Heading "We read articles for you." September 2017

Hi, Habr! We continue our tradition and again release a monthly set of reviews of scientific articles from members of the Open Data Science community from the channel #article_essense. Want to get them before everyone else - join the ODS community!
Articles are selected either from personal interest, or because of the proximity to the ongoing competition. We remind you that the descriptions of the articles are given without changes and in the form in which the authors posted them in the #article_essence channel. If you want to offer your article or you have any suggestions - just write in the comments and we will try to take everything into account in the future.
Articles for today:
- Machine Learning: An Applied Econometric Approach
- Squeeze-and-Excitation Networks
- Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
- Training RNNs as Fast as CNNs
- Transforming auto-encoders
- A Relatively Small Turing Machine
- Britlecone pine Pinus longaeva analysis of telomere length of life
- Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-experts Layer
- The Consciousness Prior
1. Machine Learning: An Applied Econometric Approach
→ Original article
Posted by: dr_no
Introduction
About the importance of ML, etc. etc., there are links to publications about intro in ML, Big Data and economics, LASSO from the point of view of econometrics and data of high dimensions. About the difference and the connection parameter estimation vs prediction in regression problems.
How Machine Learning Works
Setting the task of supervised machine learning, comparing the work of the method of least squares, regression tree (regression tree), LASSO, random forest (out of 700 trees), about overfit / crossvalidation / kfoldy.
Evaluation of the results of the work of different approaches: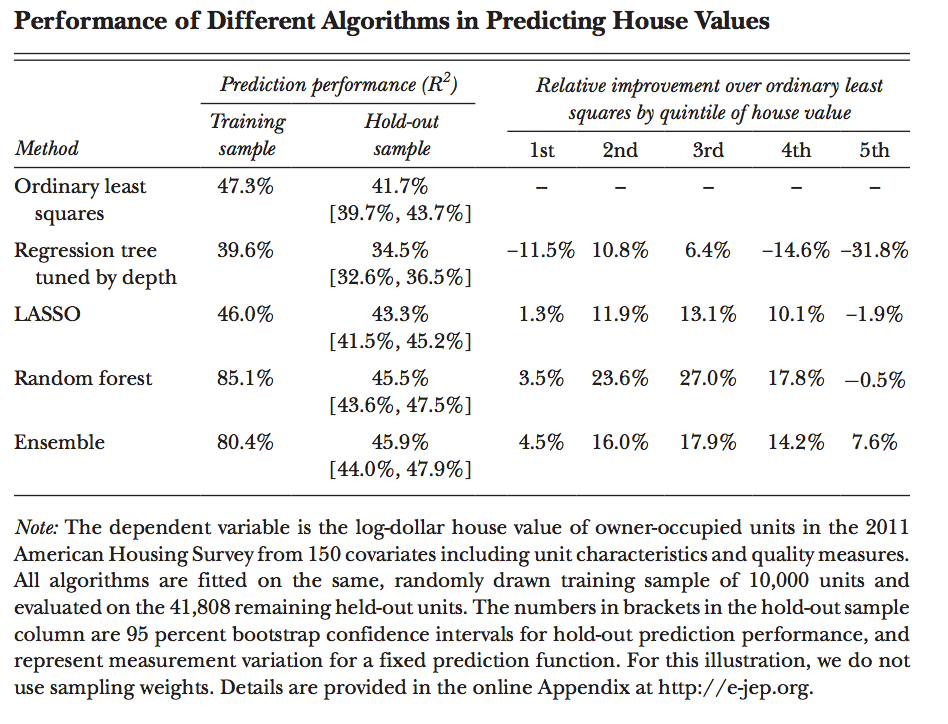
Then they follow the idea of regularization, an empirical twist of model parameters.
Further about the application to economic problems:
0) model selection;
1) preparation / transformation of data;
2) the importance of derived features (the ratio of the area to the number of rooms, etc) provided regularization, difficulty in calculating a large number of similar, and so on;
3) tuning, here the idea is brought that econometrics can help, on the one hand, helping to do design choices (number of folds, type of prediction function), and on the other - helping to determine the final quality of predictions matching (second, given the prediction function, it It will be possible to make it possible for us to make a statement;
What Do We (Not) Learn from Machine Learning Output
About the senselessness of attempts to find patterns of the modeled process on the basis of the prediction function. If in predicting the price at home, the variable N not involved, does this mean that this factor is not important? Such conclusions are incorrect.
The problem with such conclusions is the absence of standard error coefficients. Even with a model that results in a linear function, this is a problem, because the reason may lie in the very choice of model.
