Aftertaste from Kotlin, part 3. Korutiny - we divide the processor time

Java allows you to write serial, parallel and asynchronous code. Asynchronous is when a callback is registered that will start after some event (for example, the file is read). This avoids blocking the stream, but breaks the execution sequence, so that such code is written to java rather when there are no other options. Kotlin gives a solution - corutines , with them the asynchronous code looks almost the same as sequential.
There are few articles on Korutin. There are even fewer specific examples showing their advantages.
')
I have found:
- Getting rid of callback hell . Actual for UI
- Like the concept of channels and actors . They are not new, it is possible without them, but for event systems should be very well suited
- Advice from Roman Elizarov : "Korutin are needed for asynchronous tasks that expect something most of the time"
The latter is interesting - most enterprise applications are always waiting for something: the database, other applications, and occasionally the file needs to be read. And all this can be completely asynchronous, which means that the whole application can be translated into asynchronous request processing.
So, let's see how the korutiny behave under load.
IO vs NIO
Under NIO there is a ready strapping for corutin . Write the code:
suspend fun readFileAsync(): String { val channel = AsynchronousFileChannel.open(filePath) val bytes = ByteArray(size) val byteBuffer = ByteBuffer.wrap(bytes) channel.aRead(byteBuffer, 0L) /*(1)*/ /*(2)*/ channel.close() return bytes.toString(Charset.forName("UTF-8")) } fun readFileSync() = file.inputStream().use { it.readBytes(size).toString(Charset.forName("UTF-8")) } How it works
I will not focus on the syntax, for this there is a short guide . The bottom line is that in line (1) the method from NIO is called, in which a callback is registered, which will continue execution at point (2). A good compiler saves local method variables and restores them to continue the program. Between (1) and (2), while the file is being read from the disk, the stream is free and can, for example, start reading the second file. In the case of blocking for the second reading of the file, until the first reading was completed, one more stream would have to be created and it would also be blocked.
Measure performance
Take JMH and measure a single call. Bottom line: for HDD, the difference is within the margin of error, for SSD NIO in coroutine, by 7.5% ± 0.01% faster. The difference is small, but this is not surprising - everything depends on the speed of the disk. But in the case of coruntine, the threads are not blocked for the time of reading and can do other work.
Let's see how much more work can be done while we read a given amount of data from the disk. To do this, in ForkJoinPool we will throw the IO and CPU tasks in a certain ratio. When we have completed 400 IO tasks, let's calculate how many purely CPU tasks have been worked out. Benchmark
| Elapsed time (ms) | How many CPU tasks managed to perform | |||
|---|---|---|---|---|
| Share IO tasks | Sync | Async | Sync | Async |
| 3/4 | 117 | 116 | 497 | 584 (+ 17%) |
| 1/2 | 128 | 127 | 1522 | 1652 (+ 8%) |
| 1/4 | 163 | 164 | 4958 | 4960 |
| 1/8 | 230 | 238 (+ 3%) | 11381 | 11495 (+ 1%) |
There is a difference. Measured on the HDD, in which a single reading almost did not differ. Separately, I want to note the last line: await generates a relatively large number of objects, which additionally loads GC, this is noticeable against the background of our CPU task, which creates 50 objects. Measured separately: the more task creates objects, the smaller the difference between Future and await until equality.
SQL
There was one library that can work with the database without locks. It is written in scala and can work only with MySql and Postgres. If anyone knows other libraries - write in the comments.
Await for Future from scala:
suspend fun <T> Future<T>.await(): T = suspendCancellableCoroutine { cont: CancellableContinuation<T> -> onComplete({ if (it.isSuccess) { cont.resume(it.get()) } else { cont.resumeWithException(it.failed().get()) } }, ExecutionContext.fromExecutor(ForkJoinPool.commonPool())) } I made a couple of tablets in Postgres, especially without indexes, so that the timing was noticeable, I launched the database in the docker, issuing 4 logical processors. onnectionPool limited to 4. Each request to the application made three consecutive calls to the database.
