Recommender system on the knee as a means against existential crisis
Maybe the reference to an existential crisis sounds too loud, but for me personally the problem of searching and choosing (or choosing and searching, it matters) in the Internet world as well as in the world of simple things sometimes comes near torture. The choice of the film for the evening, books by an unknown author, sausages in the store, a new iron - a wild number of options. Especially when you don’t really know what you want. And when you know, but you can’t try it - it’s not a holiday either - the world is diverse and you don’t try everything at once.

Recommender systems help a lot in choosing, but not everywhere and not always as we would like. Often, the semantics of the content is not taken into account. In addition, the full length of the problem is " long tail " , when the recommendations focus only on the most popular positions, and interesting, but not very popular in the mass of things they are not covered.
I decided to start my experiment in this direction by searching for interesting texts by taking a rather small but writing community of authors who still remained on the LiveJournal blogging platform. About how to make your own recommender system and as a result get another helper in choosing wine for the evening - under the cut.
Well, first of all, this is a blog platform and often interesting things are written there. Even despite the migration of users to Facebook in LJ, there are still, according to my estimates, about 35-40 thousand active blogs. It is quite a reasonable volume for experiments without the use of big data tools. Well, the cracking process itself is quite simple, unlike working with the same facebook.
')
In the end, I wanted to get a tool to recommend interesting authors. In the process of working on the project, the hotelies expanded and multiplied, and not everything turned out right away. About what was possible and what are the future plans, and I will tell in this article.
As already mentioned, crawling blogs on the LJ platform is quite simple - you can easily get the texts of posts, pictures (if they are needed) and even comments on posts with their structure. I must say that it is the system of hierarchical commenting like on Habré that keeps some authors on this platform.
So, a simple crawler on Perl, the code of which can be taken from me on github 'for a couple of weeks of unhurried work, I downloaded texts and comments from about 40 thousand blogs for the period summer 2017 and summer 2016. These two periods were chosen for parallel comparison of activity in LiveJournal from year to year.
So, the initial data for the study turned out like this:
- Analysis period: 6 months
- Authors: approximately 45 thousand
- Publications: approximately 2.5 million
- Words: approximately 740 million

Since I am not a data scientist (although I watch contests on kaggle from time to time), the algorithms were chosen very simple - consider the proximity of the authors as the cosine distance between the vectors characterizing their texts.
There were several approaches to the construction of vectors with the characteristics of the authors' texts :
1. Obvious - we build vectors with the TF-IDF metric according to the assembled text corpus. The disadvantage is that the vector space turns out to be very much multidimensional (~ 60 thousand) and very sparse.
2. Dodgy - clustering a text corpus using word2vec and taking vectors as a projection of texts on the resulting clusters. The advantage is relatively short vectors in the number of clusters (usually ~ 1000). The disadvantage is that you need to train word2vec, select the number of clusters for clustering, think about how to project text on clusters, it is confused.
3. And also not bad - to build vectors with gensim doc2vec . Almost the same as the second option, but the side view and all the problems except training have already been solved. But in python. And I did not want this.
As a result, the first model was chosen, supplemented by LSA methods (Latent-semantic analysis) in the form of SVD decomposition of the resulting matrix “documents” - “terms”. The method has been described many times on Habré, I will not dwell.
For the lemmatization of terms , or rather the reduction of Russian words to the basic form, the mystem utility from Yandex and a wrapper around it were used, which allows you to combine several documents into a single file to feed it to the utility input. It was possible to call it on every document, which I did before, but this is not very effective. Nouns, adjectives, verbs and adverbs with a length of more than 3 characters and with a frequency of use of more than 100 throughout the body were selected into the corpus.
