Why SQL prevails over NoSQL, and where it will lead in the future

SQL Awakens and Strikes Back to the Powers of Darkness - NoSQL
From the very beginning of the computer era, humanity has been collecting exponentially growing volumes of data, and with it growing demands on data storage, processing and analysis systems. Because of this, in the past decade, software developers have abandoned SQL as an outdated technology that could not scale with growing data volumes — and as a result, NoSQL databases appeared: MapReduce and Bigtable, Cassandra, MongoDB, and others.
However, now SQL is reborn. All major cloud service providers offer popular managed relational database services: Amazon RDS , Google Cloud SQL , Azure database for PostgreSQL (launched just this year), and others. According to Amazon, its Aurora database compatible with PostgreSQL and MySQL has become “ the fastest growing service in AWS history ”. Do not lose their popularity and SQL-interfaces on top of the Hadoop and Spark platforms. And last month , Kafka also launched SQL support . The authors of the article modestly admit that they themselves are developing a new time series database that fully supports SQL.
')
In this article, we will try to figure out why the pendulum has swung back toward SQL and what to expect for database design and analysis specialists.
Transferred to Alconost
Part 1. New Hope
To understand why SQL is returning, let's go back to the very beginning and see why this technology appeared at all.

Like all good stories, ours begins in the 70s
This relational database was born in the IBM Research division in the early 1970s. At that time, query languages were based on complex mathematical logic and no less complex notation. Two of the newly-baked candidates of science, Donald Chamberlin and Raymond Beuys, were impressed with the relational data model, but at the same time saw that the query language used would prevent its dissemination. They decided to develop a new query language, which, according to them, will be " more convenient for users who have not completed a course of mathematics or computer programming ."

Query languages before SQL (Sections A, B) versus SQL ( source )
Just imagine: there was no Internet, no personal computers yet, “C” just came out, and two young specialists in the field of computer systems already understood that “the success of the computer industry largely depends on the development of the user category, and not categories of trained computer professionals . " They needed a query language that reads as easily as English, but at the same time makes it possible to administer and work with databases.
As a result, SQL appeared, first introduced to the world in 1974, and in the next few decades it will become very popular. Because the software industry has established relational databases (for example, System R, Ingres, DB2, Oracle, SQL Server, PostgreSQL, MySQL, and many others), SQL has spread widely as a language for interacting with the database and has become common in an ecosystem that has become increasingly competitive. .
(Unfortunately, Raymond Beuys failed to see the success of SQL: he died of a brain aneurysm a month after one of the first SQL reports — at the age of only 26; he had a wife and a young daughter.)
For some time it seemed that SQL had completed its task and everything was going well ... But then the Internet appeared.
Part 2. NoSQL Strikes Back
When developing SQL, Chamberlin and Boyce did not know that they were working on another promising project in California, which would later spread widely and threaten the existence of SQL. This project - ARPANET , the date of his birth - October 29, 1969

The creators of the network ARPANET (not all), which eventually turned into a modern Internet ( source )
For a while, SQL led a quiet life — until in 1989 another engineer invented the World Wide Web .

Physicist who invented the Internet ( source )
The web and the Internet grew and spread like a weed, changing the familiar world in countless ways, but database specialists have a very specific headache: new sources that generate data in much larger volumes and much faster than before.
With the growth of the Internet, software developers have discovered that relational databases cannot cope with this load. There was outrage in the Force, as if millions of databases screamed in horror and just as suddenly became silent, overloaded.
Then, two new Internet giants made a breakthrough - they developed their own distributed non-relational systems designed to solve the problem of increasing data volumes: MapReduce ( 2004 publication ) and Bigtable ( 2006 publication ) from Google and Dynamo ( 2007 publication ) from Amazon. Having fallen on fertile soil, published articles gave a good yield of non-relational databases: Hadoop (based on an article on MapReduce, 2006 ), Cassandra (the authors were inspired by articles on Bigtable and Dynamo, 2008 ), MongoDB ( 2009 ), etc. The new systems were written mostly from scratch, so they did not use SQL either, which led to an increase in the “NoSQL movement”.
The creation of Google and Amazon has spread, it seems, much wider than the authors themselves have suggested. And it is clear why this happened: NoSQL-systems were new; they promised scaling and power; it seemed like a quick way to successful development. And then the problems started to come out.