Spring makes it quite simple to make an asynchronous http server, for this it is enough to return the DeferredResult instead of the MyClasss from the controller method, and only then fill in the DeferredResult (on another thread). For convenience, I wrote a small wrapper (indicated by numbers with the actual order of execution):
@GetMapping("/async") fun async(): DeferredResult<Response> = asyncResponse { (4) //code that produce Response } fun <R> asyncResponse(body: suspend CoroutineScope.() -> R): DeferredResult<R> { (1) val result = DeferredResult<R>() // (2) launch(CommonPool) { // try { (5) result.setResult(body.invoke(this)) } catch (e: Exception) { (5') result.setErrorResult(e) } } (3) return result // DeferredResult, } A separate problem was to decide how to wait for a connection from the pool for sync and async options. For sync is set in ms, and for async - in pieces. I decided that the average request to the database was ~ 30ms, so the time was divided into 30 - I got the pieces (it turned out I was wrong about a third).
The application is launched by issuing one logical processor. On another machine, put the Yandex tank and shot the application. To my surprise, there was no difference ... up to 50 rps (left async , right sync ).
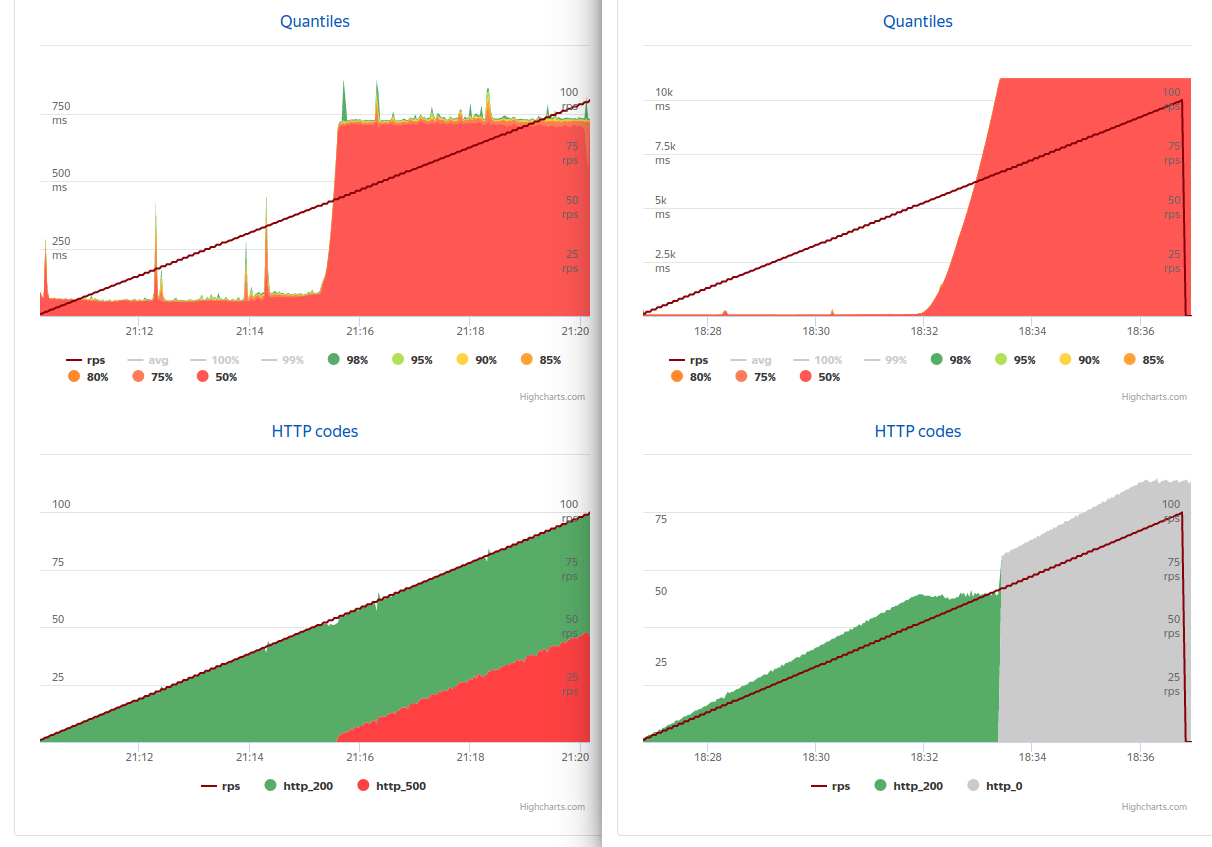
After 50 rps, 4 connections ceased to be enough (the average timing at this point was 80 rps) and the synchronous version reached 66 seconds for 11 seconds and died — only timeout responded to any request (even if the load was removed altogether), and asynchronous to 54 rps went to 730ms and began to process exactly as many requests as the base allowed, for all the rest - 500, while errors were almost always discarded instantly.
