About the Strata AI conference: the future of artificial intelligence
Habr, hello!
In this article I will talk about the O'Reilly Strata Artificial Intelligence conference, which I happened to visit this summer in New York.
Strata AI - one of the main conferences devoted to artificial intelligence, takes place about once every six months. The conference should not be confused with another well-known event Strata + Hadoop World - it is also held by O'Reilly, but that is devoted exclusively to large data and on the subject they overlap a little.
')

I work as a data scientist at CleverDATA . One of our key expertise is machine learning, and we try to send employees to relevant conferences to obtain new knowledge (we already wrote about the Scala Days Copenhagen conference in the blog), and just to be aware of the main trends.
For the industry of artificial intelligence, this is especially important, because here the landscape is changing more quickly than anywhere, and the number of sources of information is enormous. The purpose of my trip was just to understand that of the “hot” topics we can use in practice in our projects.
I arrived in New York the day before the event and, as it turned out, in the midst of the next gay parade, all the shop windows, building facades and the symbol of the Empire State Building were painted in the colors of the rainbow flag. In part, this set the tone for the trip. The next day, having walked and imbued with the spirit of the city, I drove to register for the conference.

The conference turned out to be quite large-scale and included about 80 speeches, which were held simultaneously in seven streams, so I was able to attend only a small part in person. For the rest, we had to wait for video materials - O'Reilly always publishes them on safarionlinebooks , and there you can watch videos from previous conferences (though you need a subscription).
On the one hand, the subject of the conference is rather narrow: when we say “artificial intelligence”, then in 90% of cases we mean deep neural networks. On the other hand, speakers are invited from perfect different areas, and in view of the diversity of the tasks they solve, the company of speakers turns out to be rather disparate. On the conference website can be found with its agenda .

Speaking of the companies represented at the conference, there are three large groups. The first is the ubiquitous technology giants like Google, IBM, Microsoft, Amazon and others. The second is young companies andsmoothie-oriented AI-oriented startups, which are now in short supply. And the third is representatives of the academic environment - the main supplier of new theories, approaches and algorithms. Personally, my performances of the latter, as a rule, make the greatest impression.
Due to the short format of the presentations (only 45 minutes were allotted for each lecture), there were very few mathematics or algorithms, mostly general ideas were described and examples of their application were demonstrated. In general, this is an understandable approach, if something interests you - welcome, google this topic on the Internet and study it in more detail. Therefore, for myself, I formulated the purpose of attending such events in such a way - to understand what topics are on the ear and in what direction the industry is developing.
By the way, for the entire time of the conference, in none of the speeches I have heard the term “Big Data” so beloved by many, which, in my opinion, speaks of a rather professional level of the audience - the terminology should be used correctly.
Generally, when we say “artificial intelligence,” imagination most often draws something similar.

But in fact, AI is not only and so much about robots, it is much wider. In fact, we are talking about any intellectual system or program capable of solving problems traditionally considered the prerogative of human intellect in conditions of great uncertainty.
The first day the organizers took master classes. These were mostly tutorials on all kinds of deep learning frameworks, which today are “heard” about 10 pieces and which, in my personal opinion, look like two peas in a pod like each other.
Deep learning is the process of learning multilayer neural networks optimized to work with data of complex hierarchical formats, and has recently become the standard approach for analyzing text, images, audio / video data and time series.
The main advantage of deep networks over other methods of machine learning and multi-layer networks (shallow networks) - they eliminate the need to engage in manual feature generation (feature engineering), since this mechanism is embedded in the architecture of the network itself. The downside is that such networks require more data for training and it is more difficult for them to select parameters.
In deep networks, there are 2 basic architectures: convolutional (CNN, Convolutional Neural Networks) and recurrent networks (RNN, Recurrent Neural Networks). The first are used mainly for working with images, and the second - for analyzing texts and any sequences. All other architectures are variations on these two.
So that analysts are not engaged in the implementation of low-level logic, for several years, many APIs have appeared that simplify the development of such networks and reduce it to the configuration of the desired architecture. Almost all are listed here:

I decided not to go crazy and chose the two most popular ones: TensorFlow and Keras.
Keras is one of the most high-level tools in this series, essentially being a Lego-designer. Application development comes down to the choice of network architecture, number of layers, neurons, and activation functions. The simplest deep nets in Keras are assembled into 10 lines of code, which makes this tool ideal for a quick start or prototyping.
TensorFlow, on the contrary, is one of the most low-level tools. Google is positioning it as a package for any symbolic calculations, not only for deep networks. In my opinion, one of the killer features is a awesome dynamic visualization. To understand what is at stake, you can see, for example, here .
TensorFlow is the main technology for a huge number of AI-projects and is used in addition to Google in IBM, SAP, Intel and many other places. An important plus is a large repository of ready-to-use models.

