How to run docker-voting on Swarm, Kubernetes and Nomad
Tl; DR
In this article, we will deploy the Docker application, voting on Swarm, Kubernetes and Nomad from Hashicorp. I hope you get the same pleasure from reading this article as I got when experimenting with all of this.
If you are working with technology, then it is necessary to be inquisitive. This is necessary in order to constantly learn and be aware of what is happening in the field. Painfully everything changes quickly.
Container orchestration is such a hot topic of discussion that even if you have a favorite instrument, it’s still interesting to see how others work and learn something new about them.
I used the application to vote in previous articles. The application works on microservice architecture and consists of 5 services.
')
As we see in the repository on github, there are several compose files in the application: https://github.com/dockersamples/example-voting-app
Docker-stack.yml - application presentation ready for use in production. Here is the file itself:
In general, there are 6 services in this file, and only 5 in the application architecture. The additional service is the visualizer, an excellent tool that provides an interface that shows where the services are deployed.
Docker Swarm is a tool for managing and creating Docker containers. With Swarm, administrators and developers can create and manage a cluster of nodes as a single virtual system.
A Swarm cluster consists of several nodes, some work as managers, others as performers:
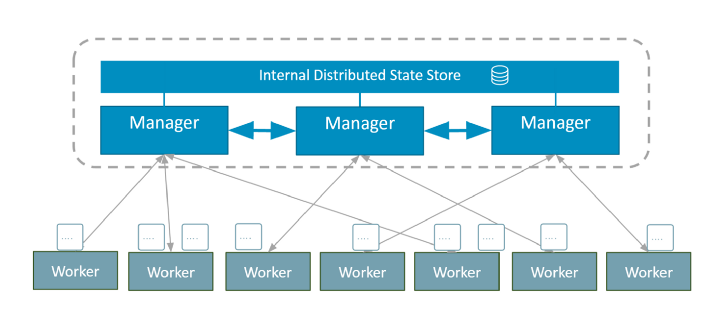
Managers share internal distributed storage to maintain a consistent cluster state. This is provided by the Raft logs.
In Swarm, services determine how applications should be deployed, and how they should work in containers.
If you have not yet installed Docker, you can download Docker CE (Community Edition) for your OS.
Once the Docker is installed, only one team separates us from the working Swarm.
This is all that is required for a Swarm cluster. Although this is a cluster with one node, it is still a cluster with all related processes.
Among the compose files available in the application repository on github, we need docker-stack.yml in order to deploy the application through Swarm.
Since the stack is running on the docker for poppy, I have access to the application right away from the local machine. You can select cats or dogs using the voting interface (port 5000), and see the results on port 5001.
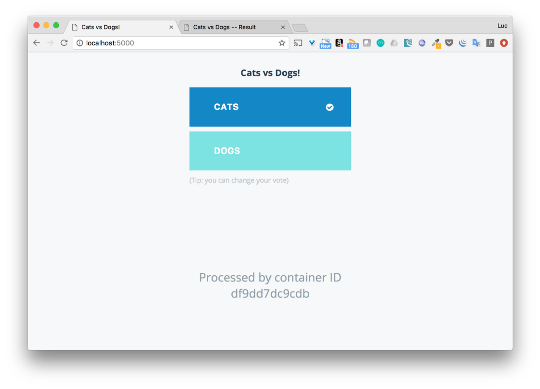
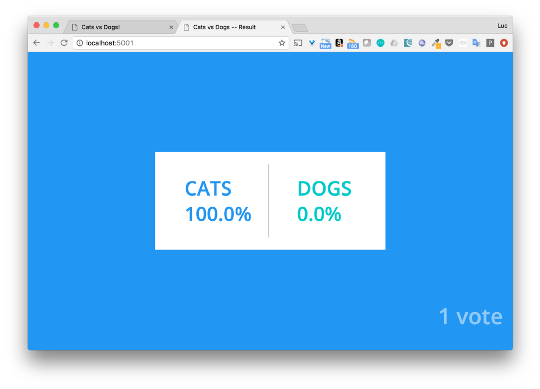
I’ll not go into details right now, I just wanted to show how easy it is to deploy an application using Swarm.
If you need a more detailed analysis of how to deploy the application through Swarm with several nodes, then you can read this article .
Kubernetes is an open source platform for automating the deployment, scaling and management of containerized applications.
A Kubernetes cluster consists of one or more Masters and nodes.
