[CppCon 2017] Matt Godbolt: What did my compiler do for me?
Continuing the cycle of review articles from the CppCon 2017 conference.
- Bjarne Stroustrup: Learning and teaching modern C ++
- Lars Knoll: C ++ Qt framework: History, Present and Future
- Herb Sutter: Metaprogramming and Code Generation in C ++
- Matt Godbolt: What did my compiler do for me?
This time a very interesting speech from the author Compiler Explorer ( godbolt.org ). Be sure to read to everyone who, for speed, multiplies by 2 using shift (at least x86-64). If you are familiar with x86-64 assembler, you can rewind to the sections with examples ("Multiplication", "Division", etc.). Next, the words of the author. My comments are in square brackets in italics.
My goal is to make you not afraid of the assembler, this is a useful thing. And used it. Not necessarily all the time. And I'm not saying that you have to drop everything and teach the assembler. But you should be able to see the result of the compiler. And when you do this, you will appreciate how much work the compiler has done, and how smart it is.
Prehistory
So, there is a classic way of summing up (before C ++ 11):
int sum(const vector<int> &v) { int result = 0; for (size_t i = 0; i < v.size(); ++i) result += v[i]; return result; } With the advent of Range-For-Loop, we wondered if we could replace it with a more pleasant code:
int sum(const vector<int> &v) { int result = 0; for (int x : v) result += x; return result; } Our concerns were related to the fact that we were already "bitten" by iterators in other languages. We had the experience of container iteration in which iterators were constructed, which added work to the garbage collector. We knew that there was no such thing in C ++, but we had to check it out.
A warning
Reading assembler code: you can easily be misled if you think that you can see what is happening here, that it works faster than that due to fewer instructions. In a modern processor, very complex things happen and you cannot predict. If you make performance predictions, then always run benchmarks. For example from Google or online interactive http://quick-bench.com .
X86-64 assembler basics
Registers
- 16 integer 64-bit general purpose registers (RAX, RBX, RCX, RDX, RBP, RSI, RDI, RSP, R8 - R15)
- 8 80-bit floating point registers (ST0 - ST7)
- 16 128-bit SSE registers (XMM0 - XMM15)
There are conventions for calling ABI functions , this is how functions "communicate" with each other, in particular:
- rdi, rsi, rdx - arguments
- rax - the return value
There are also rules that tell which registers you can overwrite, which ones to save. But if you do not write in assembler, then you don’t need to know them.
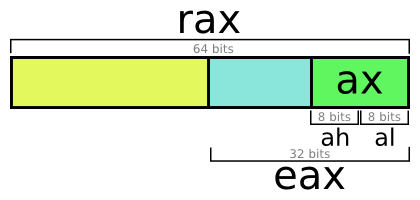
General-purpose registers are 64-bit, but have different names. For example, turning to the eax register, we get the bottom 32 bits of the rax register. But for complex reasons, writing to eax will reset the top 32 bits of rax (why) . This does not apply to ax, ah, al.
Operations
I am using Intel syntax . Who uses Intel syntax in the room? And AT & T ? Oh, it seems today I made myself enemies.
Types of operations (Intel syntax):
op op dest op dest, src op dest, src1 src2 Examples of mnemonic (op): call, ret, add, sub, cmp. Operands (dest, src) can be registers or references to memory of the form:
[base + reg1 + reg2 * (1, 2, 4 or 8)] A reference to memory is rarely an absolute value. We can use the register value, as well as add some offset, set by the value of another register.
Consider an example:
mov eax, DWORD PTR [r14] add rax, rdi add eax, DWORD PTR [r14+4] sub eax, DWORD PTR [r14+4*rbx] lea rax, [r14+4*rbx] xor edx, edx His pseudocode:
int eax = *r14; // int *r14; rax += rdi; eax += r14[1]; eax -= r14[rbx]; int *rax = &r14[rbx]; edx = 0; Let's sort in the lines:
- Reading 4 bytes from r14 register and placing in eax.