Here, for example, the top nouns, reduced to the basic form:
1 person
2. Time
3. Russia
4. Day
5. Country
SVD decomposition was done using the external utility SVDLIBC , which had to be patched to use very large matrices, as it fell when trying to create a “dense matrix” with the number of elements greater than the maximum value of the int type. But the utility is good because it can work in sparse matrices and calculate only the required number of singular vectors, which significantly saves time. By the way, for Perl there is a module PDL :: SVDLIBC based on the code of this utility.
The choice of the length of the vector (the number of singular vectors in the decomposition) was made by “expert analysis” (read by eye) on the test set of journals. As a result, I stopped at n = 500.
The result of the analysis is a matrix of coefficients of similarity of the authors.
At the initial stage, I wanted to evaluate the structure of the thematic communities with my eyes in order to understand what to do with it further.
I tried to use clustering and visualization in the form of self-organizing maps (SOM) from the analysis package Deductor by applying to the input a vector of 500 values after SVD. The result made me wait (multithreading? No, did not hear) and did not please - three large clusters were traced and the authors were fairly densely located across the entire map field.
It was obvious that the distance matrix could be transformed into a graph by keeping the edges with the value of the proximity factor greater than a certain threshold. Having written the matrix converter to the GDF format graph (it seemed to me the most suitable for visualizing various parameters), after feeding this graph to the Gephi graph visualization package and experimenting with different layouts and display parameters I got this picture:

When you click on the picture and here you can meditate on it in a resolution of 3000x3000. And if you sometimes go to LJ blogs, you may find familiar names there.
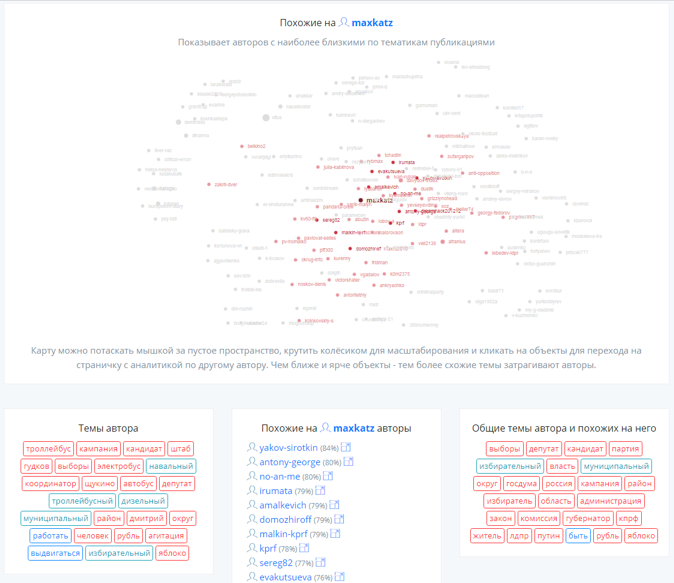
This picture is fully consistent with my ideas about the thematic structure of the authors, although not perfect (too dense). It remains a little - to give yourself and others the opportunity to receive recommendations based on personal authoring preferences : I asked the author’s name and received recommendations similar to him.
For this purpose, a small visualization of the graph areas adjacent to the author of interest on d3js was written using the force layout . For each author (and there are a little more than 40 thousand of them, as I have already said) a json file was generated with a description of the nearby nodes of the graph, a “tag annotation” based on a sorted list of popular words for this author and a similar annotation of his group that includes nearby knots. Annotations should give some insight about what the author writes and what topics are relevant to similar bloggers.
It turned out this mini-search engine similarity.me with recommendations and a graphics card:
The title picture is just a wine list for taste characteristics ))
A side effect of the research was the thought “rather than use this approach to recommend any products according to their descriptions.” And for this purpose, the wine critic Denis Rudenko’s tasting notes in his blog at the Daily Wine Telegraph Daily Journal were perfect. Unfortunately, he abandoned their publication long ago, but more than 2000 descriptions of wines accumulated there are excellent material for such an experiment.
Special preprocessing of texts was not done. Having fed them to the system, I received a taste card of 700 best wines with a recommendation of similar ones:

It can highlight the wines of the most popular grape varieties and their subjective (from the point of view of the taster) tastes.