The second and third days were reserved for lectures. After the morning review session with short ten-minute speeches about the achievements of the industry, there was a block of 6 lectures.
I have always been interested in the use of deep networks not for obvious images and text, but for more “traditional” structured data, so the first lecture I chose Eric Green's story from Wells Fargo AI Labs about the analysis of transactional data in banks.
"Advanced" banks have long done in-depth analytics to predict future transactions, segmentation, fraud detection, etc., but so far very few people can boast of a working solution based on deep networks.
The idea of the proposed approach is very simple - first, the transaction history is recorded in a certain structured format, after that each transaction attribute is encoded with a certain number (word embedding), and then deep networks (CNN or RNN) are applied to the resulting vectors. Such a mechanism is universal and allows solving both the problem of classification and the problem of forecasting and clustering transactions. Unfortunately, from the point of view of presenting the material, the lecture turned out to be rather weak, and the author could not extract the details on the quality of this decision.
But the next story about the joint project of Teradata and the Danish Danske Bank on the implementation of an antifraud solution based on in-depth training turned out to be much better. The challenge was to improve the detection of fraudulent transactions. The guys described a rather interesting solution related to the presentation of transactions in the form of “pseudo-pictures” and the subsequent use of a convolutional neural network.
Below is an example of such a pseudo-image, where the transaction attributes are horizontally postponed, and the time points are vertically. In addition, around each attribute (highlighted in light blue) clockwise the most correlated attributes are plotted. Such a view makes it easy to find abnormal patterns in customer behavior.
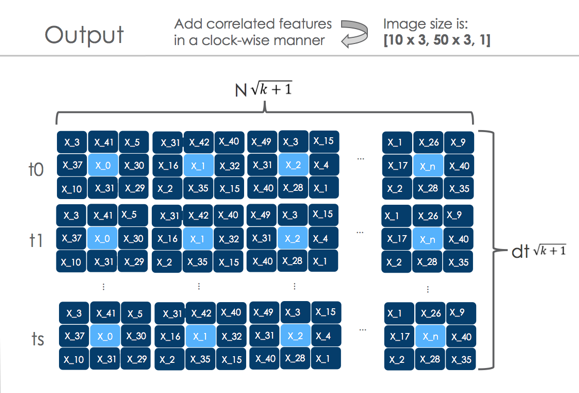
If you believe their numbers, the quality of this decision has left far behind even the beloved gradient boosting. I do not always trust the numbers in the presentations, but even if the quality is comparable, this is a very interesting result. I plan to definitely try this approach somewhere in our tasks.

True, the guys didn’t answer the question “How such a solution will pass the European GDPR requirements on model interpretability”. If it was given to me, I would refer to such a remarkable thing as LIME - the interpreter of complex non-linear models.
Then I went to the panel discussion with three girls, owners of AI-oriented startups. The discussion was about how to build an effective business in the field of AI. In fact, the session turned out to be the most useless: despite the promised “no fluff” in the title, no secrets were revealed, and the “general” questions alternated with the “general” answers. The only thing that was remembered from the lecture was the girl who spoke there with the unusual name Koko (part-time professor of MIT ).

Next, I was interested in a lecture from Amazon about the Apache MXNet distributed deep learning framework . I was counting on a mini-tutorial on this framework, but in fact 90% of the story was devoted to advertising Amazon services, and in the remaining 10% MxNet was mentioned simply as the main platform for in-depth training used in all Amazon services.
Among the achievements of thenational economy of the company were presented:

All of the above projects in one form or another use deep learning and, in particular, the Apache MxNet framework.
Then came the representative of Numenta - a company that develops systems that simulate the work of Neocortex (the part of the human brain responsible for high-level intellectual activity and training). The idea is to build learning structures that are closer in architecture to the human brain than today's neural networks. At the core lies the theory of the hierarchical temporal memory, which is described in the 2004 book of Intelligence by Jeff Hawkins. Actually, he also founded the company Numenta.
The authors themselves are positioning their project as a research and, despite the fact that the algorithm can solve different problems, there are no results yet confirming that the approach works better than traditional deep neural networks. Mat Taylor, who spoke, has a YouTube channel ( HTMSchool ), but I honestly didn’t like it and I would recommend printed materials for review.
The theme of "iron" (AI acceleration) at the conference was raised quite often. Many companies are engaged in the development of high-performance computing systems optimized specifically for the training of neural networks. Well-known examples are Google’s TPU processors (tensor processing units), GPU data centers from Nvidia, or IBM’s TrueNorth computer created in 2014, which follows the architecture of the neocortex with its architecture. As data grows, learning speed becomes an important competitive advantage.
Next was an interesting report by Katie George of McKinsey about the potential for the automation of professions. Partially, the results can be read on the McKinsey website (unfortunately, I did not find them in the form of a single pdf).
They considered each profession as a combination of certain actions and looked at what percentage of these actions could be automated taking into account current technologies. The results surprised me! Despite the fact that the potential for automation is in almost all professions, only 5% of positions can be fully automated. What is a little different from the popular rhetoric that a year later the robots enslave all lawyers (or whatever it was ...).

Predicted physical activity has the greatest potential - these are the same production lines as well as data collection and storage, unpredictable physical activity is the least - for example, playing football (however, fans of the Russian national team can argue about unpredictability).
It is curious that the dependence of automatization on wages has the shape of a triangle - high-paying professions are little automated, but the spread among low-paid workers is much greater.

It is interesting that if you look at the potential in different industries, then the authors put the personalized advertizing task, beloved in our company, to the first place.

If deep analytics has long ceased to be a purely academic discipline and has become quite applied to itself (any stall with a shawarma is able to build models), then in the field of artificial intelligence, things are a little different. The region is actively developing, and people are trying to find all new points of application, among which there are absolutely useless from a practical point of view.
Dag Ek from Google talked about the Google Magenta project - an open repository of models for creating music and drawings.
As a first example, the authors cited a classical piano work created by the machine and, if you do not know the context, it is quite difficult to understand that it was written by a robot.
Then there was a story about the sketch-RNN network, an electronic artist working on the basis of an autoencoder and able to redraw hand-drawn pictures and symbols.
An autoencoder is a network that first translates a picture into a kind of compressed representation, and then restores its original dimension. Thus, the network works as a high-frequency filter and is capable of removing noise from the image (noise in a broad sense, for example, an underecorded mustache).
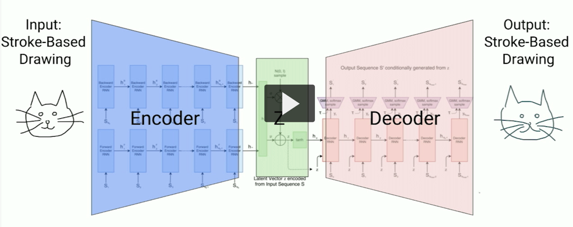
On the left is a man-drawn kote, and on the right is a car-generated image.
Understand where a car draws, where a person is impossible. In general, there are more and more areas where the machines pass the Turing test (the Turing test is not necessarily formulated for interactive systems, it can be, for example, recognition or generation of pictures).
The authors themselves admit that the project does not have a specific goal, but this is normal if we recall that many outstanding inventions were developed without any purpose. At least for the market of pop music, the potential seems to me to be obvious.
Another well-known application of artificial intelligence is a competition with a person in gambling (and not so) games. Thomas Sendholm of Carnegie-Melon University talked about poker. Everyone knows that the machine beats the man in chess for a long time, heard about the recent victory in Go, but the gain of artificial intelligence in the poker tournament this year did not receive much publicity.
In game theory, a game with incomplete information is one in which the player does not see the opponent’s cards. Because of this, at every step he has to deal not with a deterministic game tree, but with probabilities and their expectation. Such games are more difficult, since it is necessary to calculate a greater number of combinations. Solving the game means finding the optimal strategy. If simplified versions of poker using brute-force were solved relatively long ago, the more complex version of noLimit texas Holdem contains 10 ^ 161 (more than the number of atoms in the Universe) game variants, and a direct solution is impossible here.
For the solution, a powerful supercomputer was used, real-time processing the incoming information from the gaming table ( Libratus ), and the Monte-Carlo Counterfactual Regret Minimization method as a mathematical algorithm.
I did not see the tournament, but they say that, contrary to expectations, AI played quite “tightly”, made big bets, “pressed the bank” and took “on the bluff”.

