Behind the scene of TOP-1 supercomputer
This is a story about how we c mildly_parallel slowed down accelerated calculations on the most powerful supercomputer in the world .

In April of this year, our team took part in the final of the Asia supercomputer challenge 2017 , one of the tasks of which was to accelerate the Masnum-Wave ocean wave simulation program on the Chinese supercomputer Sunway TaihuLight.
It all started with a qualifying round in February: we got access to a supercomputer and met our new friend for the next couple of months.
Computing nodes are exposed in the form of two ovals, between which there is a network iron. The nodes use Shenwei 26010 processors. Each of them consists of 4 heterogeneous processor groups, which include one control and 64 cores with a clock frequency of 1.45 GHz and a local cache size of 64 KB.

All this is cooled by a water system located in a separate building.
From the software at our disposal, the FORTRAN and C compilers with the “support” of OpenACC 2 and athreads (analogous to POSIX Threads) and the task scheduler, combining the capabilities of a regular scheduler and mpirun.
The cluster was accessed through a special VPN, plug-ins for work with which were available only for Windows and Mac OS. All this added a special charm at work.
The task was to accelerate Masnum-Wave on this supercomputer. We were provided with Masnum-Wave source code, several tiny readme files describing the basics of working on a cluster and data for measuring acceleration.
Masnum-Wave is a program to simulate the movement of waves around the globe. It is written in FORTRAN using MPI. In a nutshell, it iteratively performs the following: it reads the data of the functions of external action, synchronizes the boundary regions between the MPI processes, calculates the wave propagation and stores the results. We were given a workload for 8 model months in increments of 7.5 minutes.
On the very first day we found an article on the Internet: “The Sunway TaihuLight supercomputer:
system and applications, Haohuan Fu ”with a description of Masnum-Wave acceleration on the Sunway TaihuLight architecture using pipelining. The authors of the article used the full power of the cluster (10649600 cores), we also had 64 computing groups (4160 cores).
Masnum-Wave consists of several modules:
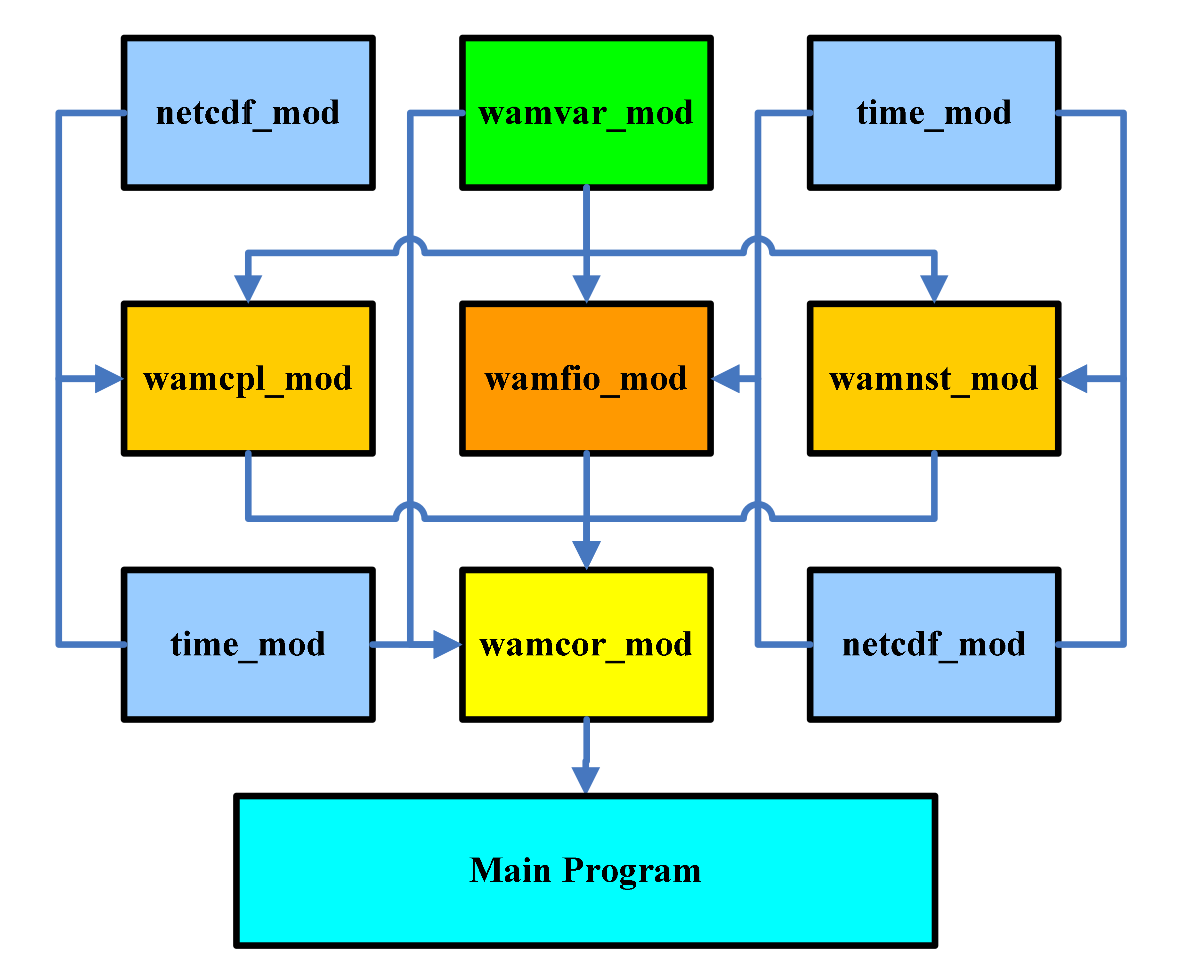
We first encountered such a large amount of code generated by science. Since the code is a mixture of two versions of FORTRAN 90 and 77, it sometimes broke the work of their own compiler. In a large number there are wonderful goto constructions, pieces of commented code and, of course, comments in Chinese.