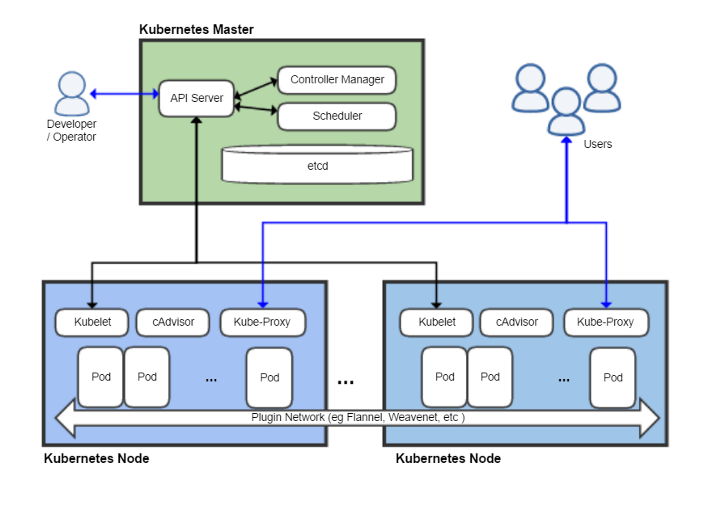
To enter commands, use kubectl CLI. Below we look at several examples of its use.
In order to understand how applications are deployed, you need to be aware of several Kubernetes high-level objects:
In this part we will use Deployment and Service for each of the application services.
Kubectl is the command line for deploying and managing applications in Kubernetes
For installation, use the official documentation (https://kubernetes.io/docs/tasks/tools/install-kubectl/). For example, to install on a Mac, enter the following commands:
Minicube is a comprehensive Kubenetes setup. It creates local VMs and starts a cluster of nodes, on which all Kubernetes processes run. Undoubtedly, this is not the tool that should be used to install a production cluster, but it is really convenient to use it for development and testing.
Once Minicube is installed, only one command is needed to install a cluster with one node.
In Kubernetes, containers are started via ReplicaSet , which is managed by Deployment .
Below is an example .yml file describing Deployment . ReplicaSet provides the launch of 2 Nginx replicas.
To create deployment you need to use CLI kubectl.
To create an application consisting of microservices, you need to create a deployment file for each service. You can do it manually, or you can use Kompose .
Kompose is a tool that converts Docker compose files into file descriptors used by Kubernetes. With this service it turns out more convenient, and it speeds up the migration process.
Note:
Kompose is optional, you can write everything manually, but it significantly speeds up the deployment process
Before running docker-stack.yml in Kompose, we change it a bit and remove the deployment key of each service. This key is not perceived, and because of it errors may occur when generating file descriptors. You can also delete information about networks. In Kompose, we will give away a new file, which we call docker-stack-k8s.yml .
From the docker-stack-k8s.yml file, we generate handles for the application using the following command:
We see that for each service a deployment and service file is created.
We received only one warning. It is connected to the visualizer , because the Docker's socket cannot be connected. We will not try to start this service, but focus on the rest.
Through kubectl we will create all the components specified in the descriptor file. Indicate that the files are located in the current folder.
Note: since we left the modified compose file in the current folder, we received an error, because you cannot parse it. But this error can be ignored without any risk.
With the help of these commands you can see the created Services and Deployments .
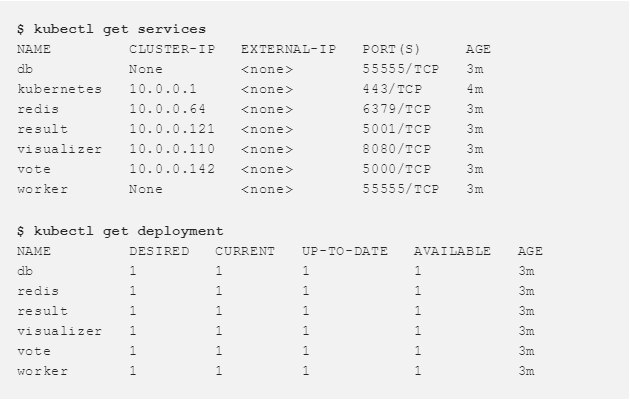
To gain access to the interface vote and result, you need to slightly change the services created for them.
Here is the generated voice descriptor:
We will change the type of service and replace ClusterIP with NodePort . ClusterIP makes the service available internally, and NodePort allows publishing the port on each node of the cluster and makes it available to the whole world. Let's do the same for result , because we want both to vote and to result was access from outside.
As soon as changes are made to both services ( vote and result ), you can re-create them.
Now we will get the details of the vote and result services and get the ports that they provide.