A developer who succumbs to the temptation of NoSQL. Do not do this.
Soon, developers discovered that the lack of SQL actually limits significantly. Each NoSQL database had its own unique query language, and this meant the following: it was necessary to learn more languages (and train our colleagues); connecting these databases to applications was more difficult, which made writing tons of unstable glue code; the absence of a third-party ecosystem - which means that companies had to develop their own tools for visualization and work with the database.
NoSQL languages have just appeared, so they could not be called complete and complete: in relational databases, for example, for many years they worked on adding necessary functions to SQL (JOIN, for example). Such immaturity meant greater complexity at the application level. The lack of JOIN operators also led to denormalization, the result of which was “inflation” of data and lack of flexibility.
Some databases from the NoSQL camp added their own SQL-like query languages - for example, CQL in the Cassandra database. And often it only got worse: using the interface, which almost coincides with something more common, in fact required more mental effort, because in this case it is not known in advance which of the familiar functions are supported and which are not.

SQL-like query languages are like the “Holiday Special Edition” for Star Wars . Avoid imitation. (And in any case, do not look "Festive special issue.")
Some of the experts at an early stage saw problems in NoSQL (for example, DeWitt and Stonebriker - in 2008 ). Over time, they were joined by more and more software developers who had experienced these problems the hard way.
Part 3. Returning SQL
Being tempted at first by the “dark side”, software developers soon saw the light and gradually began to return to SQL.
First, on top of the Hadoop and (a little later) Spark platforms, SQL interfaces appeared, so that in the industry, under the “NoSQL” they began to understand “not only SQL” (good try, aha).
Then NewSQL appeared - “new SQL”, scalable databases with full SQL support. One of the first scalable DBs with online transaction processing (OLTP) was the H-Store ( 2008 publication ) of the Massachusetts Institute of Technology and Brown University. And again, it was not without Google’s development: with its first article about Spanner ( published in 2012 , among the authors are the creators of MapReduce), the company led the movement towards geo-replication databases with a SQL interface, and other pioneers followed it - for example, CockroachDB ( 2014 g. ).
At the same time, the PostgreSQL community began to revive: there were important improvements, such as the JSON data type (2012), and the new gadget from the new features in PostgreSQL version 10 : improved built-in support for partitioning and replication, full-text search support for JSON, and much another (came out in October of this year). Other developers, for example, CitusDB ( 2016 ) and the authors of these lines ( TimescaleDB , released this year ) have found new ways to scale PostgreSQL for specialized workloads.

The road that we took when developing TimescaleDB is very similar to the path of the industry as a whole. In the early internal versions of TimescaleDB, it had its own SQL-like query language “ioQL” - yes, the dark side seduced us too: it seemed that our own query language was a huge advantage. At first, this did not seem difficult, but we soon realized that the work actually had to be much more than we expected: for example, it was necessary to decide on the syntax, develop "connectors", teach users this language, etc. And it also turned out that we are in our own language! - We are constantly looking for the correct syntax for queries that can be easily expressed through SQL.
Thus, once we realized that it was pointless to develop our own query language. This led us to the transition to SQL and turned out to be one of the best technological solutions we have made: we opened a completely new world. Today, our database is not even 5 months old, and users can already use it in their work and immediately “out of the box” have many great features: visualization tools (Tableau), connectors for popular ORMs, many backup tools and options, guides and tips syntax, etc.
You don’t have to take our word for it - let's see what Google does.

