Optimizing TensorFlow on modern Intel architectures
TensorFlow is a modern platform for deep learning and machine learning, making it possible to extract maximum performance from Intel hardware. This article will introduce the artificial intelligence (AI) development community to TensorFlow optimization techniques for platforms based on Intel Xeon and Intel Xeon Phi processors. These techniques were created as a result of close collaboration between Intel and Google. Representatives of both corporations announced this collaboration at the first Intel AI Day conference last year.

We describe the various performance problems that we encountered in the optimization process, and the decisions we made. Also indicated is the level of performance improvement for a sample of common neural network models. The adopted optimization techniques make it possible to increase productivity by several orders of magnitude. For example, our measurements recorded a performance increase of 70 times for training and 85 times for influencing Intel Xeon Phi 7250 (KNL) processors. Platforms based on Intel Xeon E5 v4 (BDW) and Intel Xeon Phi 7250 processors are the main new generation of Intel solutions. In particular, we should expect increased performance of Intel Xeon (Skylake) and Xeon Phi (Knights Mill) processors, which will be released later this year.
When optimizing the performance of models of deep learning on modern CPUs, a number of problems arise that are quite close to the problems of optimizing other resource-intensive applications in the field of high-performance computing.
')
Intel has developed a number of optimized depth learning primitives for these tasks that can be used in various depth learning platforms to effectively implement common off-the-shelf components. These ready-made components, in addition to matrix multiplication and convolution, support the following possibilities.
For more information about optimized primitives of the Intel Math Kernel Library for deep neural networks (Intel MKL-DNN), see this article.
TensorFlow implements optimized versions of operations that use Intel MKL-DNN primitives in all possible cases. This is required to take advantage of performance scaling on Intel architecture platforms. In addition, other optimization techniques have been implemented. In particular, for performance reasons, Intel MKL uses a different format than the default format in TensorFlow. It was necessary to minimize the costs of converting from one format to another. It was also necessary to take care that TensorFlow users did not have to redo existing neural network models in order to take advantage of optimized algorithms.
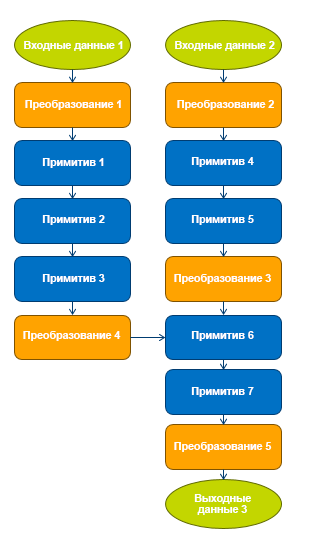
We implemented a number of graph optimization methods.
These optimization measures allow for better performance without increasing the burden on TensorFlow programmers. To optimize performance, data format optimization is paramount. TensorFlow's own format is often not the most efficient for processing certain operations on the CPU. In such cases, we insert the conversion of data from the TensorFlow format to the internal format, perform the operation on the CPU, then convert the data back to the TensorFlow format. Such transformations lead to performance costs, they should be avoided. When optimizing the data format, subgraphs are defined that can be entirely performed using operations optimized for Intel MKL, and format conversion within subgraphs is excluded. Automatically inserted conversion nodes do data format conversion at the boundaries of subgraphs. Another useful optimization method is a merge pass, which automatically combines operations that can be efficiently performed in a single Intel MKL operation.
We also configured a number of components of the TensorFlow platform to achieve the highest CPU performance for different depth learning models. Based on the existing pool allocator in TensorFlow, we created our own private allocator. It works in such a way that TensorFlow and Intel MKL share the same memory pools (using the imalloc functionality in Intel MKL), and the memory is not returned to the operating system too early. This allows you to avoid performance degradation when you “miss” past memory pages and when clearing memory pages. In addition, we have carefully configured multi-threaded management libraries (pthreads in TensorFlow and OpenMP in Intel MKL) so that they can work together and not fight with each other for CPU resources.
