About choosing data structures for beginners

Part 1. Linear structures
Array
When you need one object, you create one object. When you need several objects, then there are several options to choose from. I have seen many newbies in the code write something like this:
// int score1 = 0; int score2 = 0; int score3 = 0; int score4 = 0; int score5 = 0; This gives us the value of five records. This method works well, until you need fifty or one hundred objects. Instead of creating individual objects, you can use an array.
')
// const int NUM_HIGH_SCORES = 5; int highScore[NUM_HIGH_SCORES] = {0}; A buffer of 5 elements will be created, like this:

Notice that the array index starts at zero. If there are five elements in the array, then they will have indices from zero to four.
Disadvantages of a simple array
If you need a constant number of objects, then the array is quite suitable. But let's say you need to add another element to the array. In a simple array, this is not possible. Suppose you need to remove an element from an array. In a simple array, this is also impossible. You are tied to the same number of items. We need an array whose size can be changed. Therefore, we had better choose ...
Dynamic array
A dynamic array is an array that can change its size. The main programming languages in their standard libraries support dynamic arrays. In C ++, this is a vector . In Java, this is an ArrayList . In C #, this is a list . All of them are dynamic arrays. In its essence, a dynamic array is a simple array, but having two additional data blocks. They store the actual size of a simple array and the amount of data that can actually be stored in a simple array. A dynamic array might look something like this:
// sometype *internalArray; unsigned int currentLength; unsigned int maxCapacity; The internalArray element points to a dynamically allocated buffer. The actual buffer array is stored in maxCapacity . The number of elements used is set by currentLength .
Adding to the dynamic array
When adding an object to a dynamic array, several actions occur. The array class checks if there is enough space in it. If currentLength <maxCapacity , then there is room in the array to add. If there is not enough space, then a larger internal array is placed, and everything is copied to the new internal array. The maxCapacity value is increased to the new extended value. If there is enough space, a new item is added. Each element after the insertion point must be copied to a neighboring place in the internal array, and after copying is completed, the void is filled with a new object, and the value of currentLength is increased by one.

Since it is necessary to move each object after the insertion point, the best case would be to add an element to the end. At the same time, it is necessary to move zero elements (however, the internal array still requires expansion). A dynamic array works best when adding an element to the end rather than to the middle.
When adding an object to a dynamic array, each object can move in memory. In languages such as C and C ++, adding to a dynamic array means that ALL pointers to array objects become invalid.
Remove from dynamic array
Deleting objects requires less work than adding. First, the object itself is destroyed. Secondly, each object after this point is shifted by one element. Finally, currentLength is decremented by one.

As with adding to the end of the array, deleting from the end of the array is the best case, because you need to move zero objects. It is also worth noting that we do not need to resize the internal array to make it smaller. The selected place can remain the same, in case we add objects later.
Deleting an object from a dynamic array results in a shift in the memory after the deleted item. In languages such as C and C ++, deleting from a dynamic array means that pointers to everything after the remote array become invalid.
Disadvantages of dynamic arrays
Suppose the array is very large, and you need to add and delete objects frequently. In this case, objects can often be copied to other places, and many pointers become invalid. If you need to make frequent changes in the middle of a dynamic array, then for this there is a more suitable type of linear data structure ...
Linked lists
An array is a continuous block of memory, and each element of it is located after the other. A linked list is a chain of objects. Related lists are also present in the standard libraries of the main programming languages. In C ++, they are called list . In Java and C #, this is LinkedList . A linked list consists of a series of nodes. Each node looks like this:
// sometype data; Node* next; It creates a structure of this type:

Each node is connected to the following.
Add to linked list
Adding an object to a linked list begins with the creation of a new node. Data is copied inside the node. Then there is an insertion point. The pointer of the new node to the next object is changed to point to the next node after it. Finally, the node in front of the new node changes its pointer to point to the new node.
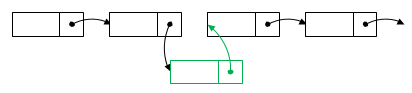
Remove from linked list
When removing an object from a linked list, there is a node in front of the node to be deleted. It is changed to indicate the next node after the deleted object. After that, the deleted object can be safely erased.