For more than a decade, Google has, without a doubt, been at the forefront of developments in the field of database development and related infrastructure. Therefore, you should pay close attention to what they do.
Looking at Google’s second major publication on Spanner DB, which came out quite recently ( Spanner: Becoming a SQL System - “Spanner becomes a SQL system”, May 2017), you will find that it confirms the conclusions we arrived at on our own.
For example, Google’s engineers began to build their system over Bigtable, but found that the lack of SQL creates difficulties:
“These systems gave some advantage as a database, but they lacked many of the traditional database functions that application developers often rely on. A key example is the absence of a thoughtful query language, which is why developers of applications for processing and aggregating data had to write complex code. As a result, we decided to turn Spanner into a fully functional SQL system, in which query execution is closely related to other architectural features of the database (for example, strict consistency and global replication). ”
Further in the article, they explain in more detail the transition from NoSQL to SQL:
“The original API Spanner database interface had NoSQL methods for point searching and searching across ranges of separate and intermittent (eng.“ Interleaved ”) tables. NoSQL methods simplified system startup and are still convenient in simple search tasks, however SQL has significant advantages in writing more complex data access patterns and calculations on data. ”
The article also says that the transition to SQL did not stop at the Spanner project, but in fact spread to other technologies of the company, where today the common SQL dialect is used in several systems:
“The SQL Core DB Spanner shares“ standard SQL ”with several other Google systems, including internal (among them, F1 and Dremel), and external systems (for example, BigQuery) ...
For users within the company, this approach reduces the barrier when working with multiple systems. A developer or data analyst who writes SQL queries to Spanner can use his skills in the Dremel system without worrying about the intricacies of syntax, null processing, etc. ”