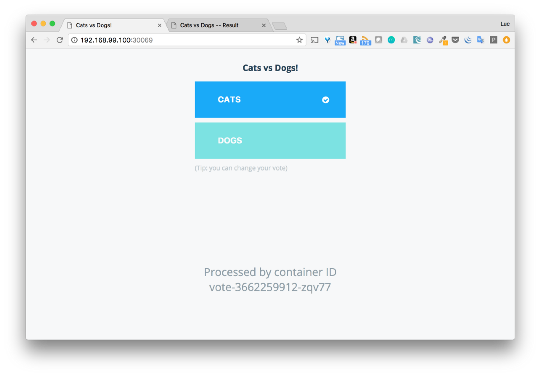
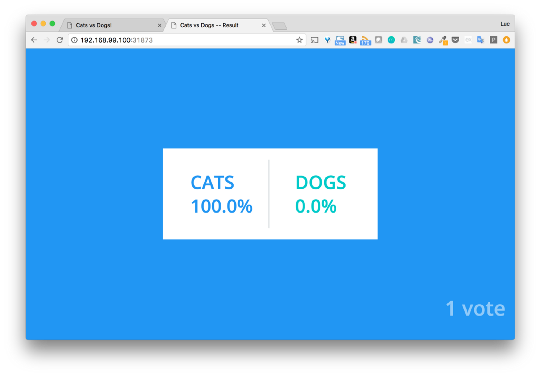
The vote is available on port 30069, and the result is 31873. Now we vote and see the results.
After we dealt with the basic components of Kubernetes, we were able to easily deploy the application. And Kompose helped us a lot.
Nomad is a tool for managing a cluster of machines and running an application on them. It abstracts the machines and the point of the application and lets users say what they want to run. And Nomad is responsible for where it will be launched and how.
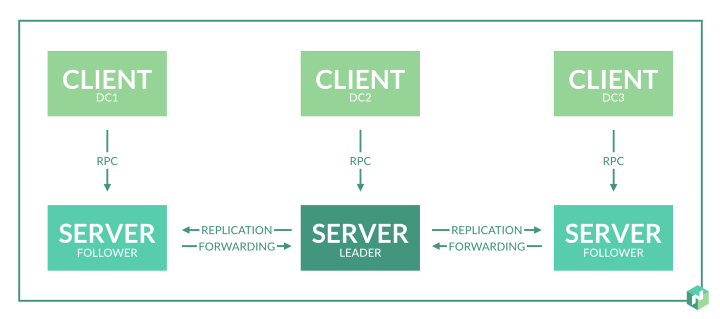
The Nomad cluster consists of agents (agents) that can operate in server (server) mode or client (client) mode.
Several types of tasks can be run on a Nomad cluster.
In order to deploy the application you need to understand the basic concepts of Nomad:
In this example, we will run the application on the Docker host, created using the Docker Machine. The local IP is 192.168.1.100. First, run Consul, which is used to discover and register services. We will launch Nomad and deploy the application as Job in Nomad.
For detecting and registering services, a tool is recommended, for example, Consul, which will not work as Job in Nomad. Consul can be downloaded here .
This command starts the Consul server locally:
Let's take a closer look at the options used:
Nomad can be downloaded from this link .
We downloaded Nomad and now we can run the Agent with the following settings.
The agent will work both as a server and as a client. We point out that bind_addr should work with any interface so that tasks can be received from the outside world. Launch the Nomad Agent with the following settings:
Note: By default, Nomad connects to the local Consul instance.
We have just installed a cluster with one node. Here is the information on the unique participant:
To deploy an application using Swarm, you can use the compose file right away. To deploy via Kubernetes, we need descriptors from the same compose files. How does all this happen through Nomad?
Firstly, there is no tool similar to Kompose for Hashicorp, so that it can simplify the migration of compose to Nomad (a good idea for an OpenSource project, by the way). Files describing Jobs , groups , tasks must be written manually.
We will analyze this in more detail when we describe Jobs for the Redis and Vote services. For other services, it will look about the same.
This file defines the part of Redis in the application:
Let's look at what is written here:
In order to check whether the Job will run correctly, use the plan command:
It seems everything works. Now deploy the task with this job:
We see that the placement is created. Check its status:
The container is running correctly. Check the Consul DNS server and make sure that the service also registers correctly:
Task was placed on IP 172.17.0.2, and its port is 6379, as we indicated.