For the gambling industry, this means a robotization prospect comparable to the robotization of the securities market.
One of the top topics related to artificial intelligence is, of course, unmanned cars. It is not only popular, but also very "wide". The developers of such machines are forced to deal not only with computer vision technologies, but also with the theory of optimal control, numerous positioning systems, and to solve many predictive problems. Not so difficult to teach the car to recognize the scene and turn the steering wheel in the right direction. It is much more difficult to create a fully autonomous agent capable of safely moving in a stream with ordinary drivers and coordinating with them.
Anka Dragan from Berkley talked about the behavior problems of unmanned cars on the roads. For the "seed" was given two examples.
The first example: in the states, the guglomachine under test stood for two hours at a crossroads, letting other cars pass because it could not break into the stream. The second example was shown the video a la TV show "Led in Russian", in which somewhere in the vastness of Minnesota, a truck does not allow the car to reorganize into its own row and "squeezes" the car back.

Now being developed drones perceive other cars as obstacles from which you need to stay away: if the robot sees that the car is not giving way, it will not go to it. But such a model of behavior (defensive behavior) will be extremely inefficient: at the intersection, these drones can skip other cars ad infinitum, and on the road they will not even be able to reorganize to the ramp.
On the other hand, as the second example shows, it is also impossible to count on reasonable behavior of drivers. Hence, one of the main concerns is whether the drone will be able to properly behave in unusual situations. Therefore, the authors propose to use a balanced approach when developing - to start a maneuver, examine the driver's reaction, and adjust their actions depending on it.
Next was a lecture by Ruslan Salakhutdinov from Carnegie-Melon University and Apple with an overview of the possibilities of deep learning for solving various problems. From the point of view of the presentation of the material, in my opinion, it was one of the best lectures. In general, I recommend to those who are interested in deep learning to read the lectures of this comrade, of which there is enough of it on the Internet (for example, here ). I will give a few examples.
Over the past few years, deep networks have made a breakthrough, not only quantitative, but also qualitative - new tasks have begun to emerge, combining visual and text analytics. If 2-3 years ago the networks could only classify the subject of the picture, now they can easily give a verbal description of the whole scene in natural language (the caption generation task).

In addition, such systems can clearly distinguish objects in the picture that correspond to each individual word from the description (the so-called Visual Attention Networks).
The main vector of development of recurrent networks is associated with the transition to more advanced mechanisms for remembering the context. At one time in the field of recurrent networks, a similar breakthrough was made by the LSTM (long short term memory) network. Networks with different memory models are also being developed, and one of these options is the MAGE networks, memory as acyclic graph enconding, which can simulate long-term associations in the text.
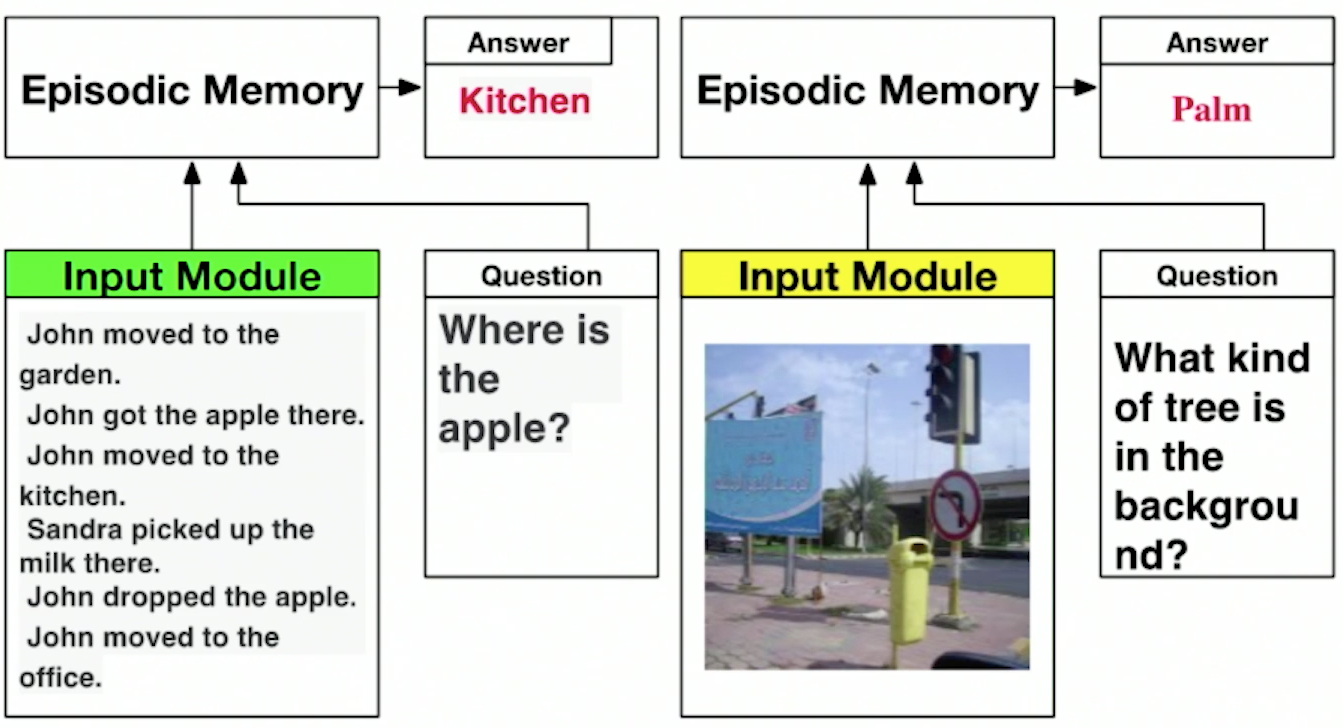
Or a completely amazing thing - dynamic memory networks (Dynamic Memory Networks), which not only analyze pictures or text, but also know how to answer any question asked about this picture or text.
Next was an interesting block about learning with reinforcement (reinforcment learning). With the advent of deep learning, this approach has received a spark of interest. New algorithms are also trying to use the memory mechanism.
In a nutshell, Reinforcment Learning is about learning optimal behavior. Some actions of the system are encouraged, some are fined, and the task of the system is to learn how to act correctly. The main difference from teaching with a teacher is that the system is not encouraged with every action, but rather rarely, so it must independently build very complex behavioral strategies.
The virtual environment, in particular computer games, is ideal for reinforcement learning. It allows you to create an infinite number of experiments, giving you the opportunity to learn the algorithm without limitations, which is impossible to do in reality.
The result of the traditional RL (without memory) was demonstrated on the example of the game Doom. For training used several classic cards. For the key found or the killed enemy was followed by encouragement, and for example, for falling into lava - punishment. If at the first iterations of the training, the bot rested its forehead against the wall, then after 8 hours of training, it took down the players a half-turn so that they did not have time to understand anything. The system perfectly generalized the knowledge gained and played equally well on both old and new maps.

