How is CatBoost? Interviews with developers

 On the eve of the 2017 SmartData conference, Anna Veronika Dorogush gave a survey interview about the current state of affairs at
On the eve of the 2017 SmartData conference, Anna Veronika Dorogush gave a survey interview about the current state of affairs at CatBoost , a relatively young library for machine learning on gradient boosting. Anna is the head of the group that develops machine learning algorithms in Yandex.The interview discusses a new method of machine learning based on gradient boosting. It was developed in Yandex for solving problems of ranking, prediction and building recommendations. If you are not familiar with this technology, it is recommended to read the announcement on Habré .
- There are several direct competitors for CatBoost: XGBoost, LightGBM, H20, ... Tell us, on what grounds did you realize that it was time to make your own product, and not use existing ones?
')
Anna : Matrixnet was created earlier than the algorithms listed above, besides, it yielded better results than most competitors. And CatBoost is its next version.
- How long did it take to develop CatBoost? Was it a smooth introduction of new ideas, or did you once plan one big CatBoost project and then implement it purposefully? What did it look like?
Anna : Initially it was a pilot project under the leadership of Andrei Gulin, the main task of the project was to figure out how to best work with categorical factors. After all, such factors appear in a natural way, and the gradient boosting did not know how to work with them. At first, Andrey Gulin’s team worked on the project for several years, they checked a huge number of experiments and a lot of hypotheses. As a result, we came to the conclusion that there are several of the best working ideas. Andrey Gulin wrote the first implementation of the CatBoost algorithm, now our team is engaged in the development of this algorithm and is being actively developed.
Biography: Andrey Gulin
He studied applied mathematics and physics at the Moscow Engineering Physics Institute. Since 2000, he played professionally in the games in the Nival company and at the same time created new ones. In 2005, he moved to Yandex and has since been engaged in improving the quality of search. One of the inspirers of the creation and launch of the MatrixNet machine learning algorithm.
He studied applied mathematics and physics at the Moscow Engineering Physics Institute. Since 2000, he played professionally in the games in the Nival company and at the same time created new ones. In 2005, he moved to Yandex and has since been engaged in improving the quality of search. One of the inspirers of the creation and launch of the MatrixNet machine learning algorithm.
- According to benchmarks, you can see an increase in performance from 0.12% to 18%. Is it really that important? Under which application architecture does the gradient boost library library become a bottleneck? In which real-life services of Yandex does this productivity increase play the greatest role?
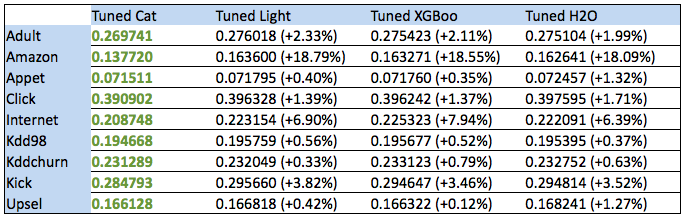
Anna : How big the difference will be is very dependent on the data. In some cases, we are fighting for interest, in some - for fractions of percent, it very much depends on the task.
Is the bottleneck in application speed or quality?
If by quality, then the bottleneck will be boosting if the bottleneck is the accuracy and quality of the prediction. For example, if your application predicts rain, and gradient boosting is used there, then the accuracy of the prediction of the application will directly depend on the accuracy of the model.
If in terms of speed, then the training model may well be a bottleneck. But here you just need to understand how much time you are willing to spend on training.
Another bottleneck in speed boosting, like other models, may be in use. If you need to apply the model very, very quickly, then you need a quick application. CatBoost has just posted a fast application, which largely removes this bottleneck.
- The Amazon benchmark results are most impressive. How does this benchmark differ from the rest, and how did you manage to win this 18 percent?
Anna : It turned out to be important on this dataset to automatically combine different categorical factors with each other, other algorithms do not know how to do this, and CatBoost can do this, so it won very much.
- What makes CatBoost different from other solutions in terms of the theory behind it?
Anna : In this algorithm, there is a more complex processing of categorical features, the ability to use combinations of features, and a scheme for calculating the values in the leaves is different.
- What are some interesting technological chips you used in a specific implementation in a programming language? Maybe some special data structures, algorithms or coding techniques, about the behavior of which in special cases can be described in more detail?
Anna : We have a lot of interesting things in the code. For example, you can look at the feature binarization code . There you will find very nontrivial dynamics, written by Alexey Poyarkov.
- Tell us about any one big problem or problem that arose during the implementation of CatBoost. What was the matter and how did you get out?
Anna : One of the interesting questions is how to count the counters for regression modes. Here, the target contains a lot of information that you want to use effectively.
We decided this way: we tried a lot of things and chose the best-working methods. It is always done this way - you have to try and experiment and in the end choose the best.
- What other projects from the world of machine learning should try to integrate CatBoost? For example, is it possible to combine it with Tensorflow and how exactly? What ligaments have you tried in practice?
Anna : In our tutorials there is an example of sharing Tensorflow and CatBoost for solving a contest on a kaggl in which it is necessary to process texts. In general, this is a very useful practice - using neural networks to generate factors for gradient boosting; in Yandex, this approach is used in many projects, including search.
In addition, we recently implemented integration with TensorBoard , so now the graphs of errors during training can be viewed using this utility.
- Now there are three types of API: Python, R and command line. Do you plan to expand the number of available programming languages and APIs in the near future?
Anna : We do not plan to do the support of new languages ourselves, but we will be very happy if the new wrappers are implemented by people from the open-source community - the project is on GitHub, so anyone can do it.
- Now the Python API looks like several classes:
Pool , CatBoost , CatBoostClassifier , CatBoostRegressor , plus validation and training parameters are described. Will this API be expanded, and if so, what opportunities do you plan to add in the near future? Are there any features that customers really want to get as soon as possible?Anna : Yes, we plan to add new features to the wrapper, but I don’t want to announce them in advance.
Follow the news on our twitter .
- How do you see the development of CatBoost in general?
Anna : We are actively developing the algorithm - we are adding new features to it, new modes, we are actively working on accelerating the application, distributed learning and training on the GPU, we are raising the quality of the algorithm. So CatBoost will still have a lot of changes.
- You will be the speaker at the conference SmartData 2017 . Can you say a few words about your report, what should we expect?
Anna : The report will talk about the basic ideas of the algorithm, as well as what the algorithm has parameters and how to use them correctly.
Source: https://habr.com/ru/post/339384/
All Articles