Benefits of the linked list
The biggest advantage of a linked list is the addition and removal of objects from the list. Making changes to the middle of the list is very fast. Remember that a dynamic array could theoretically cause the displacement of each element, and the linked list keeps every other object in its place.
Disadvantages of a linked list
Recall that a dynamic array is a continuous block of memory.
If you need to get the five hundredth element of the array, then simply look at the 500 "places" ahead. In the linked list, the memory is chained. If you need to find the five hundredth element, you will have to start from the beginning of the chain and follow its pointer to the next element, then to the next element, and so on, repeating five hundred times.
Random access to the linked list is very slow.
Another serious drawback of the linked list is not very obvious. Each node needs a small extra space. How much space does he need? You might think that only the pointer size is needed for it, but this is not quite so. When dynamically creating an object, there is always a small margin. Some programming languages, such as C ++, work with memory pages. Usually the page takes 4 kilobytes. When using add and remove statements, a whole page of memory is allocated, even if you only need to use one byte.
In Java and C #, everything is arranged a little differently, they have special rules for small objects. These languages do not require the entire 4-kilobyte page of memory, but they still have a small margin. If you use standard libraries, then you don’t need to worry about the second one. They are written in such a way as to minimize wasted space.
Conclusion
These three types (array, dynamic array, and linked list) provide the foundation for almost all more complex data containers. When studying in college, one of the first tasks in the study of data structures is the own implementation of the classes of a dynamic array and a linked list.
These structures are fundamental to programming. No matter what language you will learn, you will use them to work with the data.
Part 2. Linear data structures with endpoints
Stack
Imagine that you have a bunch of sheets of paper.
We put one sheet in a pile. Now we can access only the top sheet.
We put another sheet in a pile. The previous sheet is now hidden and access to it is impossible, we can use the top sheet. When we finish with the top sheet, we can remove it from the pile, opening access to the underlying one.
This is the idea behind the stack. A stack is a LIFO structure. This stands for Last In First Out (“last entered, first out”). When added and removed from the stack, the last item added will be the first to be removed.
For the stack you need only three operations: Push, Pop and Top.
Push adds an object to the stack. Pop removes an object from the stack. Top gives the most recent object on the stack. These containers in most languages are part of the standard libraries. In C ++, they are called stack . In Java and C # this is a stack . (Yes, the only difference in the name is with a capital letter.) Inside the stack is often implemented as a dynamic array. As you remember from this data structure, the fastest operations on dynamic arrays are adding and removing elements from the end. Since the stack always adds and deletes from the end, usually push and pop of objects in the stack is incredibly fast.
Turn
Imagine you are standing in line for something.
The first person in the queue is served, after which he leaves. Then served and goes second in line. Other people come to the line and stand at its end. This is the idea of the “queue” data structure.

The queue is a FIFO structure (First In First Out, “first went in, first out”).
When adding and removing from the queue, the first element to be added will be the first to be retrieved. Queues only need a few operations: Push_Back, Pop_Front, Front and Back. Push_Back adds an item to the end of the queue. Pop_Front removes an item from the front of the queue. Front and Back allow access to the two ends of the queue.
Programmers often need to add or remove items from both ends of the queue. Such a structure is called a double ended queue (deque). In this case, a couple more operations are added: Push_Front and Pop_Back. These containers are also included in most major languages. In C ++, these are queue and deque . Java defines interfaces for a queue and a two-way queue, and then implements them via LinkedList . In C #, there is a Queue class, but there is no Deque class.
Inside the queue and double-sided queue can be arranged quite difficult. Since objects can arrive and be retrieved from either end, the inner container must be able to grow and shorten the queue from the beginning and from the end. Many implementations use multiple memory pages. When either end grows beyond the current page, an extra page is added. If the page is no longer needed, then it is deleted. Java uses the following method: for the linked list, some additional memory is needed, not for pages of memory, but for this language this implementation works fine.
Priority queue
This is a very common variation of the queue. The priority queue is very similar to the normal queue.
The program adds elements from the end and extracts elements from the beginning. The difference is that you can set priorities for certain elements of the queue. All the most important elements are processed in the FIFO order. Then, in order of FIFO, items with lower priority are processed. And this is repeated until the elements with the lowest priority are processed in the FIFO order.
When you add a new item with a higher priority than the rest of the queue, it immediately moves to the top of the queue. In C ++, this structure is called priority_queue . In Java, this is PriorityQueue . There is no priority queue in the standard C # library. Priority queues are not only useful for getting first in line to an organization’s printer. They can be used for convenient implementation of algorithms, for example, the search procedure A *. The most probable results can be given a higher priority, less likely - a lower priority. You can create your own system for sorting and organizing A * search, but it is much easier to use the built-in queue with priority.
Conclusion
Stacks, queues, double-sided queues and priority queues can be implemented based on other data structures. These are not fundamental data structures, but they are often used. They are very effective when you need to work only with finite data elements, and the middle elements are not important.
Part 3. Trees and heaps.
Data structures "trees"
Data trees are very useful in many cases. In the development of video games, tree structures are used to subdivide the space, allowing the developer to quickly find nearby objects without having to check every object in the game world. Even though tree structures are fundamental in computer science, in practice most standard libraries do not have direct implementation of tree-based containers. I will tell you in detail about the reasons for this.
Simple tree
A tree is ... a tree. A real tree has a root, branches, and at the ends of the branches there are leaves.

