Overview of one Russian RTOS, part 7. Means of data exchange between tasks
In addition to interaction at the level of interlocking, tasks must interact with each other and at the data level. At the same time, the distinctive feature of the MAX RTOS is the possibility of data exchange not only within one controller,
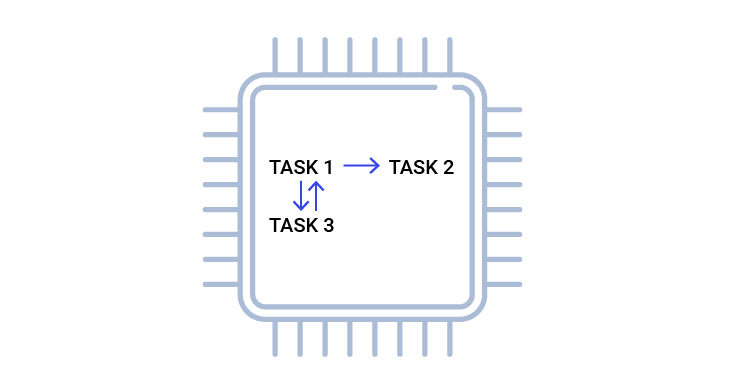
Fig. 1. An example of the interaction of tasks within one controller
but also between the controllers, completely hiding the transport level.
')

Fig. 2. An example of the interaction of tasks between controllers
In this case, different controllers are equivalent to different processes, since their memory is completely isolated. In the OS version published on our website , the physical channel between the controllers can be wired SPI or UART interfaces, as well as a wireless interface through RF24 radio modules.
The use of SPI and UART options is not recommended, since in the current implementation no more than two controllers can be connected through them.
Further I will tell about it in more detail, and other chapters of the "Book of Knowledge" can be found here:
Part 1. General information
Part 2. Core MAX MAX
Part 3. The structure of the simplest program
Part 4. Useful theory
Part 5. The first application
Part 6. Thread synchronization tools
Part 7. Means of data exchange between tasks (this article)
Part 8. Work with interruptions
The classic approach to the work of the RTOS is as follows: tasks exchange data with each other using message queues. At least all academic textbooks require it. I belong to practicing programmers, so I admit that it is sometimes easier to get by with any direct means of exchange made for a specific case. For example, banal ring buffers that are not tied to the system. But nevertheless, there are cases where message queues are the most optimal objects (if only because, unlike non-system things, they can block tasks when the buffer overflows or the polled buffer is empty).
Consider a textbook example. There is a serial port. Of course, by the circuit engineers, to simplify the system, it is made without flow control lines. Data on the wire can go one after the other. At the same time, the equipment of many (though not all) typical controllers does not imply a large hardware queue. If the data do not have time to pick up - they will be overwritten by all new portions coming from the receiving shift register.
On the other hand, suppose a task processing data takes some time (for example, to move a working tool). This is quite normal - the G-code comes to CNC machines with some pre-emption. The tool moves, and the next line at the same time runs along the wires.
So that the buffer register of the controller does not overflow, and the bytes in the program would have time to be received during the main work, it is necessary and sufficient to do them in the interrupt handler. The simplest variant is possible when “raw” bytes are transferred to the main task:
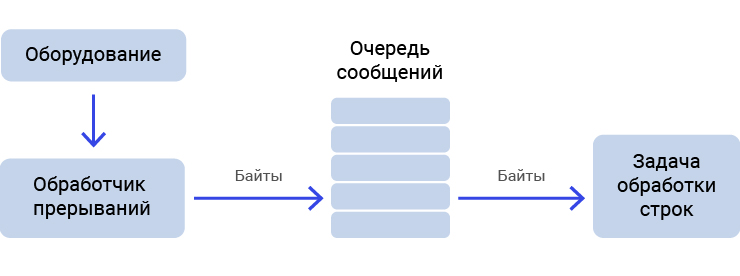
Pic.3
But in this case, it turns out too many operations of staging and taking from the queue. Overhead costs are too high. It is advisable to queue not the “raw” bytes, but already the results of their preprocessing (starting from lines, ending with the results of string interpretation for our G-code example). But it is unacceptable to perform preprocessing in the interrupt handler, because at that time part and all other interrupts are blocked (depending on the priority setting), and data for other subsystems will be processed with a delay, which sometimes disrupts the product.