When you run an application with eight logical processors, the picture has changed a bit ( async on the left, sync on the right)
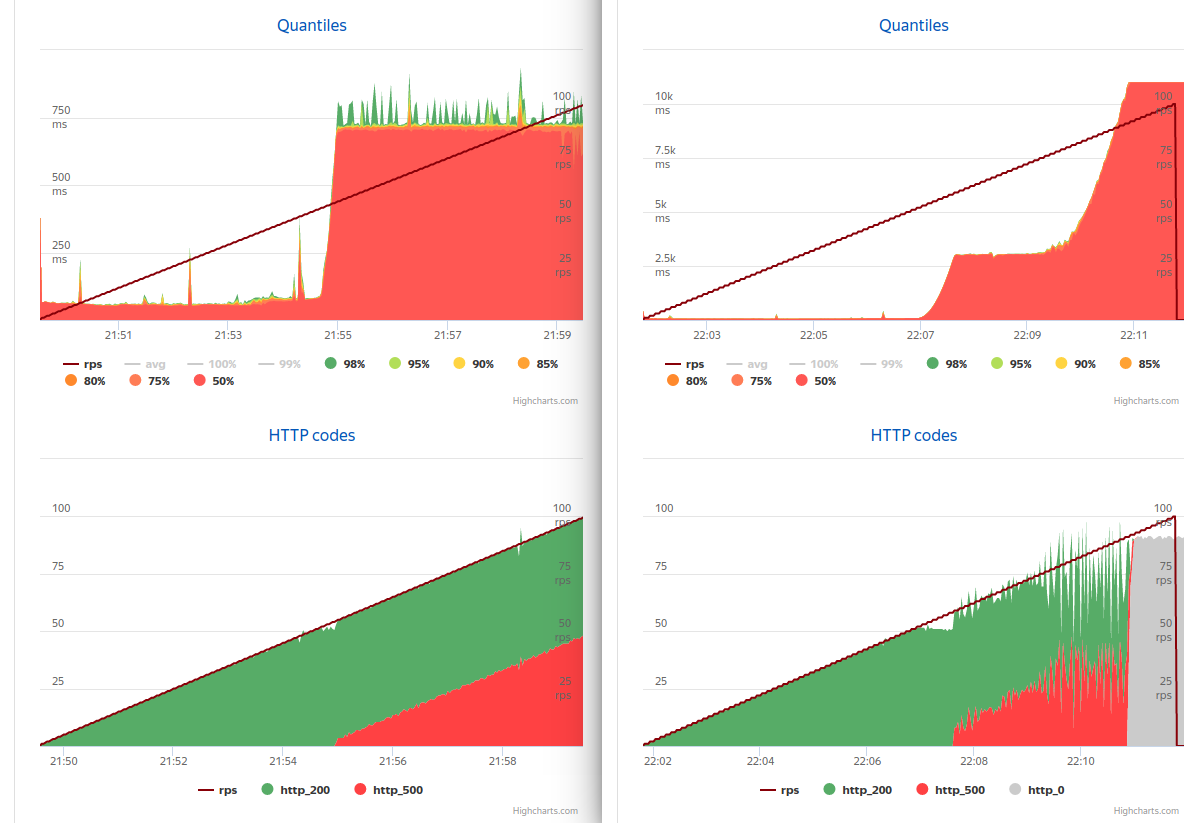
The synchronous version from 60 to 80rps answered for 3 seconds, discarding unnecessary requests, and completely stopped responding only to 91rps.
