How to teach your neural network to analyze morphology
Recently, we talked about the generator of poetry . One of the features of the language model underlying it was the use of morphological markup to obtain better consistency between words. However, the morphometry used had one fatal flaw: it was obtained using a “closed” model that was not available for general use. More specifically, the sample on which we were trained was marked up with a model created for Dialogue 2017 and based on ABBYY dictionaries and dictionaries.
I really wanted to save the generator from such restrictions. For this it was necessary to build your own morphological analyzer. At first I made it part of the generator, but in the end it turned into a separate project, which, obviously, can be used not only for generating poetry.
Instead of the morphological engine ABBYY, I used the widely known pymorphy2 . What is the result? Spoiler - turned out well.
Task
I suspect everyone in the school was engaged in morphological analysis: they determined, say, the case of nouns, the face of verbs, and even tried to distinguish between adjectives with participles. As a result, we received tests like this:

It uses the Universal Dependencies markup notation, which is gradually becoming the standard in the world of computational linguistics for most languages.
Despite the fact that morphoanalysis is a very school task, it is not so easy to teach a computer to solve it.
One of the difficulties on this path is our language itself. He is very homonymous. Nouns, for example, very often coincide in different cases: compare, I see a table and a table standing. The forms of completely different words coincide - like, say, the well-known "steel" and "glass". Usually, seeing the context is not at all difficult to distinguish between them. Actually, all systems of morphological analysis are based on the proper use of the context.
There is, unfortunately, another difficulty: the lack of a real standardization of morpho-marking. Different systems may have different opinions on the number of cases in the Russian language or on whether participles with text imprints are independent parts of speech or, for example, verbs. This makes it very difficult to compare different morpho parsers for the Russian language, and therefore the choice of the best.
This year, the MorphoRuEval-2017 morphological analysis track was held at the Dialogue conference, whose goal was to achieve this standardization. It is unlikely that the organizers managed to fully achieve their goal, but they still released training material and a sample to compare their results with the results of the teams participating in the competition. Therefore, I made my morphological analyzer based on the results of this track, and especially on the results of one of its participants, Daniil Anastasyev, who regularly consulted me.
I will try to briefly describe the essence of the track, for details, it is better to refer to the original article and materials .
Task setting in competition
An offer is given. For each word in a sentence, it is necessary to determine the part of speech and grammatical meaning, and also (this was taken into account separately) to predict the word lemma. For example:
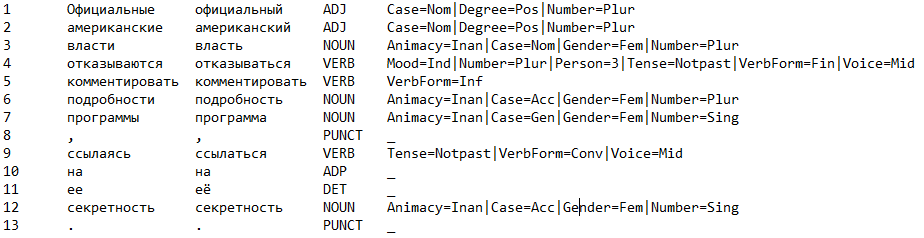
Here, the first column contains the numbers of words, the second column contains the initial version of the token, the third contains the lemma (initial form) words, the fourth column contains part of speech (NOUN is a noun, VERB is a verb, ADJ is an adjective, etc.) column - the rest of the grammatical meaning, a set of realizing gramme for the appropriate grammatical categories.
It is worth explaining here: for each part of speech there is a set of grammatical categories, each category is a set of mutually exclusive grammes. Within a specific word form, each category can be realized uniquely.
For example, for nouns there is a category of number (Number). A number can be either singular (Sing) or plural (Plur). In the text above, the word form of the program has a singular (but it could be plural - because homonymy!). In addition, she is inanimate (Animacy = Inan), in the genitive case (Case = Gen) and feminine (Gender = Fem).
Thus, Animacy, Case, Gender and Number are the categories into which the grammatical meaning of the noun is broken, and the inanimate, genitive, feminine gender, the only number is the vector of grammes realized for them.
As part of the competition, it was proposed to predict a somewhat trimmed set of possible grammatical meanings. In total, about 250 values were chosen as predicted.
The path was divided into 2 parts: open and closed. In the framework of the open part, it was allowed to use any training samples, in the framework of the closed only provided by the organizers (in this case, as far as I understand, the use of external dictionaries was allowed in the closed part).
Daniel only participated in the open track, because he used the company's internal building.
Data
The organizers suggested the following as labeled corps:
- GIKRYA UD - about 1 million tokens
- NCRD UD - about 1.2 million words
- Open UD case - approximately 400 thousand tokens
- SynTagRus - approximately 900 thousand tokens
Testing was conducted on subsamples of multi-genre buildings:
- news corps (from Lenta)
- fiction corps
- Corps texts from VK
Marked corps are quite different from each other. This is primarily due to the conversion errors and the specificity of the markup: the inconsistency of the markup that was already mentioned was attempted to be solved by automatic processing of the cases, but failed to completely reduce them to one format. As a result, at the competition itself, participants used only the GIKRYA corps for training, because adding others only reduced quality. In addition, there are errors in the cases themselves (I noticed this while I was doing the analysis of the errors of my algorithm). Example:

Track results
A total of 11 teams participated in the closed track and 5 in the open. The final results are laid out in a separate table . Accuracy was considered by the grammatical meanings of individual tokens, accuracy immediately by complete sentences, accuracy taking into account lemmatization by tokens, accuracy taking into account lemmatization by sentences.
I took as a basis the model that ranked first in the open track. It was suggested that it was not only the case of ABBYY and corporate morphology, which was later fully justified.
Basic model
Anastasyev DG, Andrianov AI, Indenbom EM, Part-of-Speech Tagging with Rich Language Description
The following signs were used for the word:
embedding words
- vector of grammatical meanings
- class probability vector
- presence of punctuation in the context of specific positions
- capitalization
- the presence of frequency suffixes
The most useful thing here is a vector of grammatical meanings (and for it corporate dictionaries were needed). The vectors of grammatical meanings were obtained from the probabilities of each possible grammatical analysis. These probabilities are simply probabilities of word forms, calculated from the marked corps. In ABBYY, they are rated for huge enclosures, marked up with Compreno.
From several vectors of grammatical meanings with different probabilities, one is obtained as follows: the probabilities of each gramme are taken separately and are normalized to the total probability for a category. For example, for the word chair, the probability of the nominative form is 1.03 · 10 ^ (- 6), and the accusative case is 8.15 · 10 ^ (- 7). Then in the common vector in the cell that corresponds to the accusative case 8.15 · 10 ^ (- 7) / (8.15 · 10 ^ (- 7) + 1.03 · 10 ^ (- 6)) = 0.4417 will be written.
Embeddings of words were taken unprepared, uniformly initialized - the use of pre-trained did not give an increase in accuracy.
The neural network itself is a two-level bidirectional LSTM with an additional fully connected layer:

Quite original in this work is the pre-training on the large internal building of the company with markings that do not correspond to the markings of the competition, and then the additional training on the relatively small building of GIKRYa. This is somewhat reminiscent of standard methods for solving a large class of problems in image analysis: we take a network trained on ImageNet and learn more on our sample.
My decision
pymoprhy2
First of all, I needed a replacement of the corporate analyzer, which would give out possible variants of the analysis of word forms. There were not so many options for Python, and besides, on the basis of pymorphy2 there was already a solution that, for reasons unknown to me, did not get into the competition. The CRF baseline from there to check turned out to be better than almost all solutions from the track.
Model
Initially, I left word signs with word embeddings and vectors of grammatical meanings. In my model, the vectors are already collected on the basis of the options that pymorphy2 returns. The architecture of the model was exactly the same as the original. It turned out about 94% on the benchmark, which is pretty good, considering that I used a much smaller number of scales.
Not satisfied with the quality of the results, I began to think how, first, to shrink the model so that it weighed less and worked a little faster, and secondly, how to accurately take information from the symbolic level. In one of the articles, I saw the solution of both problems at once - to make LSTM RNN above the symbolic level of individual words, and use the output of these grids on words as part of the input vector for the main two-layer network. Testing has shown that the symbolic representation even wins over word embeddings.

As for lemmatization, I did not reinvent my own bicycle. Among the options given by pymorphy2, the lemma of the one that best matches grammes is chosen. If there are none at all, a coincidence in terms of speech will come down. If nothing is the same in terms of speech, we simply take the lemma of the frequency analysis itself.
To get good quality at the competition, however, I had to add additional logic for processing the lemmas. For example, the initial form of participles is defined in the corpus and in pymorphy2 in different ways.
The results of my model on the test sample are presented below.
News:
- Quality by tags:
- 3999 tags out of 4179, accuracy 95.69%
- 264 sentences from 358, accuracy 73.74%
- Full parsing quality:
- 3865 words from 4179, accuracy 92.49%
- 180 offers from 358, accuracy 50.28%
VK:
- Quality by tags:
- 3674 tags out of 3877, accuracy 94.76%
- 418 sentences from 568, accuracy 73.59%
- Full parsing quality:
- 3551 words from 3877, accuracy 91.59%
- 341 sentences of 568, accuracy 60.04%
Hood literature:
- Quality by tags:
- 3879 tags out of 4042, accuracy 95.97%
- 288 sentences from 394, accuracy 73.10%
- Full parsing quality:
- 3659 words from 4042, accuracy 90.52%
- 172 sentences from 394, accuracy 43.65%
If you look at the results table , you can see that my model bypasses all other models from the closed track in terms of the quality of tag definition, and with a margin, but inferior to some in the quality of lemmatization.
On sentences with syntactic homonymy, such as “Mowed oblique oblique oblique”, the model honestly messes up. Moreover, it is unstable, at different stages of training (short-medium-long sentences) in different ways.
Unfortunately, there were no benchmarks on the speed of work within the track. If such were, my model probably sagged pretty badly. On my home laptop, it processes approximately 100 to 500 words per second, which, of course, is not suitable for an industrial solution. Our needs for marking the text for the generator of poems are completely satisfied.
As for the space occupied, the whole model weighs about 3MB, so it is even included in the PyPi package. Here I am satisfied.
There is an assumption that the additional training on other buildings may slightly increase the quality of the model, as well as an increase in the number of scales. But, again, I generally like the current version.
Work examples
Successful parsing


')


Unsuccessful parsing


Links
- Repository
- Package in pypi
- MorphoRuEval-2017: an Evaluation Track for the Automatic Morphological Analysis Methods for Russian
- Part-of-speech Tagging with Rich Language Description
- Do LSTMs really work so well for PoS tagging? - A replication study
- Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss
The post was written in collaboration with Daniel Anastasiev (@DanAnastasyev). Many thanks to Nadia Karatsapova for reading the article.
Source: https://habr.com/ru/post/339954/
All Articles