This postulate is worth repeating it several times. I remember that on one forum I saw the following question: “I took a typical microphone sound unpacker from the PDM format, but it does not work properly.” And an example was attached to the question in which PDM filtering was performed in the context of an interrupt. It goes without saying that when the author of the question began to convert from PDM to PCM without interruption (as he was immediately advised), all the problems went away by themselves. Therefore, in the interruption of preprocessing to produce unacceptable! You can not cook eggs in the microwave and perform unnecessary actions in the interrupt handler!
The scheme recommended in all textbooks, if there is a preprocessing, is as follows.
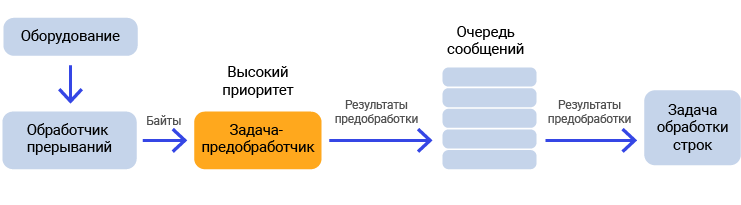
Pic.4
The high-priority preprocessing task is blocked almost all the time. The interrupt handler received a byte from the hardware, the preprocessor woke it up, passing it that byte, and then went out. From now on, all interrupts are re-enabled.
The high-priority preprocessor wakes up, accumulates data in the internal buffer, and then falls asleep, again giving the opportunity to work with normal priority tasks. When a line is accumulated (a newline character has arrived), it interprets it and places the result in the message queue. This is the option that all academic publications recommend, so I simply had to bring a classic idea to the readers here. Although I immediately add that I myself, not as a theorist, but as a practitioner, I see the weak point of this method. We win on a rare reference to the queue, but we lose on context switches for entering a high-priority task. In general, the recommendations were communicated, about the shortcomings of this approach - it’s told, and how to work in real life - everyone should find his own method, selecting the optimal ratio of performance and simplicity. Some recommendations with real estimations will be in the next article on interrupts.
To implement the message queue, the MessageQueue class is used. Since the message queue should work effectively with arbitrary types of data, it is implemented as a template (the data type is substituted for it as an argument).
The constructor has the form:
MessageQueue (size_t max_size);
The max_size parameter specifies the maximum queue size. If you try to queue an item when it is filled to capacity, the assigning task will be blocked until a free space appears (some task will not pick up one of the already queued items).
Since it has already been said too much, one cannot do without an example of queue initialization. Take a fragment of the test, in which you can see that the queue element is of type short, and the dimension of the queue will not exceed 5 elements:
You can put a message in the queue using the function:
Result Push (const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
The timeout_ms parameter is required for cases when the queue is full. In this case, the system will try to wait for the moment when free space appears in it. And this parameter - just tells how long it is allowed to wait.
If necessary, the message can be put not at the end of the queue, but at its beginning. To do this, use the function:
Result PushFront (const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
To remove another item from the head of the queue, use the function:
Result Pop (T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Here, respectively, the timeout parameter sets the wait time in case the queue is empty. During the specified time, the system will try to wait for messages in the queue to appear in other tasks.
You can also get the value of the element from the queue head, without removing it:
Result Peek (T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Finally, there are functions to find out the number of messages in the queue:
size_t Count ()
and the maximum possible queue size:
size_t GetMaxSize ()
Generally, purely formally, the means of communication between controllers are drivers. But ideologically, they belong to the usual means of data exchange, which is one of the main features of the MAKS RTOS; therefore, we will consider them in the part of the manual relating to the core.
I recall that in the published version of the OS, physical exchange can be carried out through wired interfaces UART or SPI, or through the radio module RF24 (also connected to the SPI interface). We also recall that in order to activate the data exchange between controllers, a line should be entered in the MaksConfig.h file:
#define MAKS_USE_SHARED_MEM 1
and determine the type of physical channel by setting one of the constants in the unit:
MAKS_SHARED_MEM_SPI, MAKS_SHARED_MEM_UART or MAKS_SHARED_MEM_RADIO .
The SPI and UART mechanisms in the current implementation provide communication between only two devices, so the radio variant is recommended
Now, after such a prolonged preamble, let's start studying the SharedMemory class.
The class object can be initialized using the Initialize () function. The word "can" is not applied accidentally. In general, for a radio variant, initialization is not required.
The data structure is passed to this function. Consider briefly her field.

Consider the examples of filling this structure and calling the initialization function.