Another example of a similar problem is the re-construction of 10 models of the same source (LASSO predictor) with comparing the quality on a subset of the source data.
The reason for the above is the correlation, interchangeability of features; the final choice depends on the data. Further, it is stated that in the traditional approach, correlation in the observed values would be reflected in a large standard error of prescribing the final effect of a variable.
In ML, we can get a huge number of different functions and different coefficients will give a comparable quality of predictions. Regularization only adds fuel to the fire, forcing us to choose less complex, and therefore more incorrect models, leading to systematic errors omitted variables (omitted variable bias).
Still, sometimes models can provide food for thought about the nature of simulated things.
Well, and then many inspirational speeches on the use of ML, Big Data, satellite imagery to solve absolutely seemingly unrelated tasks (lighting at night and economic indicators), similar tasks are given in other applied areas, conclusions to them. For example, the task of the judge’s decision: after the arrest, the judge must decide whether the defendant will wait for the hearing at home or behind bars.
Doubtful thoughts on the topic of supervised ML in terms of benefits for econometricians. From what you liked:
1) The resulting weights and the resultant function are not particularly talking about the underlying problem;
2) Summary table of models and regularization;
3) Some references;
4) The fact of choice "behind bars / home" by the judge.
I would not particularly advise reading, but if you have someone from an econometrician surrounded by someone who does not see the value in ML, you could give him this article.
2. Squeeze-and-Excitation Networks (ImageNet 2017 Winner)
→ Original article
Posted by: kostia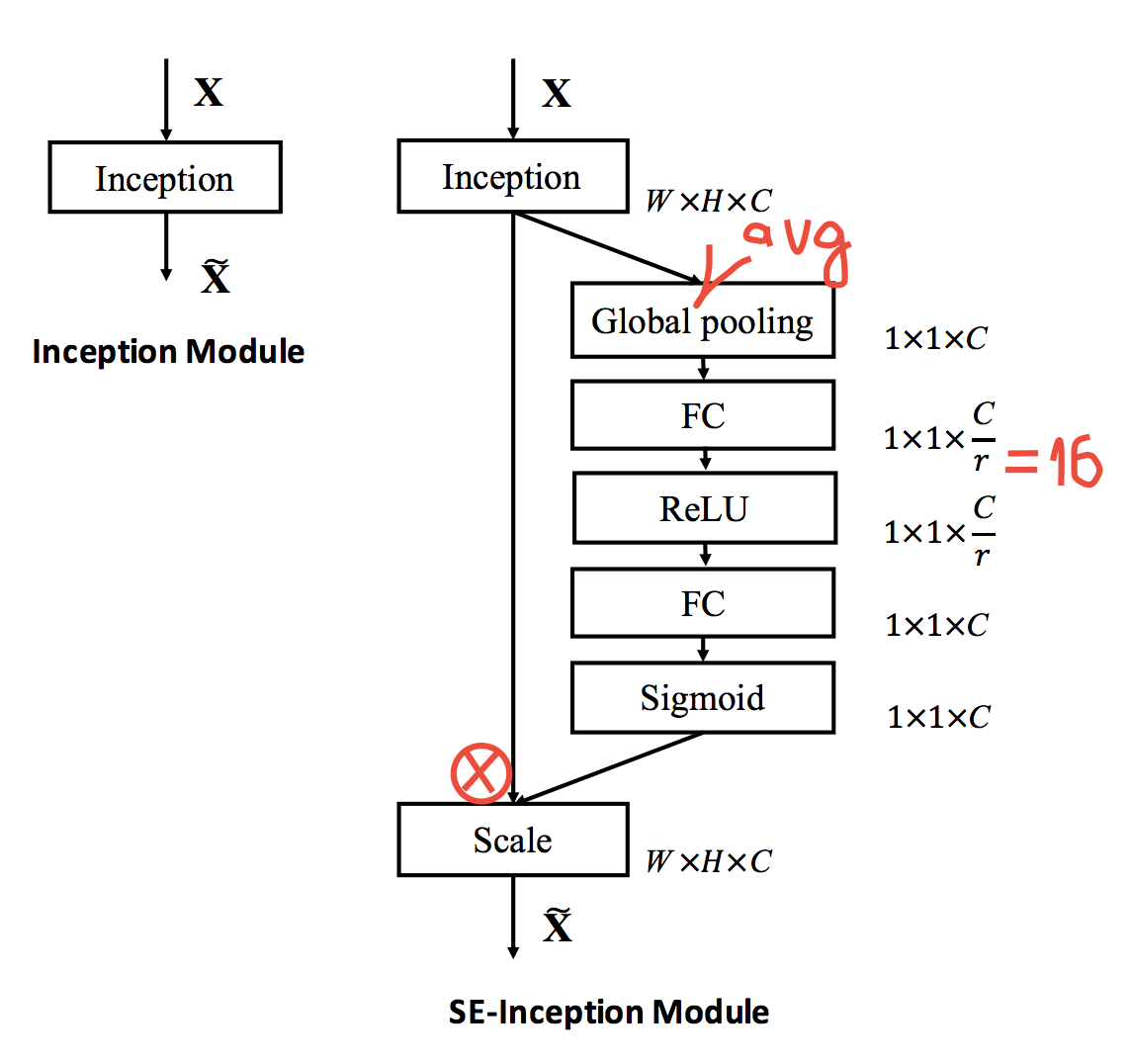
In our favorite ResNet, Inception, etc. you can add the SE Module and improve accuracy: for example, the new top5 on ImageNet is 2.25% after 2.99% last year, and for ResNet50 it is 6.6% instead of 7.5%, i.e. almost like ResNet100 with minimal overhead flops and about 10% overhead over time.
