Alice. How Yandex teaches artificial intelligence to talk to people
In the future, it seems to us, people will interact with devices using voice. Already, applications recognize the exact voice commands put into them by the developers, but with the development of artificial intelligence technologies they will learn to understand the meaning of arbitrary phrases and even keep up the conversation on any topic. Today we will tell Habr's readers how we are bringing this future closer by the example of Alice , the first voice assistant, who is not limited to a set of predetermined answers and uses neural networks for communication.

Despite the seeming simplicity, the voice assistant is one of the most large-scale technological projects of Yandex. From this post, you will learn what difficulties the developers of voice interfaces face, who actually writes answers for virtual assistants, and what Alice has in common with the artificial intelligence from the film “She”.
')
At the dawn of its existence, computers were mainly used in large scientific or defense enterprises. Only fiction writers then thought about voice control, but in reality, the operators loaded the programs and data using a piece of cardboard. Not the most convenient way: one mistake, and everything needs to start over.
Over the years, computers have become more accessible and are beginning to be used in smaller companies. Specialists manage them using text commands entered in the terminal. A good, reliable way - it is used in a professional environment to this day, but requires preparation. Therefore, when computers began to appear in the homes of ordinary users, engineers began to look for simpler ways of interaction between the machine and the person.
The concept of graphical user interface WIMP (Windows, Icons, Menus, Point-n-Click) is emerging in the Xerox laboratory - it has found mass use in products from other companies. Learning text commands to control your home computer was no longer necessary - they were replaced by gestures and mouse clicks. For its time, it was a real revolution. And now the world is approaching the next.
Now almost everyone has a smartphone in his pocket, with enough computing power to land the ship on the moon. The mouse and keyboard replaced the fingers, but with them we make all the same gestures and clicks. It is convenient to do, sitting on the couch, but not on the road or on the go. In the past, to interact with computer interfaces, man had to master the language of machines. We believe that now is the time to teach devices and applications to communicate in the language of the people. It was this idea that formed the basis of Alice’s voice assistant.
Alice can be asked [Where is nearby to drink coffee?], And not to dictate something like [coffee shop astronauts street]. Alice will look at Yandex and suggest the right place, and the question [Great, and how to get there?] Will give a link to the already constructed route in Yandex.Maps. She is able to distinguish exact factual questions from the desire to see the classic search results, rudeness from a polite request, the command to open a website from a desire to just chat.
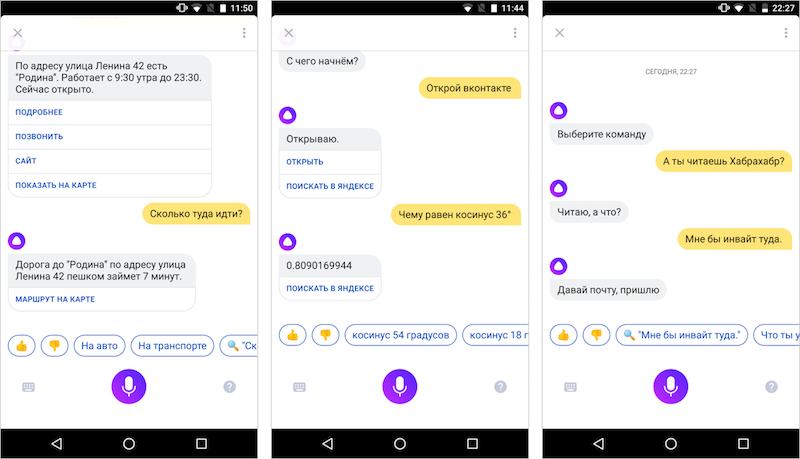
It may even seem that somewhere in the cloud a neural miracle network works, which alone solves any tasks. But in reality, any answer from Alice hides a whole chain of technological problems, which we have been learning to solve for 5 years. And we begin our excursion from the very first link - the ability to listen.
Hi Alisa
Artificial intelligence from science fiction can listen - people do not have to press special buttons to turn on the “recording mode”. And for this you need voice activation - the application must understand that the person is accessing it. This is not as easy as it may seem.
If you simply start recording and processing the entire incoming audio stream on the server, then very quickly discharge the device's battery and spend all mobile traffic. In our case, this is solved with the help of a special neural network that is trained solely on the recognition of key phrases (“Hello, Alice”, “Listen, Yandex” and some others). Support for a limited number of such phrases allows you to perform this work locally and without accessing the server.
