Airflow is a tool to conveniently and quickly develop and maintain batch data processing processes.

Hi, Habr! In this article, I want to talk about one great tool for developing batch data processing processes, for example, in an enterprise DWH infrastructure or your DataLake. It will be a question of Apache Airflow (further Airflow). It is unfairly deprived of attention on Habré, and in the main part I will try to convince you that at least on Airflow you should look when choosing a scheduler for your ETL / ELT processes.
Earlier, I wrote a series of articles on the topic of DWH, when I worked at Tinkoff Bank. Now I have become part of the Mail.Ru Group team and am developing a platform for analyzing data on the game direction. Actually, as news and interesting solutions appear, we and the team will talk here about our platform for data analytics.
Prologue
So, let's begin. What is Airflow? This is a library (or a set of libraries ) for developing, planning and monitoring workflows. The main feature of Airflow: for describing (developing) processes, Python code is used. This results in a lot of advantages for organizing your project and development: in fact, your (for example) ETL project is just a Python project, and you can organize it as you like, taking into account the particular infrastructure, team size and other requirements. Instrumental everything is simple. Use, for example, PyCharm + Git. It is beautiful and very comfortable!
Now consider the main essence of Airflow. Having understood their essence and purpose, you optimally organize the process architecture. Perhaps the main entity is the Directed Acyclic Graph (hereinafter referred to as DAG).
DAG
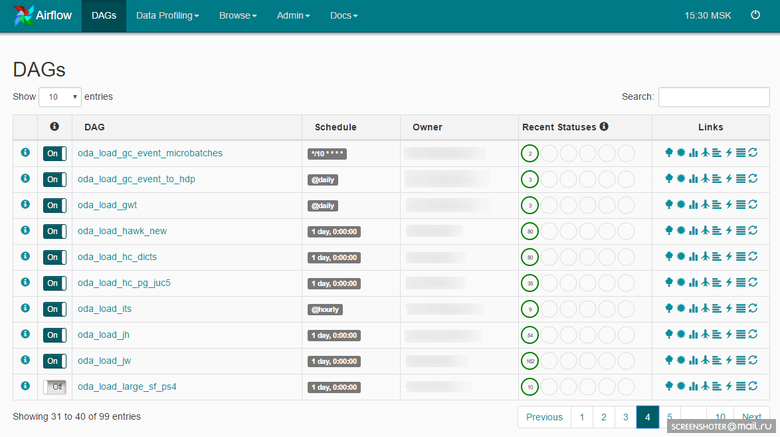
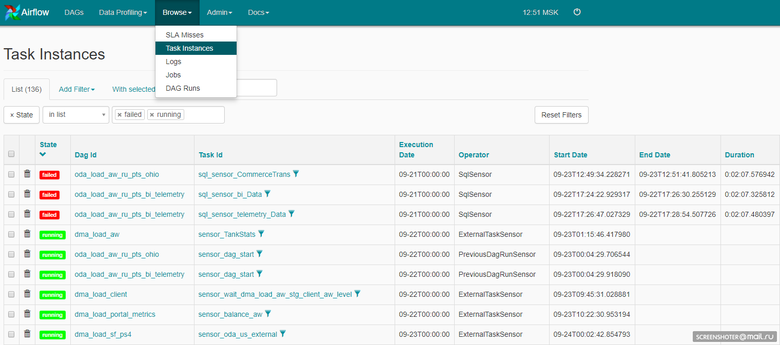
DAG is a certain semantic association of your tasks that you want to perform in a strictly defined sequence according to a specific schedule. Airflow provides a convenient web-interface for working with DAGs and other entities:
DAG might look like this:

The developer, designing DAG, lays a set of operators on which tasks will be built inside DAG'a. Here we come to another important entity: Airflow Operator.
Operators
An operator is an entity on the basis of which task instances are created, which describes what will happen during the execution of an instance of a task. Airflow releases from GitHub already contain a set of operators ready to use. Examples:
- BashOperator - an operator to execute a bash command.
- PythonOperator is an operator for calling Python code.
- EmailOperator is the operator for sending email.
- HTTPOperator is an operator for working with http requests.
- SqlOperator is an operator for executing SQL code.
- Sensor - the operator of the event wait (the desired time, the appearance of the desired file, the string in the database, the response from the API - and so on, etc.).
There are more specific operators: DockerOperator, HiveOperator, S3FileTransferOperator, PrestoToMysqlOperator, SlackOperator.
You can also develop operators, focusing on their features, and use them in the project. For example, we created MongoDBToHiveViaHdfsTransfer, an operator for exporting documents from MongoDB to Hive, and several operators for working with ClickHouse : CHLoadFromHiveOperator and CHTableLoaderOperator. As a matter of fact, as soon as a frequently used code arises in a project, built on basic operators, you can think about collecting it into a new operator. This will simplify further development, and you will replenish your library of operators in the project.