Another option:
This class provides two mechanisms for interacting tasks - messages and shared memory (with the possibility of locks).
Since the “shared memory” object is always one, the developers of the operating system created the MaksSharedMemoryExtensions.cpp file, which converts complex function names to global ones.
Here is a fragment of this file:
Since all the applications in the package use global function names, I will also use this naming convention in the examples for this document.
Let's start with the messages. To send them, use the SendMessage () function. The function is quite complex, so consider it in detail:
Result SendMessage (uint32_t message_id, const void * data, size_t data_length)
Arguments:
message_id - message identifier;
data - a pointer to the message data;
data_length - the length of the message data.
Usage example:
The result of the function reflects the status of the message being sent. It was received by any of the recipients or not - the function is silent. It is only known whether it is gone or not. To confirm, the recipient must independently send a return message.
Accordingly, the function is used to wait for a message on the recipient’s side:
Result WaitUntilMessageReceived (SmMessageReceiveArgs & args, uint32_t timeout_ms = INFINITE_TIMEOUT)
Arguments:
args - object reference with message parameters;
timeout_ms - wait timeout in milliseconds. If the time-out value is INFINITE_TIMEOUT, then the task will be blocked without the possibility of unlocking by time-out (endless waiting).
Message parameters are a whole class. Consider briefly its open members:
uint32_t GetMessageId ()
Returns the received message ID:
size_t GetDataLength ()
Returns the data size of the received message in bytes.
void CopyDataTo (void * target)
Copies the message data to the specified buffer. Memory for the buffer must be allocated in advance. The buffer size must be at least the size of the message data (the result of calling the GetDataLength method)
Thus, an example serving the receipt of a message sent in the past example looks like this:
Context is the area of memory that should be synchronized between all controllers. The goal of synchronization can be any. The simplest case is that one device informs the other about completed work steps for hot sparing. If it fails, other devices will have information about how to pick up the work. For devices that achieve the goal together, the exchange mechanism through the context may be more convenient than through messages. Messages should be formed, transmitted, received, decoded. And it is possible to work with context memory as with ordinary memory; it is only important not to forget to synchronize it so that the memory of one device is duplicated with the others.
The number of synchronized contexts in the system can be arbitrary. Therefore, it is not necessary to fit everything into one. For different needs, you can create different synchronized contexts. The size of the memory, the data structure in it and other parameters of the synchronized context is the concern of the application programmer (of course, the larger the amount of synchronized memory, the slower the synchronization occurs, which is why it is better to use different contexts of small size for different needs).
In addition, even moments for synchronization sessions - and those are selected by the application programmer. The RTOS MAX provides an API to provide, but an application programmer should call its functions. This is due to the fact that the data exchange process is relatively slow. If everything is left at the mercy of the operating system, then there may be delays at a time when the processor core should serve other tasks as much as possible. If you automatically synchronize contexts too often, resources will be wasted, if too rarely, data may become outdated before the controllers are synchronized. Add to this the question, whose data is more important (for example, if there are four different subscribers), after which it becomes absolutely clear - only an application programmer can initiate synchronization. It is he who knows when it is better to do this, as well as which of the subscribers should distribute their data to the rest. The OS also provides transparency of the operation for the application program.
The context has its own numeric identifier (set by the application programmer). All applications can have one synchronized context or several. It is only important that their identifiers be consistent within the interacting controllers.
The simplest examples of synchronized data are the cleaning robots periodically mark the territory they have cleaned on the map in order to know about the still uncleared areas, and also tell who is going where to go now, so as not to interfere with each other. Wrenches working on one product, mark each screwed nut after the end of screwing, so that if one fails, the other would have finished its part. A touch-screen board fixed the pressure and noted this fact for the rest of the boards. Well, a lot of other cases where you need to share memory, but it is allowed to do this several times per second (maximum - several dozen times per second).