If the network is trained to understand only a few phrases, you might think that it is quite simple and fast to do. But no. People utter phrases far from ideal conditions, but surrounded by completely unpredictable noise. And the voices are different. Therefore, to understand only one phrase requires thousands of training records.
Even a small local neural network consumes resources: you can not just take and start processing the entire stream from a microphone. Therefore, a less potent algorithm is applied at the forefront, which cheaply and quickly recognizes the event “speech began”. It includes the neural network key word recognition engine, which in turn launches the hardest part - speech recognition.
If thousands of examples are necessary for learning only one phrase, then you can imagine how difficult it is to train a neural network to recognize any words and phrases. For the same reason, recognition is performed in the cloud, where the audio stream is transmitted, and from where ready-made answers are returned. The accuracy of the answers depends on the quality of recognition. That is why the main challenge is to learn to recognize speech as well as a person does. By the way, people make mistakes too. It is believed that a person recognizes 96-98% of speech (WER metric). We managed to achieve an accuracy of 89-95%, which is not only comparable to the level of a live interlocutor, but also unique to the Russian language.
But even a speech ideally transformed into text will mean nothing if we cannot understand the meaning of what has been said.
What is the weather tomorrow in St. Petersburg?
If you want your application to display the weather forecast in response to a voice query [weather], then everything is simple - compare the recognized text with the word “weather” and if you get a match, output the answer. And this is a very primitive way to interact, because in real life people ask questions differently. A person may ask an assistant [What is the weather tomorrow in St. Petersburg?], And he should not be confused.
The first thing Alice does when she receives a question is that she recognizes the script. Send a search query and show a classic issue with 10 results? Search for one exact answer and immediately give it to the user? Take an action, for example, open a website? Or maybe just talk? It is incredibly difficult to teach the machine to accurately recognize scenarios of behavior. And any mistake here is unpleasant. Fortunately, we have all the power of the Yandex search engine, which every day encounters millions of queries, searches for millions of answers and learns to understand which ones are good and which are not. This is a huge knowledge base, on the basis of which you can train another neural network - one that would with high probability "understand" what a person wants. Mistakes, of course, are inevitable, but they are also committed by people.
Using machine learning, Alice "understands" that the phrase [What is the weather tomorrow in St. Petersburg?] Is a weather query (by the way, this is obviously a simple example for clarity). But what city are we talking about? On what date? This is where the extraction of Named Entity Recognition from user replicas begins. In our case, two such objects carry important information: Peter and Tomorrow. And Alice, who has search technologies behind her, “understands” that “Peter” is a synonym for “St. Petersburg”, and “tomorrow” is “current date + 1”.
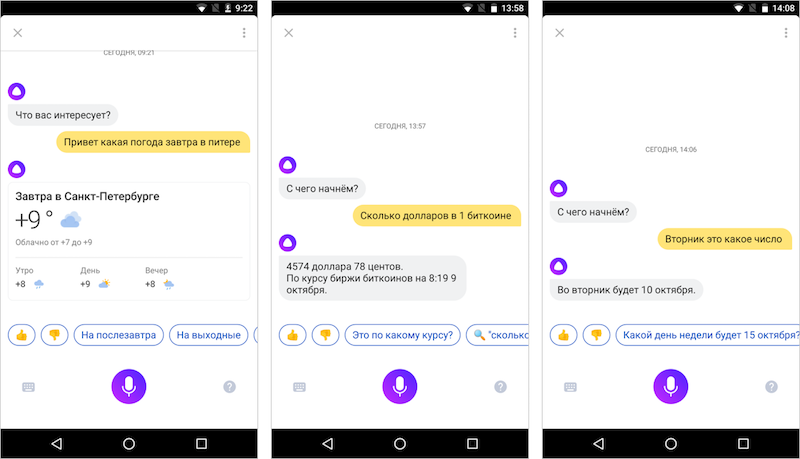
Natural language is not only the external form of our replicas, but also their coherence. In life, we do not exchange short phrases, but we conduct a dialogue — it is impossible if the context is not remembered. Alice remembers him - it helps her to deal with complex linguistic phenomena: for example, to cope with an ellipsis (to restore the missing words) or to allow coreference (to define an object by a pronoun). So, if you ask [Where is Elbrus?], And then specify [And what is its height?], Then the assistant will find the right answers in both cases. And if after asking [What is the weather today?] To ask [And tomorrow?], Alice will understand that this is a continuation of the dialogue about the weather.
