Due to which Tarantool is so optimal

Anikin Denis ( danikin , Mail.Ru )
The report will be devoted to Tarantool. I always talked about use case, about something that the user sees. Today I will talk more about the insides.
When I first saw Tarantool, when I recognized his benchmarks, what his performance was, it wasn’t that suspicious, because I had already programmed for more than 10 years and understood about what could be squeezed out of iron with optimal programming, with optimal code. But still it seemed to me suspicious - how is it that he is so fast? That is, conditionally, if all databases can operate at a speed of tens of thousands of queries per second, at best, and Tarantool - up to hundreds of thousands and even a million .
')
Therefore, before you start using it in production, in mail.ru Mail and in the Cloud, I carefully studied everything and found out how Tarantool works inside and what makes it so optimal. And I suspect that, probably, other users of Tarantool also have the same suspicion - something is somehow too fast, and somehow it is suspicious ...
By the way, raise your hands to those who have never heard of Tarantool. Almost everyone heard. Which of you applies it on production? Not much. In fact, you do not apply, including because you do not understand how he is so fast, and all others are slow, and that's due to what. If this is really the reason why you are still afraid to use it, then you have come to the right place, and I hope that today I will tell you and explain. Of course, not everything, because the database is a huge product, it has a lot of features, a lot of functions and it’s almost impossible to tell everything in 40 minutes. Therefore, I will tell you about the main thing. Go.

I also wanted to briefly tell you what to expect and what not to expect from the report. Expect - specifics, i.e. why Tarantool is so fast, why it reads quickly, writes fast, starts quickly, etc., and what were the reasons for us in Mail.ru to make it so fast.

What not to expect is holy wars, i.e. all databases are good, each database is for its case, and we do not claim to be a universal database for everything. Also, do not expect any new structures or new algorithms, because the main strength of Tarantool is not that the guys invented some new algorithms that nobody knew before, but that they correctly apply and compose existing ones algorithms. And they write the code very optimally. You all know O (N). When you say O (N) or O (logN), it means that if O (N) is 2 times the data set, the algorithm works 2 times longer, but how much it works specifically is unknown, i.e. You can write it optimally, but you can make a bunch of copies and other things that will not affect its asymptotic complexity, but will also affect the speed of work. So, in Tarantool a lot of attention is paid to this coefficient, which is facing O, i.e. on which everything is multiplied. This is a theory, and now we are moving to practice.

Let's start with the most important thing that Tarantool stores the entire copy of the data completely in memory. This does not mean that when the machine restarts, everything is lost, but the fact that a copy of the data is in memory. The data is also on the disk, of course, but at the same time all the data is in memory and is never unloaded from there. It is worth making a reservation here that it is about the original Tarantool engine, which is called Memtx, which, in fact, stores everything in memory and which is in-memory. Tarantool has recently appeared a disk engine, which allows not a complete copy of the data to be stored in memory, but only a part of it. Here I will touch only the original Tarantool engine, i.e. only in-memory engine. Obviously, memory is faster than disk, i.e. if everything is in memory, then everything happens quickly.
Such a picture symbolizing this:

Tarantool reads everything from memory, and the disk database — MySQL, Postgres, Oracle, SQL server — they all read from disk, so Tarantool is faster. This seems to be obvious, but there is a nuance.

You, probably, are looking at me now with this squint: “But what about the cache, because disk databases have a cache, and why, nevertheless, Tarantool is faster, because disk databases cache the most popular queries, which means they should also be are they fast? How do you think, what is the difference when you have a cache, from when you have data just in memory? Is there any difference with tz performance? Can get old Now about it and tell.
Let's see how Tarantool interacts with memory.

