Generate short texts with limiting conditions - for advertising and other purposes.
In practice, the task is often encountered not just to write some text, but to fulfill certain conditions — for example, to lay maximum keywords at a given length and / or use / not use certain words and phrases. This is important for business (when creating advertisements, including for contextual advertising, for SEO-optimization of sites), for educational purposes (automatic preparation of test questions) and in some other cases. Such optimization tasks cause a lot of headaches, since it is relatively easy for people to write texts, but it is not so easy to write something that meets one or another of the “optimality” criteria. On the other hand, computers do an excellent job with optimization tasks in other areas, but they do not understand natural language well, and therefore it is difficult for them to compose text. In this article, we consider the well-known approaches to solving this problem and share our own experience a little.
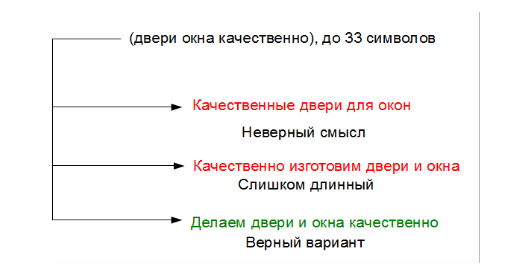
As an example, consider the task of writing a sentence of a given length on a specific subject, which should include a certain number of keywords. Let's say the words “doors, windows, quality, make” are given - you need to make a sentence like “We make windows and doors with high quality!”.
One of the first known approaches to solve this problem is the use of a statistical model of a language. A language model is a distribution function of the probability of finding words in a particular sequence. Those. some function P (S ) - which allows, knowing the sequence of words S , to get the probability P to meet the words in this sequence. Most often, the language model is based on the so-called n-grams, that is, counting the frequency of obtaining word combinations from n words in large arrays of texts. The ratio of the number of occurrences of a given phrase to the number of analyzed phrases gives an approximation of the probability of the given phrase. Since the probabilities of long n-grams are difficult to estimate (some combinations of words may occur very rarely), their probabilities are approximated in one way or another using frequencies of shorter sequences.
')
With reference to our example, if we have, say the word "Qualitatively", then we can use the P (S) function to estimate the probabilities of all possible phrases of the initial keywords "Qualitatively windows", "Qualitatively doors", "Qualitatively manufacture". Most likely the latter will have the highest probability. Therefore, we add the word "make" to our line and repeat the operation, getting in the next step, "Make the windows quality" and then "Make the door windows qualitatively."
Immediately visible cons of this approach. First, he uses words only in the original cases and numbers, and therefore we can’t say that we prefer to use “produce” instead of “produce”. Secondly, there is no possibility to use any other words besides the original ones, therefore, the wrong phrase “window of the door” is obtained. Of course, we can easily allow the use of any words included in the language model, for example, prepositions that will work in this case. But if the key words are only “high-quality windows of the door”, then the prepositions will not help and you will have to carefully select the words that the model can use “from itself”.
There will be other difficulties. For example, in the described approach, the language model does not know anything about the keywords that it can use. Therefore, if the beginning of “Qualitatively manufacture doors for” is generated, then inevitably you will get “Qualitatively manufacture doors for windows”, or if you use matching in the cases “Qualitatively manufacture doors for windows”, which is still meaningless. In part, this can be eliminated, if at each step to save the entire history of opportunities. That is, when the phrase “doors for” was composed, there were other options, including “doors and”. In the absence of a continuation, a “door for” was chosen. But if we have saved the previous versions and completed them too, then we will get several alternatives “doors and windows”, “doors for windows”, “doors under windows” and so on. Of these options, we already choose the most likely - “doors and windows”.
A more complex approach is described, for example, in [1]. Based on the same principle, it takes into account not only the probabilities of n-grams, but additional linguistic information, determining the dependencies between words. Based on the list of keywords, this method searches in a large corpus of texts for the use of these words and, based on the analysis of dependencies, generates rules for their use. Using these rules, candidate texts are created, from which the most plausible options are selected. In addition to the complexity of implementation, the disadvantage of this method is a certain dependence on the language used, which complicates its portability, as well as the fact that it received a patent, the validity of which has not yet expired.