Thus, the context can be represented in the form shown in the figure:

Fig. 5. Context
And its purpose - can be represented in the following image:
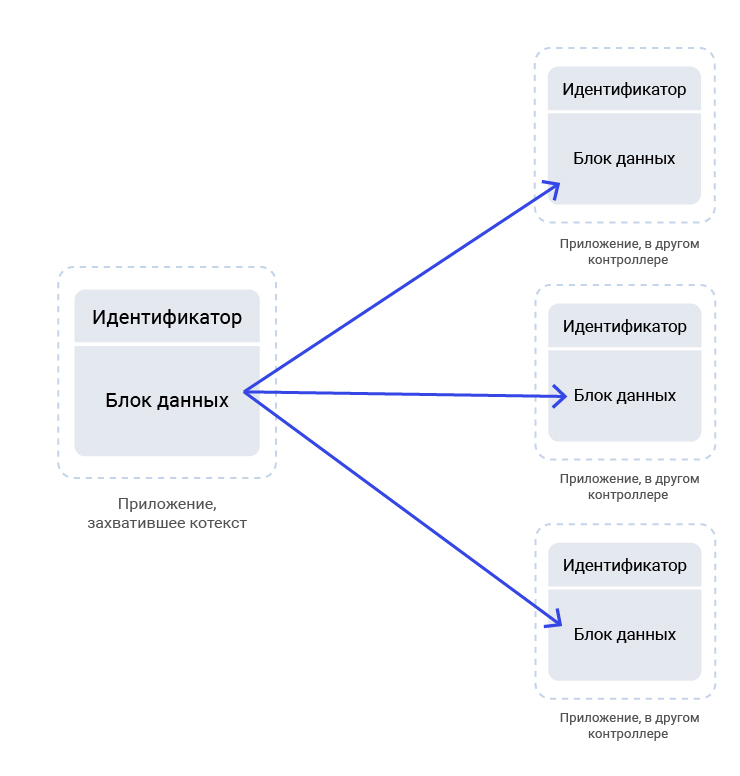
Fig. 6. The essence of context synchronization
Now consider the functions that are used to synchronize the context:
Result GetContext (uint32_t context_id, void * data);
It copies the context data to the specified memory area, the memory must be allocated in advance. Suitable for the case when the data length is known in advance (for example, a structure with simple fields).
Arguments:
context_id - context identifier;
data - pointer to the memory area for storing the context;
As a result, the context data with the specified identifier that was received during the last synchronization will be returned. Thus, this function will work quickly, since the data is taken from a local copy of the context. There is a second version of this function:
Result GetContext (uint32_tcontext_id, void * & data, size_t & data_length);
allocates memory and copies data and context length. Suitable for the case when the length of the data is not known in advance (for example, an array of arbitrary length).
Arguments:
context_id - context identifier;
data - pointer to the memory area for storing the context;
data_length - the size in bytes of the memory area for storing the context.
In principle, you can create a task that will wait for the context update, and then copy its new data into the application's memory. The following function is suitable for this:
Result WaitUntilContextUpdated (uint32_t & context_id, uint32_t timeout_ms = INFINITE_TIMEOUT)
Arguments:
context_id - context identifier;
timeout_ms - wait timeout in milliseconds. If the time-out value is INFINITE_TIMEOUT, then the task will be blocked without the possibility of unlocking by time-out (endless waiting).
Finally, consider the case when a task wants to update its context throughout the system (consisting of several controllers).
First you need to capture the context. To do this, use the following function:
Result LockContext (uint32_t context_id)
Argument:
context_id - context identifier.
The function requires the exchange between controllers, so it can take a long time.
If the context was able to be captured (if you try to capture at the same time, only one will win, the others will get an error code), then the context can be written using the following function:
Result SetContext (uint32_t context_id, const void * data, size_t data_length)
Arguments:
context_id - context identifier;
data - a pointer to the memory area for storing the context;
data_length - the size in bytes of the memory area for storing the context.
Finally, to synchronize the context, call the function:
Result UnlockContext (uint32_t context_id)
Argument:
context_id - context identifier.
It is after her call that the synchronization of contexts in the entire system will occur.
The function requires the exchange between controllers, so it can take a long time.
Consider a real example of working with synchronized contexts that comes bundled with the OS. The code is contained in the file ... \ maksRTOS \ Source \ Applications \ CounterApp.cpp
In this example, several devices increase a certain counter once a second (if you run this application on boards with a screen, the value of the counter will be displayed visually). If one of the controllers is disabled and then enabled, it will receive the current contents of the counter and will work along with all. Thus, the system will keep counting as long as at least one of the controllers is “alive” in it.
The application programmer who did this example chose the context identifier on the principle: “Why not?”
The memory to be synchronized looks easy:
The main actions that interest us occur in the function:
void CounterTask :: Execute ()
First, the controller tries to figure out: is it the first one in the system? For this, it tries to get the context:
If the controller is not the first, then the context will be received, but the value of the counter, which exists in the system, will also be received in passing.