Define a job for the vote service. Use the following file:
But there are several differences from the file that we used for Redis:
In this case, to obtain the IP container with redis, the container with vote must use the Consul DNS server. DNS query from the container is executed via the Docker bridge (172.17.0.1). dns_search_domains specifies that Service X is registered as X.service.dc1.consul within Consul
We can do the same setup for other services: worker, postgres and result.
When all the Jobs are running, you can check their status and make sure everything works.
We can also view this through the Consul interface.
By IP nodes (in our case 192.168.1.100), we get access to interfaces with a vote and result .
Here is such a wonderful application from the point of view of the demonstration. I was wondering if it could be deployed without changes in the code with the help of some orchestrator. And yes, it is possible, even without some special dances with a tambourine.
I hope this article will help you understand the basics of Swarm, Kubernetes and Nomad. It would also be interesting to know what you are launching at Docker and how you use the orchestrator.
In this article, we will deploy the Docker application, voting on Swarm, Kubernetes and Nomad from Hashicorp. I hope you get the same pleasure from reading this article as I got when experimenting with all of this.
If you are working with technology, then it is necessary to be inquisitive. This is necessary in order to constantly learn and be aware of what is happening in the field. Painfully everything changes quickly.
Container orchestration is such a hot topic of discussion that even if you have a favorite instrument, it’s still interesting to see how others work and learn something new about them.
Application for voting
I used the application to vote in previous articles. The application works on microservice architecture and consists of 5 services.
')
- Vote: a frontend that allows the user to choose between a dog and a cat
- Redis: database where votes are stored
- Worker: a service that collects radish voices and stores results in a Postgres database.
- Db: Postgres database that stores voting results.
- Result: frontend shows voting results
As we see in the repository on github, there are several compose files in the application: https://github.com/dockersamples/example-voting-app
Docker-stack.yml - application presentation ready for use in production. Here is the file itself:
version: "3" services: redis: image: redis:alpine ports: - "6379" networks: - frontend deploy: replicas: 1 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure db: image: postgres:9.4 volumes: - db-data:/var/lib/postgresql/data networks: - backend deploy: placement: constraints: [node.role == manager] vote: image: dockersamples/examplevotingapp_vote:before ports: - 5000:80 networks: - frontend depends_on: - redis deploy: replicas: 2 update_config: parallelism: 2 restart_policy: condition: on-failure result: image: dockersamples/examplevotingapp_result:before ports: - 5001:80 networks: - backend depends_on: - db deploy: replicas: 1 update_config: parallelism: 2 delay: 10s restart_policy: condition: on-failure worker: image: dockersamples/examplevotingapp_worker networks: - frontend - backend deploy: mode: replicated replicas: 1 labels: [APP=VOTING] restart_policy: condition: on-failure delay: 10s max_attempts: 3 window: 120s placement: constraints: [node.role == manager] visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" deploy: placement: constraints: [node.role == manager] networks: frontend: backend: volumes: db-data: In general, there are 6 services in this file, and only 5 in the application architecture. The additional service is the visualizer, an excellent tool that provides an interface that shows where the services are deployed.
Docker swarm
Docker Swarm is a tool for managing and creating Docker containers. With Swarm, administrators and developers can create and manage a cluster of nodes as a single virtual system.
Swarm components
A Swarm cluster consists of several nodes, some work as managers, others as performers:
- Node managers are responsible for the internal state of the cluster.
- Implementing nodes perform tasks (= launch containers)
Managers share internal distributed storage to maintain a consistent cluster state. This is provided by the Raft logs.
In Swarm, services determine how applications should be deployed, and how they should work in containers.
Docker installation
If you have not yet installed Docker, you can download Docker CE (Community Edition) for your OS.
Create Swarm
Once the Docker is installed, only one team separates us from the working Swarm.
$ docker swarm initThis is all that is required for a Swarm cluster. Although this is a cluster with one node, it is still a cluster with all related processes.
Deploying the application
Among the compose files available in the application repository on github, we need docker-stack.yml in order to deploy the application through Swarm.
$ docker stack deploy -c docker-stack.yml app Creating network app_backend Creating network app_default Creating network app_frontend Creating service app_visualizer Creating service app_redis Creating service app_db Creating service app_vote Creating service app_result Creating service app_worker Since the stack is running on the docker for poppy, I have access to the application right away from the local machine. You can select cats or dogs using the voting interface (port 5000), and see the results on port 5001.
I’ll not go into details right now, I just wanted to show how easy it is to deploy an application using Swarm.
If you need a more detailed analysis of how to deploy the application through Swarm with several nodes, then you can read this article .
Kubernetes
Kubernetes is an open source platform for automating the deployment, scaling and management of containerized applications.