- Adding the rdi value to rax.
- Adding a 4-byte value stored at r14 + 4 to eax. Such a memory access is analogous to receiving the first (if we count from zero) array values, if r14 is a pointer to the beginning of an array of 4-byte numbers.
- Similar to the previous one, but you can change the index of the array.
- The lea command is used to load an effective address. [ Approximately how
mov rax, r14+4*rbx, if so it would be possible to write .] - Here is such a strange way to zero. The fact is that
mov edx, 0is 4 bytes, andxor edx, edxis 2.
Compiler Explorer v0.1
First, to study the work of the compiler, I did the following. Compiled with the command:
$ g++ /tmp/test.cc -O2 -c -S -o - -masm=intel \ | c++filt \ | grep -vE '\s+\.' Explanation:
- Running
g++:- compile test.cc
- optimization enabled (-O2)
- without calling the linker (-c)
- with assembler listing generation (-S)
- with output to standard stream (-o -)
- using Intel notation (-masm = intel)
c++filtis a name decoding utility (demangling).grep -vE '\s+\.'- delete all the funny lines.
This command was launched at a certain interval using the watch utility, which set the -d (diff) flag to display the differences. Then I just split the terminal in half using tmux , put the script in one, vi in another. And so got a compiler explorer.
Compiler explorer
Now briefly about the modern version of Compiler Explorer. To create a new window with a code, click on the "Editor" item and hold down dragging to the right place. To create a window with the result of the compilation, you need to click on the button with the arrow up and hold it down. If I hover over the yellow line, the corresponding lines in the assembler part will become fatter.
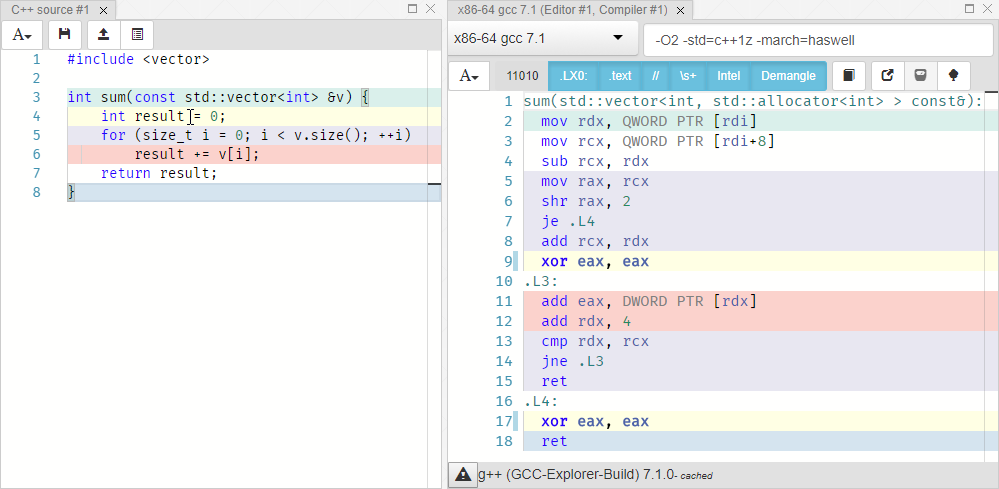
I chose GCC 7.1 with the arguments -O2 -std=c++1z -march=haswell . We see that int result = 0; corresponds to xor eax eax . The rdx register contains a pointer to the current element of the vector. Accumulation result += x; implemented as an increase in the value of the register eax by the value located at the address in rdx, with the subsequent transition to the next element of the array. String return result; not highlighted in color, which means that there is no explicit match for it. This is because after the loop completes, the eax register (which is often used to store the return value) already contains a value. With optimization, the compiler did exactly what we asked for.
Now I will show the result of the compilation without optimization (-O0).
