How we made npm packages work in a browser

During the initial development of the CodeSandbox project, I always ignored support for npm dependencies. I thought it was impossible to install an arbitrary, random number of packages in the browser, my brain just refused to think about it.
Today npm support is one of the defining capabilities of CodeSandbox, so somehow we managed to implement it. For the feature to work under any scenarios, we had to do quite a few iterations, rewriting the code many times, and even today we can still improve the logic. I will tell you how we started supporting npm, what we have today and what we can do to improve it.
"First version
I just didn’t know how to tackle it, so I started with a very simple version of npm support:
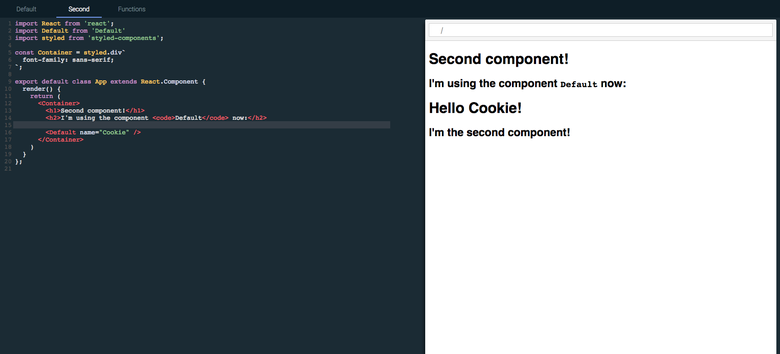
The first version, the import of stylized components and React (November 25, 2016)
This version was very simple. So much so that in fact there was no support, I just locally installed the dependencies and made a stub for each call as an already established dependency. Of course, the scalability of up to 400 thousand packages of different versions does not smell here.
Although this version is useless, it was nice to see that I made at least two dependencies work in a sandbox environment.
Webpack version
I was satisfied with the first version, and it seemed to me that it was enough for MVP (the first release of CodeSandbox). I had no idea that it was possible to establish any dependence at all without the use of magic. Until I came across https://esnextb.in/ . The guys already supported any dependencies from npm, it was enough to define them in package.json - and everything worked in a magical way!
It was a great lesson for me. I didn’t even think about such npm support because I considered it unreal. But, having seen the living proof of reality, I began to think a lot about it. First, it was necessary to explore the possibilities before discarding the idea.
In my thoughts, I have complicated the task too much. My first version didn't fit in my mind, so I drew a diagram:
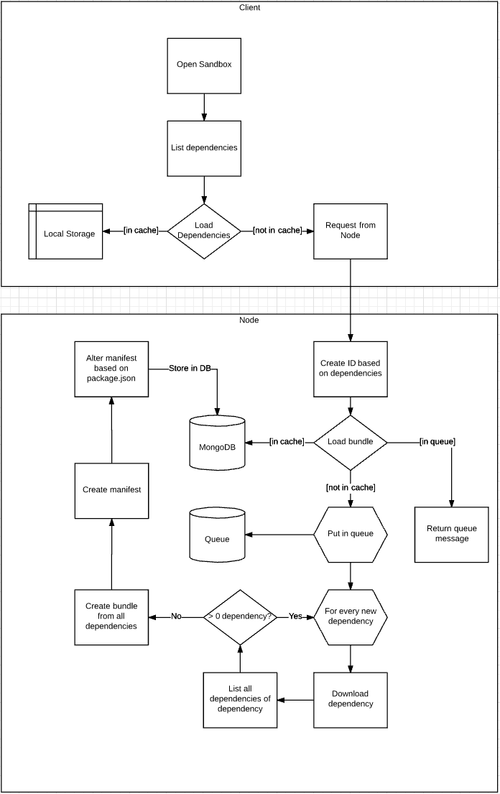
The first idea is probably wrong.
This approach had one advantage: the real implementation is much simpler than expected!