Kubernetes concept
A Kubernetes cluster consists of one or more Masters and nodes.
- The master is responsible for managing the cluster (managing the state of the cluster, scheduling tasks, responding to an event in the cluster, etc.)
- Nodes (they used to be called minions. Yes, yes, as in the Despicable Me cartoon) provide runtime to launch the application container (via Pods)
To enter commands, use kubectl CLI. Below we look at several examples of its use.
In order to understand how applications are deployed, you need to be aware of several Kubernetes high-level objects:
- Pod is the smallest unit that can be deployed on a node. This is a group of containers that should work together. But quite often Pod contains only one container.
- ReplicaSet provides the work of a specific number of replicas pod.
- Deployment manages ReplicaSet and allows rolling updates, blue / green deploy, testing, etc.
- Service defines a logical set of pods and a policy for accessing them.
In this part we will use Deployment and Service for each of the application services.
Install kubectl
Kubectl is the command line for deploying and managing applications in Kubernetes
For installation, use the official documentation (https://kubernetes.io/docs/tasks/tools/install-kubectl/). For example, to install on a Mac, enter the following commands:
$ curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/darwin/amd64/kubectl
$ chmod +x ./kubectl
$ sudo mv ./kubectl /usr/local/bin/kubectlInstall minicube
Minicube is a comprehensive Kubenetes setup. It creates local VMs and starts a cluster of nodes, on which all Kubernetes processes run. Undoubtedly, this is not the tool that should be used to install a production cluster, but it is really convenient to use it for development and testing.
Once Minicube is installed, only one command is needed to install a cluster with one node.
$ minikube start
Starting local Kubernetes v1.7.0 cluster…
Starting VM…
Downloading Minikube ISO
97.80 MB / 97.80 MB [==============================================] 100.00% 0s
Getting VM IP address…
Moving files into cluster…
Setting up certs…
Starting cluster components…
Connecting to cluster…
Setting up kubeconfig…
Kubectl is now configured to use the cluster.Kubernetes Descriptor
In Kubernetes, containers are started via ReplicaSet , which is managed by Deployment .
Below is an example .yml file describing Deployment . ReplicaSet provides the launch of 2 Nginx replicas.
// nginx-deployment.yml apiVersion: apps/v1beta1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 2 # tells deployment to run 2 pods matching the template template: # create pods using pod definition in this template metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 To create deployment you need to use CLI kubectl.
To create an application consisting of microservices, you need to create a deployment file for each service. You can do it manually, or you can use Kompose .
Using Kompose to create deployments and services
Kompose is a tool that converts Docker compose files into file descriptors used by Kubernetes. With this service it turns out more convenient, and it speeds up the migration process.
Note:
Kompose is optional, you can write everything manually, but it significantly speeds up the deployment process
- Kompose does not take into account all options used in the Docker Compose file
- Kompose can be installed on Linux or Mac using the following commands:
# Linux
$ curl -L https://github.com/kubernetes/kompose/releases/download/v1.0.0/kompose-linux-amd64 -o kompose
# macOS
$ curl -L https://github.com/kubernetes/kompose/releases/download/v1.0.0/kompose-darwin-amd64 -o kompose
$ chmod +x kompose
$ sudo mv ./kompose /usr/local/bin/komposeBefore running docker-stack.yml in Kompose, we change it a bit and remove the deployment key of each service. This key is not perceived, and because of it errors may occur when generating file descriptors. You can also delete information about networks. In Kompose, we will give away a new file, which we call docker-stack-k8s.yml .
version: "3" services: redis: image: redis:alpine ports: - "6379" db: image: postgres:9.4 volumes: - db-data:/var/lib/postgresql/data vote: image: dockersamples/examplevotingapp_vote:before ports: - 5000:80 depends_on: - redis result: image: dockersamples/examplevotingapp_result:before ports: - 5001:80 depends_on: - db worker: image: dockersamples/examplevotingapp_worker visualizer: image: dockersamples/visualizer:stable ports: - "8080:8080" stop_grace_period: 1m30s volumes: - "/var/run/docker.sock:/var/run/docker.sock" volumes: db-data: From the docker-stack-k8s.yml file, we generate handles for the application using the following command:
$ kompose convert --file docker-stack-k8s.yml
WARN Volume mount on the host "/var/run/docker.sock" isn't supported - ignoring path on the host
INFO Kubernetes file "db-service.yaml" created
INFO Kubernetes file "redis-service.yaml" created
INFO Kubernetes file "result-service.yaml" created
INFO Kubernetes file "visualizer-service.yaml" created
INFO Kubernetes file "vote-service.yaml" created
INFO Kubernetes file "worker-service.yaml" created
INFO Kubernetes file "db-deployment.yaml" created
INFO Kubernetes file "db-data-persistentvolumeclaim.yaml" created
INFO Kubernetes file "redis-deployment.yaml" created
INFO Kubernetes file "result-deployment.yaml" created
INFO Kubernetes file "visualizer-deployment.yaml" created
INFO Kubernetes file "visualizer-claim0-persistentvolumeclaim.yaml" created
INFO Kubernetes file "vote-deployment.yaml" created
INFO Kubernetes file "worker-deployment.yaml" createdWe see that for each service a deployment and service file is created.
