Competition Topcoder "Konica-Minolta Pathological Image Segmentation Challenge". Member Notes
Hello! While we are waiting for Saturday and Avito Data Science Meetup: Computer Vision, I’ll tell you about my participation in the KONICA MINOLTA Pathological Image Segmentation Challenge machine learning competition . Although I spent only a few days on this, I was lucky to take 2nd place. Description of the solution and a detective story under the cut.

Task Description
It was necessary to develop an algorithm for the segmentation of areas in the images from the microscope. Apparently, these were some foci of cancer cells in the epithelium. In the picture below - what was given and how it should be done:
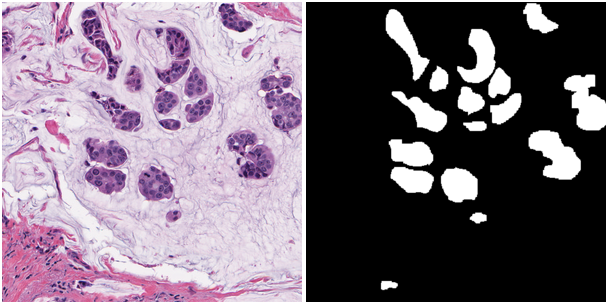
The training and test samples consisted of 168 and 162 such images, 500x500 pixels in size, respectively. The target metric is the arithmetic mean of F1-micro and instance-wise Dice x 1000000.
Lyrical digression with impressions of the site
The competition was held on the Topcoder website. Perhaps the reader this site reminds more about Olympiad programming than about machine learning and neural networks. But, apparently, the guys decided to be trendy too. It turned out that they are doubtful not only in terms of data preparation (see below), but also in terms of usability. To submit a solution, you must:
- predict train (!) and test;
- overtake the mask in txt, and do not forget to transpose them;
- pack the mask into the archive and drop it into your gdrive / dropbox / etc;
- enter the competition submission system and write a java-class that pulls the archive by reference.
Submits can be sent every 2 hours. Once every 15 minutes check your train is available. Accordingly, if at some point something went wrong - we walk for 2 hours. I threw the files in the archive into the folder, but not to the root - it’s a pity, we didn’t find the mask, go check, you have 2 hours. I forgot to throw the train masks - in 2 hours be more attentive. I'm not saying that it is easy to confuse with such a system and send a solution that has already been sent. Well, it's very cool, when at one o'clock in the morning you finally finished the next improver, compiled the archive and made a mistake - it remains either not to sleep, or to wait until the morning.
Also, there was no option to choose some kind of your submit as the final one. He just had to send it last. And not to be mistaken, of course. Looking ahead, I must say that the Chinese platform challenger.ai surpassed the topcoder in the uproarness, but this is about next time.
First iteration
I must say that I did not want to participate for a long time, because this is again a segmentation and the site is strange. But Vladimir Iglovikov and Evgeny Nizhibitsky shoved me to join, for which they had a special thanks.
As usual, I decided to start with baseline. As him, I chose the ZFTurbo code , which he brushed and laid out after the kaggle with satellites . There were already examples of models and code for their training. I added it to the division into five folds. I made them by sorting all the masks of the train by area and dividing them so that in each fold the distribution of areas was the same. I was hoping to stratify folds as much as I was wrong ...
From augmentations, I left the standard corners, crop, resize. Adam was chosen as an optimizer.
Second iteration
While the models were being trained, I decided to improve the baseline and started by looking carefully at the pictures. For a start, I used mathematics and realized that the number of shots in the train is divided into 6, so it’s better to do 6 folds, not 5. It seemed to me that I don’t really understand where some of the fabrics end and others start, so I just combined each training part of the fold in one huge mask. And then I pulled random patches 1.5 times more out of it than the input of the neural network. More aggressive augmentations were applied to them using the imgaug library.