The module is very simple, inserted after the convolution block into all SoTA architectures and produces, in fact, gating channels. More in detail, how it works, is shown in the figure: we do global average pooling, then blottleneck with a ReLU, and then gating through sigmoid. The intuition is to explicitly model the dependencies between the channels and recalibrate them.
Even in the article there is an empirical analysis of the work of the module: on the lower layers it does something the same for all classes, and closer to the exit, for different classes it is different.
3. Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
→ Original article
Posted by: asobolev
It will be about variational autoencoders for text, which helps, for example, in unsupervised mode to find good features. However, if you make such a VAE naively, that is, using the RNN encoder and the RNN decoder, many authors report on learning difficulties. In fact, the problem is that RNN is already a rather powerful model in and of itself able to model a language model without additional information, and recurring networks model just such distributions.
Accordingly, since ordinary RNN decoders are so powerful, let's replace them with something simpler. With such "something simpler" authors chose "holey convolutions" (dilated convolutions, whose debut occurred in the article about WaveNet, as I understand it, not to be confused with strided convolutions, see here ). As I understand it, the reason for this choice is that even a relatively shallow decoder will have a fairly wide scope, i.e. be able to simulate quite extensive local dependencies. It is expected, by increasing the depth of such a decoder, we will increase its power.
The authors consider not only the VAE itself, but also semi-supervised learning based on it. In addition, such a model can think of class labels, so it is natural to use it for clustering, which the authors do.
Experiments: the usual LSTM was taken as an encoder, and the LSTM baseline and 4 convolution-holey decoders of different depths were taken as a decoder: small , medium , large and very large (with visibility areas of 16, 63, 125 and 187, respectively). LSTM Baseline turned out to have a good perplexity on the language modeling task (on the responses of Yelp and Yahoo responses), but he ignored the hidden code. In general, the pattern is visible: the smaller (and weaker) a decoder, the more actively it uses hidden code, but the more difficult it is for it to learn a good language model. The optimal decoder turned out to be a big convoluted and full of holes, and a very large one worked worse and ignored the code.
Actually, why all this was done: I want to have a good hidden representation (code) that would be useful in other tasks. To begin with, the authors make it two-dimensional and show how topics that are in a cluster automatically cluster. Then semi-supervised learning begins, when the authors on a ridiculous number of marked examples (from 100 to 2000) quite successfully (relative to existing methods, there was no comparison with learning from scratch) have trained a supervised model for classification into 5 or 10 classes.
In addition, at the very end there is a small example of how the inclusion of information about class labels in a model helps to ultimately generate (VAE the same generative model!) Samples, conditioned on this very class.
Extra thoughts :
- The result that the decoder should not be very strong, but also not very weak, in my opinion, is very reasonable: the text has some "high-level idea" that we would like to capture with hidden code, and we would not like to model the syntactic fluctuations therefore, small decoders, though they actively use the code, may be shoving any nonsense there (this assumption, of course, needs experimental verification);
- Little was said about conditional generation;
- The results on semi-supervised training look good in comparison with similar methods, but it is interesting to look at what numbers can be achieved on the same dataset with full marking;
- Even a small convoluted-holey decoder had a fairly large scope. Perhaps he did not have enough deep capacity, experiments on this topic would not hurt either.
4. Training RNNs as Fast as CNNs
→ Original article
Code
Posted by: gsoul
They delivered the SRU (Simple Recurrent Unit) - removed the dependency on h_ (t-1) and made the recurrent networks parallelizable. They write that there is no loss in quality, and the speed at the same time increases by 5-10 times and is comparable with ultra-precise networks. Moreover, in many cases, the results are shown better than those of LSTM analogs, and tested it on a fairly wide range of tasks: text comprehension, language modeling, machine translation, speech recognition.