And something else. An assistant must not only understand natural language, but also be able to speak it - as a person, not as a robot. For Alice, we will synthesize a voice, originally owned by dubbing actress Tatiana Shitova (the official voice of Scarlett Johansson in Russia). She voiced artificial intelligence in the film “She” , although you could remember her by the voice acting of the sorceress Jennifer in The Witcher. And we are talking about a rather deep synthesis using neural networks, and not about cutting ready-made phrases - it is impossible to record all their diversity in advance.
Above, we described the features of natural communication (unpredictable form of cues, missing words, pronouns, mistakes, noise, voice) with which you need to be able to work. But live communication has one more feature - we do not always require a particular answer or action from the interlocutor, sometimes we just want to talk. If the application sends such requests to the search, then all the magic will be destroyed. That is why popular voice assistants use a database of editorial responses to popular phrases and questions. But we went even further.
And chat?
We taught the machine to answer our questions, to conduct a dialogue in the context of certain scenarios and to solve user problems. This is good, but can it be made less soulless and endow with human properties: give it a name, teach her to talk about herself, keep up the conversation on free topics?
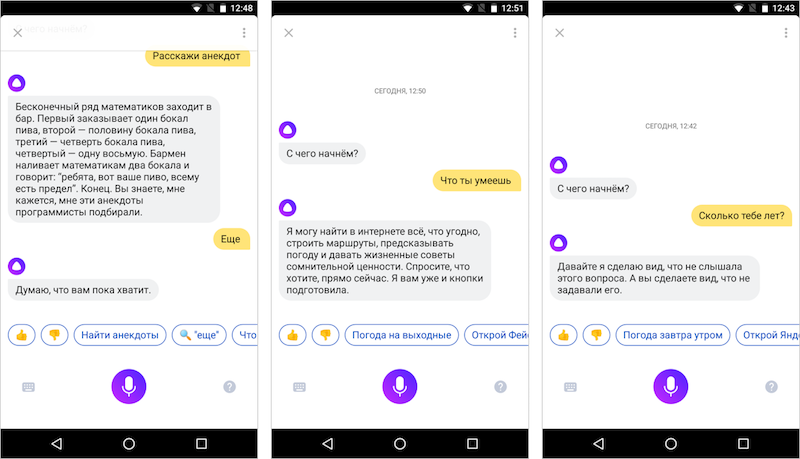
In the voice assistants industry, this task is accomplished with the help of editorial responses. A special team of authors takes hundreds of the most popular questions from users and writes several answers for each. Ideally, this should be done in the same style, so that the integral personality of the assistant can be formed from all the answers. For Alice, we also write the answers - but we have something else. Something special.
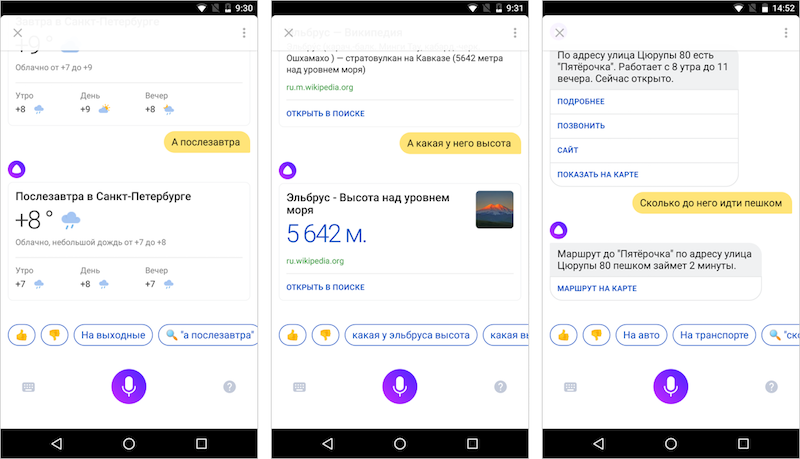
In addition to the top of popular questions, there is a long tail of low-frequency or even unique phrases for which it is impossible to prepare an answer in advance. You guessed it, with the help of which we solve this problem, right? Using another neural network model. Alice uses a neural network, trained on a huge database of texts from the Internet, books and films, to answer questions and replicas unknown to her. Connoisseurs of machine learning may be interested in what we started with a 3-layer neural network, and now we are experimenting with a huge 120-layer one. We will save the details for specialized posts, but here we say that the current version of Alice is trying to respond to arbitrary phrases with the help of a “neural net talker” —that is what we call it inside.