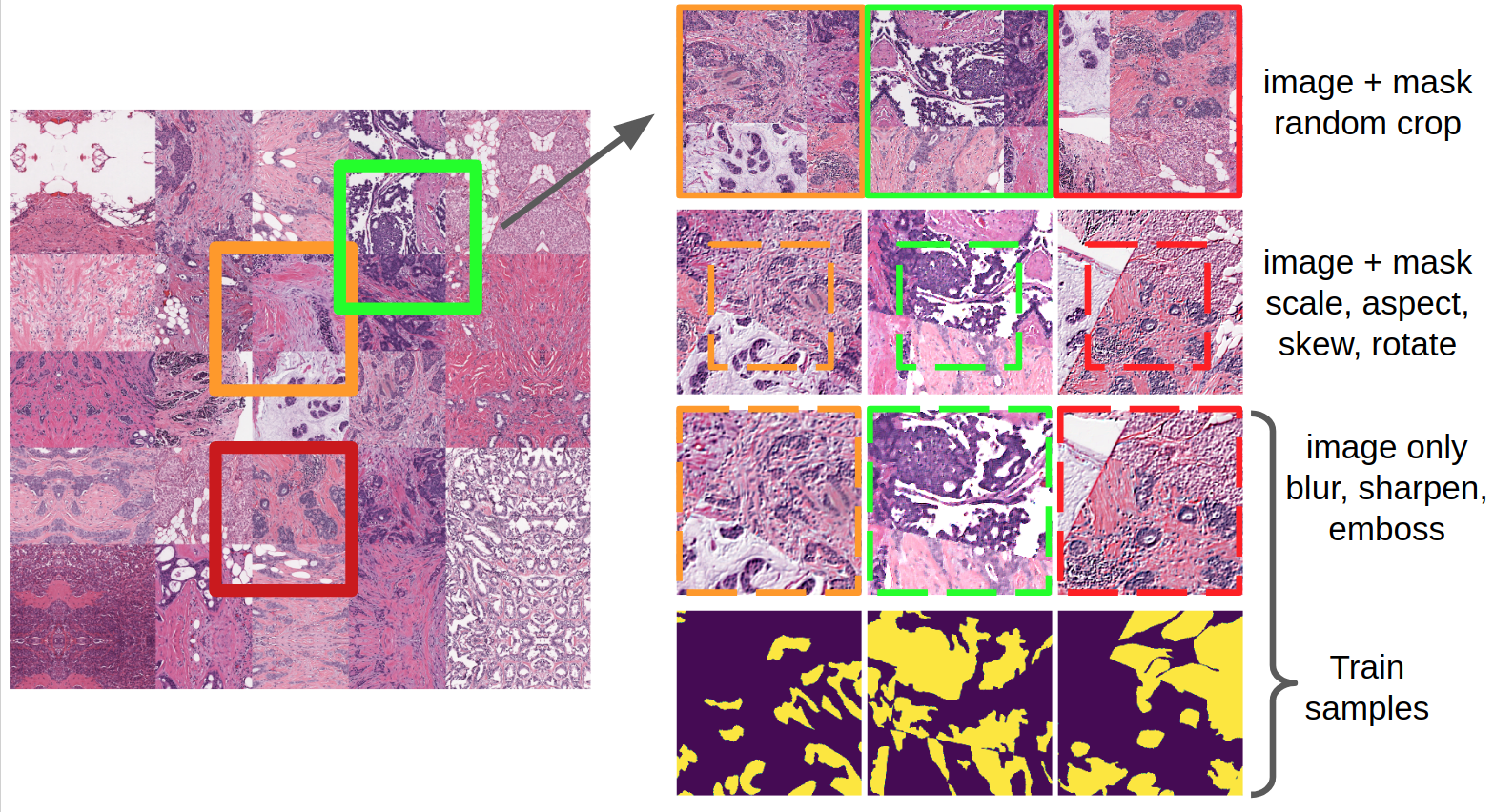
It is worth saying that imgaug uses a skimage, which is not very fast as it is written in python. To overcome this flaw, I used the pytorch dataloader. It is awesome: you need to write essentially one function get_sample, which prepares x and y (in this case, a picture and a mask), and the iterator itself collects the batch in several threads with a buffer. He is so cool that I use it even with c keras and mxnet. To do this, you need to tear out the batch tensors and overtake in numpy.
Also in the second iteration, I changed the learning strategy. At first, I trained Adam with a decrease in the Learning rate, then switched to SGD and at the end taught with SGD without augmentation of images associated with blues and sharps.
In addition, I simultaneously launched three trainings with different loss functions: Binary Cross Entropy (BCE), BCE - log (Jaccard), BCE - log (Dice).

Third iteration
In the third call, I decided that it was time to get off the needle of the U-net architecture, to love other neural networks and start living. I carefully studied the pictures in the review and chose the Global Convolutional Network . Large kernels, factorized convolutions, border-specifying blocks, a goose in the pictures ... “Easygold!”, I thought. But for a couple of evenings I didn’t get a decent result on this architecture, the time was over and all the experiments moved to kaggle Carvana.