These optimization measures have dramatically improved performance on platforms with Intel Xeon and Intel Xeon Phi processors. To demonstrate the performance gains, we describe our most well-known methods, as well as performance indicators with basic and optimized settings for three common ConvNet tests .
The following parameters are important for the performance of Intel Xeon (Broadwell) and Intel Xeon Phi (Knights Landing) processors. We recommend configuring them according to your specific neural network model and platform used. We carefully set up these parameters to achieve the best results for the convnet tests on Intel Xeon and Intel Xeon Phi processors.
Sample Settings for Intel Xeon Processor
(Broadwell family, 2 physical processors, 22 cores)

Sample Settings for Intel Xeon Phi Processor
(Knights Landing family, 68 cores)

Performance results on the Intel Xeon processor
(Broadwell family, 2 physical processors, 22 cores)
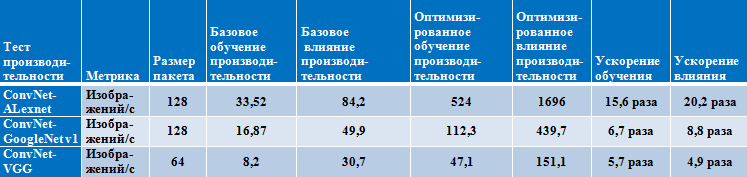
Performance results on Intel Xeon Phi processor
(Knights Landing family, 68 cores)

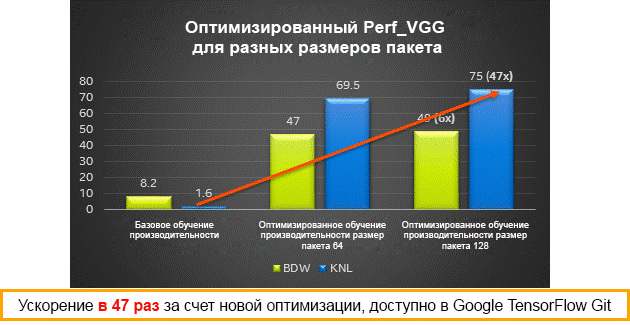
Performance results for various packet sizes on Intel Xeon (Broadwell) and Intel Xeon Phi (Knights Landing) processors - training
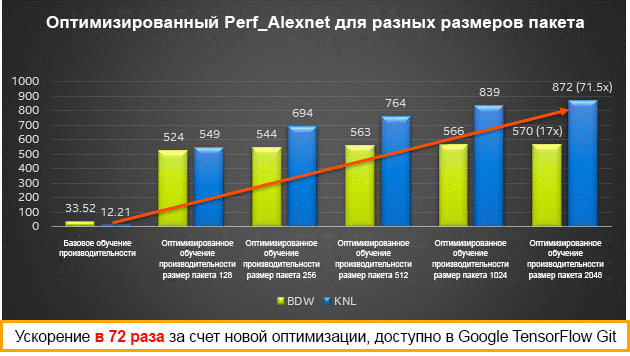
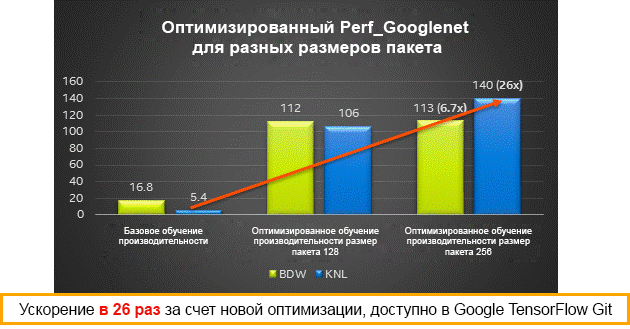
You can either install prebuilt binary packages using pip or conda according to the instructions in the Available Intel-optimized wheel TensorFlow package, or you can build the packages yourself from the source code using the instructions below.