I found out that the WebPack DLL plugin could bundle dependencies and issue a JS package (bundle) with a manifest. This manifesto looked like this:
{ "name": "dll_bundle", "content": { "./node_modules/fbjs/lib/emptyFunction.js": 0, "./node_modules/fbjs/lib/invariant.js": 1, "./node_modules/fbjs/lib/warning.js": 2, "./node_modules/react": 3, "./node_modules/fbjs/lib/emptyObject.js": 4, "./node_modules/object-assign/index.js": 5, "./node_modules/prop-types/checkPropTypes.js": 6, "./node_modules/prop-types/lib/ReactPropTypesSecret.js": 7, "./node_modules/react/cjs/react.development.js": 8 } } Each path is associated with a module ID. If I need react, then just call dll_bundle(3) , and I will get a React! It was perfect for us, so I came up with just such a real system:
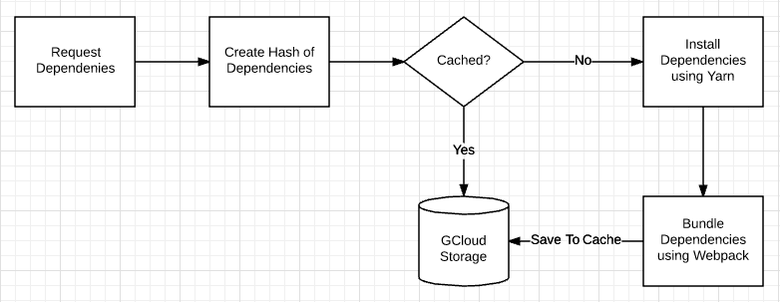
The source code of the service is here . The service also contains code for publishing any sandbox in npm, we later abandoned this function.
For each request to the packer, I created a new directory in /tmp/:hash , started yarn add ${dependencyList} and allowed WebPack to build the package. I saved the result in gcloud as a cache. It turns out to be much simpler than in the diagram, mainly because I replaced the installation of dependencies with Yarn and collected them in packages using WebPack.
When loading the sandbox, before performing the execution, we first checked the presence of the manifest and the package. During the analysis, we called dll_bundle(:id) for each dependency. This solution worked perfectly, I created the first version with normal support for npm-dependencies!
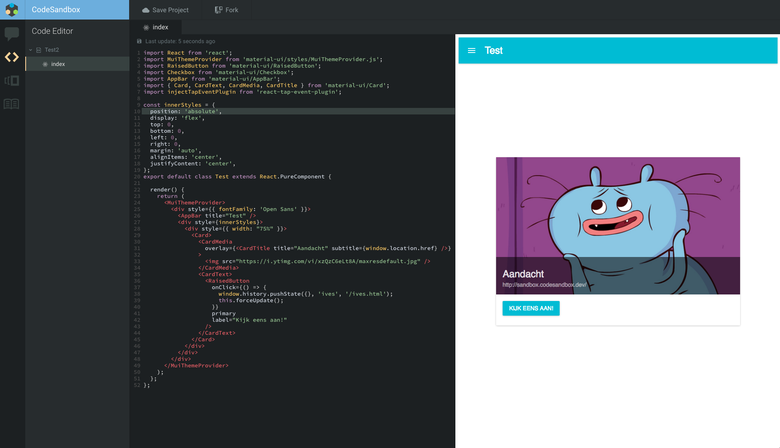
Hooray! We have an interface in the style of Material Design and dynamically executed React! (December 24, 2016)
The system still had a big limitation: it did not support files that were not in the dependency graph of the WebPack. This means that, for example, require('react-icons/lib/fa/fa-beer') will not work, because it will never be requested first by the dependency input point.
Nevertheless, I created a release of CodeSandbox with such support and contacted Christian Alfoni, the author of WebPackBin . To support npm dependencies, we used very similar systems and faced the same limitations. Therefore, we decided to join forces and create an absolute packer!
Webpack with posts
The “absolute” packer received the same functionality as the previous one, except for the algorithm created by Christian, which added files to the package depending on their importance. We manually added entry points to ensure that WebPack also packs these files. After multiple system settings, it began to work with any (?) Combination. So we could already request React icons and CSS files.
The new system received an architectural upgrade: we had only one dll service serving the load balancer and cache. Packaging was done by several packers, which could be added dynamically.

We wanted our packaging service to be available to everyone. Therefore, we made a site that explained the operation of the service and use cases. It brought us fame, we were even mentioned on the CodePen blog !
But the "absolute" packer had some limitations and shortcomings. As the popularity grew, the costs grew exponentially and we cached by combination of packages. This means that when adding a dependency, you had to recompile the whole combination.
Serverless processing (serverless)
I always wanted to try this cool technology - serverless processing. With its help, you can determine the function that will be executed on request.
It will start, process the request and after some time kill itself. This means very high scalability: if you receive a thousand simultaneous requests, you can instantly start a thousand servers. But at the same time pay only for the real time of the servers.
It sounds perfect for our service: it does not work all the time, and we need high consistency in case of multiple requests being received simultaneously. So I started experimenting with the appropriately named Serverless framework .
The change of our service went smoothly (thanks to Serverless!), After two days I had a working version. I created three serverless functions:
- Metadata handler: this service resolved versions and peerDependencies, and also requested the packer function.
- Packer: this service installs and bundles dependencies.