The main efforts in the field of text generators were concentrated mainly on adding more and more linguistic features and hand-created rules, which led to the creation of rather powerful systems, but focused mainly on the English language.
Recently, interest in learning systems of language generation has again increased, which is associated with the advent of neural language models (Neural language models). There are neural network architectures capable of describing the content of pictures, and translating from one language to another. In previous articles, we considered a chat bot on neural networks and a neural generator of product descriptions. It is interesting to see how a neural network generator can solve this specific problem.
As a task, we chose the problem of generating headline ads ads from search queries, which is similar to the example we considered. Taking a set of 15,000 training examples in one subject area, we applied a neural network with the architecture described earlier [2], having trained it to generate new headers. The peculiarities of this architecture is that it can specify the required length of the generated text and keywords as input parameters. For verification, we generated 200 headings and estimated how many of them turned out to be qualitative:
The first results were quite modest:
Total got 64% of usable headers. Of the unsuitable 5% exceeded the desired length, 10% contained grammatical errors, and the rest changed the meaning using similar, but different words.
After that, we introduced a number of modifications into the system and changed the neural network architecture. The key factor for a good result is the ability to copy words from the source text to the target [3]. This is significant, since on a small sample of several tens of thousands of texts (instead of millions of sentences, such as, for example, in machine translation), the system cannot learn a lot of words.
A few examples:
Thus, suitable for use of headings became 89%, at the same time the headings which are generally distorting sense were gone. Considering that among the headers compiled by people, the number of “ideal” reaches 68-77%, depending on the person’s qualifications, degree of tiredness, etc., it can be said that the possibilities of automatic generation make up about 80% of the person’s capabilities. This is pretty good, and opens the way to practical applications of such systems, especially since the possibilities for improvement are far from exhausted.
Literature
1. Uchimoto, Kiyotaka, Hitoshi Isahara, and Satoshi Sekine. "Text generation from keywords." Proceedings of the 19th International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2002.
2. Tarasov DS (2015) Neural Networks' Natural Language Generation, Paraphrasing and Summarization of User Reviews // Computational Linguistics and Intellectual Technologies: “International Dialogue”, Issue 14 (21), pp. 571-579
3. Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. "Pointer networks." Advances in Neural Information Processing Systems. 2015
As an example, consider the task of writing a sentence of a given length on a specific subject, which should include a certain number of keywords. Let's say the words “doors, windows, quality, make” are given - you need to make a sentence like “We make windows and doors with high quality!”.
One of the first known approaches to solve this problem is the use of a statistical model of a language. A language model is a distribution function of the probability of finding words in a particular sequence. Those. some function P (S ) - which allows, knowing the sequence of words S , to get the probability P to meet the words in this sequence. Most often, the language model is based on the so-called n-grams, that is, counting the frequency of obtaining word combinations from n words in large arrays of texts. The ratio of the number of occurrences of a given phrase to the number of analyzed phrases gives an approximation of the probability of the given phrase. Since the probabilities of long n-grams are difficult to estimate (some combinations of words may occur very rarely), their probabilities are approximated in one way or another using frequencies of shorter sequences.
')
With reference to our example, if we have, say the word "Qualitatively", then we can use the P (S) function to estimate the probabilities of all possible phrases of the initial keywords "Qualitatively windows", "Qualitatively doors", "Qualitatively manufacture". Most likely the latter will have the highest probability. Therefore, we add the word "make" to our line and repeat the operation, getting in the next step, "Make the windows quality" and then "Make the door windows qualitatively."
Immediately visible cons of this approach. First, he uses words only in the original cases and numbers, and therefore we can’t say that we prefer to use “produce” instead of “produce”. Secondly, there is no possibility to use any other words besides the original ones, therefore, the wrong phrase “window of the door” is obtained. Of course, we can easily allow the use of any words included in the language model, for example, prepositions that will work in this case. But if the key words are only “high-quality windows of the door”, then the prepositions will not help and you will have to carefully select the words that the model can use “from itself”.