It simply reads data from memory, which there are always already prepared, in an ideal format that allows them to quickly read, quickly search, quickly make queries on the index.
Now let's see how the disk database works:

Very primitive scheme, of course. All bases are different, all have a different cache, but in general, the logic is as follows. At first, let's say, comes from the user reading, some SELECT * FROM blah blah blah. First we look to see if the data is in the cache. If there is, then we climb into the cache and return, if not, then we read from the disk, write what we read into the cache. If the cache is already clogged (and the cache is always clogged by definition, because it is always full, that is its meaning), then we force out the old data and then read from the cache. Those. if you are lucky, then one more action, if not lucky, then this whole long chain happens, and it should be noted that this is not all for free. They counted it from a disk to some buffer, took it from this buffer, copied it to the cache, supplanted the old one, freed up the memory, wrote down the new one, allocated the memory. Freeing / allocating memory is expensive. This is all copying, this is all searching, and this is all not for free. This is all the very coefficient that is before O, i.e. many, many actions to do. Appealing to a hash table, to some hash index in complexity is possible and constant ±, or if the tree is logarithmic, but this is all that is multiplied by Oh, this is a huge amount of work. Plus, the data - they are on the disk in one form, in the cache are in a different form, then they are often cached through pages, so we load a little more, it means we allocate a little more memory, we also release a little more. All this precious processor cycles, which are all spent on this business. It should be understood that even if you hit the cache, i.e. read happened, and the data is already in the cache, then your processor in the background still does all this, this whole chain, it is always done in the background, without stopping. Those. if the data is even already in the cache, then the processor or its other cores are busy with something. And once the other kernels are busy with something, then blocking occurs, then mutexes occur. A lot of work compared to just counting from memory and everything.

Such a thing about the cache. Feel the difference - always in memory and the cache is not the same thing, it is a little different things.

And now let's about the record.

From reading everything is more or less clear - ok, Tarantool in-memory, it reads quickly from memory, but what about the record? Tarantool works on writing in almost the same way as reading, while it persists all the data to the disk anyway. Why do you think it is so fast, although the data is still saved to disk when recording? The keyword is consistent. Now I will show it.

What does Tarantool do when it performs a transaction? It executes it in memory and writes it to the transaction log. In the transaction log, he writes it only for the purpose of recovery, i.e. if everything falls in order to rise, roll everything out of the log and bring the database into the same state it was in before it started.

Writing to disk takes place as shown here. Just write to the file, sequentially. You all know that sequentially is written to the file very quickly.

Is the question here not slow? It is fast enough. On magnetic disks, this is somewhere around 100 MB per second, and on an SSD it is 250 MB per second. Check it out right now. On SSD macbooks usually stand, it will be hellish hundreds of MBs per second. This is on SSD. On a magnetic disk a little slower, but still, it is 100 MB per second. What is 100 MB per second? This is actually a fig, because if, for example, the transaction size is 100 bytes, which is basically a lot, i.e. any transaction on updating there is just update something set key = value. You just need to write key and value. If it's numbers, then it is literally a few bytes. But even if the transaction is 100 bytes, it is 1 million transactions per second. Those. peak performance is 1 million transactions per second. This is such a performance that is usually never needed, it is very big. And usually the bottleneck is not even a disk, but a processor or, for example, memory. Those. there is not enough memory to store so much data to do so many transactions on one machine.

But what about disk databases write to disk? Why can't they just write optimally? They do the same thing as Tarantool, i.e. they update in memory, in cache, they also write log transactions, because how can it be without this? Because transaction logs are the only way to restore the database after crash.
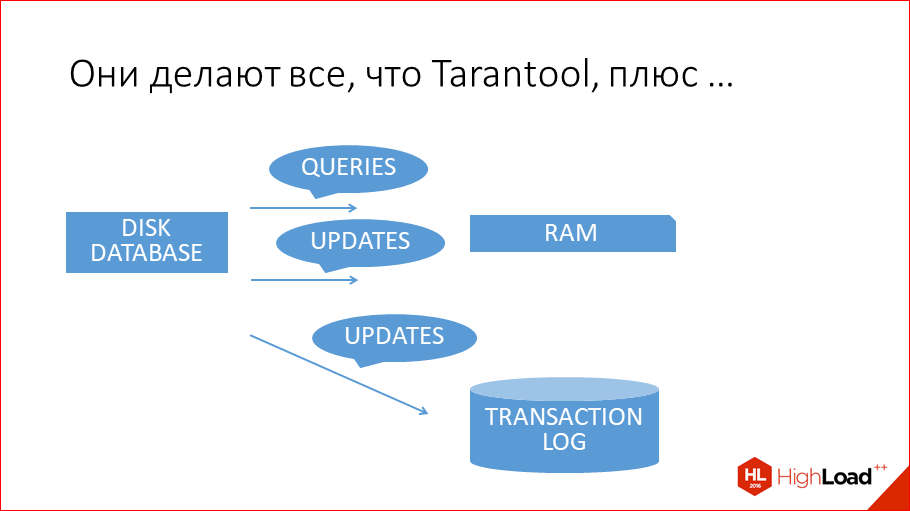
And besides that, they also update the data on the disk. How do they do it?