The success of this approach speaks for itself. Today, Spanner is a platform for major Google systems, including AdWords and Google Play, while “ potential cloud platform customers are overwhelmingly interested in using SQL”.
Most notably, Google, which helped bring the NoSQL movement into motion, is returning to SQL today. (So some people wondered: “ Did the Google developers get the “ big data ”industry off the true path for 10 years? ”)
Future data processing industry: SQL as a bottleneck
In computer networks there is such a thing as a “bottleneck”.
This idea arose to solve the main problem, which can be formulated as follows. Take a network device and imagine a kind of "pie" of the equipment layers below and the software layers above. Network devices can be very different; there are also many different applications and software. The task is to allow the software to connect to the network, whatever equipment is used; and network equipment must know how to handle network requests, regardless of software.
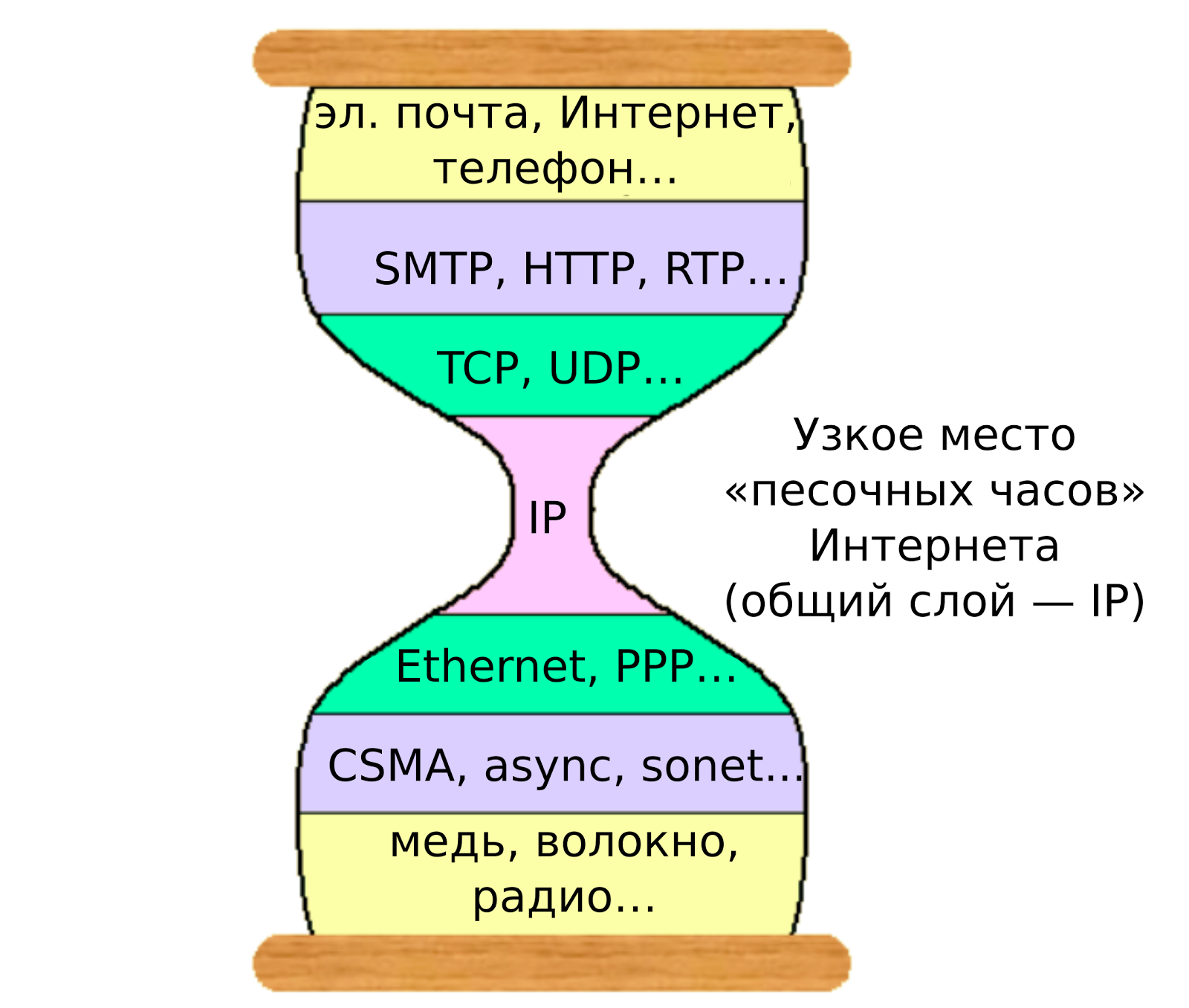
“Bottleneck” of network technologies ( source )
In networks, the bottleneck is IP : it acts as a common interface between low-level network protocols designed for the local network and high-level application and transport protocols. ( Here is one good explanation .) And, to simplify, this interface has become generally accepted for computer systems: it allows you to connect networks and exchange data between devices. And this “network of networks” has become a multi-faceted, full of various information Internet, as we know it today.
The authors of this article believe that SQL has become a bottleneck in data analysis.
We live in an era when data becomes “the most valuable resource in the world” ( The Economist, May 2017 ). As a result, we had the pleasure to observe the "Cambrian explosion" of specialized databases (OLAP, time series databases, databases for documents, graphs, etc.), data processing tools (Hadoop, Spark, Flink), data buses (Kafka, RabbitMQ ), etc. A large number of applications that run on such a data infrastructure, be it third-party visualization tools (Tableau, Grafana, PowerBI, Superset), web frameworks (Rails, Django) or specially developed applications using the database, have appeared.
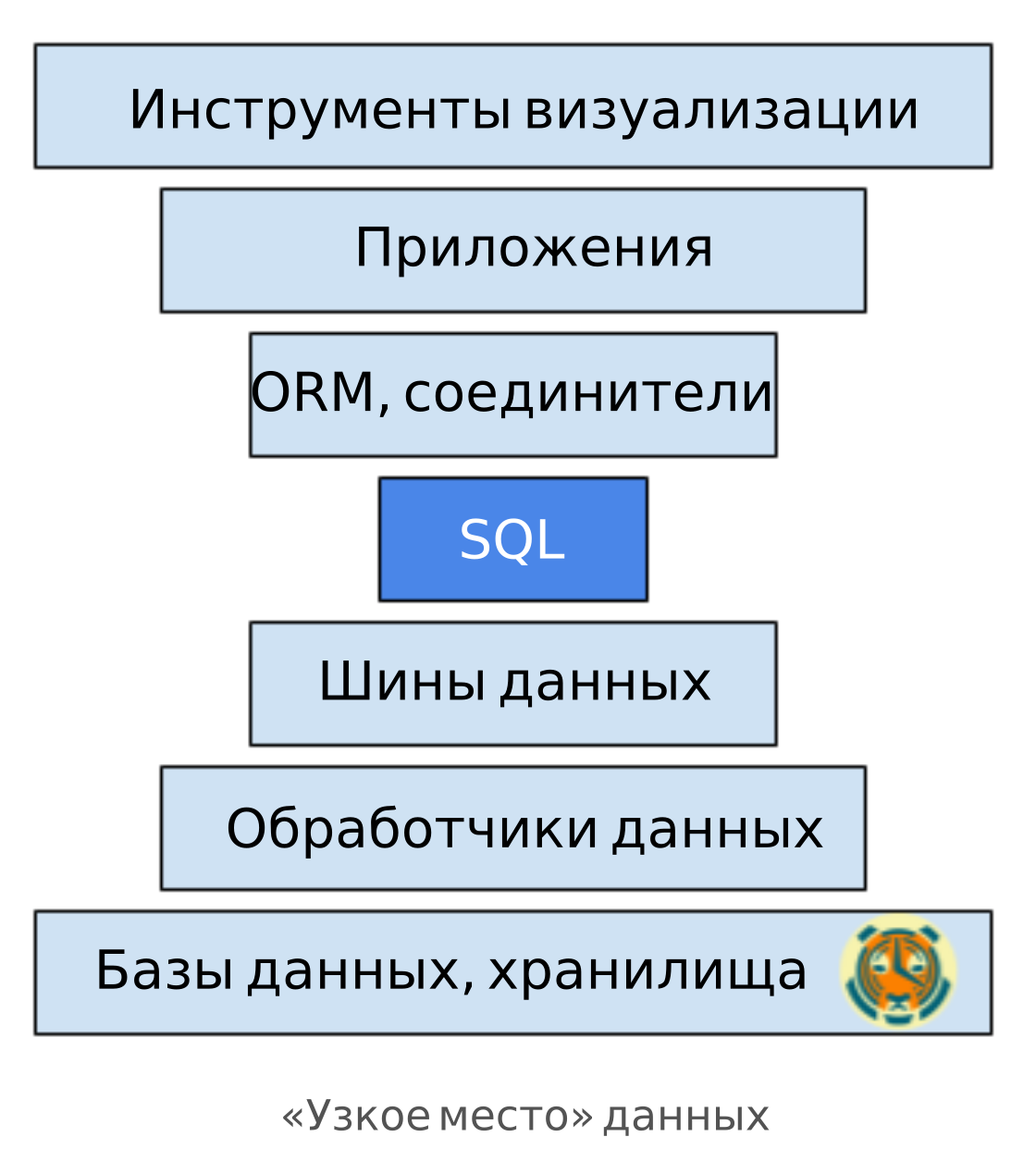