Plans to slightly optimize the recommendations by converting some adjectives into nouns, for example, “blueberry” - “blueberry”. And place on the map all over 2000 tasted wines.
This is how you can deal with the problem of choice (if all of a sudden it is relevant for you) by expanding these approaches to other areas.
Recommender systems help a lot in choosing, but not everywhere and not always as we would like. Often, the semantics of the content is not taken into account. In addition, the full length of the problem is " long tail " , when the recommendations focus only on the most popular positions, and interesting, but not very popular in the mass of things they are not covered.
I decided to start my experiment in this direction by searching for interesting texts by taking a rather small but writing community of authors who still remained on the LiveJournal blogging platform. About how to make your own recommender system and as a result get another helper in choosing wine for the evening - under the cut.
Why LiveJournal?
Well, first of all, this is a blog platform and often interesting things are written there. Even despite the migration of users to Facebook in LJ, there are still, according to my estimates, about 35-40 thousand active blogs. It is quite a reasonable volume for experiments without the use of big data tools. Well, the cracking process itself is quite simple, unlike working with the same facebook.
')
In the end, I wanted to get a tool to recommend interesting authors. In the process of working on the project, the hotelies expanded and multiplied, and not everything turned out right away. About what was possible and what are the future plans, and I will tell in this article.
Crawling
As already mentioned, crawling blogs on the LJ platform is quite simple - you can easily get the texts of posts, pictures (if they are needed) and even comments on posts with their structure. I must say that it is the system of hierarchical commenting like on Habré that keeps some authors on this platform.
So, a simple crawler on Perl, the code of which can be taken from me on github 'for a couple of weeks of unhurried work, I downloaded texts and comments from about 40 thousand blogs for the period summer 2017 and summer 2016. These two periods were chosen for parallel comparison of activity in LiveJournal from year to year.
Why perl
Because I like this language, I work on it and I consider it very suitable for tasks with unpredictable flow and result - just what is needed in experimental information retrieval and data mining when maximum performance is not needed, but maximum flexibility is needed. For data processing it is better, of course, to use python with a bunch of libraries under it.
So, the initial data for the study turned out like this:
- Analysis period: 6 months
- Authors: approximately 45 thousand
- Publications: approximately 2.5 million
- Words: approximately 740 million
Analytical model and processing
Since I am not a data scientist (although I watch contests on kaggle from time to time), the algorithms were chosen very simple - consider the proximity of the authors as the cosine distance between the vectors characterizing their texts.
There were several approaches to the construction of vectors with the characteristics of the authors' texts :
1. Obvious - we build vectors with the TF-IDF metric according to the assembled text corpus. The disadvantage is that the vector space turns out to be very much multidimensional (~ 60 thousand) and very sparse.
2. Dodgy - clustering a text corpus using word2vec and taking vectors as a projection of texts on the resulting clusters. The advantage is relatively short vectors in the number of clusters (usually ~ 1000). The disadvantage is that you need to train word2vec, select the number of clusters for clustering, think about how to project text on clusters, it is confused.
3. And also not bad - to build vectors with gensim doc2vec . Almost the same as the second option, but the side view and all the problems except training have already been solved. But in python. And I did not want this.
As a result, the first model was chosen, supplemented by LSA methods (Latent-semantic analysis) in the form of SVD decomposition of the resulting matrix “documents” - “terms”. The method has been described many times on Habré, I will not dwell.
For the lemmatization of terms , or rather the reduction of Russian words to the basic form, the mystem utility from Yandex and a wrapper around it were used, which allows you to combine several documents into a single file to feed it to the utility input. It was possible to call it on every document, which I did before, but this is not very effective. Nouns, adjectives, verbs and adverbs with a length of more than 3 characters and with a frequency of use of more than 100 throughout the body were selected into the corpus.