They usually use the good old B-trees.
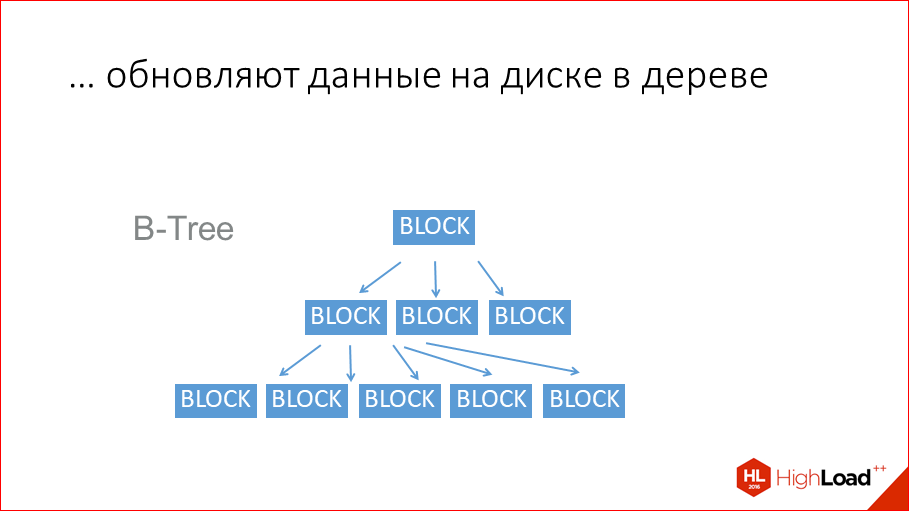
This is by far the most popular data structure for storage on disk. Although, I must say that new data structures of the LSM-tree type have already appeared. They are used in the Tarantool disk engine, they are used in RocksDB from Facebook, they are used by Google in LevelDB. In principle, all traditional run-in databases use B-trees or B + trees. MySQL or Postgres, Oracle - all built on B-trees. A B-tree is like a tree, only n-nar is it, it has a data block in each node, and further there are many references to subsequent blocks. And due to the n-narrative, it is very short. But still, in order to read the data stored here, you need to do 3 readings from the disk. And these disk readings are slow. Here the most important question ... It was correctly said that B-trees for disk databases are needed only to read the data later. If disk databases would store, as Tarantool, the entire copy of the data in memory, i.e. if they were Tarantool, they would not need to read. And when it is not necessary to read, it is not necessary to write. They write to this structure, only to be counted, only for the sake of it. This is not for recovery. For recovery, they use the same way as Tarantool, the log transaction. And it makes them slower to write simply because they are disk-based, not because there are bad programmers there, they are very good there. And simply because they are disk.

