , UNION, .. , */ VALUES (2, ' ""') UNION ALL VALUES (3, ' ') UNION ALL VALUES (4, ' ""') UNION ALL VALUES (5, ' ') UNION ALL VALUES (6, ' ') UNION ALL VALUES (7, ' ') UNION ALL VALUES (8, 'ZAO ') UNION ALL VALUES (9, ' ?') UNION ALL VALUES (10, ' 33') UNION ALL VALUES (11, ' ""') UNION ALL VALUES (12, ' " "') UNION ALL VALUES (13, ' " "') ) SELECT *, similarity(c_name, ' ""') ,dense_rank() OVER (ORDER BY similarity(c_name, ' ""') DESC) AS " " -- , FROM company WHERE similarity(c_name, ' ""') >0.25 -- 0 1, 1, ORDER BY similarity DESC; We get the following result:
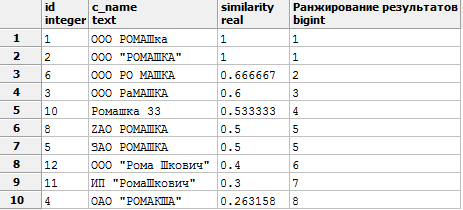
If an error occurs
"ERROR: function similarity (unknown, unknown) does not exist"You must install the extension with the following command:
CREATE EXTENSION pg_trgm; The example is more complicated
We get the following result:
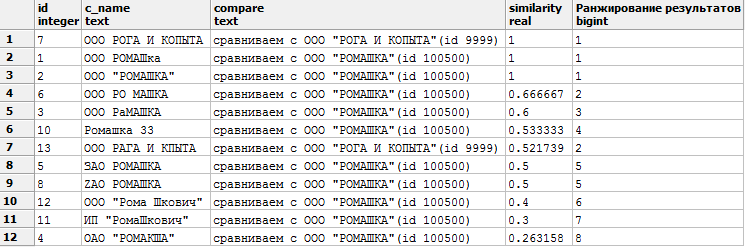
WITH company (id,c_name) AS ( -- VALUES (1, ' ') ,(2, ' ""') ,(3, ' ') ,(4, ' ""') ,(5, ' ') ,(6, ' ') ,(7, ' ') ,(8, 'ZAO ') ,(9, ' ?') ,(10, ' 33') ,(11, ' ""') ,(12, ' " "') ,(14, ' " "') ,(13, ' ') ), compare (id, need) AS -- (VALUES (100500, ' ""') ,(9999, ' " "') ) SELECT c1.id, c1.c_name, ' ' || c2.need, similarity(c1.c_name, c2.need) ,dense_rank() OVER (PARTITION BY c2.need ORDER BY similarity(c1.c_name, c2.need) DESC) AS " " -- , FROM company c1 CROSS JOIN compare c2 WHERE similarity(c_name, c2.need) >0.25 -- 0 1, 1, ORDER BY similarity DESC; We get the following result:
Sort by similarity desc . The first results see the most similar lines (1 — complete similarity).
It is not necessary to display the value of similarity in a SELECT , you can simply use it in the WHERE similarity condition (c_name, 'Romashka LLC')> 0.7
and set the parameter that suits us.
PS I would be grateful if you tell me what else there are ways to compare text data. I tried to remove everything except letters / numbers with regular expressions, and compare them by equality, but this option does not work if there are typos.
9. Window OVER () functions (PARTITION BY __ ORDER BY __)
Almost describing this very powerful tool in his draft, I discovered
10. A multiple template for LIKE
Task. You need to filter the list of users whose names should match certain patterns.
As always, I will provide the simplest example:
-- CREATE TEMP TABLE users_tst (id, u_name) AS (VALUES (1::INT, NULL::VARCHAR(50)) ,(2, ' .') ,(3, ' .') ,(4, ' .') ,(5, ' .') ,(6, ' .') ,(7, ' .') ,(8, ' .') ,(9, ' .') ); We have a request that performs its function, but becomes cumbersome with a large number of filters.
SELECT * FROM users_tst WHERE u_name LIKE '%' OR u_name LIKE '%%' OR u_name LIKE ' .' OR u_name LIKE '%' -- .. Demonstrate how to make it more compact:
SELECT * FROM users_tst WHERE u_name LIKE ANY (ARRAY['%', '%%', ' .', '%']) You can do interesting tricks using a similar approach.
Write in the comments if you have any thoughts on how to rewrite the original query.
11. Several useful features
NULLIF (a, b)
There are situations when a certain value must be treated as NULL.
For example, zero-length strings ('' - empty strings) or zero (0).