Alice learns from a huge number of various texts in which people and characters do not always behave politely. A neural network may not learn at all what we want to teach it.
Like any child, Alice cannot be taught not to be rude, protecting her from all manifestations of rudeness and aggression - that is, teaching the neural network on a “clean” base, where there are no rudeness, provocations and other unpleasant things that are often found in the real world. If Alice does not know about the existence of such expressions, she will respond to them thoughtlessly, with random phrases — for her they will remain unknown words. Let her know better what it is - and work out a certain position on these issues. If you know what a mat is, you can either swear in response, or say that you will not begin to talk with the swearing. And we model Alice's behavior so that she chooses the second option.
It so happens that Alice's remark itself is completely neutral, but in the context given by the user, the answer is no longer harmless. Once, even during the closed testing, we asked the user to find some places - a cafe or something like that. He said: "Find another one the same." And at that moment a bug occurred in Alice, and instead of launching the organization’s search script, she gave a rather bold answer - something like “look on the map”. And did not look for anything. The user was surprised at first, and then surprised us, praising Alice's behavior.
When Alice uses the “neural network talker,” a million different personalities can appear in her, as the neural network absorbed a little from the author of each replica from the training sample. Depending on the context, Alice can be polite or rude, cheerful, or depressive. We want the personal assistant to be a complete personality with a well-defined set of qualities. Here our editorial texts come to the rescue. Their peculiarity is that they were originally written on behalf of the person that we want to recreate in Alice. It turns out that you can continue to teach Alice on millions of lines of random texts, but she will respond with an eye to the pattern of behavior laid down in the editorial responses. And this is what we are already working on.
Alice became the first voice assistant known to us, who tries to maintain communication not only with the help of editorial answers, but also using a trained neural network. Of course, we are still very far from what is portrayed in modern fiction. Alice does not always accurately recognize the essence of the replica, which affects the accuracy of the answer. Therefore, we still have a lot of work.
We are planning to make Alice the most humanoid assistant in the world. Instill in her empathy and curiosity. To make it proactive is to teach you to set goals in a dialogue, take the initiative and involve the interlocutor in the conversation. Now we are both at the very beginning of the journey and at the forefront of the sciences studying this field. To move on, you have to move this edge.
You can talk to Alice in the Yandex application for Android and iOS, in the beta version for Windows, and soon in the Yandex Browser. We would be interested to discuss how you see the future of voice interfaces and scenarios for its use.
Despite the seeming simplicity, the voice assistant is one of the most large-scale technological projects of Yandex. From this post, you will learn what difficulties the developers of voice interfaces face, who actually writes answers for virtual assistants, and what Alice has in common with the artificial intelligence from the film “She”.
')
At the dawn of its existence, computers were mainly used in large scientific or defense enterprises. Only fiction writers then thought about voice control, but in reality, the operators loaded the programs and data using a piece of cardboard. Not the most convenient way: one mistake, and everything needs to start over.
Over the years, computers have become more accessible and are beginning to be used in smaller companies. Specialists manage them using text commands entered in the terminal. A good, reliable way - it is used in a professional environment to this day, but requires preparation. Therefore, when computers began to appear in the homes of ordinary users, engineers began to look for simpler ways of interaction between the machine and the person.
The concept of graphical user interface WIMP (Windows, Icons, Menus, Point-n-Click) is emerging in the Xerox laboratory - it has found mass use in products from other companies. Learning text commands to control your home computer was no longer necessary - they were replaced by gestures and mouse clicks. For its time, it was a real revolution. And now the world is approaching the next.
Now almost everyone has a smartphone in his pocket, with enough computing power to land the ship on the moon. The mouse and keyboard replaced the fingers, but with them we make all the same gestures and clicks. It is convenient to do, sitting on the couch, but not on the road or on the go. In the past, to interact with computer interfaces, man had to master the language of machines. We believe that now is the time to teach devices and applications to communicate in the language of the people. It was this idea that formed the basis of Alice’s voice assistant.