There will be other difficulties. For example, in the described approach, the language model does not know anything about the keywords that it can use. Therefore, if the beginning of “Qualitatively manufacture doors for” is generated, then inevitably you will get “Qualitatively manufacture doors for windows”, or if you use matching in the cases “Qualitatively manufacture doors for windows”, which is still meaningless. In part, this can be eliminated, if at each step to save the entire history of opportunities. That is, when the phrase “doors for” was composed, there were other options, including “doors and”. In the absence of a continuation, a “door for” was chosen. But if we have saved the previous versions and completed them too, then we will get several alternatives “doors and windows”, “doors for windows”, “doors under windows” and so on. Of these options, we already choose the most likely - “doors and windows”.
A more complex approach is described, for example, in [1]. Based on the same principle, it takes into account not only the probabilities of n-grams, but additional linguistic information, determining the dependencies between words. Based on the list of keywords, this method searches in a large corpus of texts for the use of these words and, based on the analysis of dependencies, generates rules for their use. Using these rules, candidate texts are created, from which the most plausible options are selected. In addition to the complexity of implementation, the disadvantage of this method is a certain dependence on the language used, which complicates its portability, as well as the fact that it received a patent, the validity of which has not yet expired.
The main efforts in the field of text generators were concentrated mainly on adding more and more linguistic features and hand-created rules, which led to the creation of rather powerful systems, but focused mainly on the English language.
Recently, interest in learning systems of language generation has again increased, which is associated with the advent of neural language models (Neural language models). There are neural network architectures capable of describing the content of pictures, and translating from one language to another. In previous articles, we considered a chat bot on neural networks and a neural generator of product descriptions. It is interesting to see how a neural network generator can solve this specific problem.
Our results
As a task, we chose the problem of generating headline ads ads from search queries, which is similar to the example we considered. Taking a set of 15,000 training examples in one subject area, we applied a neural network with the architecture described earlier [2], having trained it to generate new headers. The peculiarities of this architecture is that it can specify the required length of the generated text and keywords as input parameters. For verification, we generated 200 headings and estimated how many of them turned out to be qualitative:
The first results were quite modest:
| Result | Percentage of headings received |
| Ideal headers | 34% |
| Good headlines | 31% |
| Bad headers | 36% |
Total got 64% of usable headers. Of the unsuitable 5% exceeded the desired length, 10% contained grammatical errors, and the rest changed the meaning using similar, but different words.
After that, we introduced a number of modifications into the system and changed the neural network architecture. The key factor for a good result is the ability to copy words from the source text to the target [3]. This is significant, since on a small sample of several tens of thousands of texts (instead of millions of sentences, such as, for example, in machine translation), the system cannot learn a lot of words.
| Result | Percentage of headings received |
| Ideal headers | 60% |
| Good headlines | 29% |
| Bad headers | eleven% |
A few examples:
| Keywords | Text |
| wholesale supplies of toys in china | Wholesale toy from China. Discounts |
| toy talking ferb reviews | talking toy, where to buy? |
| child mats | educational mats for children |
| dolls monster high house overview | all doll houses video reviews |
Thus, suitable for use of headings became 89%, at the same time the headings which are generally distorting sense were gone. Considering that among the headers compiled by people, the number of “ideal” reaches 68-77%, depending on the person’s qualifications, degree of tiredness, etc., it can be said that the possibilities of automatic generation make up about 80% of the person’s capabilities. This is pretty good, and opens the way to practical applications of such systems, especially since the possibilities for improvement are far from exhausted.
Literature
1. Uchimoto, Kiyotaka, Hitoshi Isahara, and Satoshi Sekine. "Text generation from keywords." Proceedings of the 19th International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2002.
2. Tarasov DS (2015) Neural Networks' Natural Language Generation, Paraphrasing and Summarization of User Reviews // Computational Linguistics and Intellectual Technologies: “International Dialogue”, Issue 14 (21), pp. 571-579
3. Vinyals, Oriol, Meire Fortunato, and Navdeep Jaitly. "Pointer networks." Advances in Neural Information Processing Systems. 2015
Source: https://habr.com/ru/post/339240/
All Articles