The whole essence of the article in this picture:

Another rather significant conclusion is that for machine translation they were able to streak 10 layers of SRU with no visible overfit tendencies. And here we must take into account that in machine translation, the layers of the encoder and decoder are usually considered symmetrical, i.e. In fact, this is 20 layers of recurrent networks, which is ogogo. For comparison, mere mortals for machine translation build models on 4 + 4 layers. Google, at the end of 2016 - beginning of 2017, wrote that they more or less successfully train 6 + 6 layers, and for their sales, at that time, they made 8 + 8 layers, but it was almost impossible to train, despite the fact that 16 layers laid out on 8 hcp.
PS At the same time, BLEU En-> De somehow didn’t come out very well for them, perhaps because of the short training time.
5. Transforming Auto-encoders
→ Original article
Posted by: yane123
It will be about a new type of network architecture for working with images. Hinton and Co. believe that if we are talking about working with images, then the future is unlikely for convolutional networks. And that it is possible to obtain a more convenient representation of the invariants in the data, if we abandon the convolutions in favor of the capsules.
The purpose of each capsule in the network is to learn to recognize a certain entity in the whole range of transformations available for observation (for example, displacements). A capsule is a small neural network consisting of a recognizer, a generative part and a hidden layer. What is in the hidden layer is interpreted as the output value of the capsule (which goes to the superior capsules), and it consists of two things:
- The probability that the essence of X is present in the picture. It is also the “degree of recognition” of the essence of X capsule.
- “Instance parameters” of a specific instance of entity X.
The generative part of the capsule generates exclusively by these parameters of instantiation. The result of the generation is then multiplied by the degree of confidence of the capsule. If it is zero, then the contribution of the capsule to the final reconstruction will also be zero.
Model interpretation : if all possible guises of a certain invariant X are laid on a manifold, then the “degree of recognition” at the output of the capsule will not depend on which point on the manifold corresponds to the given instance. A high degree of recognition will speak only about the fact of falling into the desired variety. But the instantiation parameters already depend on the position of the object inside the manifold.
It's like in OOP: if capsule A is activated with a high degree of confidence, then an A class object is most likely present on the stage. If we assume that it is really there, then the output of A capsule is its parameters.
In the simplest case, these parameters can be a pair of numbers, interpreted as the coordinates of the object in the 2D picture. In a bit more complicated, it can be a transformation matrix that will be applied to the “canonical” representation of the recognized entity. In short, here you can show imagination.
The question remains how to organize the training of these capsules so that they begin to work in such an "OOP-method". The article shows that this is achieved when training capsules on pairs of images. In this case, the second image is a transformation of the first (for example, a shift), and the network itself has access to information about the transformation (for example, where and how far they have moved). Here, like a brain with its saccades.
Using the described learning approach, you can force the capsules to construct a representation of any such image properties that we can manage. The article describes a pair of capsule experiments and draws on their acquired specializations.
My personal resume : cool! highly.
6. A Relatively Small Turing Machine Set.
→ Original article
Posted by: kt
Reference article for fans of ruthlessly abstract and pretty little stupid departments of theoretical computer-sensation, with an adorable flair of engineering.
In this paper, the authors set themselves the goal of building a Turing machine that would stop only if the axiomatics of Zermelo – Frankel set theory with the axiom of choice (that is, ZFC — what underlies all of our mathematics) is controversial. As we know, thanks to Gödel, that using the rules of ZFC, it is impossible to prove or disprove the inconsistency of the rules of ZFC, it will be impossible to prove or disprove that the corresponding program works endlessly, which is cool.
The simplest program of the required type is one that simply lists in order all possible conclusions from ZFC and stops when it finds a contradiction (for example, 1 = 0). However, in the form of a Turing machine, such a program would be too complicated, but I would like something simpler. For this, the authors used several tricks, in particular:
There is a certain "Friedman's lemma" of the form "for any k, n, p, graph on the subsets of rational numbers of blabla contains blabla", which, as Friedman proved, is equivalent to the consistency of ZFC. Therefore, instead of iterating over all the theorems of ZFC, you can iterate through all the graphs of the desired type until you find the “bad” one, which is much simpler.
- On good, the "program" in the Turing machine is its state, and the "tape" is needed for intermediate calculations. Pushing the program into states, however, quickly multiplies their number, which is ugly. It is more beautiful to write the program code on the tape, and in states to write a kind of "universal interpreter" of this code. Those. the total Turing machine first writes its code on the tape, and then executes it. In terms of the number of required states, it turns out shorter.
