DevOps in Sberbank-Technologies. Instrumental standard
This article will discuss the organization of the instrumental stack DevOps on the example of Sberbank Technologies and PRB. The article is intended for infrastructure automation engineers who need an objective assessment of the structure of work on the implementation of DevOps - and for anyone who wants to become familiar with their work.
It is no secret that in a small cohesive team to organize a DevOps process is quite simple. Moreover, in modern literate developers and admins, such a process can take shape on its own - as a result of a high culture of development and support. But what to do if your small team of ten people begins to grow to the office of hundreds of people? What to do if there are already several thousand people in your organization, and you didn't even smell devops? With these questions, we turned to the staff of Sberbank-Technology, which has a positive experience in implementing DevOps practices in large-scale projects, and learned something.
Safe harbor
First, a small caveat. Many people ask, why do we need to read articles about how this is done in other companies? They did so, and we will do some sort of difference.
Sberbank-Technologies products are used, of course, in Sberbank, and our money depends on the stability and security of their work. The appearance of this article, among other things, shows that the company has reached that point in its development, when it is already possible to talk about internal technological processes, and this is absolutely normal. This is not some kind of security through obscurity, but a really good, high-quality debugged system - this is its value, and the value of the text you are currently reading. This is the thing that really works. With this knowledge, you can do anything, for example, one-on-one to copy the same infrastructure to yourself. Or go to work in Sberbank-Technologies, if you suddenly like to live with such an infrastructure.
Nevertheless, the introduction of devops into commercial operation, we will not discuss yet. Let's pretend that this is not only because of security, but also because the introduction is still underway, and it is not correct here to discuss the results of an unkilled bear. It is assumed that the introduction of the SPRB devops for industrial events will occur at the end of this, or the beginning of next year - perhaps they will talk about it at JBreak / JPoint 2018. Let's focus on the present.
In any case, the article may be errors and omissions. This article is not an official position of Sberbank-Technology or Sberbank. Information obtained from this article cannot be used as a basis for making any commercial and other important decisions.
The scale of the problem
What is special about devts-projects of SBT (let's call the organization in such an informal way)? Of course, this is the scale. In 2017, the number of SBT employees exceeded 9,800 people located in 17 cities of Russia.
Why do we need this lot of people, what are they doing at all? (ask any normal person). Formally, it sounds like this:
- SBT creates software for the largest bank in Russia and Eastern Europe (325 thousand employees)
- Solves complex infrastructure and service tasks that improve the lives of 70% of Russians
- Provides convenience and accessibility of Sberbank services for 110 million people in the world
What does this mean from the point of view of the infrastructure engineer who implements the implementation of the devops? Look, we usually have at least the following set of tasks that need to be set and solved:
- Increase the overall culture of production and service
- Formulate and implement a toolkit for typical tasks (especially CI / CD “pipes”)
- Improve the skills of solving everyday tasks (skills of automated solution of routine issues)
Each of these questions is greatly complicated by the increase in scale. You can quickly agree on engineering practices within your team, but to make peace between 8,500 people who have completely different views on the development is a challenge. An ordinary gallery would have legs here, but the SBT is able to overcome.
What seems to one team freedom (for example, the freedom to use a standardized pipeline, within which you can not think about unnecessary trifles), for the other looks like a significant restriction on the freedom to choose tools. On beautiful marketing presentations on devops, they don’t like to tell that if one team makes the Unified Total Platform of All, then another 100 teams will hate it for having to use this standard platform, but not their favorite Rock and Haskell. On the other hand, if everyone is given the opportunity to choose disparate solutions, there will never be a common product.
Not enough fun. Let's add some more complexity! The fact is that projects such as the Technological Core of a Special Programming Task Force (one of the main projects in the SBT) are extremely complex self-written technologies specifically designed for a special, custom deployment process. (This will be below). In fact, this is a proprietary Java platform, and as the developers like to joke, “just a little more and write your own Java-machine!”. Even the databases here are special - GridGain and a set of unique know-how on how to prepare this GridGain. This complexity is part of the domain, you can’t just take it and say “let's drop everything and rewrite Golang in the form of three microservices”. This is not how it works!