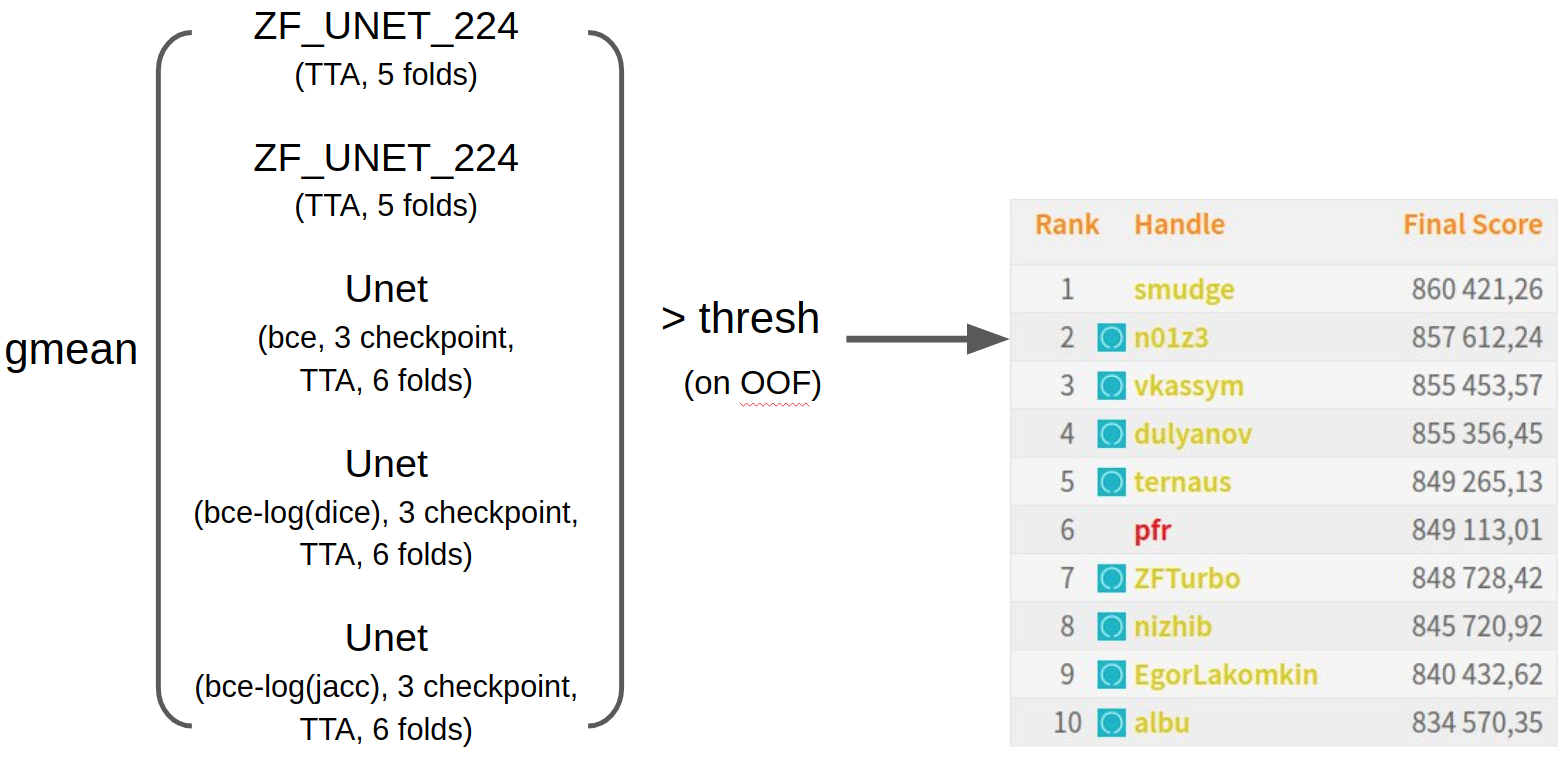
Final ensemble
As a result, I simply mixed all the neural networks trained by that time with the geometric mean. Picked up the thresholds on the OOF predictions and sent a few hours before the deadline. I was extremely surprised to find myself in second place, since the public part was 11th. In my opinion, I was incredibly lucky, because in the data there was one global joint about which below. Blue badges indicate members from the ODS.ai community. It is seen that the raid was a success. To follow the progress of our chat, you can subscribe to twitter
Detective CV-investigation of Evgeny Nizhibitsky
In the vast majority of competitions, local validation and leaderboard cease to coincide, starting with a certain quality of models. And this competence is no exception. However, the reason turned out to be much more interesting than just inhomogeneous partitioning.
In this competition, by analogy with the Kaggle Amazon from Space competition, Yevgeny Nizhibitsky decided to assemble an initial mosaic from which pictures were cut.