If classic RL is quite suitable for shooters, then for more complex games with logic tasks, remembering the context is already required, i.e. memory availability. For this, a class of algorithms Reinforcment Learning with Structured Memory was developed.
Historically, the very first application of deep networks is image analysis. The lecture from Microsoft was dedicated to computer vision technology. Timothy Hazen outlined four main tasks:

If until 2012 the ball was ruled by traditional approaches, when the generation of features for learning the model was performed manually (HOG, SIFT, etc.), then in 2012 the AlexNet deep neural network made a breakthrough in recognition quality. Later on, deep architectures became the standard.
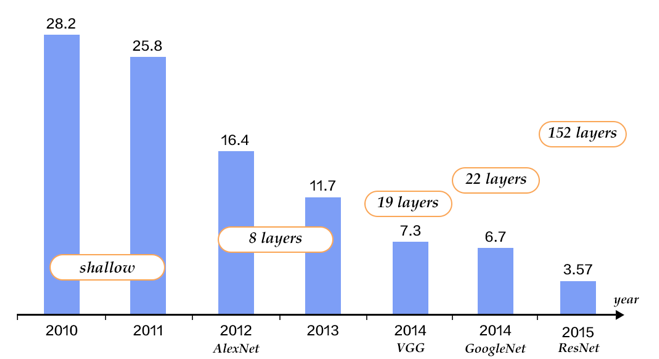
In the field of computer vision, the benchmark is the ImageNet competition, where all new architectures are tested. In 2016, the first place was taken by the network from Microsoft ResNet, containing more than 150 layers. The picture below compares the accuracy of known convolutional networks. The trend towards an increase in the number of layers per face, however, along with it, the problem of a “decreasing gradient” is becoming more and more difficult to train such networks. It can be assumed that further improvements will be associated with a change in the network architecture, rather than an increase in the number of layers.
As an example, four interesting projects were cited, which Microsoft did as consultants.
Of course, not without advertising its two products: Cognitive Toolkit (CNTK) and Custom Vision - a cloud service for the classification of images.
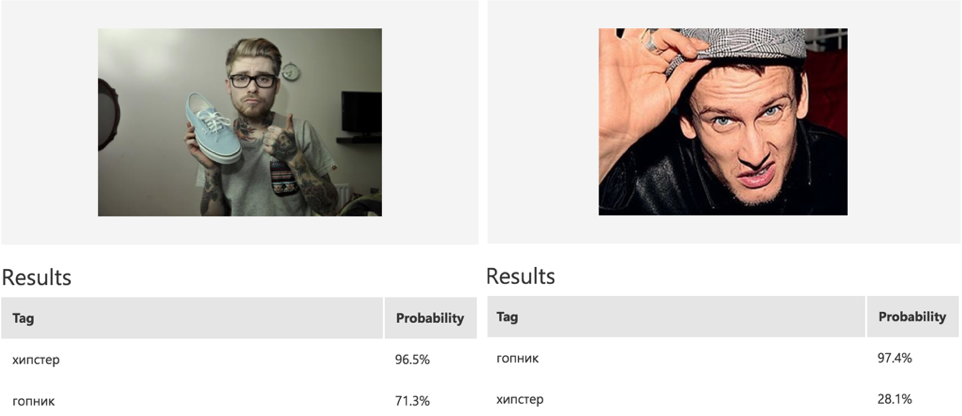
I decided to test the functionality of Custom Vision and tried to teach the binary classification model to distinguish hipsters from gopnik. To do this, uploaded about 1000 images from the Google Images search. No preprocessing done, uploaded as is.
The model was trained for several minutes and overall the results were quite good (Precision: 78%, Recall: 89%). Yes, and on new examples, the classifier works correctly (see below).
It is interesting that at the conference a lot of reports were connected with the dispelling of myths. Since the topic is hype, they write a lot about it and not always in the case.
Such an idea sounded very often: the existing neural networks today cannot be called full-fledged intelligence. So far this is only his very rough model, partly possessing the property of learning, but very poorly generalizing and devoid of what is called "common sense". Many speakers agreed that it would take more than a decade to develop truly “intelligent” intelligence. So far, we don’t even really know how the brain works, not to mention creating its full-fledged artificial counterpart.
Today there is no unambiguous definition of the concept of "artificial intelligence", but most experts agree that such intelligence should have a set of basic abilities inherent in human, in particular the ability:
We have achieved some success, perhaps, only in the ability to learn, and everything else remains at a very basic level. The potential development of artificial intelligence in the coming years is seen precisely in the development of these characteristics.
Teaching with a teacher is a standard approach today, but it is increasingly criticized. Several times an interesting thought was sounded that the future of machine learning behind a teacher-free course of study, or at least the role of the teacher, would diminish.
After all, to understand that you shouldn’t poke your fingers in the socket, a person, unlike a neural network, doesn’t need to repeat this experience 10 thousand times, and usually he remembers from the first (though not all, of course). In addition to basic instincts, a person has a certain common sense, a pre-trained knowledge base, which allows him to easily generalize. There is a hypothesis that it is embedded in the neocortex that was formed over the years of evolution, which is inherent only in the higher mammals part of the brain responsible for learning.
Therefore, one of the directions of development of AI, which the community is now actively engaged in, is the promotion of the One-shot Learning approach - a type of training in which the algorithm is able to make generalizations, analyzing a very small number of learning cases (ideally one). In the future, when making a decision, machines will have to model possible situations, and not just repeat the decision based on experience. The ability to generalize is an integral feature of any intellect.
To illustrate this, find in the two sets below objects similar to the selected ones. Unlike a computer program, a person, as a rule, quite easily copes with this task.