At the same time, such a data structure is good - it does not lead to linear searches, but, on the other hand, it leads to random access to the disk. On a magnetic disk, this is only 100 hits per second maximum. Why do you think the magnetic disk allows you to read / write data in series of 100 MB / s and accidentally access only 100 times / s? Because it causes physical movement of the disk head, and the disk head cannot move very quickly. 100 times a second - this is so very much, just imagine. But if you read the banal 100 bytes, which are scattered throughout the disk, you will write or read them at a speed of 100 bytes per second. Also, do a simple test - you can write a simple C program, take some file in several gigs so that it does not fit in the page cache, and accidentally read or write some bytes from it. You will have at best 100 times per second. If you fragment, it will be even worse, because then with each call there will be a few more sik, it will be several dozen times per second. This is a separate problem that these files are also fragmented. But, like, the databases are able to deal with this, they, in fact, create some kind of big file right away in advance and rule its pieces, but they squeeze it once in a while so that there is no fragmentation. On SSD it is a little faster, but the same thing, well, 1000 times per second. Again, feel the difference - in the transaction log we write 1 million transactions per second, in the table space, in the B-tree we write on the HDD several dozen, 100 times, on the SSD - 1000 times, just a difference of 3-4 orders of magnitude.
Now let's go further. About the start.
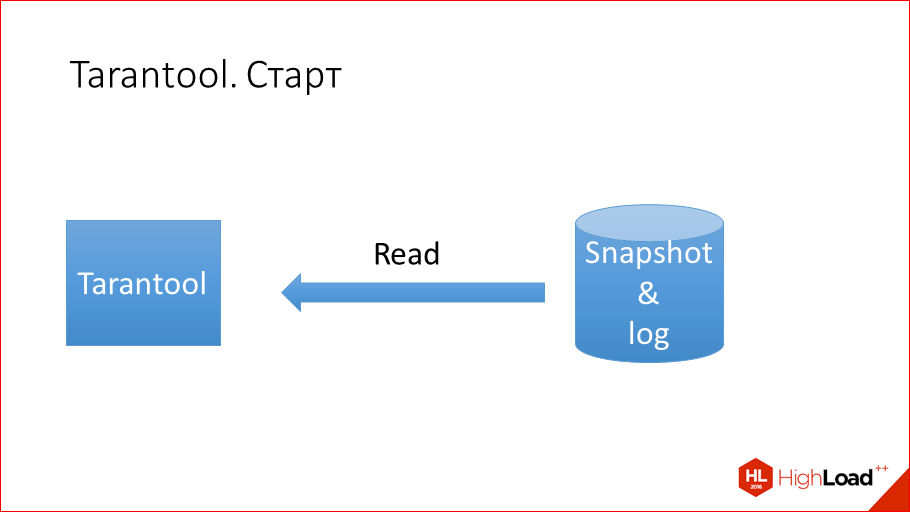
I told about reading and writing. Tarantool reads faster, because everything in-memory and in-memory is not a cache, because it does a lot less work than cache, cache, allocate, free, change data structure, copy, etc. And Tarantool writes faster, because it does not need to update the table space, because it has a disk only for recovery, and not for the execution of transactions.
Now let's start about the start. How does the start of Tarantool? Tarantool has a log of transactions, there is a Snapshot, I haven’t spoken about it yet, but I’ll tell you later. Snapshot is the state of the database at some point in time. Tarantool periodically resets all of its state to disk so that the log transactions do not grow much, so that you can easily recover later. Accordingly, the launch of Tarantool is simply reading 2 files, and the files are not fragmented and linear, i.e. reading from them is linear. Just read Snapshot from the beginning to the end, read the log from the beginning to the end and in the process of this reading apply everything to the memory. This is what start Tarantool is.
How fast?

This, again, on a magnetic disk - 100 MB / s, on SSD - 200-250 MB / s.

And how does this happen with disk databases? The question is very interesting, because disk databases, we must give them their due, they start almost instantly, because they do not need to read the Snapshot into memory.

But what happens next? Suppose you have Postgres or MySQL. They started, what next? Do they work quickly right there? The cache warms up - this is tin. We are now at HighLoad - this is a conference dedicated to high loads. If you have high loads, then you use the cache with might and main, and this means that without a cache, the database normally, in principle, does not work, it simply does not cope with the load. Experienced DBA, they can forcibly warm up, different techniques, etc. But the fact remains. How does it warm up normally?

How does the cache warm up? Like this, it warms up. Not fast.

The user goes to the database, asks for something from her, the database randomly reads something from the disk (by chance, because the data is not in the cache), and then gives it away and caches. Then comes the next request, it happens in a different place on the disk, again by chance. Yes, you can warm up, you can do cat index file, you can do many, many, many things, but the fact remains that when there is a lot of data, then no one knows the hot data, which should be in the cache where they are on the disk. How to find out? You will not know this until users begin to request them. You know that an index is hot data, but the idea is that the data is already on the disk in the format in which the data is located, and the hot data is somewhere random. To warm up the cache, you need to read some random data by some optimal algorithm, which is much slower than just reading 2 files linearly. Here they are hot data, the other Tarantool and no. It is like for hot data.
By the way, we posted in open access the video of the last five years of the conference of developers of high-loaded systems HighLoad ++ . Watch, learn, share and subscribe to the YouTube channel .
For disk databases, you need to find these hot data as a grain somewhere. In practice, Mail.ru our super cool admins all that could be squeezed out of MySQL is 1-2 MB / s. On our volumes, and we have 100 GB, 1 TB databases, more than at this speed, it does not work to start it, to warm it up with all the technicians, which is not surprising, because the hot data is scattered across the disk in different places. You need to do siki, you need to do the movements of the head. Conventionally, you read 10 Kbytes of data, made a movement of your head, spent 1 ms, and also read a couple of Kbytes - also spent 1 ms. Thus, when you spend 1 ms per every 10 Kbytes, you get 1 MB / s. Rest against just input / output. Such situation. It should be noted that this difference in heating is the result of the fact that the cache and “always in memory” are two different things. Those. Tarantool always keeps in memory what is needed, and it starts quickly, reads / writes quickly.