If the controller is first, the context will not be received. In this case, it should be created, which is done as follows (in the same place, the counter is zero);
Everything, now the context exactly exists, it was found in the system to which we just connected, or created by us. Enter an infinite loop:
There we wait one second:
And we are trying to win a contest for the right to distribute our counter to the whole system:
—
, , . , . , . , , , , , . , , - .
Fig. 1. An example of the interaction of tasks within one controller
but also between the controllers, completely hiding the transport level.
')
Fig. 2. An example of the interaction of tasks between controllers
In this case, different controllers are equivalent to different processes, since their memory is completely isolated. In the OS version published on our website , the physical channel between the controllers can be wired SPI or UART interfaces, as well as a wireless interface through RF24 radio modules.
The use of SPI and UART options is not recommended, since in the current implementation no more than two controllers can be connected through them.
Further I will tell about it in more detail, and other chapters of the "Book of Knowledge" can be found here:
Part 1. General information
Part 2. Core MAX MAX
Part 3. The structure of the simplest program
Part 4. Useful theory
Part 5. The first application
Part 6. Thread synchronization tools
Part 7. Means of data exchange between tasks (this article)
Part 8. Work with interruptions
Means for data exchange within one controller (message queue)
The classic approach to the work of the RTOS is as follows: tasks exchange data with each other using message queues. At least all academic textbooks require it. I belong to practicing programmers, so I admit that it is sometimes easier to get by with any direct means of exchange made for a specific case. For example, banal ring buffers that are not tied to the system. But nevertheless, there are cases where message queues are the most optimal objects (if only because, unlike non-system things, they can block tasks when the buffer overflows or the polled buffer is empty).
Consider a textbook example. There is a serial port. Of course, by the circuit engineers, to simplify the system, it is made without flow control lines. Data on the wire can go one after the other. At the same time, the equipment of many (though not all) typical controllers does not imply a large hardware queue. If the data do not have time to pick up - they will be overwritten by all new portions coming from the receiving shift register.
On the other hand, suppose a task processing data takes some time (for example, to move a working tool). This is quite normal - the G-code comes to CNC machines with some pre-emption. The tool moves, and the next line at the same time runs along the wires.
So that the buffer register of the controller does not overflow, and the bytes in the program would have time to be received during the main work, it is necessary and sufficient to do them in the interrupt handler. The simplest variant is possible when “raw” bytes are transferred to the main task:
Pic.3
But in this case, it turns out too many operations of staging and taking from the queue. Overhead costs are too high. It is advisable to queue not the “raw” bytes, but already the results of their preprocessing (starting from lines, ending with the results of string interpretation for our G-code example). But it is unacceptable to perform preprocessing in the interrupt handler, because at that time part and all other interrupts are blocked (depending on the priority setting), and data for other subsystems will be processed with a delay, which sometimes disrupts the product.
This postulate is worth repeating it several times. I remember that on one forum I saw the following question: “I took a typical microphone sound unpacker from the PDM format, but it does not work properly.” And an example was attached to the question in which PDM filtering was performed in the context of an interrupt. It goes without saying that when the author of the question began to convert from PDM to PCM without interruption (as he was immediately advised), all the problems went away by themselves. Therefore, in the interruption of preprocessing to produce unacceptable! You can not cook eggs in the microwave and perform unnecessary actions in the interrupt handler!
The scheme recommended in all textbooks, if there is a preprocessing, is as follows.
Pic.4
The high-priority preprocessing task is blocked almost all the time. The interrupt handler received a byte from the hardware, the preprocessor woke it up, passing it that byte, and then went out. From now on, all interrupts are re-enabled.
The high-priority preprocessor wakes up, accumulates data in the internal buffer, and then falls asleep, again giving the opportunity to work with normal priority tasks. When a line is accumulated (a newline character has arrived), it interprets it and places the result in the message queue. This is the option that all academic publications recommend, so I simply had to bring a classic idea to the readers here. Although I immediately add that I myself, not as a theorist, but as a practitioner, I see the weak point of this method. We win on a rare reference to the queue, but we lose on context switches for entering a high-priority task. In general, the recommendations were communicated, about the shortcomings of this approach - it’s told, and how to work in real life - everyone should find his own method, selecting the optimal ratio of performance and simplicity. Some recommendations with real estimations will be in the next article on interrupts.