Further, all these instances of the tasks need to be performed, and now it will be a question of the scheduler.
Scheduler
Airflow Task Scheduler is built on Celery . Celery is a Python library that allows you to organize a queue plus asynchronous and distributed execution of tasks. From the Airflow side, all tasks are divided into pools. Pools are created manually. As a rule, their goal is to limit the workload with the source or to type tasks inside DWH. Pools can be controlled via the web interface:

Each pool has a limit on the number of slots. When creating a DAG, it is given a pool:
ALERT_MAILS = Variable.get("gv_mail_admin_dwh") DAG_NAME = 'dma_load' OWNER = 'Vasya Pupkin' DEPENDS_ON_PAST = True EMAIL_ON_FAILURE = True EMAIL_ON_RETRY = True RETRIES = int(Variable.get('gv_dag_retries')) POOL = 'dma_pool' PRIORITY_WEIGHT = 10 start_dt = datetime.today() - timedelta(1) start_dt = datetime(start_dt.year, start_dt.month, start_dt.day) default_args = { 'owner': OWNER, 'depends_on_past': DEPENDS_ON_PAST, 'start_date': start_dt, 'email': ALERT_MAILS, 'email_on_failure': EMAIL_ON_FAILURE, 'email_on_retry': EMAIL_ON_RETRY, 'retries': RETRIES, 'pool': POOL, 'priority_weight': PRIORITY_WEIGHT } dag = DAG(DAG_NAME, default_args=default_args) dag.doc_md = __doc__ The pool defined at the DAG level can be overridden at the task level.
A separate process, Scheduler, is responsible for scheduling all tasks in Airflow. Actually, Scheduler deals with all the mechanics of setting tasks for execution. The task, before getting into execution, goes through several stages:
- In DAG, the previous tasks are completed, a new one can be queued.
- The queue is sorted according to the priority of tasks (priorities can also be controlled), and if there is a free slot in the pool, the task can be taken to work.
- If there is a free worker celery, the task is sent to it; the work that you have programmed in the problem begins, using one or another operator.
Simple enough.
Scheduler runs on the set of all DAGs and all tasks within DAGs.
In order for Scheduler to start working with DAG, DAG needs to set a schedule:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='@hourly') There is a set of ready-made presets: @once , @hourly , @daily , @weekly , @monthly , @yearly .
You can also use cron expressions:
dag = DAG(DAG_NAME, default_args=default_args, schedule_interval='*/10 * * * *') Execution Date
To understand how Airflow works, it is important to understand what Execution Date is for DAG. In Airflow, DAG has a Execution Date dimension, i.e., depending on the DAG work schedule, task instances are created for each Execution Date. And for each Execution Date, tasks can be executed repeatedly - or, for example, the DAG can work simultaneously on several Execution Date. This is graphically displayed here:
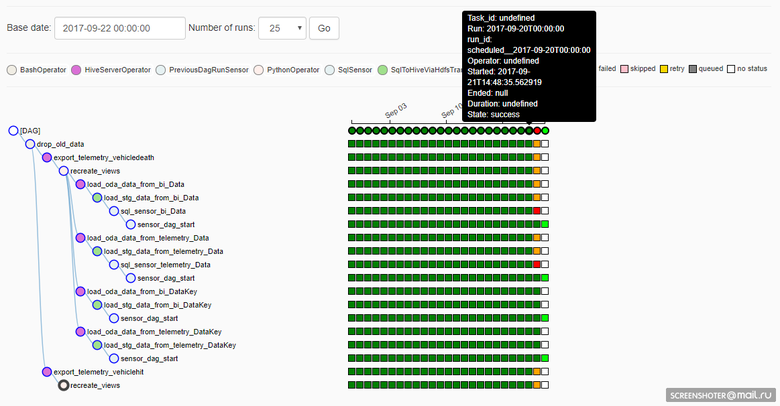
Unfortunately (and perhaps, fortunately: it depends on the situation), if the implementation of the problem is being corrected in DAG, then the execution in the previous Execution Date will go after adjustments. This is good if you need to recalculate the data in past periods with a new algorithm, but badly, because the reproducibility of the result is lost (of course, no one bothers to return the necessary version of the source code from Git and to calculate what you need, as needed).