And disk databases are arranged differently, they are calculated on the fact that the data lies on the disk, and sometimes there is something in the cache, and this data is scattered right among the disk data and lies somewhere separate, therefore a slow start occurs. The difference is 100 times somewhere.

This is what I said that Tarantool groups all the hot data in one place just by design.

Now let's talk about latency. Latency is the time between starting a query and getting a result. When I talk about Tarantool, I will not compare it with disk databases, because everything is clear, and I will compare it with other in-memory databases.
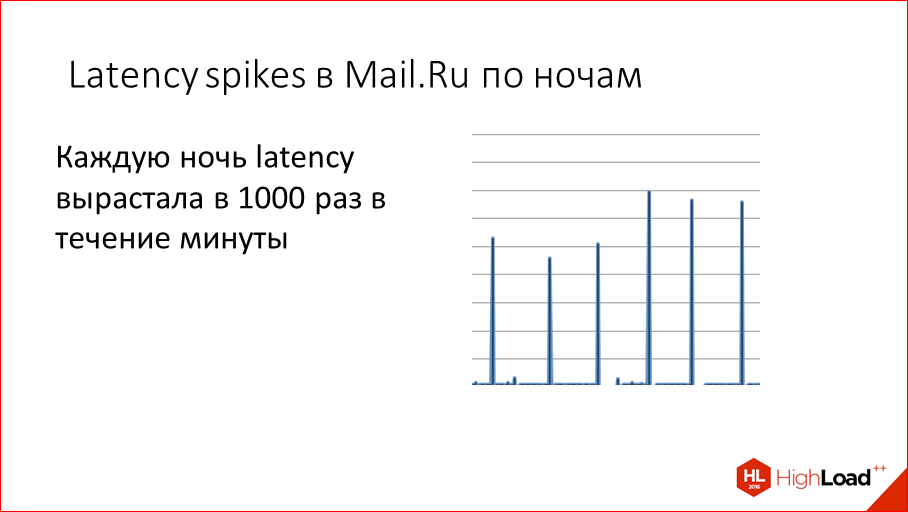
How did it all start? Once upon a time we had every night at Mail.ru we saw such latency peaks, i.e. for some reason, from time to time we grew 1000 times the execution time of the request. Those. it was not a millisecond, but it was a second.
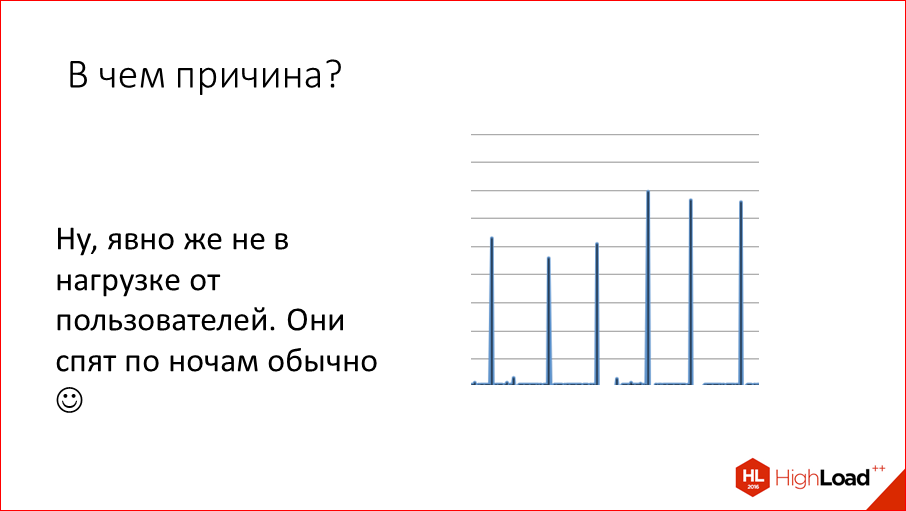
We began to think why this is happening. Moreover, it happens at night, This is clearly not the users to blame, it is something inside of us. We began to deal with this and found out that the reason is simple - it is snapshotting.