As in the case of computer networks, we have a complex “pie” with the infrastructure at the bottom and the applications at the top. As a rule, in order for this pie to work, we have to write a lot of glue code. But such code is unreliable: it must be diligently maintained.
A common interface is needed that will allow portions of this pie to interact with each other. Best of all - something that is already the standard in the industry. Something that allows you to swap different layers with minimal effort.
And here is the place for SQL: as with IP, SQL is a common interface.
But SQL is still more universal than IP: people have to analyze data, and queries in the SQL language, as was intended, can be read by humans.
Is SQL flawless? Not. But it is this language that is familiar to most database specialists. Of course, somewhere there is already work being done on an interface that is more oriented towards natural language, but what will such systems be connected to? To SQL.
Thus, at the very top of the pie there is another layer, and this layer is us.
SQL returns
SQL returns - and the main reason for this is not that it is annoying to write binding code to connect NoSQL-tools. And it is not that training specialists in a multitude of new languages is difficult. And not that standards should be thought out.
The main reason is that our world is full of data: they surround us, connect us. Once we relied on our own sense organs and nervous system to process them. Now our hardware systems and software are becoming smart enough to help us. We want to better understand the world around us, and for this we collect more and more data - therefore, the complexity of the data storage, processing, analysis and visualization systems will only grow.

Yoda Data Processing Wizard
We have a choice: to live in the world of fragile systems and millions of interfaces - or return to SQL and restore the imbalance of the Force.
About the translator
The article is translated in Alconost.
Alconost is engaged in the localization of games , applications and sites in 68 languages. Language translators, linguistic testing, cloud platform with API, continuous localization, 24/7 project managers, any formats of string resources.
We also make advertising and training videos - for websites selling, image, advertising, training, teasers, expliners, trailers for Google Play and the App Store.
Read more: https://alconost.com
Source: https://habr.com/ru/post/340372/
All Articles