How IIS supports our BI analytics, and what are the features of settings under Highload

In the analytical part of the Yandex.Money backend, Microsoft IIS is being actively used, and some knowledge has already accumulated about its use in a high-loaded environment that I want to share.
Our analytics runs on the Microsoft stack ( SQL Server and SSIS, SSAS, SSRS), one of the best BI solutions on the market. Once our BI is based on the services of a single vendor, then it is logical to use Microsoft’s IIS solution for hosting web applications.
In the article I will tell you about the features of working with applications running on IIS that are typical for a high-loaded environment.
To begin, we synchronize with you our ideas about "Hayload". As an illustration of a highly loaded system, the article mainly uses our system of fraud protection (antifraud). It processes all incoming Yandex.Money operations - and this is not one hundred operations per second.
# 1 Minimum operations per request, and all heavy - to start the service
It is important to exclude logging, calls to other services and everything else that is not required for a response from processing a user request. Secondary actions can be performed in parallel processes outside the main thread. Especially critical is the observance of this rule, when the service has a certain SLA response.
Anything that is initialized “for a while” should not do this when the first request comes from the user. One of our most important anti-fraud services, anti-fraud, once required loading the entire set of rules at the start of each new request handler.
Imagine a simple network firewall that, when a new packet arrives, passes its contents through a long set of rules. Only in the case of an antifraud, the number of rules and conditions in them have reached such volumes that it is impossible to load all this every time you start the next processing flow without a significant decrease in the responsiveness of the service. At peak antifraud loads, the processor load even reached 100% over several minutes.
In addition, long initialization is fraught with cascading performance degradation. When the first request arrives, the anti-fraud creates a separate handler for it and loads the entire list of security rules there, and the user admires the offer to wait a bit.
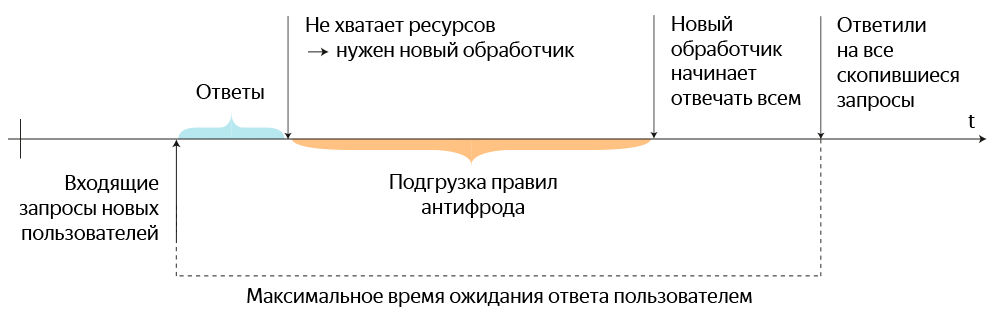
The old process of responding to user requests with a lack of resources ready handlers.
Now imagine that, until the loading of the rules for the previous handler is complete, a transfer request arrives from other users. A similar operation is launched for each of them, and there can be quite a few such duplicate initializations. All this led to periodic interface delays of 30 seconds or more.
Therefore, the object with the rules made the only one and hung up for launch along with the main service. Now the handlers are started in a couple of milliseconds and do not affect the overall performance of the server (bursts within 10%). Initially, there were thoughts to make their launch proactive, but given the quick start of each handler, this would not have a noticeable effect on performance.
On this, of course, you should not stop - you need to introduce optimization at all levels of the system. By the way, when processing the rules, we revised the basic mechanism and divided the rules into online and offline logic and servers, but this story deserves a separate story in the future.
# 2 Do not forget about related queries and different nodes
When it comes to working with a server farm, you need to either teach the application to bind a user session to a specific node, or correctly handle logically related requests that come to different nodes.
Since binding a session to a single node is wrong in terms of users' fault tolerance and happiness, it is better to immediately build a synchronization system so that any cluster node knows about the results of the queries of its “colleagues”. This can be done in different ways, for example:
- Use common for all database nodes, which stores the necessary results of all queries. The important point is that not all requests are stored in such a database, but only those that can be useful on other nodes - this also should not be forgotten when developing an application. Architecturally, such a database can easily become a bottleneck, so you need to carefully monitor its performance. For example, in time to move from normal to SSD-drives.
- Transfer this task to the client. That is, build it in such a way that it includes the result of the previous related query in the next one.
- Finally, you can build an application architecture so that there are not two requests for one process. No related requests - no problem.
For example, we want to know when making a payment when the source account was opened. To do this, you will need to either find the account opening operation itself, or save some of its data separately for later use. In our case, option 1 is used.
# 3 Warm up or not warm up
The application must always be running, and the launch itself must be done in advance, before the appearance of real requests. In addition, the service should already be “warmed up” with test requests in order to immediately process incoming calls with minimal delays.
This is to some extent hampered by the default IIS settings, due to which unloaded processes periodically stop. Even if they are automatically launched at the first relevant request from the outside, the application will need time for initial initialization, processing of related requests and so on.