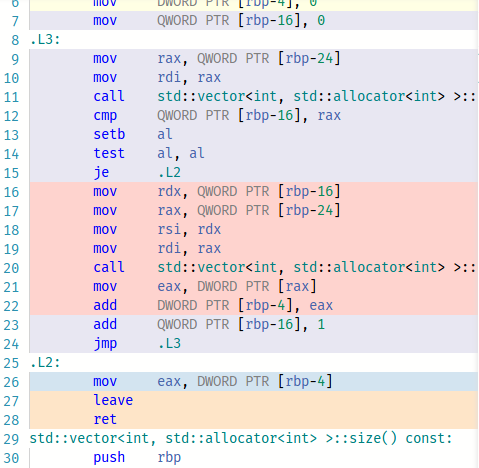
If you compile with -O1 , then GCC for some reason does not consider it necessary to use xor eax, eax instead of mov eax, 0 .
Change to -O3 . This is amazing, just take a look:

Awesome, all these cool operations are used! But you need to use benchmarks to make sure that such code is faster than the simple version.
Let's return to our example:
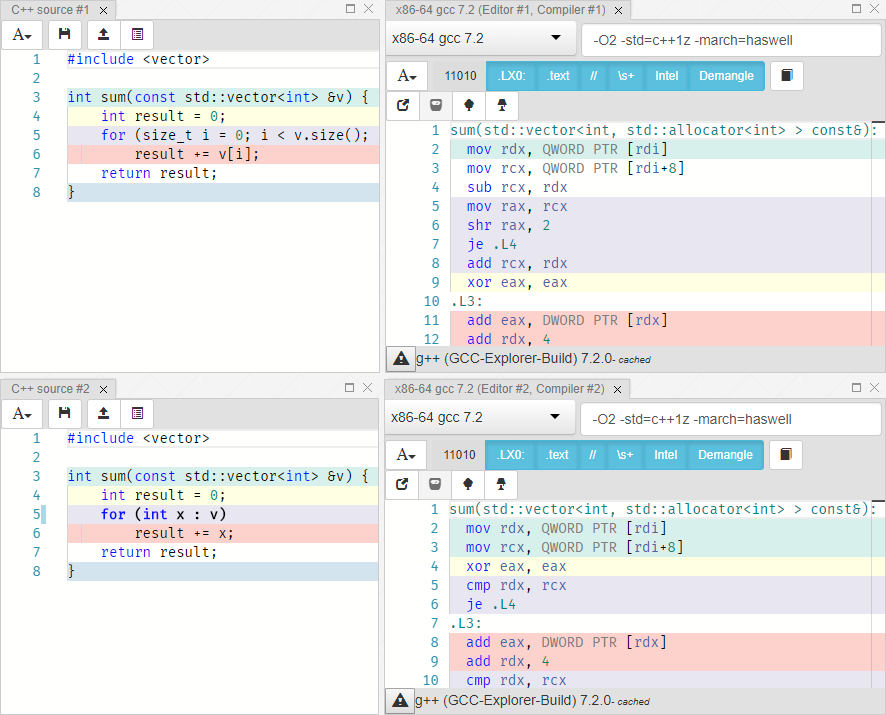
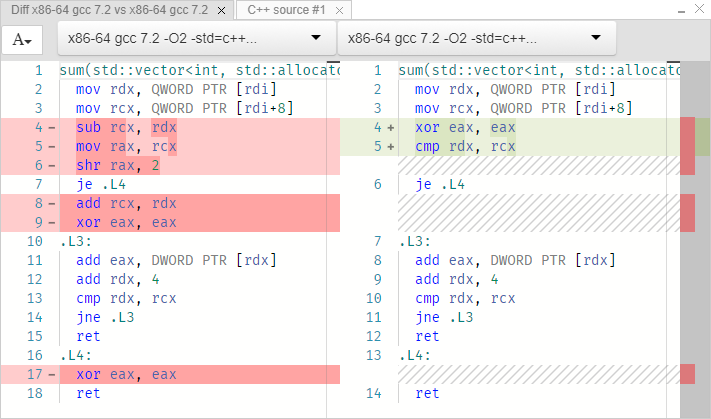
Left cycle from 0 to size, right range for. The code implementing loops is identical in both cases. Let's try this way:
int sum(const vector<int> &v) { return std::accumulate(std::begin(v), std::end(v), 0); } Same.