Another close topic is the use of the so-called Transfer Learning - a learning model in which some kind of universal “rough” model is pre-trained, and then it is already learned from new data to solve more specific problems. The main advantage is that the learning process in this case is performed many times faster.
Most often, this term is used in the context of computer vision, but in fact the idea is easily generalized to any AI tasks. As an example - numerous pre-trained networks for image recognition from Google or Microsoft. These networks are trained to recognize the basic elements of the image; to solve specific problems, it is necessary to train only a few output layers of such a network.
In general, the trip was very instructive and gave a lot of food for thought. It is always nice to be in the company of professionals who are doing about the same thing as you. I can summarize my impressions of the conference as follows: in spite of the fact that mankind is still far from creating a true artificial intelligence, the topic is developing by leaps and bounds and finds all new application points in completely different and sometimes unexpected areas. Technologies that were considered exotic a couple of years ago are gradually becoming a new standard.
The next conference of this series is scheduled for April 2018.
In this article I will talk about the O'Reilly Strata Artificial Intelligence conference, which I happened to visit this summer in New York.
Strata AI - one of the main conferences devoted to artificial intelligence, takes place about once every six months. The conference should not be confused with another well-known event Strata + Hadoop World - it is also held by O'Reilly, but that is devoted exclusively to large data and on the subject they overlap a little.
')
About myself
I work as a data scientist at CleverDATA . One of our key expertise is machine learning, and we try to send employees to relevant conferences to obtain new knowledge (we already wrote about the Scala Days Copenhagen conference in the blog), and just to be aware of the main trends.
For the industry of artificial intelligence, this is especially important, because here the landscape is changing more quickly than anywhere, and the number of sources of information is enormous. The purpose of my trip was just to understand that of the “hot” topics we can use in practice in our projects.
I arrived in New York the day before the event and, as it turned out, in the midst of the next gay parade, all the shop windows, building facades and the symbol of the Empire State Building were painted in the colors of the rainbow flag. In part, this set the tone for the trip. The next day, having walked and imbued with the spirit of the city, I drove to register for the conference.
About the conference
The conference turned out to be quite large-scale and included about 80 speeches, which were held simultaneously in seven streams, so I was able to attend only a small part in person. For the rest, we had to wait for video materials - O'Reilly always publishes them on safarionlinebooks , and there you can watch videos from previous conferences (though you need a subscription).
On the one hand, the subject of the conference is rather narrow: when we say “artificial intelligence”, then in 90% of cases we mean deep neural networks. On the other hand, speakers are invited from perfect different areas, and in view of the diversity of the tasks they solve, the company of speakers turns out to be rather disparate. On the conference website can be found with its agenda .
Speaking of the companies represented at the conference, there are three large groups. The first is the ubiquitous technology giants like Google, IBM, Microsoft, Amazon and others. The second is young companies and
Due to the short format of the presentations (only 45 minutes were allotted for each lecture), there were very few mathematics or algorithms, mostly general ideas were described and examples of their application were demonstrated. In general, this is an understandable approach, if something interests you - welcome, google this topic on the Internet and study it in more detail. Therefore, for myself, I formulated the purpose of attending such events in such a way - to understand what topics are on the ear and in what direction the industry is developing.
By the way, for the entire time of the conference, in none of the speeches I have heard the term “Big Data” so beloved by many, which, in my opinion, speaks of a rather professional level of the audience - the terminology should be used correctly.
Generally, when we say “artificial intelligence,” imagination most often draws something similar.
But in fact, AI is not only and so much about robots, it is much wider. In fact, we are talking about any intellectual system or program capable of solving problems traditionally considered the prerogative of human intellect in conditions of great uncertainty.
About deep learning
The first day the organizers took master classes. These were mostly tutorials on all kinds of deep learning frameworks, which today are “heard” about 10 pieces and which, in my personal opinion, look like two peas in a pod like each other.
Deep learning is the process of learning multilayer neural networks optimized to work with data of complex hierarchical formats, and has recently become the standard approach for analyzing text, images, audio / video data and time series.
The main advantage of deep networks over other methods of machine learning and multi-layer networks (shallow networks) - they eliminate the need to engage in manual feature generation (feature engineering), since this mechanism is embedded in the architecture of the network itself. The downside is that such networks require more data for training and it is more difficult for them to select parameters.
In deep networks, there are 2 basic architectures: convolutional (CNN, Convolutional Neural Networks) and recurrent networks (RNN, Recurrent Neural Networks). The first are used mainly for working with images, and the second - for analyzing texts and any sequences. All other architectures are variations on these two.
So that analysts are not engaged in the implementation of low-level logic, for several years, many APIs have appeared that simplify the development of such networks and reduce it to the configuration of the desired architecture. Almost all are listed here:
I decided not to go crazy and chose the two most popular ones: TensorFlow and Keras.
Keras is one of the most high-level tools in this series, essentially being a Lego-designer. Application development comes down to the choice of network architecture, number of layers, neurons, and activation functions. The simplest deep nets in Keras are assembled into 10 lines of code, which makes this tool ideal for a quick start or prototyping.
TensorFlow, on the contrary, is one of the most low-level tools. Google is positioning it as a package for any symbolic calculations, not only for deep networks. In my opinion, one of the killer features is a awesome dynamic visualization. To understand what is at stake, you can see, for example, here .
TensorFlow is the main technology for a huge number of AI-projects and is used in addition to Google in IBM, SAP, Intel and many other places. An important plus is a large repository of ready-to-use models.