In-memory databases, unlike disk, and this is their minus very well-known, must snapshot once in a while. Those. if the disk database does not snapsot, it works for itself, it changes data in B-trees, writes transaction logs and does not need to reset the state to disk periodically because it has data already stored on the disk in the format in which they are readable. The in-memory databases are wrong. They have to snapshot once in a while, because if you don’t do this, huge transaction logs will accumulate that will be used for a very long time. Do you understand why log transactions take longer than snapshot? There can be 50-100-1000 operations to the same field, and each transaction in the transaction log will go separately, and it should all roll. And in the snapshot, it will be like one, just the current last value. Therefore, in-memory databases need to constantly snapshot.

How does it happen, why does snapshoting hinder everything? It would seem, well, the snapshot database and snapshot, it snapshot on disks, it would seem, the disk is a bottleneck, but it also works with memory, why snapshoting can slow down the entire database? Lock This is a very interesting lock.

In order not to snapshot'it with the lock of the entire database, we at one time made it a fork. Fork () is a Linux or Unix system call that simply creates a copy of the process. Those. it creates the entire child process from the context of the parent process.
How did we do the snapshot? We do fork (), create a child process. Fork () has all the data that its parent has, and quietly writes this data to disk. And parent serves transactions at this time. And log at the same time slows down, why? Copy-on-write.
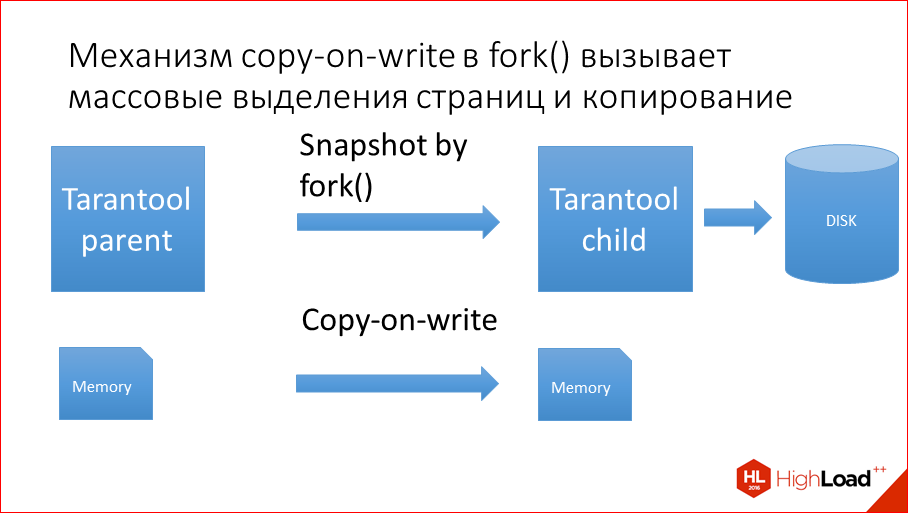
How does fork () happen?Fork (), firstly, copies the descriptors of all pages from parents to children, and if you have hundreds of memory gigs on a machine, then tens of millions of pages or under 100 million pages of 4 KBytes each have a handle which weighs something there, this whole thing needs to be copied first. And after copying all this marahayki begins to work copy-on-write. What it is?Initially, child, when it starts, it inherits all pages of memory from parent, i.e. they have a common memory completely sharpened. But as soon as a parent or child changes at least 1 byte in itself, no matter where, this page is completely copied, and the page is 4 KB. Sowhat is going on? In Tarantool, mass updates are sent to parent, it is updated here and there, and for each update of the several bytes that are updated, the entire page 4 Kb is copied. Update came in some other place - again the page. Those. it is copied hundreds of times more than the data changes. Soeven from a small load, everything leaves on the CPU, the whole machine.