Detailed analysis
Let's start with the first two lines:
; rdi = const vector<int> * mov rdx, QWORD PTR [rdi] ; rdx = *rdi ≡ begin() mov rcx, QWORD PTR [rdi+8] ; rcx = *(rdi+8) ≡ end() We passed the vector by reference. But there is no such thing as a link. Only pointers. The rdi register indicates the transmitted vector. The values are read at addresses rdi and rdi + 8. It is a mistake to think that rdi is a pointer directly to an array of ints. This is a pointer to a vector. At least in GCC, the implementation of the vector is as follows:
template<typename T> struct _Vector_impl { T *_M_start; T *_M_finish; T *_M_end_of_storage; }; That is, a vector is a structure containing three pointers. The first pointer is the beginning of the array, the second is the end, the third is the end of the reserved memory (allocated) for this vector. The size of the array is clearly not stored here. It is interesting. Let's look at the differences in implementations before the cycle begins. The first example (a normal loop with an index):
sub rcx, rdx ; rcx = end-begin mov rax, rcx shr rax, 2 ; (end-begin)/4 je .L4 add rcx, rdx xor eax, eax The first line calculates the number of bytes in the array. In the third, this value is divided by 4 to find the number of elements (since int is 4-byte). That is, it’s just a size function:
size_t size() const noexcept { return _M_finish - _M_start; } If you get a size of 0 after the shift operation, then Equal Flag is set and the jump operation je (Jump If Equal), and the program returns 0. Thus, the check for equality of the size to zero occurred. Further, we assume that during the iterations an index with a size will be checked. But the compiler guesses that in fact we don’t need this index, and in the loop it will compare the current pointer to the array element with the end of the array (rcx).
Now the second example (with range for):
xor eax, eax cmp rdx, rcx ; begin==end? je .L4 Here it is simply compared whether the initial pointer is equal to the final one, and if so, then jump to the end of the program. In fact, it happened:
auto __begin = begin(v); auto __end = end(v); for (auto __it = __begin; __it != __end; ++it) The cycle itself is identical in both cases:
; rcx ≡ end, rdx = begin, eax = 0 .L3: add eax, DWORD PTR [rdx] ; eax += *rdx add rdx, 4 ; rdx += sizeof(int) cmp rdx, rcx ; is rdx == end? jne .L3 ; if not, loop ret ; we're done We found:
- Range-for turned out to be a slightly more preferred option.
- Compiler options are important.
- std :: accumulate shows the same result.
Multiplication
Further I will show small, but cool examples.
int mulByY(int x, int y) { return x * y; } mulByY(int, int): mov eax, edi imul eax, esi ret edi is the first parameter, esi is the second. Normal multiplication with imul. This is what 4-bit manual multiplication looks like:
1101 (13) x 0101 (5) -------- 1101 0000 1101 + 0000 -------- 01000001 (65) We had to perform 4 additions. It is a miracle that the Haswell 32-bit multiplication takes place in just 4 clock cycles. Addition per 1 clock. But let's see examples in which even faster:
int mulByConstant(int x) { return x * 2; } You can expect the left shift to occur by 1. Check:
lea eax, [rdi+rdi] One operation. The advantage of lea is that you can set the source very flexibly. To implement using the shift, you would have to do 2 operations: copy the value to eax and shift.