Abbreviated sample code for clarity:
do 1201 j=1,jl js=j j11=jp1(mr,j) j12=jp2(mr,j) j21=jm1(mr,j) j22=jm2(mr,j) !**************************************************************** ! do 1202 ia=ix1,ix2 ! do 1202 ic=iy1,iy2 eij=e(ks,js,ia,ic) !if (eij.lt.1.e-20) goto 1201 if (eij.lt.1.e-20) cycle ea1=e(kp ,j11,ia,ic) ea2=e(kp ,j12,ia,ic) ! ... eij2=eij**2 zua=2.*eij/al31 ead1=sap/al11+sam/al21 ead2=-2.*sap*sam/al31 ! fcen=fcnss(k,ia,ic)*enh(ia,ic) fcen=fconst0(k,ia,ic)*enh(ia,ic) ad=cwks17*(eij2*ead1+ead2*eij)*fcen adp=ad/al13 adm=ad/al23 delad =cwks17*(eij*2.*ead1+ead2) *fcen deladp=cwks17*(eij2/al11-zua*sam)*fcen/al13 deladm=cwks17*(eij2/al21-zua*sap)*fcen/al23 !* nonlinear transfer se(ks ,js )= se(ks ,js )-2.0*ad se(kp2,j11)= se(kp2,j11)+adp*wp11 se(kp2,j12)= se(kp2,j12)+adp*wp12 se(kp3,j11)= se(kp3,j11)+adp*wp21 se(kp3,j12)= se(kp3,j12)+adp*wp22 se(im ,j21)= se(im ,j21)+adm*wm11 se(im ,j22)= se(im ,j22)+adm*wm12 se(im1,j21)= se(im1,j21)+adm*wm21 se(im1,j22)= se(im1,j22)+adm*wm22 !... ! 1202 continue ! 1212 continue 1201 continue First of all, we determined the bottlenecks in the code and the candidates for optimization by displaying the execution time of each function. We were most interested in the warcor module, which is responsible for the numerical solution of the model equation and the function for recording control points.
After reviewing the meager documentation for Chinese compilers, we decided to use OpenACC, since this is a standard from Nvidia with examples and specifications. In addition, the code from the readme to athreads seemed to us unnecessarily complicated and simply did not compile. How wrong we were.
One of the first ideas that comes to mind when optimizing code on accelerators is the use of local memory. In OpenACC, this can be done with several directives, but the result must always be the same: the data must be copied to local memory before starting the calculations.
To test and select the right directive, we wrote several test programs on Fortran, which made sure that they work and that you can get acceleration in this way. Next, we set up these directives in Masnum-Wave, indicating the names of the most used variables. After compilation, they began to appear in the logs, the accompanying inscriptions in Chinese were not highlighted in red, and we thought that everything was copied and working.