Why did this happen? Tomcat creates up to 200 (default) threads to handle incoming requests. When requests come in more than can be processed, they are all created and after a while all are blocked. In this case, each request should receive a connection 3 times and waits every second in a second. In the case of the asynchronous option, the request does not wait for any time, but looks at how many more people want this resource and sends an error if there are too many people interested. In my case, the limit was 33 with 4 connections, which is probably a bit too much. By reducing this number, we get a more acceptable response rate during server overloads.
HTTP
Smooth failure is good, but I wonder if it is possible to get a performance boost in regular situations.
This time the application went over http to the stub, the stub responded with a delay (from 1.5 ms). Made two options: 100 consecutive and 100 parallel (batch) requests for a stub. Measured with JMH in 1 and 6 threads (imitated different loads).
| Sequentially (avg ms) | In parallel (avg ms) | |||||
|---|---|---|---|---|---|---|
| Sync | Async | Δ | Sync | Async | Δ | |
| 1core / 1 jmh thread | 160.3 ± 1.8 | 154.1 ± 1.0 | 4.0% ± 1.7% | 163.9 ± 2.4 | 10.7 ± 0.3 | 1438.3% ± 4.6% |
| 2core / 1 jmh thread | 159.3 ± 1.0 | 156.3 ± 0.7 | 1.9% ± 1.1% | 57.6 ± 0.5 | 15.4 ± 0.2 | 274.0% ± 1.9% |
| 4core / 1 jmh thread | 159.0 ± 1.1 | 157.4 ± 1.3 | 1.0% ± 1.5% | 25.7 ± 0.2 | 14.8 ± 0.3 | 74.3% ± 2.8% |
| 1core / 6 jmh thread | 146.8 ± 2.5 | 146.3 ± 2.5 | 0.4% ± 3.4% | 984.8 ± 34.2 | 79.3 ± 3.7 | 1141.6% ± 5.1% |
| 2core / 6 jmh thread | 151.3 ± 1.6 | 143.8 ± 1.9 | 5.2% ± 2.3% | 343.9 ± 17.2 | 86.7 ± 3.7 | 296.5% ± 6.3% |
| 4core / 6 jmh thread | 152.3 ± 1.5 | 144.7 ± 1.2 | 5.2% ± 1.8% | 135.0 ± 3.0 | 81.7 ± 4.8 | 65.2% ± 8.1% |
Even with successive requests, we get a gain, well, with a batch ... Of course, if we add processors, the picture for the synchronous version will be much better. So, having increased the resources by 4 times, we will get the increase in the synchronous variant by 6.5 times, but we will not reach the speed async. The speed of async does not depend on the number of processors.
About bad
- As I already mentioned, doing very small tasks in async is not beneficial. However, I do not think that this is necessary.
- It is necessary to monitor the blocking code. Probably, in this case, you should have a separate threadPool for their execution.
- ThreadLocal can be forgotten. Korutina is restored in a random stream from the pool provided (in the case of NIO, you cannot even specify it ...). RequestScope, I think, will also stop working (did not try). Nevertheless, there is a CoroutineContext to which something can be tied, but it will have to be communicated explicitly anyway.
- The Java world is used to blocking, so non-blocking libraries are LITTLE.
Aftertaste
Korutiny can and should be used. They can write applications that require fewer processors to run at the same speed. My impression is that in most cases 1-2 cores will suffice.
Yes, also a gift in the form of resiliency.
I hope that the best practices will gradually appear, since now it’s better to look at the patterns for working with channels in Go, async / await - in C #, yield - C # and python.
PS:
source code
Kotlin aftertaste, part 1
Kotlin aftertaste, part 2
Source: https://habr.com/ru/post/339618/
All Articles