Here, for example, the top nouns, reduced to the basic form:
1 person
2. Time
3. Russia
4. Day
5. Country
SVD decomposition was done using the external utility SVDLIBC , which had to be patched to use very large matrices, as it fell when trying to create a “dense matrix” with the number of elements greater than the maximum value of the int type. But the utility is good because it can work in sparse matrices and calculate only the required number of singular vectors, which significantly saves time. By the way, for Perl there is a module PDL :: SVDLIBC based on the code of this utility.
The choice of the length of the vector (the number of singular vectors in the decomposition) was made by “expert analysis” (read by eye) on the test set of journals. As a result, I stopped at n = 500.
The result of the analysis is a matrix of coefficients of similarity of the authors.
Result visualization
At the initial stage, I wanted to evaluate the structure of the thematic communities with my eyes in order to understand what to do with it further.
I tried to use clustering and visualization in the form of self-organizing maps (SOM) from the analysis package Deductor by applying to the input a vector of 500 values after SVD. The result made me wait (multithreading? No, did not hear) and did not please - three large clusters were traced and the authors were fairly densely located across the entire map field.
It was obvious that the distance matrix could be transformed into a graph by keeping the edges with the value of the proximity factor greater than a certain threshold. Having written the matrix converter to the GDF format graph (it seemed to me the most suitable for visualizing various parameters), after feeding this graph to the Gephi graph visualization package and experimenting with different layouts and display parameters I got this picture:
When you click on the picture and here you can meditate on it in a resolution of 3000x3000. And if you sometimes go to LJ blogs, you may find familiar names there.
This picture is fully consistent with my ideas about the thematic structure of the authors, although not perfect (too dense). It remains a little - to give yourself and others the opportunity to receive recommendations based on personal authoring preferences : I asked the author’s name and received recommendations similar to him.
For this purpose, a small visualization of the graph areas adjacent to the author of interest on d3js was written using the force layout . For each author (and there are a little more than 40 thousand of them, as I have already said) a json file was generated with a description of the nearby nodes of the graph, a “tag annotation” based on a sorted list of popular words for this author and a similar annotation of his group that includes nearby knots. Annotations should give some insight about what the author writes and what topics are relevant to similar bloggers.
It turned out this mini-search engine similarity.me with recommendations and a graphics card:
What can be improved?
- Adequacy - now the process of data collection is underway, so the coverage of posts will be greater and the semantic proximity of the authors on the map should become more adequate. In addition, I plan to conduct an additional pre-selection of authors - to exclude "half-dead", fans of reposts, automatic publishers - this will allow a little to clear the graph from garbage.
- Accuracy - there is a thought to use neural networks to form vectors of documents and experiment with different distances except cosine.
- Visualization - try to impose a thematic structure on the structure of relations between the authors using hexagonal projections and all the same self-organizing maps. Well, to achieve a clearer clustering of the overall map.
- Annotation - try annotation algorithms with the creation of phrases.
What about vinishka?
The title picture is just a wine list for taste characteristics ))
A side effect of the research was the thought “rather than use this approach to recommend any products according to their descriptions.” And for this purpose, the wine critic Denis Rudenko’s tasting notes in his blog at the Daily Wine Telegraph Daily Journal were perfect. Unfortunately, he abandoned their publication long ago, but more than 2000 descriptions of wines accumulated there are excellent material for such an experiment.
Special preprocessing of texts was not done. Having fed them to the system, I received a taste card of 700 best wines with a recommendation of similar ones:
It can highlight the wines of the most popular grape varieties and their subjective (from the point of view of the taster) tastes.
Plans to slightly optimize the recommendations by converting some adjectives into nouns, for example, “blueberry” - “blueberry”. And place on the map all over 2000 tasted wines.
This is how you can deal with the problem of choice (if all of a sudden it is relevant for you) by expanding these approaches to other areas.
Source: https://habr.com/ru/post/340262/
All Articles