Optimizing TensorFlow means that depth learning solutions built on this widely available and widely used platform are now much faster on Intel processors; increased flexibility, availability and scale of such solutions. The performance of Intel Xeon Phi processors, for example, scales almost linearly with the addition of cores and nodes, which can dramatically reduce training time for machine learning models. Increasing the performance of TensorFlow while increasing the performance of Intel processors will enable the processing of larger and more complex loads of AI.
Collaboration between Intel and Google to optimize TensorFlow is organized in the course of continuous activity aimed at increasing the availability of AI for data developers and researchers, to realize the possibility of launching AI applications, where they are needed, on any devices and in any environment, from user devices to of clouds. Intel experts believe that higher availability of AI is the most important factor for creating models and algorithms of AI of a new generation that can solve the most pressing problems of business, science, technology, medicine and society.
During the collaboration, we have already managed to dramatically improve performance on platforms with Intel Xeon and Intel Xeon Phi processors. The code with improved algorithms is available in the TensorFlow repository of Google Inc. in GitHub . We ask developers from the AI community to try these optimization measures and share their feedback.
We describe the various performance problems that we encountered in the optimization process, and the decisions we made. Also indicated is the level of performance improvement for a sample of common neural network models. The adopted optimization techniques make it possible to increase productivity by several orders of magnitude. For example, our measurements recorded a performance increase of 70 times for training and 85 times for influencing Intel Xeon Phi 7250 (KNL) processors. Platforms based on Intel Xeon E5 v4 (BDW) and Intel Xeon Phi 7250 processors are the main new generation of Intel solutions. In particular, we should expect increased performance of Intel Xeon (Skylake) and Xeon Phi (Knights Mill) processors, which will be released later this year.
When optimizing the performance of models of deep learning on modern CPUs, a number of problems arise that are quite close to the problems of optimizing other resource-intensive applications in the field of high-performance computing.
')
- When processing the code, it is necessary to use modern vector instructions. This means that all basic primitives, such as convolution, matrix multiplication, and packet normalization, are processed into vector code using the latest version (AVX2 for Intel Xeon processors and AVX512 for Intel Xeon Phi processors).
- To achieve the highest performance, it is important to pay special attention to the efficiency of using all available cores. For this, it is necessary to consider both parallelization within a given level, and work and parallelization between different levels.
- Data should always be available (if possible) when it is needed by executable blocks. This means that it is necessary to balance the use of technologies of prefetch, blocking the cache and data formats that ensure the locality of data both in space and in time.
Intel has developed a number of optimized depth learning primitives for these tasks that can be used in various depth learning platforms to effectively implement common off-the-shelf components. These ready-made components, in addition to matrix multiplication and convolution, support the following possibilities.
- Direct packet convolution
- Inner work
- Survey: maximum, minimum, average
- Normalization: normalization of local response by channels (LRN), packet normalization
- Activation: linear rectification unit (ReLU)
- Data manipulation: multidimensional transposition (transformation), separation, coupling, summation, conversion
For more information about optimized primitives of the Intel Math Kernel Library for deep neural networks (Intel MKL-DNN), see this article.
TensorFlow implements optimized versions of operations that use Intel MKL-DNN primitives in all possible cases. This is required to take advantage of performance scaling on Intel architecture platforms. In addition, other optimization techniques have been implemented. In particular, for performance reasons, Intel MKL uses a different format than the default format in TensorFlow. It was necessary to minimize the costs of converting from one format to another. It was also necessary to take care that TensorFlow users did not have to redo existing neural network models in order to take advantage of optimized algorithms.
Graph optimization
We implemented a number of graph optimization methods.
- Replacing TensorFlow default operations with optimized versions of Intel when running on a CPU. Thanks to this, users can run existing Python programs with enhanced performance without changing the neural network model.
- Eliminate unnecessary and resource-intensive data format conversion.