- Minifikator (Uglifier) was responsible for asynchronous minification (uglifying) of the resulting packets.
I launched a new service next to the old one, everything worked perfectly! We predicted spending at $ 0.18 per month (compared with the previous $ 100), and the response time improved by 40-700%.
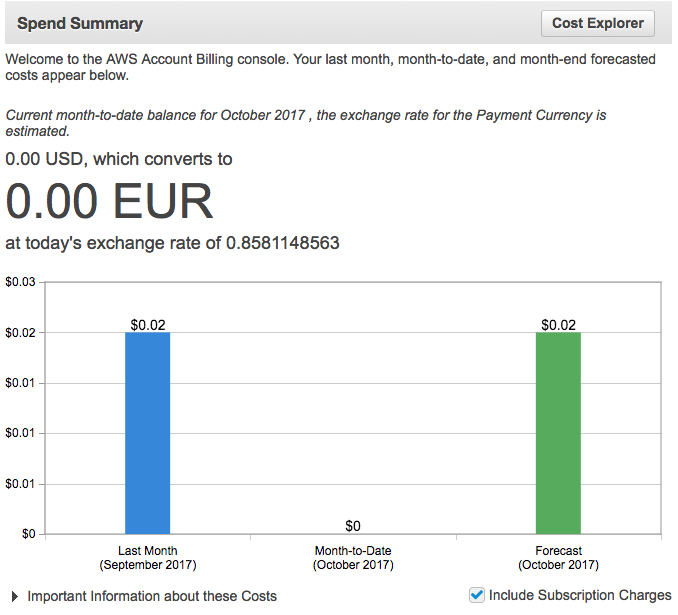
A few days later I noticed one restriction: the lambda function had only 500 MB of disk space. This means that some dependency combinations could not be installed. This was unacceptable, and I went back to drawing schemes.
Revise serverless processing
A couple of months passed, and I released a new packer for CodeSandbox. It was very powerful and supported more libraries like Vue and Preact. Thanks to this, we have interesting requests. For example: if you want to use React libraries in Preact, then you need to associate require('react') with require('preact-compat') . For Vue, you may need to resolve (resolve) @/components/App.vue for sandbox files. Our packer does not do this for dependencies, while others do.
I began to think that perhaps we would shift the packaging task to the browser wrapper. If you simply send the corresponding files to the browser, then as a result, its packer will assemble the dependencies into packages. So it will be faster, because we do not process the whole package, but only a part.
This approach has a big advantage: we can independently install and cache dependencies. Or simply merge the dependency files on the client. This means that if you request a new dependency on top of an existing one, we only need to collect the files for the new dependency! This solves the 500 MB problem for AWS Lambda, because we only install one dependency. So you can throw WebPack out of the packer, because it is now fully responsible for calculating the relevant files and sending them.
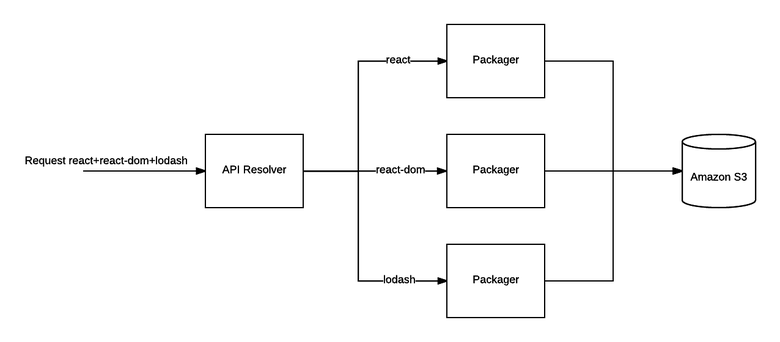
Parallel packaging of our dependencies
Note: you can throw out the packer and dynamically query each file from unpkg.com. Perhaps this is faster than my approach. But I decided to leave the packer for the time being (at least for the editor), because I want to provide offline support. This is only possible if you have all the possible relevant files.
Work in practice
When requesting a combination of dependencies, we first check whether it is already stored in S3. If not, then we request a combination from the API service, and the latter requests all packers separately for each dependency. If we get 200 OK in response, then we request S3 again.