To implement the message queue, the MessageQueue class is used. Since the message queue should work effectively with arbitrary types of data, it is implemented as a template (the data type is substituted for it as an argument).
template <typename T> class MessageQueue { ... The constructor has the form:
MessageQueue (size_t max_size);
The max_size parameter specifies the maximum queue size. If you try to queue an item when it is filled to capacity, the assigning task will be blocked until a free space appears (some task will not pick up one of the already queued items).
Since it has already been said too much, one cannot do without an example of queue initialization. Take a fragment of the test, in which you can see that the queue element is of type short, and the dimension of the queue will not exceed 5 elements:
voidMessageQueueTestApp::Initialize() { mQueue = new MessageQueue<short>(5); Task::Add(new MessageSenderTask("send"), Task::PriorityNormal, 0x50); Task::Add(new MessageReceiverTask("receive"), Task::PriorityNormal, 0x50); } You can put a message in the queue using the function:
Result Push (const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
The timeout_ms parameter is required for cases when the queue is full. In this case, the system will try to wait for the moment when free space appears in it. And this parameter - just tells how long it is allowed to wait.
If necessary, the message can be put not at the end of the queue, but at its beginning. To do this, use the function:
Result PushFront (const T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
To remove another item from the head of the queue, use the function:
Result Pop (T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Here, respectively, the timeout parameter sets the wait time in case the queue is empty. During the specified time, the system will try to wait for messages in the queue to appear in other tasks.
You can also get the value of the element from the queue head, without removing it:
Result Peek (T & message, uint32_t timeout_ms = INFINITE_TIMEOUT);
Finally, there are functions to find out the number of messages in the queue:
size_t Count ()
and the maximum possible queue size:
size_t GetMaxSize ()
Means of data exchange between different controllers
Generally, purely formally, the means of communication between controllers are drivers. But ideologically, they belong to the usual means of data exchange, which is one of the main features of the MAKS RTOS; therefore, we will consider them in the part of the manual relating to the core.
I recall that in the published version of the OS, physical exchange can be carried out through wired interfaces UART or SPI, or through the radio module RF24 (also connected to the SPI interface). We also recall that in order to activate the data exchange between controllers, a line should be entered in the MaksConfig.h file:
#define MAKS_USE_SHARED_MEM 1
and determine the type of physical channel by setting one of the constants in the unit:
MAKS_SHARED_MEM_SPI, MAKS_SHARED_MEM_UART or MAKS_SHARED_MEM_RADIO .
The SPI and UART mechanisms in the current implementation provide communication between only two devices, so the radio variant is recommended
Now, after such a prolonged preamble, let's start studying the SharedMemory class.
The class object can be initialized using the Initialize () function. The word "can" is not applied accidentally. In general, for a radio variant, initialization is not required.
The data structure is passed to this function. Consider briefly her field.
Consider the examples of filling this structure and calling the initialization function.
SmInitInfo info; info.TransferCore = &SpiTransferCore::GetInstance(); info.NotifyMessageReceived = true; info.AutoSendContextsActivity = true; info.SendActivityDelayMs = 100; info.CheckActivityDelayMs = 200; SpiTransferCore::GetInstance().Initialize(); SharedMemory::GetInstance().Initialize(info); Another option:
SmInitInfo info; info.TransferCore = &SpiTransferCore::GetInstance(); info.AutoSendContextsActivity = true; info.SendActivityDelayMs = 100; info.CheckActivityDelayMs = 200; SpiTransferCore::GetInstance().Initialize(); SharedMemory::GetInstance().Initialize(info); This class provides two mechanisms for interacting tasks - messages and shared memory (with the possibility of locks).
Since the “shared memory” object is always one, the developers of the operating system created the MaksSharedMemoryExtensions.cpp file, which converts complex function names to global ones.
Here is a fragment of this file:
Result GetContext(uint32_t context_id, void* data) { return SharedMemory::GetInstance().GetContext(context_id, data); } Result GetContext(uint32_t context_id, void* data, size_t data_length) { return SharedMemory::GetInstance().GetContext(context_id, data, data_length); } Result SetContext(uint32_t context_id, const void* data, size_t data_length) { return SharedMemory::GetInstance().SetContext(context_id, data, data_length); } Since all the applications in the package use global function names, I will also use this naming convention in the examples for this document.
Messages
Let's start with the messages. To send them, use the SendMessage () function. The function is quite complex, so consider it in detail:
Result SendMessage (uint32_t message_id, const void * data, size_t data_length)
Arguments:
message_id - message identifier;
data - a pointer to the message data;
data_length - the length of the message data.