- Combine multiple operations together for more efficient use of the CPU cache.
- Processing intermediate states for accelerated backward propagation.
These optimization measures allow for better performance without increasing the burden on TensorFlow programmers. To optimize performance, data format optimization is paramount. TensorFlow's own format is often not the most efficient for processing certain operations on the CPU. In such cases, we insert the conversion of data from the TensorFlow format to the internal format, perform the operation on the CPU, then convert the data back to the TensorFlow format. Such transformations lead to performance costs, they should be avoided. When optimizing the data format, subgraphs are defined that can be entirely performed using operations optimized for Intel MKL, and format conversion within subgraphs is excluded. Automatically inserted conversion nodes do data format conversion at the boundaries of subgraphs. Another useful optimization method is a merge pass, which automatically combines operations that can be efficiently performed in a single Intel MKL operation.
Other optimization algorithms
We also configured a number of components of the TensorFlow platform to achieve the highest CPU performance for different depth learning models. Based on the existing pool allocator in TensorFlow, we created our own private allocator. It works in such a way that TensorFlow and Intel MKL share the same memory pools (using the imalloc functionality in Intel MKL), and the memory is not returned to the operating system too early. This allows you to avoid performance degradation when you “miss” past memory pages and when clearing memory pages. In addition, we have carefully configured multi-threaded management libraries (pthreads in TensorFlow and OpenMP in Intel MKL) so that they can work together and not fight with each other for CPU resources.
Experiments and performance evaluation
These optimization measures have dramatically improved performance on platforms with Intel Xeon and Intel Xeon Phi processors. To demonstrate the performance gains, we describe our most well-known methods, as well as performance indicators with basic and optimized settings for three common ConvNet tests .
The following parameters are important for the performance of Intel Xeon (Broadwell) and Intel Xeon Phi (Knights Landing) processors. We recommend configuring them according to your specific neural network model and platform used. We carefully set up these parameters to achieve the best results for the convnet tests on Intel Xeon and Intel Xeon Phi processors.
- Data format: for best performance, we recommend that users explicitly specify the NCHW format for their neural network models. The default NHWC format used in TensorFlow is not the most efficient from the point of view of data processing in the CPU; when it is used, additional conversion costs are incurred.
- Inter-op / intra-op parameters: we also recommend experimenting with these TensorFlow parameters to achieve optimal tuning for each model and each CPU platform. These parameters affect the parallelization within the same level and between levels.
- Package size: this is another important parameter that affects both the available parallelization for enabling all cores, and the size of the working set and the overall memory performance.
- OMP_NUM_THREADS : for best performance, you need to effectively use all available cores. This parameter is especially important for Intel Xeon Phi processors, since it can be used to control the level of hyperthreading (from 1 to 4).
- Transposition at matrix multiplication: for matrices of a certain size, the transposition of the second input matrix b provides higher performance (more efficient use of the cache) at the level of matrix multiplication. This is true for all matrix multiplication operations used in the three models shown below. Users should experiment with this parameter for other matrix sizes.
- KMP_BLOCKTIME : here you can try different settings for the timeout (in milliseconds) of each thread after completing execution in a parallel area.
Sample Settings for Intel Xeon Processor
(Broadwell family, 2 physical processors, 22 cores)
Sample Settings for Intel Xeon Phi Processor
(Knights Landing family, 68 cores)
Performance results on the Intel Xeon processor
(Broadwell family, 2 physical processors, 22 cores)
Performance results on Intel Xeon Phi processor
(Knights Landing family, 68 cores)
Performance results for various packet sizes on Intel Xeon (Broadwell) and Intel Xeon Phi (Knights Landing) processors - training
TensorFlow installation with CPU optimizations
You can either install prebuilt binary packages using pip or conda according to the instructions in the Available Intel-optimized wheel TensorFlow package, or you can build the packages yourself from the source code using the instructions below.