The second and third days were reserved for lectures. After the morning review session with short ten-minute speeches about the achievements of the industry, there was a block of 6 lectures.
Deep learning in banks
I have always been interested in the use of deep networks not for obvious images and text, but for more “traditional” structured data, so the first lecture I chose Eric Green's story from Wells Fargo AI Labs about the analysis of transactional data in banks.
"Advanced" banks have long done in-depth analytics to predict future transactions, segmentation, fraud detection, etc., but so far very few people can boast of a working solution based on deep networks.
The idea of the proposed approach is very simple - first, the transaction history is recorded in a certain structured format, after that each transaction attribute is encoded with a certain number (word embedding), and then deep networks (CNN or RNN) are applied to the resulting vectors. Such a mechanism is universal and allows solving both the problem of classification and the problem of forecasting and clustering transactions. Unfortunately, from the point of view of presenting the material, the lecture turned out to be rather weak, and the author could not extract the details on the quality of this decision.
But the next story about the joint project of Teradata and the Danish Danske Bank on the implementation of an antifraud solution based on in-depth training turned out to be much better. The challenge was to improve the detection of fraudulent transactions. The guys described a rather interesting solution related to the presentation of transactions in the form of “pseudo-pictures” and the subsequent use of a convolutional neural network.
Below is an example of such a pseudo-image, where the transaction attributes are horizontally postponed, and the time points are vertically. In addition, around each attribute (highlighted in light blue) clockwise the most correlated attributes are plotted. Such a view makes it easy to find abnormal patterns in customer behavior.
If you believe their numbers, the quality of this decision has left far behind even the beloved gradient boosting. I do not always trust the numbers in the presentations, but even if the quality is comparable, this is a very interesting result. I plan to definitely try this approach somewhere in our tasks.
True, the guys didn’t answer the question “How such a solution will pass the European GDPR requirements on model interpretability”. If it was given to me, I would refer to such a remarkable thing as LIME - the interpreter of complex non-linear models.
Then I went to the panel discussion with three girls, owners of AI-oriented startups. The discussion was about how to build an effective business in the field of AI. In fact, the session turned out to be the most useless: despite the promised “no fluff” in the title, no secrets were revealed, and the “general” questions alternated with the “general” answers. The only thing that was remembered from the lecture was the girl who spoke there with the unusual name Koko (part-time professor of MIT ).
What's there in amazon
Next, I was interested in a lecture from Amazon about the Apache MXNet distributed deep learning framework . I was counting on a mini-tutorial on this framework, but in fact 90% of the story was devoted to advertising Amazon services, and in the remaining 10% MxNet was mentioned simply as the main platform for in-depth training used in all Amazon services.
Among the achievements of the
- Alexa voice assistant,
- Amazon Show television assistant - Alexa option with camera and display,
- Amazon X-Ray - an assistant built into the video player who can show an actor's biography through a frame, as well as display information about the plot and character,
- as well as Amazon Go - a store without cash registers (a gopnik's dream) - you simply pick up the products in the basket and go to the exit, the shop itself determines the composition of the products in the basket and deducts money from the account. The store is now in beta mode (for employees only).
All of the above projects in one form or another use deep learning and, in particular, the Apache MxNet framework.
"Iron logic
Then came the representative of Numenta - a company that develops systems that simulate the work of Neocortex (the part of the human brain responsible for high-level intellectual activity and training). The idea is to build learning structures that are closer in architecture to the human brain than today's neural networks. At the core lies the theory of the hierarchical temporal memory, which is described in the 2004 book of Intelligence by Jeff Hawkins. Actually, he also founded the company Numenta.
The authors themselves are positioning their project as a research and, despite the fact that the algorithm can solve different problems, there are no results yet confirming that the approach works better than traditional deep neural networks. Mat Taylor, who spoke, has a YouTube channel ( HTMSchool ), but I honestly didn’t like it and I would recommend printed materials for review.
The theme of "iron" (AI acceleration) at the conference was raised quite often. Many companies are engaged in the development of high-performance computing systems optimized specifically for the training of neural networks. Well-known examples are Google’s TPU processors (tensor processing units), GPU data centers from Nvidia, or IBM’s TrueNorth computer created in 2014, which follows the architecture of the neocortex with its architecture. As data grows, learning speed becomes an important competitive advantage.
When robots capture people
Next was an interesting report by Katie George of McKinsey about the potential for the automation of professions. Partially, the results can be read on the McKinsey website (unfortunately, I did not find them in the form of a single pdf).
They considered each profession as a combination of certain actions and looked at what percentage of these actions could be automated taking into account current technologies. The results surprised me! Despite the fact that the potential for automation is in almost all professions, only 5% of positions can be fully automated. What is a little different from the popular rhetoric that a year later the robots enslave all lawyers (or whatever it was ...).
Predicted physical activity has the greatest potential - these are the same production lines as well as data collection and storage, unpredictable physical activity is the least - for example, playing football (however, fans of the Russian national team can argue about unpredictability).
It is curious that the dependence of automatization on wages has the shape of a triangle - high-paying professions are little automated, but the spread among low-paid workers is much greater.
It is interesting that if you look at the potential in different industries, then the authors put the personalized advertizing task, beloved in our company, to the first place.
Second day
If deep analytics has long ceased to be a purely academic discipline and has become quite applied to itself (any stall with a shawarma is able to build models), then in the field of artificial intelligence, things are a little different. The region is actively developing, and people are trying to find all new points of application, among which there are absolutely useless from a practical point of view.
Art generation
Dag Ek from Google talked about the Google Magenta project - an open repository of models for creating music and drawings.