We received only one warning. It is connected to the visualizer , because the Docker's socket cannot be connected. We will not try to start this service, but focus on the rest.
Deploy the application
Through kubectl we will create all the components specified in the descriptor file. Indicate that the files are located in the current folder.
$ kubectl create -f .
persistentvolumeclaim "db-data" created
deployment "db" created
service "db" created
deployment "redis" created
service "redis" created
deployment "result" created
service "result" created
persistentvolumeclaim "visualizer-claim0" created
deployment "visualizer" created
service "visualizer" created
deployment "vote" created
service "vote" created
deployment "worker" created
service "worker" created
unable to decode "docker-stack-k8s.yml":...Note: since we left the modified compose file in the current folder, we received an error, because you cannot parse it. But this error can be ignored without any risk.
With the help of these commands you can see the created Services and Deployments .
We give access to the application from the outside world
To gain access to the interface vote and result, you need to slightly change the services created for them.
Here is the generated voice descriptor:
apiVersion: v1 kind: Service metadata: creationTimestamp: null labels: io.kompose.service: vote name: vote spec: ports: - name: "5000" port: 5000 targetPort: 80 selector: io.kompose.service: vote status: loadBalancer: {} We will change the type of service and replace ClusterIP with NodePort . ClusterIP makes the service available internally, and NodePort allows publishing the port on each node of the cluster and makes it available to the whole world. Let's do the same for result , because we want both to vote and to result was access from outside.
apiVersion: v1 kind: Service metadata: labels: io.kompose.service: vote name: vote spec: type: NodePort ports: - name: "5000" port: 5000 targetPort: 80 selector: io.kompose.service: vote As soon as changes are made to both services ( vote and result ), you can re-create them.
$ kubectl delete svc vote
$ kubectl delete svc result
$ kubectl create -f vote-service.yaml
service "vote" created
$ kubectl create -f result-service.yaml
service "result" createdAccess to the application
Now we will get the details of the vote and result services and get the ports that they provide.
The vote is available on port 30069, and the result is 31873. Now we vote and see the results.
After we dealt with the basic components of Kubernetes, we were able to easily deploy the application. And Kompose helped us a lot.
Hashicorp's Nomad
Nomad is a tool for managing a cluster of machines and running an application on them. It abstracts the machines and the point of the application and lets users say what they want to run. And Nomad is responsible for where it will be launched and how.
Nomad concept
The Nomad cluster consists of agents (agents) that can operate in server (server) mode or client (client) mode.
- The server is responsible for the consensus protocol , which allows the server to choose a leader and perform state replication.
- Clients are very light, because they interact with the server, while doing almost nothing themselves. In client nodes, tasks are executed.
Several types of tasks can be run on a Nomad cluster.
In order to deploy the application you need to understand the basic concepts of Nomad:
- Job - defines what tasks Nomad should perform. This is described in a job file (text file in hcl format, Hashicorp Configuration Language). A job can contain one or more tasks groups.
- Group contains several tasks that are located on the same machine.
- Task is a running process, in our case it is a Docker container
- Mapping tasks in a job is done using Allocations. Allocation is used to ensure that tasks in a job are executed on a specific node.
Installation
In this example, we will run the application on the Docker host, created using the Docker Machine. The local IP is 192.168.1.100. First, run Consul, which is used to discover and register services. We will launch Nomad and deploy the application as Job in Nomad.
Consul for registration and discovery services
For detecting and registering services, a tool is recommended, for example, Consul, which will not work as Job in Nomad. Consul can be downloaded here .
This command starts the Consul server locally:
$ consul agent -dev -client=0.0.0.0 -dns-port=53 -recursor=8.8.8.8Let's take a closer look at the options used:
- - dev — the flag that sets up the Consul cluster with the server and client. This option should only be used for development and testing.