- Run ./configure in the TensorFlow source folder. In this case, the latest version of Intel MKL for machine learning will be automatically loaded into tensorflow / third_party / mkl / mklml, if you choose to use Intel MKL.
- Run the following commands to create a pip package with which you can install an optimized TensorFlow assembly.
- PATH can be changed to point to a specific version of the GCC compiler.
export PATH=/PATH/gcc/bin:$PATH - LD_LIBRARY_PATH can also be modified to point to the new GLIBC.
export LD_LIBRARY_PATH=/PATH/gcc/lib64:$LD_LIBRARY_PATH - Build for best performance on Intel Xeon and Intel Xeon Phi processors.
bazel build --config=mkl --copt=”-DEIGEN_USE_VML” -c opt //tensorflow/tools/pip_package:
build_pip_package
- PATH can be changed to point to a specific version of the GCC compiler.
- Install the optimized package wheel TensorFlow.
bazel-bin/tensorflow/tools/pip_package/build_pip_package ~/path_to_save_wheel
pip install --upgrade --user ~/path_to_save_wheel /wheel_name.whl
system configuration
| BDW4 | KNL11 | ||
|---|---|---|---|
| Architecture | x86_64 | Architecture | x86_64 |
| CPU operating modes | 32-bit, 64-bit | CPU operating modes | 32-bit, 64-bit |
| Byte order | Straight | Byte order | Straight |
| Number of CPU | 44 | Number of CPU | 272 |
| Included CPUs | 0–43 | Included CPUs | 0–271 |
| Threads per core | one | Threads per core | four |
| Core on physical processor | 22 | Core on physical processor | 68 |
| Physical processors | 2 | Physical processors | one |
| NUMA nodes | 2 | NUMA nodes | 2 |
| Vendor ID | Genuinelntel | Vendor ID | Genuinelntel |
| CPU family | 6 | CPU family | 6 |
| Model | 79 | Model | 37 |
| Model name | lntel® Xeon® E5-2699v4 2.20 GHz | Model name | lntel® Xeon Phi (TM) 7250 1.40 GHz |
| Release | one | Release | one |
| CPU frequency, MHz | 2426,273 | CPU frequency, MHz | 1400 |
| BogoMIPS | 4397.87 | BogoMIPS | 2793.45 |
| Visualization | VT-x | Level 1 data cache | 32 KB |
| Level 1 data cache | 32 KB | Level 1 instruction cache | 32 KB |
| Level 1 instruction cache | 32 KB | Level 2 Cache | 1024 KB |
| Level 2 Cache | 256 KB | CPU node NUMA 0 | 0–271 |
| Level 3 Cache | 56 320 KB | ||
| CPU node NUMA 0 | 0–21 | ||
| NUMA 1 CPU | 22–43 | ||
What does this mean for AI?
Optimizing TensorFlow means that depth learning solutions built on this widely available and widely used platform are now much faster on Intel processors; increased flexibility, availability and scale of such solutions. The performance of Intel Xeon Phi processors, for example, scales almost linearly with the addition of cores and nodes, which can dramatically reduce training time for machine learning models. Increasing the performance of TensorFlow while increasing the performance of Intel processors will enable the processing of larger and more complex loads of AI.
Collaboration between Intel and Google to optimize TensorFlow is organized in the course of continuous activity aimed at increasing the availability of AI for data developers and researchers, to realize the possibility of launching AI applications, where they are needed, on any devices and in any environment, from user devices to of clouds. Intel experts believe that higher availability of AI is the most important factor for creating models and algorithms of AI of a new generation that can solve the most pressing problems of business, science, technology, medicine and society.
During the collaboration, we have already managed to dramatically improve performance on platforms with Intel Xeon and Intel Xeon Phi processors. The code with improved algorithms is available in the TensorFlow repository of Google Inc. in GitHub . We ask developers from the AI community to try these optimization measures and share their feedback.
Source: https://habr.com/ru/post/338870/
All Articles