Previously, web application restarts occurred every 30 minutes on one of the nodes. Therefore, we wrote a Powershell script that took the load off the service on the balancer, restarted the application and ran several dozen requests. After that, the script waited for initialization and, when the application started responding quickly enough, returned the “combat” traffic to the server. However, the algorithm is still relevant, despite the reduction of planned restarts.
Therefore, before starting the process or restarting the web application, it is necessary to transfer the load to another server, wait for the newly launched one to warm up and then include it in incoming processing.
# 4 Choosing the right stream population
IIS has a limited set of service streams for working with disks, a network, etc. These streams are used to process most user requests, and at some point the resources of service streams may not be enough.
IIS has two key stream settings that can limit performance:
Queue Length - adjusts the queue length for incoming requests.
- Worker process - the number of independent copies of the application. There is no universal council on the value, therefore it is necessary to experimentally select the one that is appropriate in your environment.
In addition, there is the parameter Database connection pooling , which is configured in the client DBMS on the side of the web application. Here you need to carefully select values, otherwise there will be a lot of unused connections to the database, each of which consumes memory.
In addition to the service ones, there are worker threads (WorkerThreads) - just those that are used by the server application to start new handlers of the same anti-fraud. It is desirable to issue these flows exactly as much as is required for work. Parameters can be roughly calculated by the following algorithm:
- Take from the characteristics of a particular system the number of requests per unit of time. For example, in our case, this value linearly depends on the number of payments of the entire payment system.
- The number of units of time for each request is best determined experimentally - for example, by turning on logging in the application. IIS logs can also be useful - there are both queries themselves and timestamps.
- The lower limit of the number of threads is obtained by multiplying Clauses 1 and 2.
If it fails to calculate, it is better to conduct an experiment in a test environment, because simply setting the maximum values is not the best idea. You should not waste server resources and increase the time of IIS initialization.
Of course, this algorithm can only be considered as a starting point for evaluating your application. For example, possible load peaks in your environment are not taken into account. For a full assessment, you will need to consider many other parameters that are clearly beyond the scope of this article.
Speaking of resources, the stable operation of 64-bit applications can be hampered by auxiliary libraries compiled under 32-bits — right up to the crash of the main application. When debugging 64-bit applications, you should not forget that the IIS emulator from Microsoft Visual Studio 2012 (and earlier) will not work, since it is 32-bit and you need to use an instance of IIS for debugging in 64-bit mode problems.
# 5 Layout of the application on the entire cluster
From the point of view of exploitation, for Yandex.Money antifraud, a 1 + N cluster is needed, in which you can make changes only once, regardless of the number of nodes. Therefore, experiments in choosing the appropriate “rollout” logic led to the following algorithm:
- The load is removed from one of the nodes, after which an update is installed.
- A check is performed on the application's performance (results of the monitoring system, viewing logs, etc.).
- The script performs a remote backup of the application from the neighboring working server and distributes the release to other machines. In this case, the load is not disconnected
Speaking of monitoring. Of course, the approach for each application is different, but we use IIS logging as one of the tools. Once a day, a script is launched that scans the logs with the help of Microsoft LogParser and generates a report with an average time, number and ratio of response status (500, 200, etc.). I do not post the code itself, because there is too much added solely under the realities of our system. But the idea from the article LogParser, PowerShell and IIS files was used as a basis.
It is important to pre-unify the layout of applications on disks. That is, to locate the site in the same folders on each server - this will simplify further automation. To run an IIS farm, you will need Shared Config to store a single IIS configuration for all nodes, which is better placed on the local drives of each server with synchronization scripts.
When placing Shared Config on a network folder, "special effects" are possible - for example, IIS will not be able to read the configuration and will quench all applications.
A common data storage (in our case, anti-fraud rules) may also be required. For this, it is convenient to use DFS synchronization: the application works with a local folder on the node, and the data of this folder is synchronized over the other machines by means of DFS, which also handles conflicts itself. For greater fault tolerance and ease of upgrading, you can use the Many-to-Many synchronization scheme.
A couple more words about balancing
The key element of any distributed and high-loaded system is the balancer of incoming requests. For example, requests from users to frontend systems. Such a balancer can be of two types:
- Without “feedback” - the internal balancer algorithm simply distributes the incoming request flow among the cluster nodes. A prime example is the NLB service built into Windows Server. It only checks if the neighboring nodes are alive and does not know anything about the state of the applications. The service is quite flexible in load distribution and can be controlled from the command line, but it works only on one local network.
- A more intelligent balancer, which evaluates the state of nodes and redistributes requests for any deviations. For example, for outgoing requests from web servers, you can use Haproxy, which periodically polls all cluster nodes and distributes requests based on this data.
Using Microsoft's web server is convenient for those who use the stack of applications and the development of the same manufacturer. If your application does not need large data structures, then memory costs on the hosts will be minimal. In addition, most of the necessary options and features are provided out of the box, which is clearly simpler than building analogs on Opensource.
If the application is written on the same .Net - why launch it on a “foreign” platform with a fight?
')
Source: https://habr.com/ru/post/339976/
All Articles