Task generation
The implementation of DAG is Python code, so we have a very convenient way to reduce the amount of code when working, for example, with shardirovannyh sources. Let you have three MySQL shards as your source, you need to slag into each one and pick up some data. And independently and in parallel. Python code in DAG can look like this:
connection_list = lv.get('connection_list') export_profiles_sql = ''' SELECT id, user_id, nickname, gender, {{params.shard_id}} as shard_id FROM profiles ''' for conn_id in connection_list: export_profiles = SqlToHiveViaHdfsTransfer( task_id='export_profiles_from_' + conn_id, sql=export_profiles_sql, hive_table='stg.profiles', overwrite=False, tmpdir='/data/tmp', conn_id=conn_id, params={'shard_id': conn_id[-1:], }, compress=None, dag=dag ) export_profiles.set_upstream(exec_truncate_stg) export_profiles.set_downstream(load_profiles) DAG is obtained as follows:
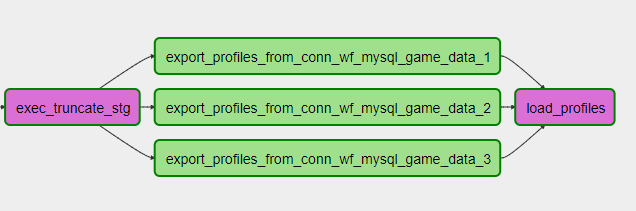
In this case, you can add or remove the shard by simply adjusting the setting and updating the DAG. Conveniently!
You can also use more complex code generation, for example, work with sources in the form of a database or describe a table structure, algorithm for working with a table and taking into account the features of the DWH infrastructure, generate the process of loading N tables to you in the repository. Or, for example, working with an API that does not support working with a parameter in the form of a list, you can generate N tasks in the DAG for this list, limit the parallelism of requests in the API to a pool and retrieve the necessary data from the API. Flexibly!
Repository
Airflow has its own backend repository, a database (maybe MySQL or Postgres, we have Postgres) that stores the status of tasks, DAGs, connection settings, global variables, etc., etc. say that the repository in Airflow is very simple (about 20 tables) and convenient if you want to build your own process over it. I remember 100500 tables in the Informatica repository, which had to be consumed for a long time before understanding how to build a query.
Monitoring
Given the simplicity of the repository, you can build yourself a convenient process for monitoring tasks. We use a notebook in Zeppelin, where we look at the status of the tasks:
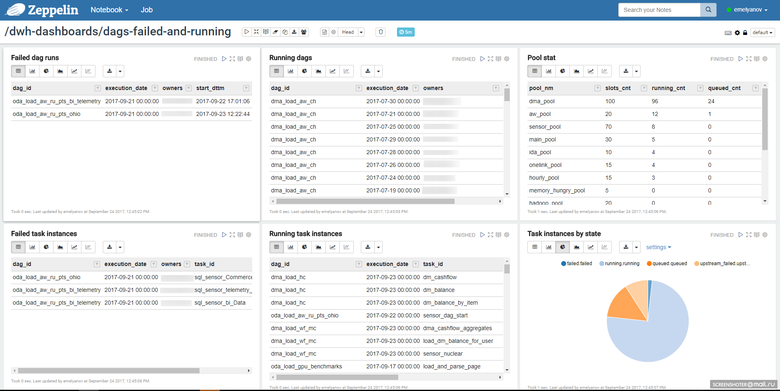
This could be the Airflow web interface itself:
The Airflow code is open, so we added an alert to the Telegram. Each running instance of the task, if an error occurs, spam to the group in Telegram, where the entire development and support team consists.
We get a quick response via Telegram (if such is required), through Zeppelin - a general picture of the tasks in Airflow.
Total
Airflow is primarily open source, and no need to wait for miracles from it. Be prepared to spend time and energy building a working solution. A goal from the category of achievable, believe me, it's worth it. The speed of development, flexibility, ease of adding new processes - you will like it. Of course, you need to pay a lot of attention to the organization of the project, the stability of the Airflow itself: there are no miracles.
Now we have Airflow working out about 6.5 thousand tasks daily. By the nature they are quite different. There are tasks for loading data into the main DWH from many different and very specific sources, there are tasks for calculating windows in the main DWH, there are tasks for publishing data into a fast DWH, there are many, many different tasks - and Airflow chews them all day after day. Speaking in numbers, these are 2.3 thousand ELT tasks of varying complexity within DWH (Hadoop), about 2.5 hundred source databases , this is a team of 4 ETL developers who are divided into ETL data processing in DWH and ELT data processing inside DWH and of course another admin who deals with the infrastructure of the service.
Future plans
The number of processes is inevitably growing, and the main thing we will be doing in terms of the Airflow infrastructure is scaling. We want to build an Airflow cluster, select a pair of legs for Celery workers and make a duplicate of the head with the tasks planning process and repository.
Epilogue
This, of course, is not all that I would like to tell about Airflow, but I tried to highlight the main points. Appetite comes with eating, try it - and you will like it :)
')
Source: https://habr.com/ru/post/339392/
All Articles