int mulByConstant(int x) { return x * 4; } lea eax, [0+rdi*4] lea supports multiplication by 2, 4, 8. Therefore, multiplying by 8 will be the same:
lea eax, [0+rdi*8] At 16 already with a shift:
mov eax, edi sal eax, 4 On 65599:
imul eax, edi, 65599 Yeah, these compiler developers are not as smart as they think they are. I can implement more efficiently:
int mulBy65599(int a) { return (a << 16) + (a << 6) - a; // ^ ^ // a * 65536 | // a * 64 // 65536a + 64a - 1a = 65599a } Checking:
imul eax, edi, 65599 OU! [ Laughter, applause ]. Is this what the compiler is smarter than me? Yes, indeed, multiplication is more effective than these few shifts and additions. But it is on modern processors. Let's return to the past -O2 -std=c++1z -march=i486 -m32 :
mov edx, DWORD PTR [esp+4] mov eax, edx sal eax, 16 mov ecx, edx sal ecx, 6 add eax, ecx sub eax, edx Well, return back return a * 65599; :
mov edx, DWORD PTR [esp+4] mov eax, edx sal eax, 16 mov ecx, edx sal ecx, 6 add eax, ecx sub eax, edx Let the compiler do all these things for you.
Division
In general:
int divByY(int x, int y) { return x / y; } divByY(int, int): mov eax, edi cdq idiv esi ret On Haswell, 32-bit division is performed in 22-29 cycles. Can we do better?
unsigned divByConstant(unsigned x) { return x / 2; } mov eax, edi shr eax No magic, just a shift to the right. Also, no surprises if we divide by 4, 8, 16, etc. Let's try on 3:
mov eax, edi mov edx, -1431655765 mul edx mov eax, edx shr eax What happened?
mov eax, edi ; eax = x mov edx, 0xaaaaaaab mul edx ; eax:edx = x * 0xaaaaaaab mov eax, edx ; (x * 0xaaaaaaab) >> 32 ; ≡ (x * 0xaaaaaaab) / 0x10000000 ; ≡ x * 0.6666666667 shr eax ; x * 0.333333333 ret The value of 2/3 * x turned out to be in edx, the high-order 32 bits of the 64-bit multiplication result. That is, in fact, there was a multiplication by 2/3 and a shift of 1 to the right. [ If it is not very clear, then multiply in some hex-calculator 0xaaaaaaab by 3, 4, 5, 6 ... and watch the high-order digits ].
Remainder of the division
In general:
int modByY(int x, int y) { return x % y; } modByY(int, int): mov eax, edi cdq idiv esi mov eax, edx ret In particular, the remainder of dividing by 3:
int modBy3(unsigned x) { return x % 3; } mov eax, edi mov edx, 0xaaaaaaab mul edx mov eax, edx shr eax lea eax, [rax+rax*2] sub edi, eax mov eax, edi The first 5 lines - already considered division. And in the following, the result of the division is multiplied by 3 and subtracted from the original value. That is, x-3 * [x / 3]. Why do I pay attention to the division by module? Because it is used in hash-map - a favorite container of all. To find or add an object to the container, the remainder of the hash division by the size of the hash table is calculated. This remainder is the index of the table element (bucket). It is very important that this operation works as quickly as possible. In general, it works for quite a long time. Therefore, libc ++ uses powers of two for the allowable table sizes. But these are not very good values. The Boost multi_index implementation contains many acceptable sizes, and a switch with their enumeration.
[ Judging by the question from the audience, not everyone understood this explanation. Roughly speaking, such an implementation: ]
switch(size_index): { case 0: return x % 53; case 1: return x % 97; case 2: return x % 193; ... } Counting bits
The following function counts unit bits:
int countSetBits(int a) { int count = 0; while (a) { count++; a &= (a-1); } return count; } At each iteration, the number of the youngest one disappears until the whole number turns zero. GCC did cleverly:
countSetBits(int): xor eax, eax test edi, edi je .L4 .L3: add eax, 1 blsr edi, edi test edi, edi jne .L3 ret .L4: ret Here, the expression a &= (a-1); replaced by blsr instruction. I have never seen her before preparing for this talk. It clears the last unit and places the result in the specified register. Let's try to choose another compiler - x86-64 clang (trunk) :
popcnt eax, edi This instruction, which performs the counting of bits that people so wanted, that intel added it. Just think what a clang should do. For him there were no clues "I want to count the bits."