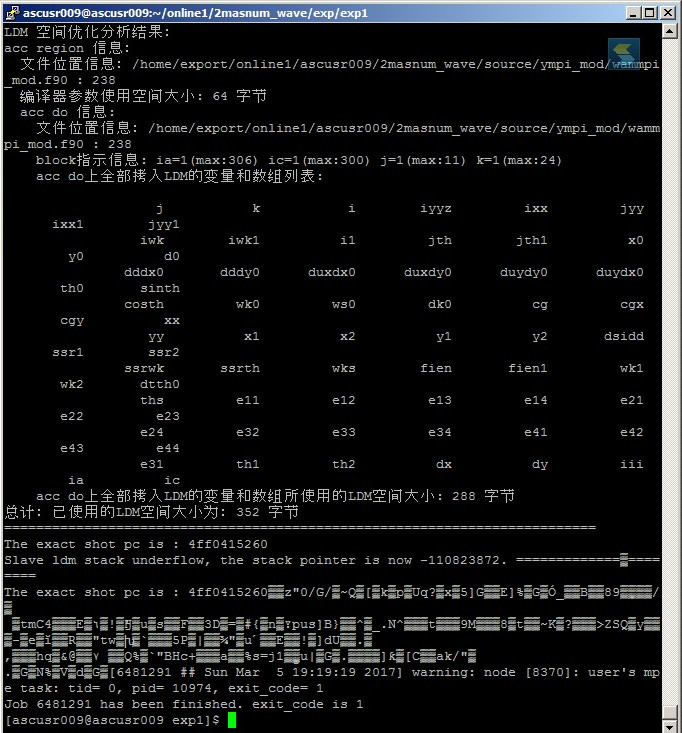
But it turned out that not everything is so simple. The OpenACC compiler did not copy the arrays in Masnum-Wave, but it worked properly with test programs. After spending a couple of days with Google Translate, we realized that it does not copy objects that are defined in files that are connected via preprocessor directives (include)!
For the next week we transferred the Masnum-Wave code from the included files (and there are more than 30 of them) to the files with the source code, and it was necessary to make sure that everything is defined and linked in the correct order. But, since none of us had any experience with FORTRAN, and it all came down to “let's roam and see what happens”, then without replacing some of the basic functions with the crutch versions, it also wasn't done.
And now, when all the modules were cracked, and we, in the hope of getting our scanty acceleration, launched the freshly styled code, we received another portion of frustration! Directives written in accordance with all canons of the OpenACC 2.0 standard give errors in runtime. At that moment, the idea began to creep into our heads that this wonderful supercomputer maintains its own particular standard.
Then we asked the organizers of the documentation, and on the third attempt they gave it to us.

A couple of hours with Google Translate confirmed our concerns: the standard they support is called OpenACC 0.5, and it is completely different from the OpenACC 2.0 that comes with the pgi compiler.
For example, our main idea was to reuse data on the accelerator. To do this in standard 2.0, you need to wrap parallel code in a data block. Here’s how this is done in Nvidia’s examples:
!$acc data copy(A, Anew) do while ( error .gt. tol .and. iter .lt. iter_max ) error=0.0_fp_kind !$omp parallel do shared(m, n, Anew, A) reduction( max:error ) !$acc kernels do j=1,m-2 do i=1,n-2 Anew(i,j) = 0.25_fp_kind * ( A(i+1,j ) + A(i-1,j ) + & A(i ,j-1) + A(i ,j+1) ) error = max( error, abs(Anew(i,j)-A(i,j)) ) end do end do !$acc end kernels !$omp end parallel do if(mod(iter,100).eq.0 ) write(*,'(i5,f10.6)'), iter, error iter = iter +1 !$omp parallel do shared(m, n, Anew, A) !$acc kernels do j=1,m-2 do i=1,n-2 A(i,j) = Anew(i,j) end do end do !$acc end kernels !$omp end parallel do end do !$acc end data But on a cluster, this code will not compile, because in their standard, this operation is done by specifying an index for each data block:
#include <stdio.h> #include <stdlib.h> #define NN 128 int A[NN],B[NN],C[NN]; int main() { int i; for (i=0;i<NN;i++) { A[i]=1; B[i]=2; } #pragma acc data index(1) { #pragma acc parallel loop packin(A,B, at data 1) copyout(C) for (i=0;i<NN;i++) { C[i]=A[i]+B[i]; } } for(i=0;i<NN;i++) { if(C[i]!=3) { printf("Test Error! C[%d] = %d\n", i, C[i]); exit(-1); } } printf("Test OL!\n"); return 0; } Measuring ourselves for choosing OpenACC, we still continued to work, as there was only a couple of days left. On the last day of the qualifying round, we finally managed to launch our “accelerated” code. We got a slowdown 3.5 times. We had no choice but to write in the task report everything we think about their implementation of OpenACC in censorship form. Despite this, we received a lot of positive emotions. When else do you have to remotely debug code on the most powerful computer in the world?
PS: As a result, we still went to the final part of the competition and went to China.
The final task of the final was a presentation with a description of solutions. The best result was achieved by the local team, which wrote its C library using athread. OpenACC, they say, does not work.
')
Source: https://habr.com/ru/post/340318/
All Articles