The packer installs dependencies using Yarn and, bypassing the AST of all files in the input point directory, finds all relevant files. It searches for require statements and adds to the file list. This is done recursively, and as a result we get a dependency graph. Example output ( react@latest ):
{ "aliases": { "asap": "asap/browser-asap.js", "asap/asap": "asap/browser-asap.js", "asap/asap.js": "asap/browser-asap.js", "asap/raw": "asap/browser-raw.js", "asap/raw.js": "asap/browser-raw.js", "asap/test/domain.js": "asap/test/browser-domain.js", "core-js": "core-js/index.js", "encoding": "encoding/lib/encoding.js", "fbjs": "fbjs/index.js", "iconv-lite": "iconv-lite/lib/index.js", "iconv-lite/extend-node": false, "iconv-lite/streams": false, "is-stream": "is-stream/index.js", "isomorphic-fetch": "isomorphic-fetch/fetch-npm-browserify.js", "js-tokens": "js-tokens/index.js", "loose-envify": "loose-envify/index.js", "node-fetch": "node-fetch/index.js", "object-assign": "object-assign/index.js", "promise": "promise/index.js", "prop-types": "prop-types/index.js", "react": "react/index.js", "setimmediate": "setimmediate/setImmediate.js", "ua-parser-js": "ua-parser-js/src/ua-parser.js", "whatwg-fetch": "whatwg-fetch/fetch.js" }, "contents": { "react/index.js": { "requires": [ "./cjs/react.development.js" ], "content": "/* code */" }, "object-assign/index.js": { "requires": [], "content": "/* code */" }, "fbjs/lib/emptyObject.js": { "requires": [], "content": "/* code */" }, "fbjs/lib/invariant.js": { "requires": [], "content": "/* code */" }, "fbjs/lib/emptyFunction.js": { "requires": [], "content": "/* code */" }, "react/cjs/react.development.js": { "requires": [ "object-assign", "fbjs/lib/warning", "fbjs/lib/emptyObject", "fbjs/lib/invariant", "fbjs/lib/emptyFunction", "prop-types/checkPropTypes" ], "content": "/* code */" }, "fbjs/lib/warning.js": { "requires": [ "./emptyFunction" ], "content": "/* code */" }, "prop-types/checkPropTypes.js": { "requires": [ "fbjs/lib/invariant", "fbjs/lib/warning", "./lib/ReactPropTypesSecret" ], "content": "/* code */" }, "prop-types/lib/ReactPropTypesSecret.js": { "requires": [], "content": "/* code */" }, "react/package.json": { "requires": [], "content": "/* code */" } }, "dependency": { "name": "react", "version": "16.0.0" }, "dependencyDependencies": { "asap": "2.0.6", "core-js": "1.2.7", "encoding": "0.1.12", "fbjs": "0.8.16", "iconv-lite": "0.4.19", "is-stream": "1.1.0", "isomorphic-fetch": "2.2.1", "js-tokens": "3.0.2", "loose-envify": "1.3.1", "node-fetch": "1.7.3", "object-assign": "4.1.1", "promise": "7.3.1", "prop-types": "15.6.0", "setimmediate": "1.0.5", "ua-parser-js": "0.7.14", "whatwg-fetch": "2.0.3" } } Benefits
Saving
I deployed a new packer on October 5th, and in two days we paid a ridiculous $ 0.02 dollar! And this is for the creation of the cache. Giant savings compared to $ 100 per month.
Higher performance
A new combination of dependencies you can get in 3 seconds. Any combination. On the old system, sometimes it took a minute. If the combination is cached, you will receive it in 50 milliseconds with a fast connection. We cache with Amazon Cloudfront around the world. Also, our sandbox is faster, because now we parse and execute only the relevant .js files.
More flexibility
Our packager now handles dependencies as if they were local files. This means that our error stack traces have become much cleaner, we can now include any dependency files (.scss, .vue, etc.) and easily maintain aliases. All this works as if the dependencies are installed locally.
Release
I started using the new packer next to the old one to build a cache. In two days, 2000 different combinations and 1400 different dependencies were cached. I want to intensely test the new version before fully switching to it. You can try to enable it in your settings.
Source code It is still unsightly, soon I will clean it, write README.md, etc.
Use Serverless!
I am very impressed with this technology, it makes it incredibly easy to scale and manage servers. The only thing that always kept me, is a very complicated setup, but the developers from serverless.com have greatly simplified it. Very grateful for their work, I think that serverless is the future of many forms of applications.
Future
We can still greatly improve our system. I want to explore the dynamic queries required in embedding and offline saving. It is difficult to strike a balance, but it should be possible. You can start independently cache dependencies in the browser, based on what it allows you to do. In this case, you sometimes do not even need to download new dependencies when visiting a new sandbox with a different combination of dependencies. I also want to explore dependency resolution better. In the new system there is a possibility of a version conflict, which I want to exclude before giving up the old version.
In any case, I am very pleased with the result and intend to work on innovations for CodeSandbox!
')
Source: https://habr.com/ru/post/340418/
All Articles