- -client = 0.0.0.0 allows you to reach Consul services (API and DNS server) through any host interface. This is necessary because Nomad will join the Consul via the localhost interface, and the containers through the docker-bridge (something like 172.17.x.x).
- -dns-port = 53 specifies the port that Consul’s DNS server will use (default is 8600). We will install the standard port 53 so that DNS can be used from the container.
- -recursor = 8.8.8.8 defines another DNS server that will handle requests that Consul cannot handle
Nomad can be downloaded from this link .
Create a cluster with a node
We downloaded Nomad and now we can run the Agent with the following settings.
// nomad.hcl bind_addr = "0.0.0.0" data_dir = "/var/lib/nomad" server { enabled = true bootstrap_expect = 1 } client { enabled = true network_speed = 100 } The agent will work both as a server and as a client. We point out that bind_addr should work with any interface so that tasks can be received from the outside world. Launch the Nomad Agent with the following settings:
$ nomad agent -config=nomad.hcl
==> WARNING: Bootstrap mode enabled! Potentially unsafe operation.
Loaded configuration from nomad-v2.hcl
==> Starting Nomad agent...
==> Nomad agent configuration:
Client: true
Log Level: INFO
Region: global (DC: dc1)
Server: true
Version: 0.6.0
==> Nomad agent started! Log data will stream in below:Note: By default, Nomad connects to the local Consul instance.
We have just installed a cluster with one node. Here is the information on the unique participant:
$ nomad server-members
Name Address Port Status Leader Protocol Build Datacenter Region
neptune.local.global 192.168.1.100 4648 alive true 2 0.6.0 dc1 globalDeploy the application
To deploy an application using Swarm, you can use the compose file right away. To deploy via Kubernetes, we need descriptors from the same compose files. How does all this happen through Nomad?
Firstly, there is no tool similar to Kompose for Hashicorp, so that it can simplify the migration of compose to Nomad (a good idea for an OpenSource project, by the way). Files describing Jobs , groups , tasks must be written manually.
We will analyze this in more detail when we describe Jobs for the Redis and Vote services. For other services, it will look about the same.
Determine Job for Redis
This file defines the part of Redis in the application:
// redis.nomad job "redis-nomad" { datacenters = ["dc1"] type = "service" group "redis-group" { task "redis" { driver = "docker" config { image = "redis:3.2" port_map { db = 6379 } } resources { cpu = 500 # 500 MHz memory = 256 # 256MB network { mbits = 10 port "db" {} } } service { name = "redis" address_mode = "driver" port = "db" check { name = "alive" type = "tcp" interval = "10s" timeout = "2s" } } } } } Let's look at what is written here:
- Job Name - redis-nomad
- Job type is a service (i.e. a lengthy operation)
- The group is given an arbitrary name; contains one operation
- Task Redis uses docker-driver, which means it will be launched in a container
- Task will use Redis image: 3.2
- In the resource block there are limitations for CPU and memory.
- The network block indicates that the db port must be dynamic.
- In the service block, it is defined how the Consul registration will take place: service name, IP address and health check definition
In order to check whether the Job will run correctly, use the plan command:
$ nomad plan redis.nomad + Job: "nomad-redis" + Task Group: "cache" (1 create) + Task: "redis" (forces create) Scheduler dry-run: - All tasks successfully allocated. Job Modify Index: 0 To submit the job with version verification run: nomad run -check-index 0 redis.nomad When running the job with the check-index flag, the job will only be run if the server side version matches the job modify index returned. If the index has changed, another user has modified the job and the plan's results are potentially invalid. It seems everything works. Now deploy the task with this job:
$ nomad run redis.nomad ==> Monitoring evaluation "1e729627" Evaluation triggered by job "nomad-redis" Allocation "bf3fc4b2" created: node "b0d927cd", group "cache" Evaluation status changed: "pending" -> "complete" ==> Evaluation "1e729627" finished with status "complete" We see that the placement is created. Check its status:
$ nomad alloc-status bf3fc4b2 ID = bf3fc4b2 Eval ID = 1e729627 Name = nomad-redis.cache[0] Node ID = b0d927cd Job ID = nomad-redis Job Version = 0 Client Status = running Client Description = <none> Desired Status = run Desired Description = <none> Created At = 08/23/17 21:52:03 CEST Task "redis" is "running" Task Resources CPU Memory Disk IOPS Addresses 1/500 MHz 6.3 MiB/256 MiB 300 MiB 0 db: 192.168.1.100:21886 Task Events: Started At = 08/23/17 19:52:03 UTC Finished At = N/A Total Restarts = 0 Last Restart = N/A Recent Events: Time Type Description 08/23/17 21:52:03 CEST Started Task started by client 08/23/17 21:52:03 CEST Task Setup Building Task Directory 08/23/17 21:52:03 CEST Received Task received by client The container is running correctly. Check the Consul DNS server and make sure that the service also registers correctly:
$ dig @localhost SRV redis.service.consul ; <<>> DiG 9.10.3-P4-Ubuntu <<>> @localhost SRV redis.service.consul ; (1 server found) ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 35884 ;; flags: qr aa rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 2 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;redis.service.consul. IN SRV ;; ANSWER SECTION: redis.service.consul. 0 IN SRV 1 1 6379 ac110002.addr.dc1.consul. ;; ADDITIONAL SECTION: ac110002.addr.dc1.consul. 0 IN A 172.17.0.2 ;; Query time: 0 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Wed Aug 23 23:08:36 CEST 2017 ;; MSG SIZE rcvd: 103 Task was placed on IP 172.17.0.2, and its port is 6379, as we indicated.