Addition
The addition of all integers from 0 to x inclusive:
constexpr int sumTo(int x) { int sum = 0; for (int i = 0; i <= x; ++i) sum += i; return sum; } int main(int argc, const char *argv[]) { return sumTo(20); } mov eax, 210 OK understood! Here constexpr is not so important. If we replace it with static [ so that the function is visible only in one translation unit ], then we get the same result. If you call sumTo(argc) , then the loop is not going anywhere. Let's try clang:
test edi, edi js .LBB0_1 mov ecx, edi lea eax, [rdi - 1] imul rax, rcx shr rax add eax, edi ret .LBB0_1: xor eax, eax ret Interestingly, the cycle is gone. The first two lines check the argument to zero. In the following 5, just the sum formula is: x (x + 1) / 2 == x + x (x-1) / 2. Implemented the second version of the formula, because the first option will cause an overflow if you pass INT_MAX.
How Compiler Explorer Works
[ I don’t understand Frontend, Docker, virtualization and other things that the author was talking about, so I decided not to describe all the details of the implementation so as not to blurt out the nonsense ]
Written on node.js. Launched on Amazon EC2. This is my second speech at this conference, in which I speak about JavaScript and I feel so bad. Of course, we sometimes criticize C ++ ... but if you just look at javascript, oh ...
It all looks something like this:
function compile(req, res, next) { // exec compiler, feed it req.body, parse output } var webServer = express(); var apiHandler = express.Router(); apiHandler.param('compiler', function (req, res, next, compiler) { req.compiler = compiler; next(); }); apiHandler.post('/compiler/:compiler/compile', compile); webServer.use('/api', apiHandler); webServer.listen(10240); Amazon EC2
The following features:
- Edge cache
- Load balancer
- Virtual machines
- Docker images
- Shared compiler storage
Compilers
I installed them using apt-get. Microsoft compilers work through WINE.
Security
A huge security hole. Although compilers only compile, not run, GCC, for example, supports plugins, and you can load the dynamic library ( -fplugin=/path/to/name.so ). Or specs files. At first I tried to find possible vulnerabilities, but I came to the conclusion that it is very difficult to take everything into account. And I began to ponder what is the worst that can happen? You can stop the docker container, but it will start again. Even if you get beyond it in a virtual machine, there will be no privileges. Docker protects me from such tricks.
Frontend
Microsoft Monaco is used as an online code editor. Drag-drop for windows is implemented using GoldenLayout.
Sources
Soon
- CFG - control graph viewer [ I understand, as in IDA ].
- Unification of languages. Compiler Explorer supports other languages ({d, swift, haskell, go, ispc} .godbolt.org). I would like to combine them in one place, and not across different domains. So that you can compare the implementation of the same in different languages.
- Running the code!
Questions
I would like to see support for other libraries, for example Boost.
Some already have:
You talked about switch for all possible table sizes in Boost multi_index. But such an implementation is inefficient - since the values are very sparse, you will not be able to use the jump table, but only binary search.
The switch lists not the dimensions themselves, but their indices.
Is web assembly support planned?
There are many compilers that do not have backends for webassembly. Well, yes, it would be nice, but still busy with other things.
How much is it?
I spend about $ 120-150 per month on Amazon servers.
Whether support of llvm intermediate representation is planned?
Yes, already there, if you run with the -emit-llvm flag. The compiler itself produces this dump, I do nothing. Improved backlight is planned.
How do you tint the relevant lines of source code and assembler?
Just run with the "-g" flag. The resulting listing has comments with line numbers.
')
Source: https://habr.com/ru/post/339962/
All Articles