By the way, this problem in other in-memory databases, as far as we know, has not been solved yet, they all do the same, including Redis, Couchbase, Aerospike. But we solved this problem at some point to solve. And I hope that everyone else will follow us, and they will be the same optimal ones too.
Do you have any idea how to improve it? How to get rid of this copying that happens during snapshoting?

In fact, it is its own copy-on-write mechanism, which does not replace the system copy-on-write, but which is simply implemented inside Tarantool, and which operates not with pages, but with fields and entries. This is a bit like a multiview concurrency control.

If you have heard such a word, it is in many databases so. transactions are arranged so as not to block reading when writing is in progress. We, in principle, do the same here, our idea is not to block the recording in Tarantool while reading is in progress, and the entire database is read and dumped to disk. The idea is very simple - during snapshoting, any change to any data item leads to copying this item. Just like copy-on-write. Only not the whole page is copied, but only a small element is copied. And, accordingly, from this profit. If very briefly. At the same time there is no fixed cost in the form of a copy of the table of descriptors. It just starts snapshoting, starts slowly on every change to make a copy of the elements that change.

Something like this happens. There is an old version, a new version. Something has changed, new versions are budding. Everything, we work with the new version. We don’t touch the old version, it participates in snapshoting. Those.all updates go to new versions. The old versions do not change, the old version of the database is complete and, in fact, we do not copy the entire database, we copy only what has changed, and only those bytes that have changed, those records, those fields.

This helped us solve this problem. Night spikes disappeared. This is starting from version 1.6.6. This is about 9 months ago. The snapshot we had was turned on at night, if it was turned on during the day, it would be still worse.
We talked about reading, about writing, about latency. The last topic for today is the bottlenecks in the database.

In fact, of course, there are a lot of bottlenecks, and we will not cover all the bottlenecks, but will highlight the “narrowest”.

In C ++, Java and other languages have built-in structures that are very similar to a database. For example, in C ++, there is a std :: unordered_map - this is a hash, in fact. It is like an index, i.e. there you can write a key, a value, it is quickly read, it is written quickly, all for O (1), and everything is fine. It is, in essence, like a database. Only it is inside your process.
This database works at a speed (I checked it on the MacBook) 2 million operations per second on a single core. In fact, you can accelerate even more, I just did not bother much, but to give you an estimate - millions of operations per second. Just take this cycle and somehow start this hash to read / write by chance.
With this index in the database, everyone knows that it does not work at such a speed. At best, 10 thousand operations on one core, 20. This is a difference of 2 orders of magnitude. Strangely it turns out - the standard C ++ hash that already exists, I don’t want to use it, 100 times faster than the same hash, but inside the database. Why is that?There is one word that explains everything, and that word is “system calls.”
What are system calls? This is when a process goes to the kernel with the goal that it does something to it, which it cannot do - read the file, write the file, read from the network, etc. Every system call is evil.

Where do system calls come from? At least 5 system calls need to be made to process one transaction in the database, because they are obliged to read our request from the network, without this in any way. Next we have to block the data - this is also a system call, this is mutex. Next we have to do something with them. Next we have to unblock them, again this is mutex. Then we must write a transaction to the log, and further, even if we do not write anything in the table space, and write only to the log of transactions, we must also give an answer to the network. Those.less than 5 system calls are very difficult to make. In fact, there are many more of them, in Postgres, MySQL, Oracle, there will be 10 of them, well, plus or minus.
SQLite memory is in the same address space, i.e. SQLite is std :: unordered_map, which works in the same address space as the code works. You can discuss for a long time what is best, because when your database works in the same address space as the code, you lose network interaction and you cannot go from another place. And if you go there from another place on the network, then you get it all.

Why are system calls expensive? This may not be clear to everyone. Because a lot of copying happens. To make a system call, you need to enter the kernel, exit the kernel and copy a lot of data, then restore. You can make some program that makes read from / dev / zero, the simplest one, and reads one byte from there. Reading one byte from / dev / zero, which actually doesn't go anywhere on the disk, just returns 0 to you, it does almost nothing in the kernel, it will occur, well, if 1 million times per second. Even the simplest system call is slower than the useful std :: unordered_map, which does all our dirty work. Even 1. And there are 5 of them here, but in fact there are more. On the log, on the system call, it is huge, it is 90% -95% - just huge.