Determine Job for Vote
Define a job for the vote service. Use the following file:
// job.nomad job "vote-nomad" { datacenters = ["dc1"] type = "service" group "vote-group" { task "vote" { driver = "docker" config { image = "dockersamples/examplevotingapp_vote:before" dns_search_domains = ["service.dc1.consul"] dns_servers = ["172.17.0.1", "8.8.8.8"] port_map { http = 80 } } service { name = "vote" port = "http" check { name = "vote interface running on 80" interval = "10s" timeout = "5s" type = "http" protocol = "http" path = "/" } } resources { cpu = 500 # 500 MHz memory = 256 # 256MB network { port "http" { static = 5000 } } } } } } But there are several differences from the file that we used for Redis:
- Vote connects to redis using only the name of the operation. Here is an example of a part of the app.py file used in the vote service:
// app.py def get_redis(): if not hasattr(g, 'redis'): g.redis = Redis(host="redis", db=0, socket_timeout=5) return g.redis In this case, to obtain the IP container with redis, the container with vote must use the Consul DNS server. DNS query from the container is executed via the Docker bridge (172.17.0.1). dns_search_domains specifies that Service X is registered as X.service.dc1.consul within Consul
- We installed a static port so that the vote service on port 5000 is accessible from outside the cluster.
We can do the same setup for other services: worker, postgres and result.
Access to the application
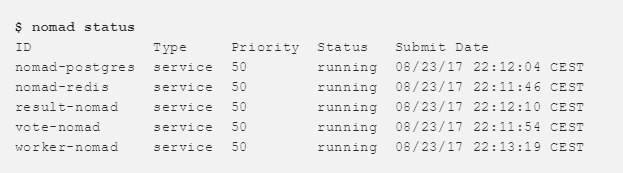
When all the Jobs are running, you can check their status and make sure everything works.
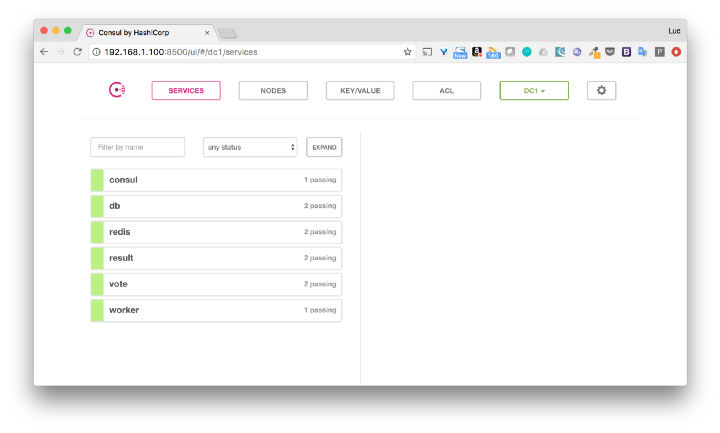
We can also view this through the Consul interface.
By IP nodes (in our case 192.168.1.100), we get access to interfaces with a vote and result .
Total
Here is such a wonderful application from the point of view of the demonstration. I was wondering if it could be deployed without changes in the code with the help of some orchestrator. And yes, it is possible, even without some special dances with a tambourine.
I hope this article will help you understand the basics of Swarm, Kubernetes and Nomad. It would also be interesting to know what you are launching at Docker and how you use the orchestrator.
Source: https://habr.com/ru/post/339508/
All Articles