Usage example:
const uint32_t APP5_EXPOSE_MESSAGE_ID = 503; ... if (broadcast) { char t = 0; SendMessage(APP5_EXPOSE_MESSAGE_ID, &t, sizeof(t)); } const uint32_t APP5_AIRPLANE_MESSAGE_ID = 504; ... bool AirplaneTask::SendAirplane() { Message msg(_x, _y, _deg, _visibility); return SendMessage(APP5_AIRPLANE_MESSAGE_ID, &msg, sizeof(msg)) == ResultOk; } The result of the function reflects the status of the message being sent. It was received by any of the recipients or not - the function is silent. It is only known whether it is gone or not. To confirm, the recipient must independently send a return message.
Accordingly, the function is used to wait for a message on the recipient’s side:
Result WaitUntilMessageReceived (SmMessageReceiveArgs & args, uint32_t timeout_ms = INFINITE_TIMEOUT)
Arguments:
args - object reference with message parameters;
timeout_ms - wait timeout in milliseconds. If the time-out value is INFINITE_TIMEOUT, then the task will be blocked without the possibility of unlocking by time-out (endless waiting).
Message parameters are a whole class. Consider briefly its open members:
uint32_t GetMessageId ()
Returns the received message ID:
size_t GetDataLength ()
Returns the data size of the received message in bytes.
void CopyDataTo (void * target)
Copies the message data to the specified buffer. Memory for the buffer must be allocated in advance. The buffer size must be at least the size of the message data (the result of calling the GetDataLength method)
Thus, an example serving the receipt of a message sent in the past example looks like this:
void MessageReceiveTask::Execute() { Message msg; while (true) { SmMessageReceiveArgs args; Result res = WaitUntilMessageReceived(args); if (res == ResultOk) { uint32_t mid = args.GetMessageId(); switch (mid) { .... case APP5_EXPOSE_MESSAGE_ID: #ifdef BOARD_LEFT _gfx->ExposeAirplaneRed(); #else _gfx->ExposeAirplaneBlue(); #endif break; case APP5_AIRPLANE_MESSAGE_ID: { args.CopyDataTo(&msg); #ifdef BOARD_LEFT _gfx->UpdateAirplaneRed(msg.X, msg.Y, msg.Deg); _gfx->SetAirplaneRedVisibility(msg.Visibility); #else _gfx->UpdateAirplaneBlue(msg.X, msg.Y, msg.Deg); _gfx->SetAirplaneBlueVisibility(msg.Visibility); #endif } break; ... Synchronized context
Context is the area of memory that should be synchronized between all controllers. The goal of synchronization can be any. The simplest case is that one device informs the other about completed work steps for hot sparing. If it fails, other devices will have information about how to pick up the work. For devices that achieve the goal together, the exchange mechanism through the context may be more convenient than through messages. Messages should be formed, transmitted, received, decoded. And it is possible to work with context memory as with ordinary memory; it is only important not to forget to synchronize it so that the memory of one device is duplicated with the others.
The number of synchronized contexts in the system can be arbitrary. Therefore, it is not necessary to fit everything into one. For different needs, you can create different synchronized contexts. The size of the memory, the data structure in it and other parameters of the synchronized context is the concern of the application programmer (of course, the larger the amount of synchronized memory, the slower the synchronization occurs, which is why it is better to use different contexts of small size for different needs).
In addition, even moments for synchronization sessions - and those are selected by the application programmer. The RTOS MAX provides an API to provide, but an application programmer should call its functions. This is due to the fact that the data exchange process is relatively slow. If everything is left at the mercy of the operating system, then there may be delays at a time when the processor core should serve other tasks as much as possible. If you automatically synchronize contexts too often, resources will be wasted, if too rarely, data may become outdated before the controllers are synchronized. Add to this the question, whose data is more important (for example, if there are four different subscribers), after which it becomes absolutely clear - only an application programmer can initiate synchronization. It is he who knows when it is better to do this, as well as which of the subscribers should distribute their data to the rest. The OS also provides transparency of the operation for the application program.
The context has its own numeric identifier (set by the application programmer). All applications can have one synchronized context or several. It is only important that their identifiers be consistent within the interacting controllers.