You can write CASE, but more concisely use the function NULLIF, which has 2 parameters, with equality of which returns NULL, otherwise displays the original value.
SELECT id ,param ,CASE WHEN param = 0 THEN NULL ELSE param END -- CASE ,NULLIF(param,0) -- NULLIF ,val FROM( VALUES( 1, 0, ' 0' ) ) AS tst (id,param,val); COALESCE selects the first non-NULL value.
SELECT COALESCE(NULL,NULL,-20,1,NULL,-7); -- -20 GREATEST selects the highest value listed.
SELECT GREATEST(2,1,NULL,5,7,4,-9); -- 7 LEAST selects the lowest value listed.
SELECT LEAST(2,1,NULL,5,7,4,-9); -- -9 PG_TYPEOF indicates the data type of the column.
SELECT pg_typeof(id), pg_typeof(arr), pg_typeof(NULL) FROM (VALUES ('1'::SMALLINT, array[1,2,'3',3.5])) AS x(id,arr); -- smallint, numeric[] unknown PG_CANCEL_BACKEND stop unwanted processes in the database
SELECT pid, query, * FROM pg_stat_activity -- . postgres PID PROCPID WHERE state <> 'idle' and pid <> pg_backend_pid(); -- SELECT pg_terminate_backend(PID); /* PID , , , */ SELECT pg_cancel_backend(PID); /* PID . , - KILL -9 LINUX */ More in the manual
PS
Attention! Do not kill the hung process through the KILL-9 console or task manager.
This can lead to the collapse of the database, data loss and long automatic database recovery.
SELECT pg_cancel_backend(pid) FROM pg_stat_activity -- WHERE state <> 'idle' and pid <> pg_backend_pid(); Attention! Do not kill the hung process through the KILL-9 console or task manager.
This can lead to the collapse of the database, data loss and long automatic database recovery.
12. Escaping characters
I'll start with the basics.
In SQL, string values are framed with an apostrophe (single quote).
Numeric values can not be framed with apostrophes, and to separate the fractional part, you must use a point, because comma will be interpreted as a delimiter
SELECT ' ', 365, 567.6, 567,6 result:

All is well, until it is required to display the apostrophe sign itself .
For this there are two shielding methods (known to me)
SELECT 1, ' '' '''' ' -- '' UNION ALL SELECT 2, E' \' \'\' ' -- , , E , \ The result is the same:

In PostgreSQL, there is a more convenient way to use data, without escaping characters. You can use almost any character in the line framed with two dollar signs $$ .
Example:
select $$ '' ', E'\' $$ I get the data in its original form:

If this is not enough, and inside you need to use two dollar symbols in a row $$ , then Postgres allows you to set your own "limiter". It is only between two dollars to write your own text, for example:
select $uniq_tAg$ '' ', E'\', $$ $any_text$ $uniq_tAg$ We will see our text:

For myself, this method was discovered not so long ago, when I began to study the writing of functions.
Conclusion
I hope this material will help learn a lot of new beginners and "srednichkam." I myself am not a developer, and I can only call myself a SQL buff, so it’s up to you how to use the described techniques.
I wish you success in learning SQL. I am waiting for comments and thank you for reading!
UPD . There was a sequel
Source: https://habr.com/ru/post/340460/
All Articles