Thus, the instrumental stack is a point of balance not only between different cultures, but also different approaches to design and programming - a bottomless gap between a highly specialized technological stack and the desire to have a stable, tested for decades administration software.
Therefore, each element of the CI / CD SBT tool standard is a compromise solution. These decisions, like the rules of the road, are written in blood and years. It's time to show this instrumental standard!
CI / CD Instrument Standard
And now you are surprised. Surprised by his usual. As we were surprised at JUG.ru when we saw it for the first time, so were the architects of the SBT infrastructure engineers, when they realized what was coming out of it. You are accustomed to, that SBT constantly writes some unimaginable new frameworks, using them in strange ways, then to talk about it at conferences ? Not this time. It turns out that the best way (at the moment, autumn 2017) is to use what everyone uses and polish the solution to a mirror shine.
For starters, a top view:

Approximately all modern projects have the same sequence of steps. PSI is the Acceptance Test.
We apologize in advance that the picture is hard to read on mobile phones. In the future, all these items will be duplicated by large icons, so that you do not lose anything.
For many, it is a shock that coding is almost the most important and bold part of the CI / CD standards. The fact is that if the source software is written critically incorrectly, then no “devops" will help it, nothing will help.
In this regard, there are two fundamental elements that depend on the role:
- The developer . This is usually the Java / Scala / Cpp stack, which is handled on local machines.
- Development of code and other content
- Run unit tests before uploading to repository
- Publish code in the
developbranch - Binding to the task in the bugtracker
- The main developer .
- Code Review
- Merge to
masterbranch
Developers can use what is needed to complete a task. As a standard for Java development, for example, it is better to take the tools that are used throughout the world: Maven (Java itself), Node Package Manager (for the JS front), JUnit and TestNG (testing). SBT does not develop its own build systems, not because it cannot (why are we worse than Google?), But because it would violate the idea of a common equilibrium point. Too many projects external to the company (try to live without the Spring Framework!) Are tied to standard utilities like Maven, and it is pointless to break this integration.
Storage of detailed requirements at this stage occurs on a Wiki-like system (eg, Confluence). Work with tasks is based on standard agile terminology (epic, feature, user-story, etc.), natively implemented in the selected task management system (for example, JIRA). Having these two systems is critical to getting a good result. This rule is written in blood - even a small project should immediately issue a wiki and a bugtracker.
It is important to note that hereinafter, two different repositories are used for development:
- one of the repositories stores the actual product code,
- the other is for storing only build scripts
As part of the idea of Infrastructure as Code, it is now customary to store deployment scripts together with a project in one repository. As a result of long practice, in the PBT they chose to have a separate repository for deployment scripts, and, if necessary, implement a strong coherence programmatically. This feature is associated solely with the scale and need for complex, connected, generalized configurations, when the same “script” can work with different products. Plus, it allows you to separate the development and administration teams by areas of responsibility and access levels. Specific project settings and specialized scripts, of course, are stored with the projects.
Jenkins is used here and hereafter as a control system. Someone may not like it, due to the fact that it is an ancient software, overgrown with a certain amount of legacy, and having a serious footprint on the amount of RAM, processor usage, and so on. But remember what we said about the point of balance? The fact remains that with all its flaws, right now (autumn 2017), Jenkins is the system that everyone agrees to use. In the future this may change.
In addition to Jenkins, an additional system for managing the end-to-end deployment process is used, starting from the coding stage and continuing up to PROM. But this is a special internal software, to describe which in this article does not make sense not only because of the inaccessibility in Open Source, but also because it is very sharpened for specific features of PBT. There is an assumption that any company with a fairly large pipeline always writes a similar system. For small projects, it may exist in a rudimentary form, in the form of a bundle of scripts that are not dependent on Jenkins. When scaling on 10+ projects that come together, it can turn into serious software.
It is important that the deployment scripts repository, jenkins, and end-to-end management tools are available immediately, starting at the coding stage. If someone from the developers will need to go to Jenkins and do a new job there - this is normal. Using devops tools is something as freely available and essential as breathing air.

It's simple. The tools on which the initial build was done and the tests written are used. It uses one of the most extensible toolboxes, and also is heavily language dependent. For Java, this will most likely be JUnit, for .NET - NUnit, for JS - QUnit. It is only important that these tools have the appropriate Jenkins plugins. In extreme cases, you can write them yourself, but this is undesirable. Code verification is a critical step in which it is better to use proven solutions for centuries.