To implement this beauty, the authors implemented two special languages: TMD, for a convenient description of Turing machines (from which you can compile the actual machine), and Laconic, a high-level C-like language that compiles into TMD.
As a result, they obtained the required Turing machine from 7918 states. Then they suffered, and they made a Turing machine to prove the hypotheses of Goldbach (4888 states) and Riemann (5372 states).
One of the fun results of this result is the following. Let BB (k) be the maximum finite number of steps that a Turing machine can do with k states (the so-called busy beaver function). In this case, BB (7918) (as well as BB (k) for any k> = 7918) is an incomputable number (its value cannot be proved or disproved from ZFC).
7. Bristlecone pine Pinus longaeva Analysis of telomere length of life
→ Original article
Posted by: kt
As far as we know, during division, cells lose some of their DNA (telomeres), which provides so-called cell aging. Some cells (embryonic, cancerous) have a special protein against this - telomerase, which restores telomeres and gives cells eternal life.
An interesting question is what happens in the trees, because some of them can live for hundreds and thousands of years, while their growth mainly occurs in the area of meristems (ie, as if "embryonic" cells). If the authors of the article are to be believed, there was no particular clarity on the issue of cellular aging of plants for 2005 (and, as I personally made for myself, the article did not bring any more clarity).
The authors took samples of needles, wood and roots from trees of six different species of different ages, measured the distribution of telomere lengths and telomerase activity in them, and gave corresponding graphs of the dependence of these indicators on the tree species ("long-lived", "srednegivushchie", "low-lived") and age within one species (some kind of pine).
The authors saw that the lengths of the longest telomeres and telomerase activity seem to be on average longer in long-lived trees, but the authors do not show statistical significance, so maybe there is not much of it (the sample size is measured in dozens of points). Moreover, within the framework of one species, it seems that the length of telomeres in roots grows with age, and telomerase activity is generally as if cyclical (with a cycle length of about 1000 years). In short, in fact, nifiga is not clear except that telomerase does work.
8. Outrageously Large Neural Networks: The Sparsely-gated Mixture-of-experts Layer
→ Original article
Posted by: yane123
Motivation
If a model is faced with the task of learning a complex subject area, then the model should have many parameters. The network should be big. Activating the entire large network on each clock is expensive. It would be desirable, that at each moment of time only its separate sections worked (trained) (conditional computation).
Model
The authors proposed a new type of layer - a mixture of experts under a sparse gateway. The bottom line: there is a neural network gateway that works as a manager and decides which experts within its jurisdiction will process current data. The experts are simple neural networks of direct distribution. There are a lot of them (thousands), but at each moment the manager selects only a few of them. Both the gateway and the experts are trained together in reverse propagation.
At the output, the gateway outputs a vector of length n, where n is the number of experts. Gateway activation function - softmax with a couple of additions: noise and sparseness. The sparseness is set simply - in the vector, k of the brightest cells are selected, and the rest are forcibly set to minus infinity (so that the softmax on them would later give zero, and this would mean not using an expert on this task).
Difficulties
One of the difficulties is that the more experts, the less part of the batch, which will be on each expert. It is impossible to increase the batch to infinity, because memory size is limited, and the authors had to look for other approaches.
Another subtle point is load balancing between experts. In practice, it turned out that the network is prone to stupor a steady state in which the gateway constantly selects the same experts, and others do not have the opportunity to learn. The authors solved the problem by adding a couple of fines to this cost function. For each expert, it was calculated how much he was required by the gateway when calculating this batch. The penalty pushes all experts to have equal demand. The construction of a smooth fine is devoted to the appendix.
Another point: the initialization of the scales. Soft restrictions (like the mentioned penalty for uneven load on experts) do not work immediately, and the simplest way to avoid instantly stalling the network in the mode “I choose the same” is to initialize the gateway weights equally.
Result
Testing was conducted on tasks for working with text (1 Billion Words Benchmark and machine translation). It is said to work comparable with the best methods.
9. The Consciousness Prior
- 4 RL- / (disentangled) , conscious ( 41 ! ! , !)
, .. , (, ), .. (conscious state), (sparse attention) , , . , , (, , , ).
, s_t ( RL) RNN' ( ), h_t — , .
, c_t : C(h_t, c_{t-1}, z_t) , h_t , c_{t-1} , (exploration).
, - . , , , t - c_t , k h_{t+k} . V(h_t, c_{tk}) , . , — .
( 100+ ?), , .
')
Source: https://habr.com/ru/post/339094/
All Articles