As a first example, the authors cited a classical piano work created by the machine and, if you do not know the context, it is quite difficult to understand that it was written by a robot.
Then there was a story about the sketch-RNN network, an electronic artist working on the basis of an autoencoder and able to redraw hand-drawn pictures and symbols.
An autoencoder is a network that first translates a picture into a kind of compressed representation, and then restores its original dimension. Thus, the network works as a high-frequency filter and is capable of removing noise from the image (noise in a broad sense, for example, an underecorded mustache).
On the left is a man-drawn kote, and on the right is a car-generated image.
Understand where a car draws, where a person is impossible. In general, there are more and more areas where the machines pass the Turing test (the Turing test is not necessarily formulated for interactive systems, it can be, for example, recognition or generation of pictures).
The authors themselves admit that the project does not have a specific goal, but this is normal if we recall that many outstanding inventions were developed without any purpose. At least for the market of pop music, the potential seems to me to be obvious.
Poker and game theory
Another well-known application of artificial intelligence is a competition with a person in gambling (and not so) games. Thomas Sendholm of Carnegie-Melon University talked about poker. Everyone knows that the machine beats the man in chess for a long time, heard about the recent victory in Go, but the gain of artificial intelligence in the poker tournament this year did not receive much publicity.
In game theory, a game with incomplete information is one in which the player does not see the opponent’s cards. Because of this, at every step he has to deal not with a deterministic game tree, but with probabilities and their expectation. Such games are more difficult, since it is necessary to calculate a greater number of combinations. Solving the game means finding the optimal strategy. If simplified versions of poker using brute-force were solved relatively long ago, the more complex version of noLimit texas Holdem contains 10 ^ 161 (more than the number of atoms in the Universe) game variants, and a direct solution is impossible here.
For the solution, a powerful supercomputer was used, real-time processing the incoming information from the gaming table ( Libratus ), and the Monte-Carlo Counterfactual Regret Minimization method as a mathematical algorithm.
I did not see the tournament, but they say that, contrary to expectations, AI played quite “tightly”, made big bets, “pressed the bank” and took “on the bluff”.
For the gambling industry, this means a robotization prospect comparable to the robotization of the securities market.
Unmanned cars
One of the top topics related to artificial intelligence is, of course, unmanned cars. It is not only popular, but also very "wide". The developers of such machines are forced to deal not only with computer vision technologies, but also with the theory of optimal control, numerous positioning systems, and to solve many predictive problems. Not so difficult to teach the car to recognize the scene and turn the steering wheel in the right direction. It is much more difficult to create a fully autonomous agent capable of safely moving in a stream with ordinary drivers and coordinating with them.
Anka Dragan from Berkley talked about the behavior problems of unmanned cars on the roads. For the "seed" was given two examples.
The first example: in the states, the guglomachine under test stood for two hours at a crossroads, letting other cars pass because it could not break into the stream. The second example was shown the video a la TV show "Led in Russian", in which somewhere in the vastness of Minnesota, a truck does not allow the car to reorganize into its own row and "squeezes" the car back.
Now being developed drones perceive other cars as obstacles from which you need to stay away: if the robot sees that the car is not giving way, it will not go to it. But such a model of behavior (defensive behavior) will be extremely inefficient: at the intersection, these drones can skip other cars ad infinitum, and on the road they will not even be able to reorganize to the ramp.
On the other hand, as the second example shows, it is also impossible to count on reasonable behavior of drivers. Hence, one of the main concerns is whether the drone will be able to properly behave in unusual situations. Therefore, the authors propose to use a balanced approach when developing - to start a maneuver, examine the driver's reaction, and adjust their actions depending on it.
About Doom, or what else deep networks can do
Next was a lecture by Ruslan Salakhutdinov from Carnegie-Melon University and Apple with an overview of the possibilities of deep learning for solving various problems. From the point of view of the presentation of the material, in my opinion, it was one of the best lectures. In general, I recommend to those who are interested in deep learning to read the lectures of this comrade, of which there is enough of it on the Internet (for example, here ). I will give a few examples.
Over the past few years, deep networks have made a breakthrough, not only quantitative, but also qualitative - new tasks have begun to emerge, combining visual and text analytics. If 2-3 years ago the networks could only classify the subject of the picture, now they can easily give a verbal description of the whole scene in natural language (the caption generation task).
In addition, such systems can clearly distinguish objects in the picture that correspond to each individual word from the description (the so-called Visual Attention Networks).
The main vector of development of recurrent networks is associated with the transition to more advanced mechanisms for remembering the context. At one time in the field of recurrent networks, a similar breakthrough was made by the LSTM (long short term memory) network. Networks with different memory models are also being developed, and one of these options is the MAGE networks, memory as acyclic graph enconding, which can simulate long-term associations in the text.
Or a completely amazing thing - dynamic memory networks (Dynamic Memory Networks), which not only analyze pictures or text, but also know how to answer any question asked about this picture or text.
Next was an interesting block about learning with reinforcement (reinforcment learning). With the advent of deep learning, this approach has received a spark of interest. New algorithms are also trying to use the memory mechanism.
In a nutshell, Reinforcment Learning is about learning optimal behavior. Some actions of the system are encouraged, some are fined, and the task of the system is to learn how to act correctly. The main difference from teaching with a teacher is that the system is not encouraged with every action, but rather rarely, so it must independently build very complex behavioral strategies.
The virtual environment, in particular computer games, is ideal for reinforcement learning. It allows you to create an infinite number of experiments, giving you the opportunity to learn the algorithm without limitations, which is impossible to do in reality.