Many developers have their own DEV-stands (servers) on which they can conduct simple system testing and any convenient experiments outside their computer. Of course, these stands are very limited in resources (it is economically pointless for them to allocate a terabyte of RAM), and integration testing cannot be done on them. But for the experiments - go.

At this stage, several key things happen:
- Static code check
- Check for compliance with information security rules
- Found defects are immediately sent to work, because it is very important
For information security, we will not spread here for good reason. The last one who spoke about security was taken away by a UFO :-) Suffice to say that all elements of the CI / CD take into account security requirements, and in the event of something there the mouse will not slip through. Usually, security reduces the usability of CI / CD tools, so this is a very complex topic, filled with special engineering trade-offs.
As for conventional surface static analysis, the SonarQube used. It is clear that for many heterogeneous projects there are various configurations and sets of coding rules, so each of them must be approached individually and with an understanding of the specifics. Of course, for all Java backend projects there are prepared sets of standard rules so that you don’t need to bother your head with details.
Each project has its own stand (server), where you can and should test ready-made solutions. You can’t just roll out an unverified solution for general integration testing. The stand can be allocated both for the entire project as a whole, and for a specific developer (for testing experimental branches). These booths have more serious resources than the personal DEV-booths of developers, but are still limited to reasonable ones, because complete reconstruction of the entire infrastructure on the resources allocated to the project would be incredibly difficult, long and economically meaningless. Therefore, the normal integration testing here will not work, but it is not necessary.
Several important points that occur at this stage:
- Final assembly and publication of artifacts in the repository. For example, for Java it will be Nexus, and any project will be able to access these artifacts using Maven or through a direct link.
- Installing applications on the stand.
- Perform a set of autotests.
An interesting feature of these DEV command stands is that it must already be prepared according to all the rules: install internal software, create test users, and so on. Usually the stand is not one computer, but a cluster of virtual machines, therefore at this moment the correct cluster initialization is also being tested. In fact, a mini-installation testing of the entire stack starts here, starting right from the moment of the stand deployment.
Ansible usually appears at this stage. Ensible is mainly used as a configuration tool for the target system, and is run from Jenkins. In addition, Ensibl can be used more comprehensively to manage already deployed systems - it is not designed for this, but it is perfect for this purpose on the DEV contour. Ensibl was chosen for the fact that he does not need a special agent (except for the SSH server, which is already on all GNU / Linux host systems), so if someone on the SUDDET team needs to restart something on 10 servers in the DEV cluster, this does not require any special “secret admin knowledge”. Ensibl is very simple, therefore, both the developer and the competent administrator, cope with the study of Ensibl as soon as possible.
Of course, there are some problems in using Ensibl. For example, a standard role system may be unnecessarily simple for a complex modular project. In the most recent version there is experimental support for nested roles, but it may not be enough (especially since it is really very raw and not tested for compatibility with other Ensible features). If you try to use Ensible in full scale, as a system not only for configuring, but also for managing target systems, you will have to write a lot of additional strapping software, where Ensibl is just an “SSH assembler” for higher-level commands.
In addition, it quickly turns out that devops, working closely with Ensibl, should know Python. For example, you have some kind of self-written software that has an extremely complex configuration procedure associated with fine-tuning the cluster, Linux, application software, and so on. Many of these operations require working with little-known and native functions for which the community has not written ready-made solutions, and will never write. If you describe it in the playbook on a “clean pit”, it would take dozens of pages of text. And the log of these operations would be difficult-to-read porridge - in particular, this is due to the lack of normal branch management and the corresponding log output (from time to time the question is raised in the community, but it is still there). A better way to solve this problem is to write an Action Plugin and Module, all the complex code in which is encapsulated in an elegantly written Python script. In fact, only plug-in calls containing high-level business parameters remain in the playbook itself - just like the GNU / Linux command line utilities. From this it follows directly that the infrastructure engineer (devops, admin, developer — anyone who is involved in this task) is obliged to know Python at a decent level. It’s not necessary to know it as well as a special Python programmer, but to be able to read and download ready-made code, and write simple modules for Ensibl is a recipe for success.