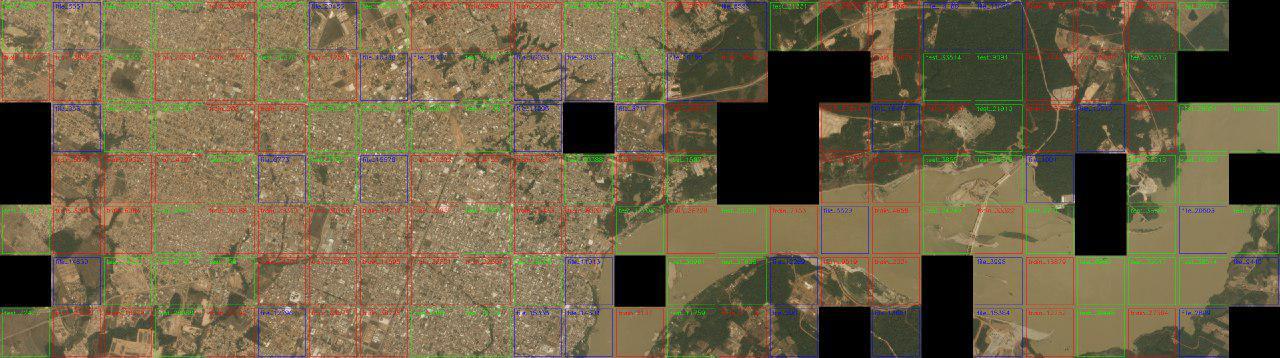
The search for neighbors was carried out on the basis of the L2 distance between pairs of boundaries for all possible images. Based on the comparison with the threshold, a table was created in which its neighbors and the distance to them were indicated for each image. Each time the pairs found were validated with the eyes, and both correct and incorrect were memorized separately. After that, the threshold increased slightly and the search was performed again.
The result of the mosaic was the understanding of the data structure - the training sample consists of 42 squares 1000x1000, each of which is cut into 4 smaller ones. The test sample into squares did not “fall apart”, but 120 out of 162 test images are also combined into 30 2x2 squares.
A disappointing conclusion can be made from this experiment - cross-validation with random splits of splits is not representative, because with 6 folds for each fixed 2x2 square, its parts with a probability of about 50% fall in the train and in the validation.
But curiosity did not fade away, why did 42 tiles from the test not unite in a mosaic? During one of the screening processes of incorrectly matched adjacent tiles, it was found that the erroneously glued dough and train tiles were not really connected along the border, but after turning, they would be fought by entire subregions!
A small proof-of-concept with matching on the SURF signs made it possible to find out that some test images were really just cut from the original large images of the train:

After trying to match all the pictures of the test, it turned out that 42 pictures from the test that do not come together in the mosaic are nothing but the sections of the train. That is, the orgi did the following.
- They took 42 original (1000x1000 size) pictures of the train and 30 pictures of the dough.
- Cut from them pictures of size 500x500.
- We decided that the test is not enough pictures (120).
- Dropped into the test randomly rotated patches from the train.
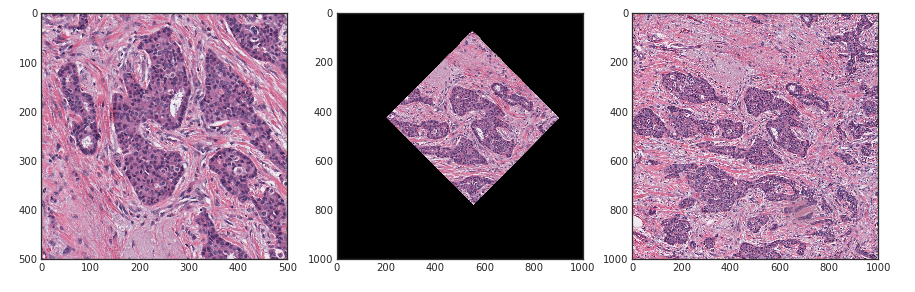
In the picture from left to right: one picture from the test, it is also rotated to fit the train, the original square is 2x2 train.
As a result, all the participants who did not clean the data in this way and who did not split the patients (that is, all the ODS.ai participants) were overwritten. At the same time, improvement on the leaderboard could occur for two reasons: improving the quality of the model on unknown data and retraining on rotated pieces of dough in the train. And since the splits were not informative, there was no sign of a correlation with local validation and leaderboard. After all, it was impossible even locally to understand: the model really learned to generalize or overfit on the train and due to this the validation improved.
I talked about this competency at the ML-training in Yandex , you can watch the video. Bonus, you can see the slides of Vladimir from mitap in H20 . Yevgeny Nizhibitsky will talk about a much more advanced approach to segmentation at the end of this week at a meetup at Avito . Registration is already closed, but you can join the online broadcast on the youtube channel AvitoTech on the day of the event from 12:30.
')
Source: https://habr.com/ru/post/340400/
All Articles