The tree data structure starts with the root node. Each node can branch into child nodes. If a node has no children, then it is called a leaf node. When there are several trees, it is called a forest. Here is an example of a tree. Unlike real trees, they grow from top to bottom: the root node is usually drawn from above, and the leaves - below.

One of the first questions arises: how many nodes can each child have?
Many trees have no more than two child nodes. They are called binary trees. The example above shows a binary tree. Children are usually called left and right children nodes. Another common tree type in games is a tree with four children. In the quadtree tree, which can be used to cover the grid, the child nodes are usually named after the direction they close: NorthWest or NW, NorthEast or NE, SouthWest or SW and SouthEast (Southeast) or SE.
Trees are used in many algorithms (I already mentioned binary trees). There are balanced and unbalanced trees. There are red-black trees, AVL-trees, and many others.
Although tree theory is convenient, it suffers from serious flaws: storage space and access speed. What is the best way to store a tree? The easiest way is to build a linked list, it turns out to be the worst. Suppose we need to build a balanced binary tree. We start with the following data structure:
// Node* left; Node* right; sometype data; Simple enough. Now imagine that you need to store 1024 elements in it. Then for 1024 nodes you have to store 2048 pointers.
This is normal, the pointers are small and you can get away with a little space.
You may remember that each time you place an object, it takes up a small portion of the additional resources. The exact amount of additional resources depends on the library of the language you are using. Many popular compilers and tools can use a variety of options - from just a few bytes to store data to a few kilobytes, to simplify debugging. I worked with systems in which the placement takes at least 4 KB of memory. In this case, 1024 items will require about 4 MB of memory. Usually the situation is not so bad, but the additional costs of storing many small objects grow very quickly.
The second problem is speed. Processors "like" when objects are in memory next to each other. Modern processors have a lot of very fast memory — a cache — that copes very well with most of the data. When a program needs one piece of data, the cache loads this item, as well as the items next to it. When data is not loaded into very fast memory (this is called a “cache miss”), the program pauses its work and waits for data to load. In the most obvious format, when each element of the tree is stored in its own section of memory, none of them is next to the other. Each time a tree is traversed, the program is suspended.
If creating a tree is directly related to such problems, then you should choose a data structure that works like a tree, but does not have its drawbacks. And this structure is called ...
A pile
To confuse you, I will say that there are two kinds of heaps.
The first is a bunch in memory. This is a large block of memory in which objects are stored. But I will talk about another heap.
The heap data structure is essentially the same as a tree. It has a root node, each node has children, and so on. The heap adds restrictions, its sorting should always be performed in a certain order. A sorting function is required — usually a “less than” operator.
When adding or removing objects from a heap, the structure sorts itself to become a “full” tree, in which each level of the tree is filled, except perhaps for the last row, where everything should be shifted to one side. This makes it very efficient to provide storage space and search by heap.
Heaps can be stored in a simple or dynamic array, that is, little space is spent on its placement. In C ++, there are functions such as push_heap () and pop_heap () that allow heaps to be implemented in the developer’s own container. In standard libraries Java and C # there is no similar functionality. Here is a tree and a bunch with the same information:
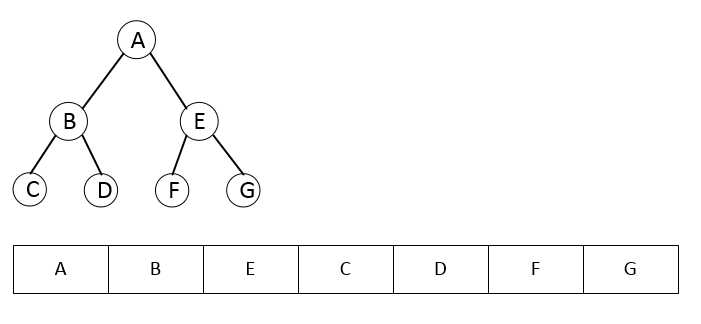
Why they are not in standard libraries
These are simple, fundamental, and very useful data structures. Many people think that they should be present in standard libraries. Within seconds, you can find thousands of tree implementations in a search engine.
It turns out that although trees are very useful and fundamental, there are better containers. There are more complex data structures that have the advantages of a tree (stability and shape) and the advantages of a heap (space and speed). More advanced data structures are usually a combination of data tables with lookup tables. Two tables in combination provide fast access, fast change, and manifest themselves well in dense and non-tight situations. They do not require the transfer of elements when adding and deleting elements, do not consume excessive memory and do not fragment the memory for extended use.
Conclusion
It is important to know about the data structures "tree", because in the work you often have to use them. It is also important to know that these data structures, when directly implemented, have disadvantages. You can implement your own tree structures, just know that more compact types exist. Why did I talk about them if they are not really used in standard libraries? They are used as internal structures in our next topic:
Part 4. Nonlinear data structures.
These data structures are different from arrays and lists. Arrays are sequential containers. Elements in them are arranged in order. When you add multiple items in a specific order, they remain in that order.
Nonlinear data structures do not necessarily remain in the order in which they are added. When adding or removing items, the order of other items may change. Inside they consist of trees and heaps, discussed in the previous section.
There are many variations of such data structures. The most basic are the data dictionary, as well as ordered and unordered sets.
Data dictionary
An ordinary dictionary consists of a set of words (key) and definition (value). Since the keys are in alphabetical order, any element can be found very quickly.
If the dictionaries were not sorted, then the search for words in them was incredibly difficult.
There are two main ways to sort items in a dictionary: a comparison or hash. Traditional ordering by comparison is usually more intuitive. It is similar to the order of a paper dictionary, where everything is sorted alphabetically or by numbers.
When sorting items in this way, a comparison function may be required. Typically, this default function is a “less than” operator, for example, a <b .
The second way to sort items is to use hash. A hash is simply a way to convert a data block to a single number. For example, the string “blue” may have hash 0xa66b370d, the string “red” - hash 0x3a72d292. When a data dictionary uses a hash, it is usually considered as unassorted. In fact, it is still sorted by hash, rather than by human-friendly criteria. The data dictionary works in the same way. There is a slight difference in speed between using dictionaries with traditional sorting and sorting by hash. The differences are so small that they can be ignored.
In C ++, there is a family of containers, map / mutimap or unordered_map / unordered_multimap . In Java, the family is called HashMap ,TreeMap or LinkedHashMap . In C #, this is a Dictionary or SortedDictionary . Each of them has its own implementation features, for example, sorting by hash or by comparison, assumption of duplicates, but in general the concept is the same. Note that in each of the standard libraries there is an ordered version (in which a comparison is specified) and an unordered version (where the hash function is used). After adding items to the data dictionary, you can change the values, but not the key.
Let us return to the analogy with the paper dictionary: you can change the definition of a word without moving the word in the book; if you change the spelling of the word, you will have to delete the first spelling and re-insert the word with the new spelling. Details of the work you can find in the textbooks. It is enough to know that dictionaries are very fast when searching for data, and can be very slow when adding or removing values.
Ordered and unordered set
An ordered set is almost the same as a dictionary. Instead of a key and a value, there is only a key in it. Instead of a traditional vocabulary with words and definitions, there are only words. Sets are useful when you need to store only words without additional data. In C ++, the family of structures is called set / multiset or unordered_set / unordered_multiset . In Java, this is HashSet , TreeSet or LinkedHashSet . In C #, they are called HashSet and SortedSet .
As is the case with dictionaries, there are ordered versions (where a comparison is given) and unordered versions (where a hash function is used). After adding the key, it also can not be changed. Instead, you need to delete the old object and insert a new one. Often they are implemented in the same way as a data dictionary, they just store only the value. Since they are implemented in the same way, they have the same characteristics. The sets look up and find the values very quickly, but they work slowly when adding and removing items.
Conclusion
The container classes of data dictionaries, ordered and unordered sets are very useful for quick data retrieval. Often they are implemented as trees or hash tables, which are very effective in this regard. Use them when you need to create data once and often refer to it. They are not as effective at adding and removing items. Making changes to a container may cause an offset or reordering inside it. If you need to follow this usage pattern, it is best to choose an ordered linked list.
Part 5. The right choice of data structures.
In the previous sections, we listed the most frequently used data structures.
Briefly repeat them.
There are linear structures: an array, a dynamic array, and a bound array. They are linear because they remain in the order in which they are located. Arrays are very fast with random access and have relatively good performance when added and removed from the end. The linked list is very good at frequent additions and deletions from the middle.
There are linear data structures with endpoints: a family of stacks and queues. Both work about the same as their counterparts in the real world. In a stack, for example, in a stack of plates or in a data stack, you can push something up, you can get access to the top element, and you can pop this element. The queue, as well as the queue of people, works by adding to the end of the line and removing from the beginning of the line.