The result is often, in fact, is not just some kind of "script", but a very complex software that requires special support. This is where the initial division into a pair of repositories went: one for the product code, the other for the code for the deployment scripts. For the deployment scripts repository, you can use some other special repository management system (for example, not Atlassian Stash, but GitLab with specific settings) to add more flexibility in configuration management.
In addition to the tools described above, there are many smaller ones. For example, some projects still use not GridGain, but SQL bases - there you can connect Liquibase for rolling migrations. And so on. Such things are already very dependent on the specifics of the project, and, if possible, they should be standardized. For example, if we chose Selenium as a framework for UI testing, that’s what we should adhere to, since support of such decisions requires a great deal of expertise.

The next stage is a clean, proper system testing on a dedicated stand.
Here are two key things:
- Install and configure the test environment
- Running a set of auto tests
Installing and setting up the environment is often in itself reveals many amazing things that are immediately sent for revision. Basically, they relate to simplicity and ease of administration. Systems tend to grow over time, the complexity of setting increases, and you need to cut these problems in the bud - right from this stand.
The set of autotests for “pure” CT testing may differ from “dirty” DEV testing in the direction of increasing rigor. Even the smallest experimental project must have tests, at least basic smoke testing. If there are no tests, this project will not be allowed for integration testing.

Integration testing is the largest, most complex and important testing. At least, it seems so to developers, because at this stage there is the largest number of complex bugs :-) You need to carry it out as carefully as possible, because any mistake affects the results of the work of not only the specific project, but hundreds, if not thousands of people.
At this stage, the stands simulate real infrastructure, have full-fledged (very large) resources, and receive the full support of system administrators.
There are several required things:
- The test manager should receive an alert about the readiness of the product for publication, and decide whether to do it. The test manager is an invisible front fighter, but his contribution is difficult to overestimate.
- Install and configure the test environment. Since the environment is intended for integration testing, it is common to all projects that are integrated within the umbrella of an umbrella, and goes along with receiving applications for product installation.
- Automatic and manual testing. The most rigorous, complex and large set of tests.
Rang the bell on the word “manual”? Yes, in real systems there are moments that are poorly amenable to automation, and on average, you can’t do anything about it. This is especially true of the responsiveness of the UI (perhaps soon the AI will do them, but not yet). One of the main tasks of the entire team of developers is to make this stage go as quickly and painlessly as possible. - The test manager receives confirmation of the passage of all types of testing and prepares a detailed report.
- We agreed not to write about IB :-)
- Of particular interest is the load testing, the results of which may have long-term consequences, because in fact this is the first moment in the pipeline, when performance is seen not in formal calculations, but in reality.

Fully tested finished product is laid out in a special centralized distribution repository. Together with it all available documentation and other materials are applied. The resulting files are frozen forever. Special means are used to change them in no way possible.
(If you suddenly want to make such a storage yourself, and write in Java, you can simply use Nexus).

Acceptance testing is another topic, dangerously approaching secret knowledge. But at the top level, everything is simple, it happens:
- Conducting special autotests and a large complex of acceptance tests
- Including unprecedentedly complex manual tests.
After passing this stage, we can assume that the product is ready for operation.

Finally, the deployment in the present industrial exploitation, which, for obvious reasons, cannot be written about. And it does not make sense, because The pipeline described above will reach the prom only at the end of the year. Currently, when deploying to a prom, a manual installation procedure is used, using installation instructions attached to the distribution kit, which is performed by special deployment experts.
In the case of automated deployment, there will be two things at this stage:
- A living person (conditionally “devops-engineer”) must manually confirm readiness for deployment
- Automated Deployment
EVERYTHING. This minimal set of tools is already enough for a bunch of people to get along under one roof. It is important to understand that this instrumental standard does not limit the possibilities of developers, but provides a stable platform for further development.
Technological Core
A reader familiar with the reports of Sberbank Technologies at JUG.ru conferences (by the way, the next one will be very soon ) may notice that the story of the devops does not end with the above scheme. Rather, she is just beginning.
The article began with a common instrumental stack precisely because these solutions are very specific to Sberbank-Technologies themselves, and not everyone needs to know about them. For those who are still with us - we continue.