The simplest examples of synchronized data are the cleaning robots periodically mark the territory they have cleaned on the map in order to know about the still uncleared areas, and also tell who is going where to go now, so as not to interfere with each other. Wrenches working on one product, mark each screwed nut after the end of screwing, so that if one fails, the other would have finished its part. A touch-screen board fixed the pressure and noted this fact for the rest of the boards. Well, a lot of other cases where you need to share memory, but it is allowed to do this several times per second (maximum - several dozen times per second).
Thus, the context can be represented in the form shown in the figure:
Fig. 5. Context
And its purpose - can be represented in the following image:
Fig. 6. The essence of context synchronization
Now consider the functions that are used to synchronize the context:
Result GetContext (uint32_t context_id, void * data);
It copies the context data to the specified memory area, the memory must be allocated in advance. Suitable for the case when the data length is known in advance (for example, a structure with simple fields).
Arguments:
context_id - context identifier;
data - pointer to the memory area for storing the context;
As a result, the context data with the specified identifier that was received during the last synchronization will be returned. Thus, this function will work quickly, since the data is taken from a local copy of the context. There is a second version of this function:
Result GetContext (uint32_tcontext_id, void * & data, size_t & data_length);
allocates memory and copies data and context length. Suitable for the case when the length of the data is not known in advance (for example, an array of arbitrary length).
Arguments:
context_id - context identifier;
data - pointer to the memory area for storing the context;
data_length - the size in bytes of the memory area for storing the context.
In principle, you can create a task that will wait for the context update, and then copy its new data into the application's memory. The following function is suitable for this:
Result WaitUntilContextUpdated (uint32_t & context_id, uint32_t timeout_ms = INFINITE_TIMEOUT)
Arguments:
context_id - context identifier;
timeout_ms - wait timeout in milliseconds. If the time-out value is INFINITE_TIMEOUT, then the task will be blocked without the possibility of unlocking by time-out (endless waiting).
Finally, consider the case when a task wants to update its context throughout the system (consisting of several controllers).
First you need to capture the context. To do this, use the following function:
Result LockContext (uint32_t context_id)
Argument:
context_id - context identifier.
The function requires the exchange between controllers, so it can take a long time.
If the context was able to be captured (if you try to capture at the same time, only one will win, the others will get an error code), then the context can be written using the following function:
Result SetContext (uint32_t context_id, const void * data, size_t data_length)
Arguments:
context_id - context identifier;
data - a pointer to the memory area for storing the context;
data_length - the size in bytes of the memory area for storing the context.
Finally, to synchronize the context, call the function:
Result UnlockContext (uint32_t context_id)
Argument:
context_id - context identifier.
It is after her call that the synchronization of contexts in the entire system will occur.
The function requires the exchange between controllers, so it can take a long time.
Work example
Consider a real example of working with synchronized contexts that comes bundled with the OS. The code is contained in the file ... \ maksRTOS \ Source \ Applications \ CounterApp.cpp
In this example, several devices increase a certain counter once a second (if you run this application on boards with a screen, the value of the counter will be displayed visually). If one of the controllers is disabled and then enabled, it will receive the current contents of the counter and will work along with all. Thus, the system will keep counting as long as at least one of the controllers is “alive” in it.
The application programmer who did this example chose the context identifier on the principle: “Why not?”
static const uint32_t m_context_id = 42; The memory to be synchronized looks easy:
uint32_t m_counter; The main actions that interest us occur in the function:
void CounterTask :: Execute ()
First, the controller tries to figure out: is it the first one in the system? For this, it tries to get the context:
Result result = GetContext(m_context_id, & m_counter); If the controller is not the first, then the context will be received, but the value of the counter, which exists in the system, will also be received in passing.
If the controller is first, the context will not be received. In this case, it should be created, which is done as follows (in the same place, the counter is zero);
if ( result != ResultOk ) { m_counter = 0; result = LockContext(m_context_id); if ( result == ResultOk ) { SetContext(m_context_id, & m_counter, sizeof(m_counter)); UnlockContext(m_context_id); } } Everything, now the context exactly exists, it was found in the system to which we just connected, or created by us. Enter an infinite loop:
while (true) { There we wait one second:
Delay(MAKS_TICK_RATE_HZ); And we are trying to win a contest for the right to distribute our counter to the whole system:
result = LockContext(m_context_id); —
if ( result == ResultOk ) { GetContext(m_context_id, & m_counter); ++ m_counter; SetContext(m_context_id, & m_counter, sizeof(m_counter)); UnlockContext(m_context_id); } , , . , . , . , , , , , . , , - .
Source: https://habr.com/ru/post/339498/
All Articles