How did we solve this problem in Tarantool? We thought: why not make more payloads for one system call? Those.idea such that we use a socket in parallel. For example, if there is a client application, all clients that are on the same machine, they all write to the same socket in parallel. They make a lot of write system calls on the client, but Tarantool reads all the requests from the network that came in parallel to it in one read in one read. Then it processes these requests in parallel in one lock. In fact, there are no locks in Tarantool, there is such a special approach, which makes it work without locks. But even if they were there, we accepted a packet of requests, blocked, executed, unblocked, so less system calls. Next one pack all written to disk. Those.also one write, one syscall write for many, many transactions. And one pack gave everything to the client, too, to write to the socket.

It looks like this. This is, in fact, several threads, each of which does its work in parallel. This is a client, it from parallel processes all into one socket in parallel, Tarantool catches it all with one read, gives it further to the processing of the transaction processor, it processes in-memory, then the same packet with one write, i.e. gives a pack of this thread, thread writes to disk with one write. Then he gives the whole pack back, again, the whole inter thread communication, i.e. all locks that are, if they are, they are per pack, not per request, but per per package. And it all comes back. At the same time, everything works in parallel while it is processing it, this new one takes, a new pack, a new pack, a new pack ...
This can be compared with the fact that the bus pulls up to the bus stop, and it takes as many people as there are. Stand 100 - took 100, left. It is worth 1 - took 1, left. On latency is not affected. The idea is that the more requests from the client accumulate here, the more efficiently it uses the processor. If there are few of them, the processor is used inefficiently, it is true, but at the same time, it smokes so, why not?
Many machines, many sockets, then we return to the good old system calls. If each client writes everything synchronously to one socket, then we return to this scheme:

It is also fast, but there is no such magic -
Konstantin Osipov:We have this activity on many sockets, many clients, all the same will not affect the transaction-processor, because the network thread will process all these sockets separately and then the transaction-processor patches. Therefore, we have a network thread ... If we compare Redis with us, then when there are many customers and the load is small, then Redis eats less CPU, this is due to the approach that it does not do interthread communications, it all has one thread. But if the load grows and there are a lot of clients, then we have the throughput of this dedicated thread, which processes transactions, above, because everything else is pulled out of it, and it only does useful work.
Denis Anikin: Because this crap is scaled right there on all cores, they will always be ineffective, because such a load pattern all use their own socket.
Konstantin Osipov: In 2 words, an event-machine runs in each thread, and in each thread its own firewalls work, so the exchange of messages between the fireboxes is just part of the work of the event-machine scheduler. Under the hood, they use shared memory and a file descriptor is used.
Denis Anikin: This is a separate big topic, that Tarantool also has faders, except for this whole thing. He has parallel requests being processed in the faybery ...

There is still a lot of things that I haven’t told, you can still make 2-3 reports here, but the general idea is that we write, read, start and process the mass load faster, simply because we use the right approaches, algorithms and always think about performance.

And finally, you can go to the address on the slide. We have everything open-source, not only the code, but all of our tools. We have such a tool (link to it) that shows the performance of each commit. Those.there for each commit a complete set of performance tests takes place. And if we see that some commit has dropped one of the tests, then we fix it right there. The method is not technical, but this is how we keep ourselves in shape to be always fast.

Contacts
» Anikin@corp.mail.ru
» danikin
» Mail.ru company blog
This report is a transcript of one of the best speeches at the conference of developers of high-loaded HighLoad ++ systems. Less than a month is left before the HighLoad ++ 2017 conference.
We have already prepared the conference program , now the schedule is being actively formed.
What will be this year about Tarantool?
- Synchronization of data from PgSQL to Tarantool / Veniamin Carnations (Calltouch);
- Stored procedures in NoSQL DBMS on the example of Tarantool / Denis Linnik (Mail.Ru);
- Cluster metadata: race key-value-heroes / Ruslan Ragimov, Svetlana Lazareva (RAIDIX)
- libfpta - the pinnacle of performance between SQLite and Tarantool / Leonid Yuriev (Positive Technologies)
Also, some of these materials are used by us in an online training course on the development of high-load systems HighLoad.Guide is a chain of specially selected letters, articles, materials, videos. Already, in our textbook more than 30 unique materials. Get connected!
Source: https://habr.com/ru/post/340062/
All Articles