Innovative solutions used in Sbertech require special approaches to development. The reasons could be called a heterogeneous technological stack, the need for aggregation of data from a variety of subsystems, an incredible number of servers needed to service this amount of data, the lack of “weekends” and “nights” when maintenance can be performed, and so on. Despite the need to organize high performance, fault tolerance, and 24x7 maintainability, the solutions obtained should work on standard hardware and not require special supercomputers. The resulting solution must simultaneously possess signs of both a centralized and decentralized system. Difficult situation.
As a result, the so-called Single Information Space was created. This is a cluster architecture in which all nodes are interconnected, everyone can communicate with each. There is no duplication and integration, all data exists in one copy and is available to all modules from any node at any time. The back-end of this system uses an in-memory data grid called GridGain. Today, it is one of the world's best systems for storing and processing large volumes of business data.
It is with this architecture that administrators and devops have to deal with in any integration test. .
, CI/CD . Jenkins Ansible , . .
Java- , .
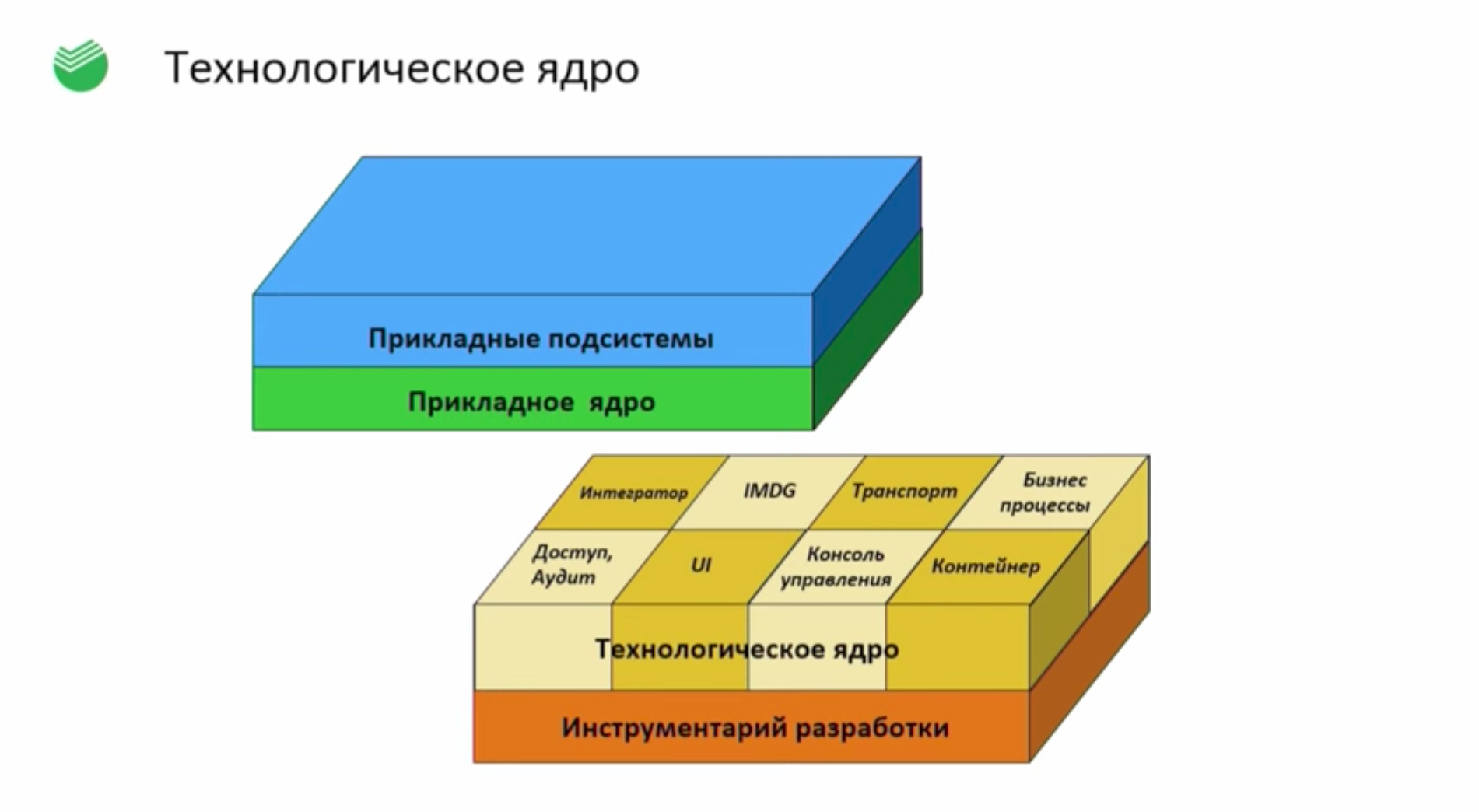
, “” ( -), , . , : , , , . - , Java.