The result of the traditional RL (without memory) was demonstrated on the example of the game Doom. For training used several classic cards. For the key found or the killed enemy was followed by encouragement, and for example, for falling into lava - punishment. If at the first iterations of the training, the bot rested its forehead against the wall, then after 8 hours of training, it took down the players a half-turn so that they did not have time to understand anything. The system perfectly generalized the knowledge gained and played equally well on both old and new maps.
If classic RL is quite suitable for shooters, then for more complex games with logic tasks, remembering the context is already required, i.e. memory availability. For this, a class of algorithms Reinforcment Learning with Structured Memory was developed.
About computer vision
Historically, the very first application of deep networks is image analysis. The lecture from Microsoft was dedicated to computer vision technology. Timothy Hazen outlined four main tasks:
- image classification
- search for objects in the picture (object detection),
- segmentation - selection of connected areas,
- definition of similarity.
If until 2012 the ball was ruled by traditional approaches, when the generation of features for learning the model was performed manually (HOG, SIFT, etc.), then in 2012 the AlexNet deep neural network made a breakthrough in recognition quality. Later on, deep architectures became the standard.
In the field of computer vision, the benchmark is the ImageNet competition, where all new architectures are tested. In 2016, the first place was taken by the network from Microsoft ResNet, containing more than 150 layers. The picture below compares the accuracy of known convolutional networks. The trend towards an increase in the number of layers per face, however, along with it, the problem of a “decreasing gradient” is becoming more and more difficult to train such networks. It can be assumed that further improvements will be associated with a change in the network architecture, rather than an increase in the number of layers.
As an example, four interesting projects were cited, which Microsoft did as consultants.
- Tracking the movement of snow leopards in the wild (more here )
- A smart fridge - when beer ends, it sends an urgent sms to the owner with a warning or makes an order at the store.
- Recognition of aerial photographs for the analysis of the development of territories ( here ).
- A hackneyed idea for a fashion startup, when from the picture it is determined what is worn on a person, and the most similar clothes are searched for in the nearest stores. By the way, if someone is interested, there is an open dataset with clothes.
Of course, not without advertising its two products: Cognitive Toolkit (CNTK) and Custom Vision - a cloud service for the classification of images.
I decided to test the functionality of Custom Vision and tried to teach the binary classification model to distinguish hipsters from gopnik. To do this, uploaded about 1000 images from the Google Images search. No preprocessing done, uploaded as is.
The model was trained for several minutes and overall the results were quite good (Precision: 78%, Recall: 89%). Yes, and on new examples, the classifier works correctly (see below).
Antihyp
It is interesting that at the conference a lot of reports were connected with the dispelling of myths. Since the topic is hype, they write a lot about it and not always in the case.
Such an idea sounded very often: the existing neural networks today cannot be called full-fledged intelligence. So far this is only his very rough model, partly possessing the property of learning, but very poorly generalizing and devoid of what is called "common sense". Many speakers agreed that it would take more than a decade to develop truly “intelligent” intelligence. So far, we don’t even really know how the brain works, not to mention creating its full-fledged artificial counterpart.
Today there is no unambiguous definition of the concept of "artificial intelligence", but most experts agree that such intelligence should have a set of basic abilities inherent in human, in particular the ability:
- to learn
- to plan and solve tasks,
- generalize,
- communicate with people.
We have achieved some success, perhaps, only in the ability to learn, and everything else remains at a very basic level. The potential development of artificial intelligence in the coming years is seen precisely in the development of these characteristics.
About One-shot Learning and Transfer Learing
Teaching with a teacher is a standard approach today, but it is increasingly criticized. Several times an interesting thought was sounded that the future of machine learning behind a teacher-free course of study, or at least the role of the teacher, would diminish.
After all, to understand that you shouldn’t poke your fingers in the socket, a person, unlike a neural network, doesn’t need to repeat this experience 10 thousand times, and usually he remembers from the first (though not all, of course). In addition to basic instincts, a person has a certain common sense, a pre-trained knowledge base, which allows him to easily generalize. There is a hypothesis that it is embedded in the neocortex that was formed over the years of evolution, which is inherent only in the higher mammals part of the brain responsible for learning.
Therefore, one of the directions of development of AI, which the community is now actively engaged in, is the promotion of the One-shot Learning approach - a type of training in which the algorithm is able to make generalizations, analyzing a very small number of learning cases (ideally one). In the future, when making a decision, machines will have to model possible situations, and not just repeat the decision based on experience. The ability to generalize is an integral feature of any intellect.
To illustrate this, find in the two sets below objects similar to the selected ones. Unlike a computer program, a person, as a rule, quite easily copes with this task.
Another close topic is the use of the so-called Transfer Learning - a learning model in which some kind of universal “rough” model is pre-trained, and then it is already learned from new data to solve more specific problems. The main advantage is that the learning process in this case is performed many times faster.
Most often, this term is used in the context of computer vision, but in fact the idea is easily generalized to any AI tasks. As an example - numerous pre-trained networks for image recognition from Google or Microsoft. These networks are trained to recognize the basic elements of the image; to solve specific problems, it is necessary to train only a few output layers of such a network.
Instead of conclusion
In general, the trip was very instructive and gave a lot of food for thought. It is always nice to be in the company of professionals who are doing about the same thing as you. I can summarize my impressions of the conference as follows: in spite of the fact that mankind is still far from creating a true artificial intelligence, the topic is developing by leaps and bounds and finds all new application points in completely different and sometimes unexpected areas. Technologies that were considered exotic a couple of years ago are gradually becoming a new standard.
The next conference of this series is scheduled for April 2018.
UPD: If you wanted to work with us in CleverData, here are a couple of vacancies
Source: https://habr.com/ru/post/339874/
All Articles