Then there are non-linear data structures: a data dictionary, an ordered and unordered set. They are all internally non-linear, the order in which you add them, in essence, is not related to the order in which you get them back. The data dictionary works much like a real paper dictionary. It has a key (the word we are looking for) and a value (definition of the word). An ordered set is exactly the same as a data dictionary containing keys, but not values, and sorted. An unordered set is just a “bag” with objects. The name is a bit confusing, because in fact they are ordered, just the way of ordering is inconvenient for a person. All of these structures are ideal for quick searches.
The effect of the right choice
Most of the time, programmers have to iteratively process datasets.
Usually we do not care about the order in which the set is located, we simply start from the beginning and visit each element. In this very common situation, the choice of data structure is not really important.
If in doubt, the best choice is usually a dynamic array. It can grow to any volume, while it is relatively neutral, which makes it quite easy to replace it later with another data structure. But sometimes the structure is very important.
One of the most frequent tasks in games is finding a path: you need to find a route from point A to point B. One of the most common algorithms for finding a path is A *. In the A * algorithm, there is a data structure containing partial paths. The structure is sorted so that the most likely partial path is in front of the container. This path is estimated, and if it is not complete, the algorithm turns this partial path into several partial paths of a larger size, and then adds them to the container.
Using a dynamic array as this container will be a bad choice for several reasons. First, removing elements from the beginning of a dynamic array is one of the slowest operations we can perform. Secondly, re-sorting the dynamic array after each addition can also be slow. As you can remember from the above, there is a data structure optimized for this type of access. We remove from the beginning and add from the end, and automatic sorting is performed based on which path is the best. The ideal choice for container A * paths is the priority queue, it is built into the language and fully debugs.
The choice of patterns
The choice of data structure mainly depends on the usage pattern.
Dynamic array - the default selection
If in doubt, use a dynamic array. In C ++, this is a vector . In Java, it is called ArrayList . In C #, this is a list . In general, a dynamic array is what you need. It has good speed for most operations, and good speed for everyone else. If you find out that you need another data structure, then it will be the easiest to switch from it.
Stack - only one end
If you use add and remove from one end only, then select the stack. This stack in C ++, Stack in Java and C #. There are many algorithms using a stack data structure. The first that comes to my mind is a two-stack calculator. Numerical problems, such as the Towers of Hanoi, can be solved using the stack. But, probably, you will not use these algorithms in your game. However, gaming tools often perform data parsing, and parsers actively use stack data structures to ensure the right combination of pairs of elements. If you work with a wide range of AI types, then the stack data structure will be incredibly useful for a family of machines called pushdown automaton.
Queue family - first entered, first out.
If you add and remove only from both ends, then use either a queue or a two-way queue. In C ++, this is queue or deque . In Java, you can use Queue or Deque interfaces , both of which are implemented using LinkedList . In C #, there is a Queue class , but there is no built-in Deque. If you need important events to happen first, but otherwise everything happened in order, then select a priority queue. In C ++, this is the priority_queue , in Java it is the PriorityQueue . In C #, you need to implement it yourself.
Nonlinear structures - quick search.
If you create a stable group of elements, and basically perform an arbitrary search, then you should choose one of the nonlinear structures. Some of them store pairs of data, others contain separate data. Some of them are sorted in a useful way, others are ordered in a computer-friendly manner. If you try to create a list of all their combinations, you will have to write a separate article (or you can re-read the previous part).
Linked list - frequent changes while maintaining order
If you often change the middle of the container, and you only need to bypass the list sequentially, then use the linked list. In C ++, it is called list . In Java and C #, this is LinkedList . A linked list is a great container for cases where the data is just coming in and must be kept in order, or when you need to periodically sort and move items.
Conclusion
Choosing the right data structure can greatly affect the speed of the algorithms. Understanding the basic data structures, their advantages and disadvantages, will help you in using the most efficient structure for any task. I recommend that you end up exploring them in detail. A complete study of these data structures in college in the specialty "Computer Science" usually takes several weeks. I hope you understand the basic data structures and will be able to choose the right one without a long college degree.
This concludes the article. Thanks for reading.
Source: https://habr.com/ru/post/339656/
All Articles