Alice can be asked [Where is nearby to drink coffee?], And not to dictate something like [coffee shop astronauts street]. Alice will look at Yandex and suggest the right place, and the question [Great, and how to get there?] Will give a link to the already constructed route in Yandex.Maps. She is able to distinguish exact factual questions from the desire to see the classic search results, rudeness from a polite request, the command to open a website from a desire to just chat.
It may even seem that somewhere in the cloud a neural miracle network works, which alone solves any tasks. But in reality, any answer from Alice hides a whole chain of technological problems, which we have been learning to solve for 5 years. And we begin our excursion from the very first link - the ability to listen.
Hi Alisa
Artificial intelligence from science fiction can listen - people do not have to press special buttons to turn on the “recording mode”. And for this you need voice activation - the application must understand that the person is accessing it. This is not as easy as it may seem.
If you simply start recording and processing the entire incoming audio stream on the server, then very quickly discharge the device's battery and spend all mobile traffic. In our case, this is solved with the help of a special neural network that is trained solely on the recognition of key phrases (“Hello, Alice”, “Listen, Yandex” and some others). Support for a limited number of such phrases allows you to perform this work locally and without accessing the server.
If the network is trained to understand only a few phrases, you might think that it is quite simple and fast to do. But no. People utter phrases far from ideal conditions, but surrounded by completely unpredictable noise. And the voices are different. Therefore, to understand only one phrase requires thousands of training records.
Even a small local neural network consumes resources: you can not just take and start processing the entire stream from a microphone. Therefore, a less potent algorithm is applied at the forefront, which cheaply and quickly recognizes the event “speech began”. It includes the neural network key word recognition engine, which in turn launches the hardest part - speech recognition.
If thousands of examples are necessary for learning only one phrase, then you can imagine how difficult it is to train a neural network to recognize any words and phrases. For the same reason, recognition is performed in the cloud, where the audio stream is transmitted, and from where ready-made answers are returned. The accuracy of the answers depends on the quality of recognition. That is why the main challenge is to learn to recognize speech as well as a person does. By the way, people make mistakes too. It is believed that a person recognizes 96-98% of speech (WER metric). We managed to achieve an accuracy of 89-95%, which is not only comparable to the level of a live interlocutor, but also unique to the Russian language.
But even a speech ideally transformed into text will mean nothing if we cannot understand the meaning of what has been said.
What is the weather tomorrow in St. Petersburg?
If you want your application to display the weather forecast in response to a voice query [weather], then everything is simple - compare the recognized text with the word “weather” and if you get a match, output the answer. And this is a very primitive way to interact, because in real life people ask questions differently. A person may ask an assistant [What is the weather tomorrow in St. Petersburg?], And he should not be confused.
The first thing Alice does when she receives a question is that she recognizes the script. Send a search query and show a classic issue with 10 results? Search for one exact answer and immediately give it to the user? Take an action, for example, open a website? Or maybe just talk? It is incredibly difficult to teach the machine to accurately recognize scenarios of behavior. And any mistake here is unpleasant. Fortunately, we have all the power of the Yandex search engine, which every day encounters millions of queries, searches for millions of answers and learns to understand which ones are good and which are not. This is a huge knowledge base, on the basis of which you can train another neural network - one that would with high probability "understand" what a person wants. Mistakes, of course, are inevitable, but they are also committed by people.
Using machine learning, Alice "understands" that the phrase [What is the weather tomorrow in St. Petersburg?] Is a weather query (by the way, this is obviously a simple example for clarity). But what city are we talking about? On what date? This is where the extraction of Named Entity Recognition from user replicas begins. In our case, two such objects carry important information: Peter and Tomorrow. And Alice, who has search technologies behind her, “understands” that “Peter” is a synonym for “St. Petersburg”, and “tomorrow” is “current date + 1”.
Natural language is not only the external form of our replicas, but also their coherence. In life, we do not exchange short phrases, but we conduct a dialogue — it is impossible if the context is not remembered. Alice remembers him - it helps her to deal with complex linguistic phenomena: for example, to cope with an ellipsis (to restore the missing words) or to allow coreference (to define an object by a pronoun). So, if you ask [Where is Elbrus?], And then specify [And what is its height?], Then the assistant will find the right answers in both cases. And if after asking [What is the weather today?] To ask [And tomorrow?], Alice will understand that this is a continuation of the dialogue about the weather.