, , OpenSource.
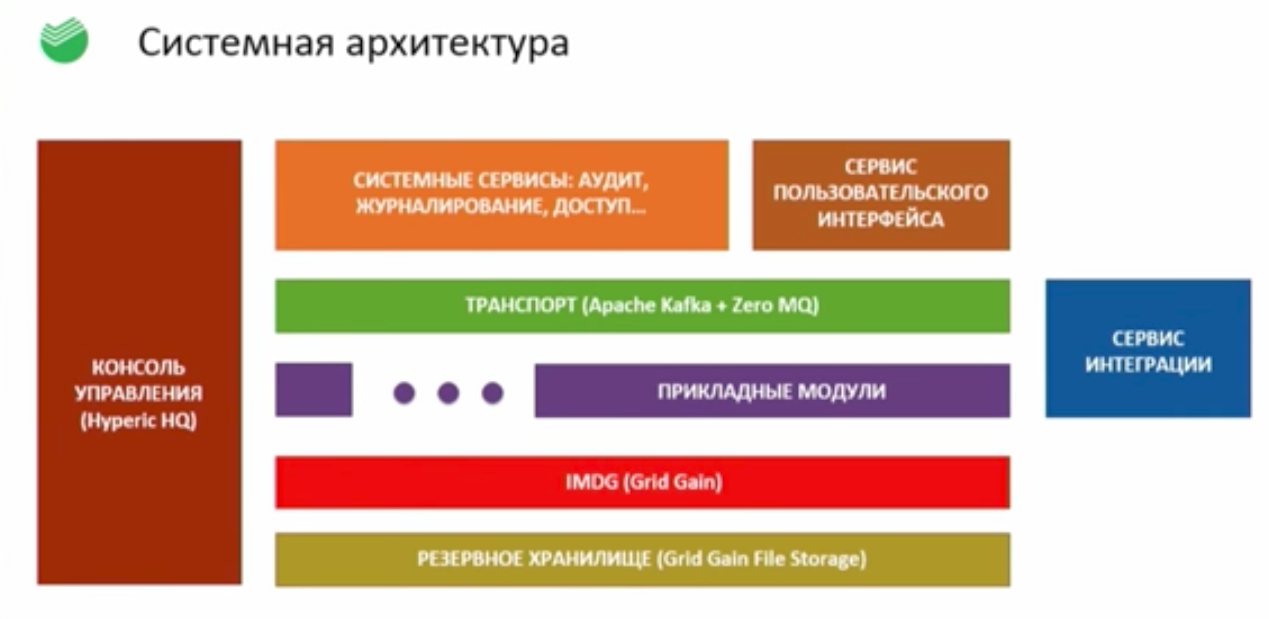
GridGain Apache Ignite ( ? , JUG.ru, ). Apache Kafka , ZeroMQ , Hyperic — Open Source. , — (, , ), , , . , Apache Kafka OpenStack — , .
, — , . , . — Kafka, , . — Ignite/GridGain, , - , IMDG, . ( ), Java- ( ). — , , , .
, , , , , , . , -. , HypericHQ — “ ”. , ( , ) , . - “ Windows”, , - . , Java-: properties-. — /etc , . , , ( ) — .properties /etc . .
, CI/CD , .
Conclusion
CI/CD - ( ), - ( , ).
, : , - ; , ; , - — . , , : , .
, DevOops 2017 , - 20 2017. , - — .
Thanks
-: ( ), ( ), ( .BPM), ( ) . , , . Thank!
')
Source: https://habr.com/ru/post/339856/
All Articles