And something else. An assistant must not only understand natural language, but also be able to speak it - as a person, not as a robot. For Alice, we will synthesize a voice, originally owned by dubbing actress Tatiana Shitova (the official voice of Scarlett Johansson in Russia). She voiced artificial intelligence in the film “She” , although you could remember her by the voice acting of the sorceress Jennifer in The Witcher. And we are talking about a rather deep synthesis using neural networks, and not about cutting ready-made phrases - it is impossible to record all their diversity in advance.
Above, we described the features of natural communication (unpredictable form of cues, missing words, pronouns, mistakes, noise, voice) with which you need to be able to work. But live communication has one more feature - we do not always require a particular answer or action from the interlocutor, sometimes we just want to talk. If the application sends such requests to the search, then all the magic will be destroyed. That is why popular voice assistants use a database of editorial responses to popular phrases and questions. But we went even further.
And chat?
We taught the machine to answer our questions, to conduct a dialogue in the context of certain scenarios and to solve user problems. This is good, but can it be made less soulless and endow with human properties: give it a name, teach her to talk about herself, keep up the conversation on free topics?
In the voice assistants industry, this task is accomplished with the help of editorial responses. A special team of authors takes hundreds of the most popular questions from users and writes several answers for each. Ideally, this should be done in the same style, so that the integral personality of the assistant can be formed from all the answers. For Alice, we also write the answers - but we have something else. Something special.
In addition to the top of popular questions, there is a long tail of low-frequency or even unique phrases for which it is impossible to prepare an answer in advance. You guessed it, with the help of which we solve this problem, right? Using another neural network model. Alice uses a neural network, trained on a huge database of texts from the Internet, books and films, to answer questions and replicas unknown to her. Connoisseurs of machine learning may be interested in what we started with a 3-layer neural network, and now we are experimenting with a huge 120-layer one. We will save the details for specialized posts, but here we say that the current version of Alice is trying to respond to arbitrary phrases with the help of a “neural net talker” —that is what we call it inside.
Alice learns from a huge number of various texts in which people and characters do not always behave politely. A neural network may not learn at all what we want to teach it.
- Order me a sandwich.
- You will manage.
Like any child, Alice cannot be taught not to be rude, protecting her from all manifestations of rudeness and aggression - that is, teaching the neural network on a “clean” base, where there are no rudeness, provocations and other unpleasant things that are often found in the real world. If Alice does not know about the existence of such expressions, she will respond to them thoughtlessly, with random phrases — for her they will remain unknown words. Let her know better what it is - and work out a certain position on these issues. If you know what a mat is, you can either swear in response, or say that you will not begin to talk with the swearing. And we model Alice's behavior so that she chooses the second option.
It so happens that Alice's remark itself is completely neutral, but in the context given by the user, the answer is no longer harmless. Once, even during the closed testing, we asked the user to find some places - a cafe or something like that. He said: "Find another one the same." And at that moment a bug occurred in Alice, and instead of launching the organization’s search script, she gave a rather bold answer - something like “look on the map”. And did not look for anything. The user was surprised at first, and then surprised us, praising Alice's behavior.
When Alice uses the “neural network talker,” a million different personalities can appear in her, as the neural network absorbed a little from the author of each replica from the training sample. Depending on the context, Alice can be polite or rude, cheerful, or depressive. We want the personal assistant to be a complete personality with a well-defined set of qualities. Here our editorial texts come to the rescue. Their peculiarity is that they were originally written on behalf of the person that we want to recreate in Alice. It turns out that you can continue to teach Alice on millions of lines of random texts, but she will respond with an eye to the pattern of behavior laid down in the editorial responses. And this is what we are already working on.
Alice became the first voice assistant known to us, who tries to maintain communication not only with the help of editorial answers, but also using a trained neural network. Of course, we are still very far from what is portrayed in modern fiction. Alice does not always accurately recognize the essence of the replica, which affects the accuracy of the answer. Therefore, we still have a lot of work.
We are planning to make Alice the most humanoid assistant in the world. Instill in her empathy and curiosity. To make it proactive is to teach you to set goals in a dialogue, take the initiative and involve the interlocutor in the conversation. Now we are both at the very beginning of the journey and at the forefront of the sciences studying this field. To move on, you have to move this edge.
You can talk to Alice in the Yandex application for Android and iOS, in the beta version for Windows, and soon in the Yandex Browser. We would be interested to discuss how you see the future of voice interfaces and scenarios for its use.
Source: https://habr.com/ru/post/339638/
All Articles